LiveBrowseComp: Are Search Agents Searching, or Just Verifying What They Already Know?
Pith reviewed 2026-06-29 11:59 UTC · model grok-4.3
The pith
Static search benchmarks let agents succeed by verifying what they already know rather than finding new evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
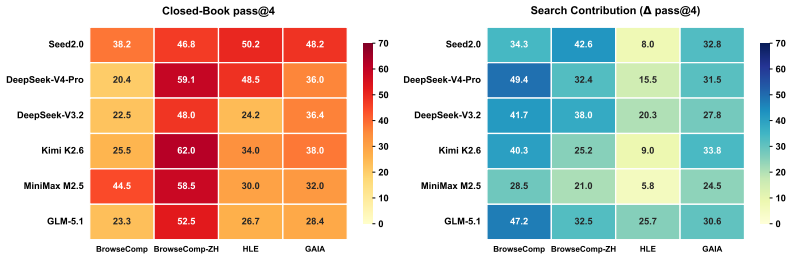
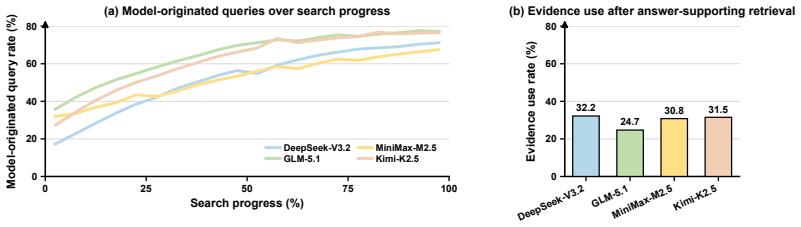
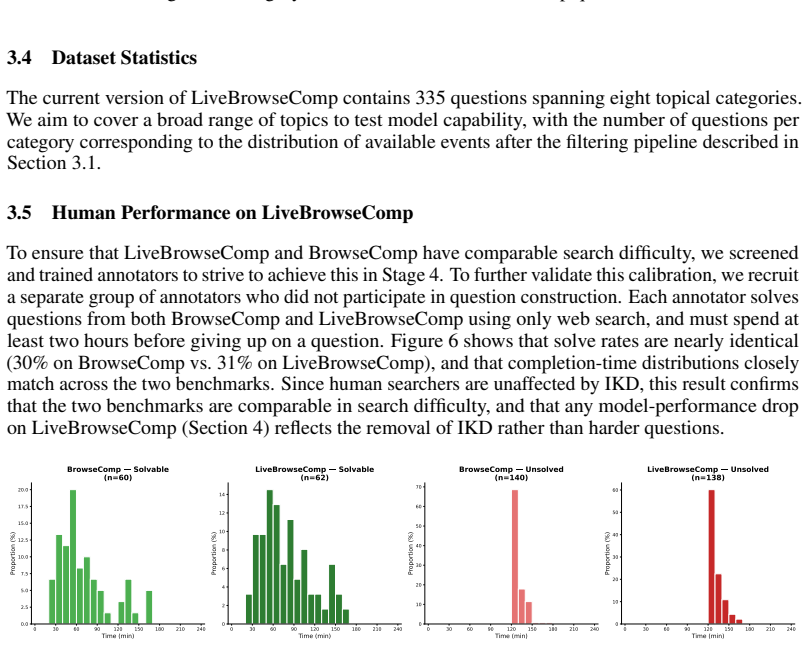
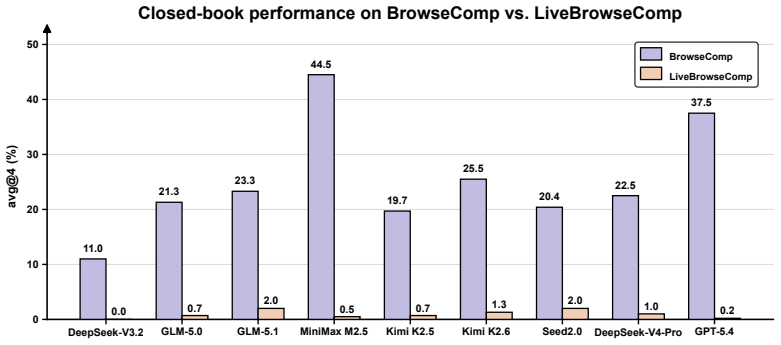
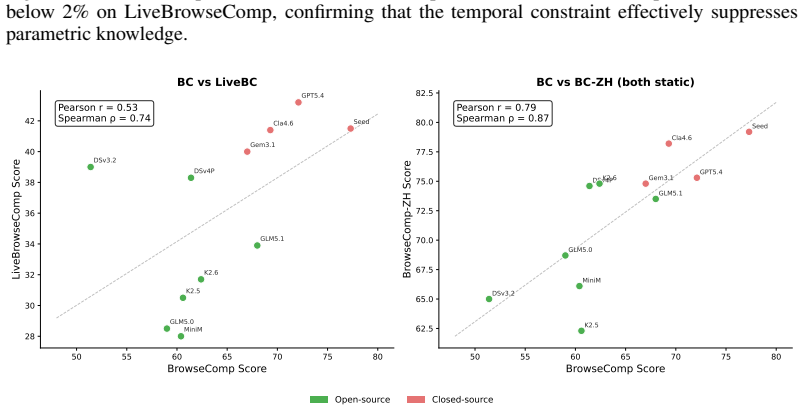
Agents exhibit Intrinsic Knowledge Dependence on BrowseComp by answering up to 44.5 percent of questions without tools, generating more than half their search queries from internally produced hypotheses, and performing worse than closed-book baselines once answer-supporting evidence is removed. LiveBrowseComp counters this by restricting questions to facts published within the 90 days before benchmark construction, drawn from six updated sources and filtered to exclude globally salient events. All evaluated agents score below 2 percent closed-book accuracy on LiveBrowseComp, search-augmented performance drops 25 to 40 points relative to BrowseComp, and prior model rankings cease to predict r
What carries the argument
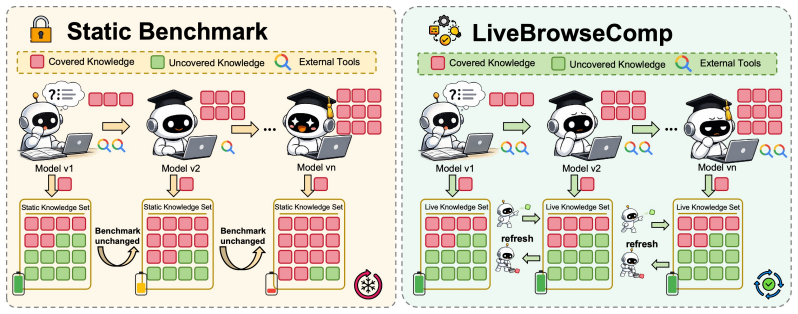
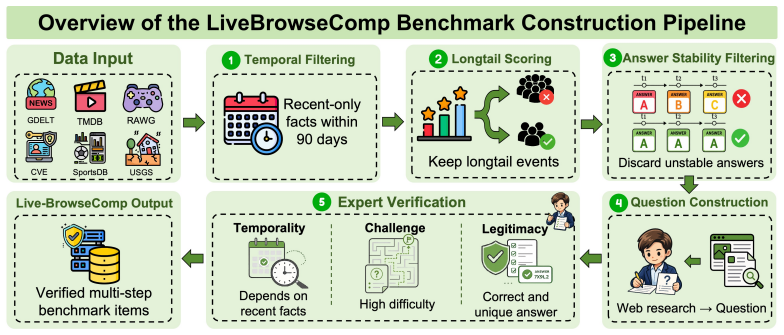
LiveBrowseComp, a benchmark of 335 human-authored questions whose answers depend exclusively on facts published in the 90 days preceding construction and filtered to exclude globally salient events.
If this is right
- Static benchmarks can produce inflated estimates of search ability by allowing agents to rely on internal knowledge.
- LiveBrowseComp isolates evidence-driven performance by using only recent, non-salient facts.
- Model rankings derived from BrowseComp may not reflect ordering on tasks that require genuine discovery.
- Development of search agents should target methods that increase dependence on retrieved evidence over pre-encoded information.
- Future benchmarks of this type may need repeated updates to stay outside training cutoffs.
Where Pith is reading between the lines
- The same time-window approach could be used to create stricter tests in other agent benchmarks that currently mix recall with reasoning.
- Designers might add query-log analysis to detect and penalize internally generated hypotheses during evaluation.
- If models are periodically retrained on newer data, the effective lifetime of such a benchmark would shorten and require more frequent refresh cycles.
Load-bearing premise
The 335 questions in LiveBrowseComp have answers that depend exclusively on facts published within the 90 days preceding benchmark construction and have been filtered to exclude globally salient events, ensuring they lie outside models' intrinsic knowledge.
What would settle it
A closed-book test in which any evaluated model achieves substantially higher than 2 percent accuracy on LiveBrowseComp questions would show that the questions are not outside the models' prior knowledge.
Figures

read the original abstract
Are LLM-based search agents genuinely searching, or using the web to verify what they already know? We study this question on BrowseComp with three diagnostics. Our analysis reveals Intrinsic Knowledge Dependence (IKD): even with tool access, agents often rely on intrinsic knowledge -- information encoded in the model before retrieval -- rather than on external evidence. Agents answer up to 44.5% of BrowseComp questions without tools, generate more than half of their search queries from internally produced hypotheses rather than retrieved leads, and perform worse than closed-book baselines when answer-supporting evidence is removed. These results suggest that static search benchmarks can reward memory-backed verification rather than evidence-driven discovery, conflating what agents already know with what they can find. We then introduce LiveBrowseComp, a deep-search benchmark designed to evaluate agents beyond intrinsic coverage. It contains 335 human-authored questions whose answers depend on facts published within the 90 days preceding benchmark construction, drawn from six updated sources and filtered to exclude globally salient events. On LiveBrowseComp, all evaluated agents fall below 2% closed-book accuracy, search-augmented scores drop by 25-40 points relative to BrowseComp, and prior model rankings no longer reliably predict performance. LiveBrowseComp is available at https://huggingface.co/datasets/Forival/LiveBrowseComp.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM search agents on static benchmarks like BrowseComp frequently rely on intrinsic knowledge (pre-trained information) rather than external evidence, as shown by up to 44.5% closed-book accuracy, over half of search queries generated from internal hypotheses, and degraded performance when supporting evidence is removed. To address this, the authors introduce LiveBrowseComp, a benchmark of 335 human-authored questions based exclusively on facts from the 90 days before construction (drawn from six updated sources and filtered for non-salient events), on which closed-book accuracy falls below 2%, search-augmented scores drop 25-40 points, and prior model rankings no longer hold. The dataset is released publicly.
Significance. If the central claim holds, the work identifies a meaningful limitation in how static search benchmarks evaluate agents, potentially conflating memorization with retrieval. The public release of LiveBrowseComp is a clear strength that enables further community use and testing. This could prompt more careful benchmark design in AI agent evaluation, though the result's impact depends on resolving the verification gaps noted below.
major comments (2)
- [LiveBrowseComp construction] LiveBrowseComp construction (abstract and associated methods description): The claim that the 335 questions lie outside models' intrinsic knowledge—and thus that performance drops reflect removal of memory-backed verification—rests on the 90-day recency window plus salience filter. No per-question leakage checks against evaluated model cutoffs, exact source-selection criteria, or explicit verification procedures are reported beyond the aggregate <2% closed-book result. This is load-bearing for the interpretation that LiveBrowseComp evaluates 'beyond intrinsic coverage' rather than simply harder or differently formatted questions.
- [Diagnostics on BrowseComp] Diagnostics section (three IKD diagnostics on BrowseComp): The reported percentages (44.5% closed-book, >50% internal-hypothesis queries, performance drops when evidence removed) lack any mention of statistical tests, confidence intervals, or controls for confounds such as query-generation procedures. Without these, it is unclear whether the observed IKD effects are robust or could be explained by other factors.
minor comments (1)
- The abstract refers to 'six updated sources' without naming them; adding the specific sources and filtering criteria in the main text would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [LiveBrowseComp construction] LiveBrowseComp construction (abstract and associated methods description): The claim that the 335 questions lie outside models' intrinsic knowledge—and thus that performance drops reflect removal of memory-backed verification—rests on the 90-day recency window plus salience filter. No per-question leakage checks against evaluated model cutoffs, exact source-selection criteria, or explicit verification procedures are reported beyond the aggregate <2% closed-book result. This is load-bearing for the interpretation that LiveBrowseComp evaluates 'beyond intrinsic coverage' rather than simply harder or differently formatted questions.
Authors: We agree that more explicit documentation of the construction process is warranted. In the revised manuscript we will expand the methods section with the precise list of six sources, the exact criteria used to select them for recency, and a step-by-step description of the salience filter (including the operational definition of “globally salient events” and how it was applied by the human authors). The aggregate closed-book accuracy below 2% across multiple models remains our primary empirical support that the questions lie outside intrinsic coverage; however, we acknowledge that per-question leakage checks against each model’s training cutoff were not performed. We will add an explicit limitations paragraph noting this gap and recommending such checks for future benchmark releases. revision: partial
-
Referee: [Diagnostics on BrowseComp] Diagnostics section (three IKD diagnostics on BrowseComp): The reported percentages (44.5% closed-book, >50% internal-hypothesis queries, performance drops when evidence removed) lack any mention of statistical tests, confidence intervals, or controls for confounds such as query-generation procedures. Without these, it is unclear whether the observed IKD effects are robust or could be explained by other factors.
Authors: We accept the need for greater statistical transparency. The revised diagnostics section will report bootstrap confidence intervals for all three percentages and will include paired statistical tests (McNemar’s test for accuracy differences and binomial tests for the proportion of internal-hypothesis queries) to establish that the observed effects are unlikely to arise from sampling variability. We will also clarify the query-generation annotation protocol and discuss potential confounds, while noting that the >50% internal-hypothesis rate was replicated across two independent agent frameworks, which provides some control for implementation-specific artifacts. revision: yes
Circularity Check
No circularity: benchmark constructed from independent external sources
full rationale
The paper constructs LiveBrowseComp from six updated external sources using a 90-day recency window and salience filter, then reports empirical closed-book accuracy <2% as supporting evidence. This does not reduce to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. The central claim that questions lie outside intrinsic knowledge is grounded in the construction process and measured performance rather than assumed by construction. No equations or derivations are present that loop back to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Models' training data cutoff precedes the 90-day window used for LiveBrowseComp questions
Reference graph
Works this paper leans on
-
[7]
Introducing Deep Research
OpenAI. Introducing Deep Research. https://openai.com/zh-Hans-CN/index/ introducing-deep-research/, 2025. Accessed: 2026-05-07
2025
-
[8]
Gemini Deep Research
Google. Gemini Deep Research. https://gemini.google/overview/deep-research/,
-
[9]
Accessed: 2026-05-07
2026
-
[10]
T rivia QA : A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension, 2017. URL https://doi. org/10.18653/v1/P17-1147
-
[11]
Lost in the middle: How language models use long contexts
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur P. Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: a benchmark for question answering research.Trans...
work page internal anchor Pith review doi:10.1162/tacl 2019
-
[12]
Cohen, Ruslan Salakhut- dinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhut- dinov, and Christopher D. Manning. Hotpotqa: A dataset for diverse, explainable multi- hop question answering. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii, editors,Proceedings of the 2018 Conference on Empirical Methods in Natural Lan- guage P...
-
[13]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents.CoRR, abs/2504.12516, 2025. doi: 10.48550/ ARXIV .2504.12516. URLhttps://doi.org/10.48550/arXiv.2504.12516
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.12516 2025
-
[15]
Introducing GPT-5.5
OpenAI. Introducing GPT-5.5. https://openai.com/index/introducing-gpt-5-5/ ,
-
[16]
Published: 2026-04-23; updated: 2026-04-24; accessed: 2026-05-07
2026
-
[17]
Introducing Claude Opus 4.6
Anthropic. Introducing Claude Opus 4.6. https://www.anthropic.com/news/ claude-opus-4-6, 2026. Published: 2026-02-05; accessed: 2026-05-07
2026
-
[18]
MiniMax-M2.5
MiniMaxAI. MiniMax-M2.5. https://huggingface.co/MiniMaxAI/MiniMax-M2.5,
-
[19]
Hugging Face model card; accessed: 2026-05-07
2026
-
[20]
Kimi-K2.6
Moonshot AI. Kimi-K2.6. https://huggingface.co/moonshotai/Kimi-K2.6, 2026. Hugging Face model card; accessed: 2026-05-07
2026
-
[21]
The GDELT project: Global database of events, language, and tone
GDELT Project. The GDELT project: Global database of events, language, and tone. https: //www.gdeltproject.org/data.html, 2024. Accessed: 2026-05-23
2024
-
[22]
TMDB — the movie database
The Movie Database (TMDB). TMDB — the movie database. https://www.themoviedb. org/, 2024. Accessed: 2026-05-23
2024
-
[23]
RAWG — video game database.https://rawg.io/, 2024
RAWG. RAWG — video game database.https://rawg.io/, 2024. Accessed: 2026-05-23
2024
-
[24]
NVD — national vulnerability database
National Vulnerability Database. NVD — national vulnerability database. https://nvd. nist.gov/, 2024. Accessed: 2026-05-23
2024
-
[25]
TheSportsDB — sports database
TheSportsDB. TheSportsDB — sports database. https://www.thesportsdb.com/, 2024. Accessed: 2026-05-23
2024
-
[26]
Geological Survey
U.S. Geological Survey. USGS earthquake hazards program. https://earthquake.usgs. gov/, 2024. Accessed: 2026-05-23
2024
-
[27]
BrowseComp-ZH: Benchmarking Web Browsing Ability of Large Language Models in Chinese
Peilin Zhou, Bruce Leon, Xiang Ying, Can Zhang, Yifan Shao, Qichen Ye, Dading Chong, Zhiling Jin, Chenxuan Xie, Meng Cao, et al. Browsecomp-zh: Benchmarking web browsing ability of large language models in chinese.arXiv preprint arXiv:2504.19314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
GAIA: a benchmark for general AI assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: a benchmark for general AI assistants. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URLhttps://openreview.net/forum?id=fibxvahvs3
2024
-
[30]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. Glm-5: from vibe coding to agentic engineering. arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Deepseek-v4: Towards highly efficient million-token context intelligence
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence. arXiv preprint, 2026. URL https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/ blob/main/DeepSeek_V4.pdf. Technical report
2026
-
[33]
Bytedance Seed. Seed2. 0 model card: Towards intelligence frontier for real-world complexity. Technical report, Technical report, Technical report, Bytedance, 2025. URL https://lf3-static . . . , 2026
2025
-
[34]
Zijian Chen, Xueguang Ma, Shengyao Zhuang, Ping Nie, Kai Zou, Andrew Liu, Joshua Green, Kshama Patel, Ruoxi Meng, Mingyi Su, et al. Browsecomp-plus: A more fair and transparent evaluation benchmark of deep-research agent.arXiv preprint arXiv:2508.06600, 2025
-
[35]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Kimi k2.5: Visual agentic intelligence
Kimi Team. Kimi k2.5: Visual agentic intelligence. 2026. URL https://api. semanticscholar.org/CorpusID:285269548
2026
-
[37]
Introducing GPT-5.4
OpenAI. Introducing GPT-5.4. https://openai.com/index/introducing-gpt-5-4/ , 2026
2026
-
[38]
Gemini 3.1 Pro
Google DeepMind. Gemini 3.1 Pro. https://deepmind.google/models/gemini/pro/, 2026
2026
-
[39]
Claude Sonnet 4.6.https://www.anthropic.com/claude/sonnet, 2026
Anthropic. Claude Sonnet 4.6.https://www.anthropic.com/claude/sonnet, 2026
2026
-
[40]
Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2...
2024
-
[41]
Mind2web: Towards a generalist agent for the web
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samual Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web. In Alice Oh, Tris- tan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Syst...
2023
-
[42]
Webvoyager: Building an end-to-end web agent with large multimodal models
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024,...
-
[43]
Fact, fetch, and reason: A unified evaluation of retrieval-augmented generation
Satyapriya Krishna, Kalpesh Krishna, Anhad Mohananey, Steven Schwarcz, Adam Stambler, Shyam Upadhyay, and Manaal Faruqui. Fact, fetch, and reason: A unified evaluation of retrieval-augmented generation. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Pro- ceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Com...
-
[44]
Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, John Ling, Sean Shi, Michael Choi, Anish Agrawal, Arnav Chopra, Adam Khoja, Ryan Kim, Richard Ren, Jason Hausenloy, Oliver Zhang, Mantas Mazeika, Sum- mer Yue, Alexandr Wang, and Dan Hendrycks. Humanity’s last exam.CoRR, abs/2501.14249,
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Tianci Xue, Weijian Qi, Tianneng Shi, Chan Hee Song, Boyu Gou, Dawn Song, Huan Sun, and Yu Su. An illusion of progress? assessing the current state of web agents.CoRR, abs/2504.01382,
-
[49]
NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark
Oscar Sainz, Jon Ander Campos, Iker García-Ferrero, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023,...
-
[50]
Alon Jacovi, Avi Caciularu, Omer Goldman, and Yoav Goldberg. Stop uploading test data in plain text: Practical strategies for mitigating data contamination by evaluation benchmarks. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6...
-
[52]
Data contamination quiz: A tool to detect and estimate contamination in large language models.Trans
Shahriar Golchin and Mihai Surdeanu. Data contamination quiz: A tool to detect and estimate contamination in large language models.Trans. Assoc. Comput. Linguistics, 13:809–830, 2025. doi: 10.1162/TACL.A.20. URLhttps://doi.org/10.1162/tacl.a.20
-
[53]
White, Aaron Schein, and Ryan Cotterell
Kevin Du, Vésteinn Snæbjarnarson, Niklas Stoehr, Jennifer C. White, Aaron Schein, and Ryan Cotterell. Context versus prior knowledge in language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, Augu...
-
[54]
Pro- cedural knowledge in pretraining drives reasoning in large language models
Laura Ruis, Maximilian Mozes, Juhan Bae, Siddhartha Rao Kamalakara, Dwaraknath Gnanesh- war, Acyr Locatelli, Robert Kirk, Tim Rocktäschel, Edward Grefenstette, and Max Bartolo. Pro- cedural knowledge in pretraining drives reasoning in large language models. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
2025
-
[55]
URLhttps://openreview.net/forum?id=1hQKHHUsMx
OpenReview.net, 2025. URLhttps://openreview.net/forum?id=1hQKHHUsMx
2025
-
[56]
LiveBench: A Challenging, Contamination-Limited LLM Benchmark
Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Benjamin Feuer, Siddhartha Jain, Ravid Shwartz-Ziv, Neel Jain, Khalid Saifullah, Siddartha Naidu, Chinmay Hegde, Yann LeCun, Tom Goldstein, Willie Neiswanger, and Micah Goldblum. Livebench: A challenging, contamination- free LLM benchmark.CoRR, abs/2406.19314, 2024. doi: 10.48550/ARXIV .2406.19314. URL...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2024
-
[57]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2...
2025
-
[58]
ImageInWords: Unlocking hyper-detailed image descriptions
Tu Vu, Mohit Iyyer, Xuezhi Wang, Noah Constant, Jerry W. Wei, Jason Wei, Chris Tar, Yun- Hsuan Sung, Denny Zhou, Quoc V . Le, and Thang Luong. Freshllms: Refreshing large language models with search engine augmentation. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, T...
-
[59]
Junnan Liu, Hongwei Liu, Linchen Xiao, Ziyi Wang, Kuikun Liu, Songyang Gao, Wenwei Zhang, Songyang Zhang, and Kai Chen. Are your llms capable of stable reasoning? In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Findings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1,...
2025
-
[60]
final” or “championship,
Siyuan Wang, Zhuohan Long, Zhihao Fan, Xuanjing Huang, and Zhongyu Wei. Benchmark self-evolving: A multi-agent framework for dynamic LLM evaluation. In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, and Steven Schockaert, editors,Proceedings of the 31st International Conference on Computational Linguistics, COL- ING 202...
2025
-
[61]
Plan and execute research: Break complex questions into sub-questions, gather evidence across multiple sources, and prioritize primary sources and authoritative references when available
-
[62]
Note uncertainty, conflicts, and limitations when sources disagree
Evaluate source quality: Prefer reputable institutions, peer-reviewed research, official documentation, and high-quality journalism. Note uncertainty, conflicts, and limitations when sources disagree
-
[63]
Synthesize, don’t just list: Combine evidence into a coherent narrative or structured output, highlighting key takeaways and nuanced trade-offs
-
[66]
zero-based budgeting
https://www.zerobased.co.uk/about(production company: “zero-based budgeting” origin)
-
[68]
Where do I go from Here?
“Where do I go from Here?”(Model A, Model C, Model E – matches reference)
-
[69]
The Diaspora Project
“The Diaspora Project”(Model B)
-
[70]
Zero Based
“Zero Based”(Model D)
-
[71]
“Homecoming”(Model F) ... For each candidate̸=reference answer, manually search the web and check whether it satisfieseveryconstraint in the question. Result: PASS / FAIL(if FAIL, specify broken evidence or alternative valid answer) (Three verifiers independently complete this task per question.) Stage 5(b): Difficulty screening.Three independent annotato...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.