SeeGroup: Multi-Layer Depth Estimation of Transparent Surfaces via Self-Determined Grouping
Pith reviewed 2026-06-29 12:54 UTC · model grok-4.3
The pith
SeeGroup models multi-layer depth for transparent objects as unordered events in a point process, allowing the model to choose its own groupings without a fixed front-to-back order.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that per-pixel multi-layer depth can be cast as a point process in which depth layers are unordered events along each camera ray. This formulation induces a permutation-invariant likelihood over the observed layers and therefore a loss that naturally accommodates arbitrary groupings rather than requiring any predefined ordering strategy.
What carries the argument
Point-process formulation that treats depth layers as unordered events along each camera ray, yielding a permutation-invariant likelihood.
If this is right
- The network can assign surfaces to depth maps adaptively rather than following a rigid ordering.
- Any valid grouping of 3D points into layers is admissible during both training and inference.
- Quadruplet relative depth accuracy on LayeredDepth rises from 61.34% to 70.09%.
- The approach removes the inherent restrictiveness of sequential front-to-back layer prediction.
Where Pith is reading between the lines
- The same point-process construction could be tested on other estimation tasks where the number of output entities is variable and ordering is arbitrary.
- If the permutation-invariant loss proves stable across domains, it may simplify training pipelines that currently rely on hand-crafted ordering heuristics.
- Robotic perception systems that must handle transparent or reflective surfaces may gain from the removal of grouping assumptions.
Load-bearing premise
Treating depth layers as unordered events in a point process along each ray produces a permutation-invariant likelihood that correctly supports arbitrary valid groupings without introducing bias or instability in training.
What would settle it
A controlled test set of transparent scenes that admit multiple equally valid layer groupings, on which the SeeGroup loss either produces lower accuracy than a fixed-order baseline or fails to train stably.
Figures


read the original abstract
Transparent objects are common in daily life, and it is important to understand their multilayer depth, including the transparent surface and the objects behind it. Existing methods for multilayer depth typically extend single-layer prediction. They define layers by the front-to-back ordering of 3D points and predict the layers sequentially. However, as layered geometry can admit multiple valid groupings of 3D points into layers, a predefined grouping strategy is inherently restrictive. In this work, we propose SeeGroup, a multi-layer depth estimation method that avoids imposing a predefined grouping and allows the model itself to adaptively assign surfaces to depth maps. We formulate per-pixel multi-layer depth as a point process, treating depth layers as unordered events along each camera ray. This induces a permutation-invariant likelihood over the observed depth layers, yielding a loss that naturally supports arbitrary layer groupings. Experiments demonstrate that our method significantly advances the state of the art of multi-layer depth estimation, improving quadruplet relative depth accuracy on LayeredDepth benchmark from 61.34% to 70.09%. Code is available at https://github.com/princeton-vl/SeeGroup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SeeGroup, a multi-layer depth estimation method for transparent surfaces that models per-pixel depths along each camera ray as an unordered point process. This yields a permutation-invariant likelihood and loss function that supports arbitrary valid groupings without imposing a predefined front-to-back ordering. The central empirical claim is an improvement in quadruplet relative depth accuracy on the LayeredDepth benchmark from 61.34% to 70.09%.
Significance. If the reported gain is attributable to the point-process formulation rather than ancillary implementation choices, the work would offer a principled alternative to sequential layer prediction, addressing a recognized limitation in handling multiple valid groupings of transparent surfaces. The availability of code strengthens reproducibility.
major comments (2)
- [§3] §3 (Method): The derivation of the permutation-invariant likelihood from the point-process model is presented at a high level; it is unclear whether the resulting loss remains stable under varying numbers of layers or introduces bias toward certain groupings during optimization. A concrete expansion with the explicit likelihood expression and training objective is needed to confirm it correctly supports arbitrary groupings.
- [§4] §4 (Experiments): The 8.75-point absolute gain on quadruplet relative depth accuracy is reported without ablations that isolate the contribution of the self-determined grouping (e.g., comparison against the same backbone with a fixed ordering loss). This makes it difficult to attribute the improvement to the claimed formulation rather than other factors.
minor comments (3)
- The abstract and introduction would benefit from a brief statement of the exact point-process intensity function and how the likelihood is normalized.
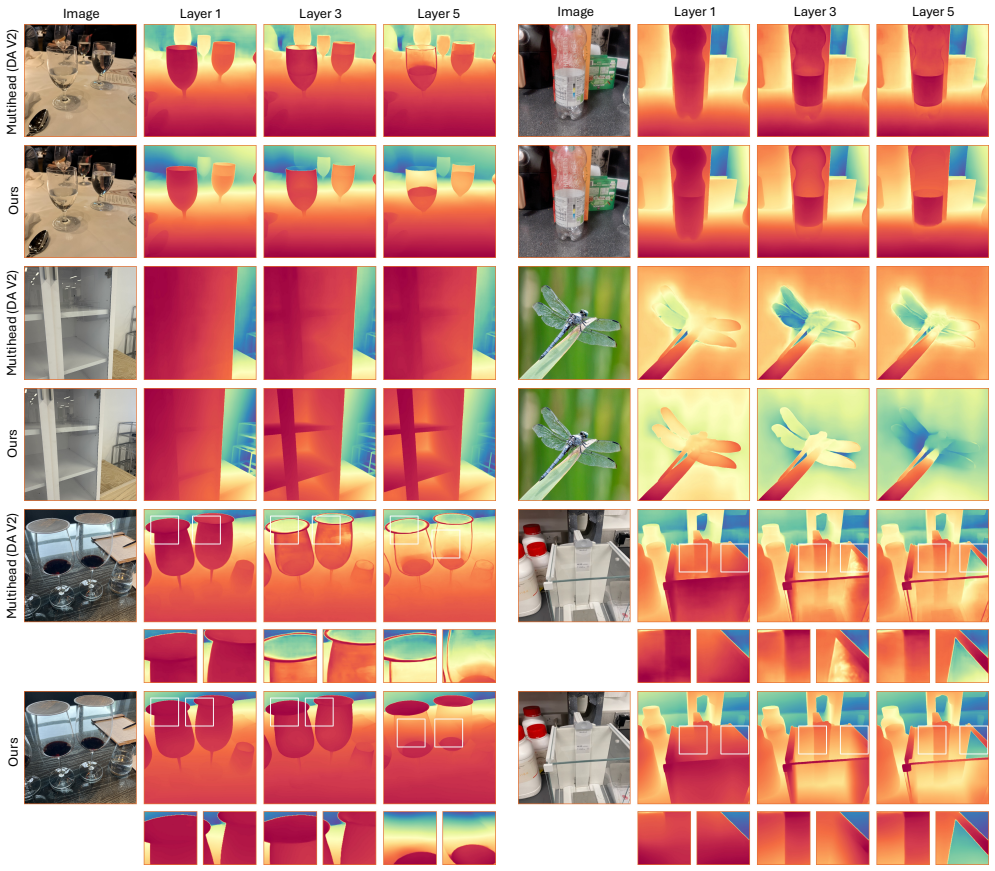
- Figure 2 (qualitative results) lacks error maps or per-layer visualizations that would illustrate the adaptive grouping behavior.
- Training details (optimizer, learning-rate schedule, number of layers sampled during training) are referenced but not fully specified in the main text; they should be expanded or clearly cross-referenced to the supplement.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and the recommendation for minor revision. We address each major comment below and will revise the manuscript accordingly to improve clarity and strengthen the empirical attribution.
read point-by-point responses
-
Referee: [§3] §3 (Method): The derivation of the permutation-invariant likelihood from the point-process model is presented at a high level; it is unclear whether the resulting loss remains stable under varying numbers of layers or introduces bias toward certain groupings during optimization. A concrete expansion with the explicit likelihood expression and training objective is needed to confirm it correctly supports arbitrary groupings.
Authors: We agree that an explicit derivation will improve clarity. In the revision we will add the full likelihood expression for the unordered point process along each ray, followed by the resulting permutation-invariant loss. Because the formulation treats layers as an unordered set of events, the likelihood is invariant to any reordering of the observed depths; this property holds for any number of layers and does not introduce ordering bias. We will also include a short stability analysis across layer cardinalities. revision: yes
-
Referee: [§4] §4 (Experiments): The 8.75-point absolute gain on quadruplet relative depth accuracy is reported without ablations that isolate the contribution of the self-determined grouping (e.g., comparison against the same backbone with a fixed ordering loss). This makes it difficult to attribute the improvement to the claimed formulation rather than other factors.
Authors: We acknowledge the value of an isolated ablation. While the main experiments already compare against prior sequential-layer methods that enforce fixed ordering, we will add a controlled ablation that replaces only the loss function (permutation-invariant vs. fixed-order) on the identical backbone and training schedule. This will directly quantify the contribution of the point-process formulation. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's derivation centers on modeling per-ray depths as an unordered point process to induce a permutation-invariant likelihood, presented as a modeling choice that supports arbitrary groupings without predefined ordering. This is not equivalent to its inputs by construction, nor does it reduce via fitted parameters renamed as predictions or self-citation chains. The reported accuracy gain (61.34% to 70.09%) is framed as an empirical benchmark outcome on LayeredDepth, with no load-bearing self-citations, ansatz smuggling, or renaming of known results visible in the abstract or described approach. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bidirectional attention network for monocular depth estimation
Shubhra Aich, Jean Marie Uwabeza Vianney, Md Amirul Is- lam, and Mannat Kaur Bingbing Liu. Bidirectional attention network for monocular depth estimation. In2021 IEEE In- ternational Conference on Robotics and Automation (ICRA), pages 11746–11752. IEEE, 2021. 2 Layer 1Layer 3Layer 5Image Layer 1Layer 3Layer 5Image Multihead(DA V2)OursMultihead(DA V2)OursM...
2021
-
[2]
CRC press Boca Raton, 2016
Adrian Baddeley, Ege Rubak, Rolf Turner, et al.Spatial point patterns: methodology and applications with R. CRC press Boca Raton, 2016. 5
2016
-
[3]
Neural Machine Translation by Jointly Learning to Align and Translate
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate.arXiv preprint arXiv:1409.0473, 2014. 7
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[4]
Adabins: Depth estimation using adaptive bins
Shariq Farooq Bhat, Ibraheem Alhashim, and Peter Wonka. Adabins: Depth estimation using adaptive bins. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4009–4018, 2021. 2
2021
-
[5]
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, and Matthias M ¨uller. Zoedepth: Zero-shot trans- fer by combining relative and metric depth.arXiv preprint arXiv:2302.12288, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Depth pro: Sharp monocular metric depth in less than a second
Alexey Bochkovskiy, Ama ¨el Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan Richter, and Vladlen Koltun. Depth pro: Sharp monocular metric depth in less than a second. InThe Thirteenth International Conference on Learning Representations, 2024. 1, 3
2024
-
[7]
Tom-net: Learning transparent object matting from a single image
Guanying Chen, Kai Han, and Kwan-Yee K Wong. Tom-net: Learning transparent object matting from a single image. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 9233–9241, 2018. 3
2018
-
[8]
Clearpose: Large-scale trans- parent object dataset and benchmark
Xiaotong Chen, Huijie Zhang, Zeren Yu, Anthony Opipari, and Odest Chadwicke Jenkins. Clearpose: Large-scale trans- parent object dataset and benchmark. InEuropean Confer- ence on Computer Vision, pages 381–396, 2022. 1, 3
2022
-
[9]
Learn- ing depth estimation for transparent and mirror surfaces
Alex Costanzino, Pierluigi Zama Ramirez, Matteo Poggi, Fabio Tosi, Stefano Mattoccia, and Luigi Di Stefano. Learn- ing depth estimation for transparent and mirror surfaces. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9244–9255, 2023. 3
2023
-
[10]
Predicting depth, surface nor- mals and semantic labels with a common multi-scale con- volutional architecture
David Eigen and Rob Fergus. Predicting depth, surface nor- mals and semantic labels with a common multi-scale con- volutional architecture. InProceedings of the IEEE inter- national conference on computer vision, pages 2650–2658,
-
[11]
Depth map prediction from a single image using a multi-scale deep net- work.Advances in neural information processing systems, 27, 2014
David Eigen, Christian Puhrsch, and Rob Fergus. Depth map prediction from a single image using a multi-scale deep net- work.Advances in neural information processing systems, 27, 2014. 2
2014
-
[12]
Depth map prediction from a single image using a multi-scale deep net- work.Advances in neural information processing systems, 27, 2014
David Eigen, Christian Puhrsch, and Rob Fergus. Depth map prediction from a single image using a multi-scale deep net- work.Advances in neural information processing systems, 27, 2014. 8
2014
-
[13]
Transcg: A large-scale real-world dataset for transparent object depth completion and a grasping baseline.IEEE Robotics and Automation Letters, 7(3):7383–7390, 2022
Hongjie Fang, Hao-Shu Fang, Sheng Xu, and Cewu Lu. Transcg: A large-scale real-world dataset for transparent object depth completion and a grasping baseline.IEEE Robotics and Automation Letters, 7(3):7383–7390, 2022. 1, 3
2022
-
[14]
Deep ordinal regression net- work for monocular depth estimation
Huan Fu, Mingming Gong, Chaohui Wang, Kayhan Bat- manghelich, and Dacheng Tao. Deep ordinal regression net- work for monocular depth estimation. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 2002–2011, 2018. 2
2002
-
[15]
Geowiz- ard: Unleashing the diffusion priors for 3d geometry esti- mation from a single image
Xiao Fu, Wei Yin, Mu Hu, Kaixuan Wang, Yuexin Ma, Ping Tan, Shaojie Shen, Dahua Lin, and Xiaoxiao Long. Geowiz- ard: Unleashing the diffusion priors for 3d geometry esti- mation from a single image. InEuropean Conference on Computer Vision, pages 241–258. Springer, 2024. 2
2024
-
[16]
Depthfm: Fast generative monocular depth estimation with flow matching
Ming Gui, Johannes Schusterbauer, Ulrich Prestel, Pingchuan Ma, Dmytro Kotovenko, Olga Grebenkova, Stefan Andreas Baumann, Vincent Tao Hu, and Bj ¨orn Om- mer. Depthfm: Fast generative monocular depth estimation with flow matching. InProceedings of the AAAI Conference on Artificial Intelligence, pages 3203–3211, 2025. 2, 3
2025
-
[17]
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Hao Chen, Kaixuan Wang, Gang Yu, Chunhua Shen, and Shaojie Shen. Metric3d v2: A versatile monocular geomet- ric foundation model for zero-shot metric depth and surface normal estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 1, 3
2024
-
[18]
Repurpos- ing diffusion-based image generators for monocular depth estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Met- zger, Rodrigo Caye Daudt, and Konrad Schindler. Repurpos- ing diffusion-based image generators for monocular depth estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9492– 9502, 2024. 2
2024
-
[19]
Jin Han Lee, Myung-Kyu Han, Dong Wook Ko, and Il Hong Suh. From big to small: Multi-scale local planar guidance for monocular depth estimation.arXiv preprint arXiv:1907.10326, 2019. 2
-
[20]
Megadepth: Learning single- view depth prediction from internet photos
Zhengqi Li and Noah Snavely. Megadepth: Learning single- view depth prediction from internet photos. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 2041–2050, 2018. 5
2041
-
[21]
Depthformer: Exploiting long-range correlation and local in- formation for accurate monocular depth estimation.Machine Intelligence Research, 20(6):837–854, 2023
Zhenyu Li, Zehui Chen, Xianming Liu, and Junjun Jiang. Depthformer: Exploiting long-range correlation and local in- formation for accurate monocular depth estimation.Machine Intelligence Research, 20(6):837–854, 2023. 2
2023
-
[22]
Binsformer: Revisiting adaptive bins for monocular depth estimation.IEEE Transactions on Image Processing, 33: 3964–3976, 2024
Zhenyu Li, Xuyang Wang, Xianming Liu, and Junjun Jiang. Binsformer: Revisiting adaptive bins for monocular depth estimation.IEEE Transactions on Image Processing, 33: 3964–3976, 2024. 2
2024
-
[23]
Monocular depth estimation for glass walls with context: a new dataset and method.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
Yuan Liang, Bailin Deng, Wenxi Liu, Jing Qin, and Shengfeng He. Monocular depth estimation for glass walls with context: a new dataset and method.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023. 1, 3
2023
-
[24]
Rich context aggregation with reflection prior for glass surface detection
Jiaying Lin, Zebang He, and Rynson WH Lau. Rich context aggregation with reflection prior for glass surface detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13415–13424, 2021. 3
2021
-
[25]
Keypose: Multi-view 3d labeling and key- point estimation for transparent objects
Xingyu Liu, Rico Jonschkowski, Anelia Angelova, and Kurt Konolige. Keypose: Multi-view 3d labeling and key- point estimation for transparent objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11602–11610, 2020. 3
2020
-
[26]
Stereobj-1m: Large-scale stereo image dataset for 6d object pose estima- tion
Xingyu Liu, Shun Iwase, and Kris M Kitani. Stereobj-1m: Large-scale stereo image dataset for 6d object pose estima- tion. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 10870–10879, 2021. 3
2021
-
[27]
Zhidan Liu, Chengtang Yao, Jiaxi Zeng, Yuwei Wu, and Yunde Jia. Multi-label stereo matching for transparent scene depth estimation.arXiv preprint arXiv:2505.14008, 2025. 3
-
[28]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 5, 9
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Don’t hit me! glass detection in real- world scenes
Haiyang Mei, Xin Yang, Yang Wang, Yuanyuan Liu, Shengfeng He, Qiang Zhang, Xiaopeng Wei, and Ryn- son WH Lau. Don’t hit me! glass detection in real- world scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3687– 3696, 2020. 3
2020
-
[30]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 5, 9
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Pytorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zem- ing Lin, Natalia Gimelshein, Luca Antiga, Alban Desmai- son, Andreas Kopf, Edward Yang, Zachary DeVito, Mar- tin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high...
2019
-
[32]
See- ing glassware: from edge detection to pose estimation and shape recovery
Cody J Phillips, Matthieu Lecce, and Kostas Daniilidis. See- ing glassware: from edge detection to pose estimation and shape recovery. InRobotics: Science and Systems, page 3. Michigan, USA, 2016. 3
2016
-
[33]
Unidepth: Universal monocular metric depth estimation
Luigi Piccinelli, Yung-Hsu Yang, Christos Sakaridis, Mattia Segu, Siyuan Li, Luc Van Gool, and Fisher Yu. Unidepth: Universal monocular metric depth estimation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10106–10116, 2024. 3
2024
-
[34]
UniDepthV2: Universal Monocular Metric Depth Estimation Made Simpler
Luigi Piccinelli, Christos Sakaridis, Yung-Hsu Yang, Mat- tia Segu, Siyuan Li, Wim Abbeloos, and Luc Van Gool. Unidepthv2: Universal monocular metric depth estimation made simpler.arXiv preprint arXiv:2502.20110, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Looking through the glass: Neu- ral surface reconstruction against high specular reflections
Jiaxiong Qiu, Peng-Tao Jiang, Yifan Zhu, Ze-Xin Yin, Ming- Ming Cheng, and Bo Ren. Looking through the glass: Neu- ral surface reconstruction against high specular reflections. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20823–20833, 2023. 1, 3
2023
-
[36]
Infinigen indoors: Photorealistic in- door scenes using procedural generation
Alexander Raistrick, Lingjie Mei, Karhan Kayan, David Yan, Yiming Zuo, Beining Han, Hongyu Wen, Meenal Parakh, Stamatis Alexandropoulos, Lahav Lipson, Zeyu Ma, and Jia Deng. Infinigen indoors: Photorealistic in- door scenes using procedural generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21783–...
2024
-
[37]
Open chal- lenges in deep stereo: the booster dataset
Pierluigi Zama Ramirez, Fabio Tosi, Matteo Poggi, Samuele Salti, Stefano Mattoccia, and Luigi Di Stefano. Open chal- lenges in deep stereo: the booster dataset. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21168–21178, 2022. 1, 3
2022
-
[38]
Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer, 2020
Ren ´e Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer, 2020. 2, 5, 9
2020
-
[39]
Clear grasp: 3d shape estimation of transparent objects for manip- ulation
Shreeyak Sajjan, Matthew Moore, Mike Pan, Ganesh Na- garaja, Johnny Lee, Andy Zeng, and Shuran Song. Clear grasp: 3d shape estimation of transparent objects for manip- ulation. In2020 IEEE International Conference on Robotics and Automation (ICRA), pages 3634–3642. IEEE, 2020. 3
2020
-
[40]
Diffusion-based depth inpainting for transparent and reflec- tive objects.IEEE Transactions on Circuits and Systems for Video Technology, 2024
Tianyu Sun, Dingchang Hu, Yixiang Dai, and Guijin Wang. Diffusion-based depth inpainting for transparent and reflec- tive objects.IEEE Transactions on Circuits and Systems for Video Technology, 2024. 3
2024
-
[41]
Seeing through the glass: Neural 3d reconstruction of object inside a transpar- ent container
Jinguang Tong, Sundaram Muthu, Fahira Afzal Maken, Chuong Nguyen, and Hongdong Li. Seeing through the glass: Neural 3d reconstruction of object inside a transpar- ent container. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12555– 12564, 2023. 1, 3
2023
-
[42]
Dif- fusion models for monocular depth estimation: Overcoming challenging conditions
Fabio Tosi, Pierluigi Zama Ramirez, and Matteo Poggi. Dif- fusion models for monocular depth estimation: Overcoming challenging conditions. InEuropean Conference on Com- puter Vision (ECCV), 2024. 2, 3
2024
-
[43]
Phocal: A multi-modal dataset for category-level object pose estima- tion with photometrically challenging objects
Pengyuan Wang, HyunJun Jung, Yitong Li, Siyuan Shen, Rahul Parthasarathy Srikanth, Lorenzo Garattoni, Sven Meier, Nassir Navab, and Benjamin Busam. Phocal: A multi-modal dataset for category-level object pose estima- tion with photometrically challenging objects. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages ...
2022
-
[44]
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision.arXiv preprint arXiv:2410.19115, 2024. 3
-
[45]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang. Moge-2: Accurate monocular geometry with metric scale and sharp details.arXiv preprint arXiv:2507.02546,
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Layeredflow: A real-world benchmark for non-lambertian multi-layer optical flow
Hongyu Wen, Erich Liang, and Jia Deng. Layeredflow: A real-world benchmark for non-lambertian multi-layer optical flow. InEuropean Conference on Computer Vision, pages 477–495. Springer, 2024. 3
2024
-
[47]
Seeing and seeing through the glass: Real and synthetic data for multi-layer depth estimation
Hongyu Wen, Yiming Zuo, Venkat Subramanian, Patrick Chen, and Jia Deng. Seeing and seeing through the glass: Real and synthetic data for multi-layer depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6715–6725, 2025. 1, 2, 3, 5, 6, 9
2025
-
[48]
Segmenting transparent ob- jects in the wild
Enze Xie, Wenjia Wang, Wenhai Wang, Mingyu Ding, Chunhua Shen, and Ping Luo. Segmenting transparent ob- jects in the wild. InEuropean Conference on Computer Vi- sion, pages 696–711, 2020. 3
2020
-
[49]
Seeing glass: Joint point-cloud and depth completion for transparent objects
Haoping Xu, Yi Ru Wang, Sagi Eppel, Alan Aspuru-Guzik, Florian Shkurti, and Animesh Garg. Seeing glass: Joint point-cloud and depth completion for transparent objects. InConference on Robot Learning, pages 827–838. PMLR,
-
[50]
Transcut: Transparent object segmentation from a light-field image
Yichao Xu, Hajime Nagahara, Atsushi Shimada, and Rin- ichiro Taniguchi. Transcut: Transparent object segmentation from a light-field image. InProceedings of the IEEE Inter- national Conference on Computer Vision, pages 3442–3450,
-
[51]
Transformer-based attention networks for continuous pixel-wise prediction
Guanglei Yang, Hao Tang, Mingli Ding, Nicu Sebe, and Elisa Ricci. Transformer-based attention networks for continuous pixel-wise prediction. InProceedings of the IEEE/CVF International Conference on Computer vision, pages 16269–16279, 2021. 2
2021
-
[52]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10371–10381, 2024. 3
2024
-
[53]
Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2025
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2025. 1, 3, 5, 9
2025
-
[54]
En- forcing geometric constraints of virtual normal for depth pre- diction
Wei Yin, Yifan Liu, Chunhua Shen, and Youliang Yan. En- forcing geometric constraints of virtual normal for depth pre- diction. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 5684–5693, 2019. 2
2019
-
[55]
Metric3d: Towards zero-shot metric 3d prediction from a single image
Wei Yin, Chi Zhang, Hao Chen, Zhipeng Cai, Gang Yu, Kaixuan Wang, Xiaozhi Chen, and Chunhua Shen. Metric3d: Towards zero-shot metric 3d prediction from a single image. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9043–9053, 2023. 3
2023
-
[56]
Neural window fully-connected crfs for monocu- lar depth estimation
Weihao Yuan, Xiaodong Gu, Zuozhuo Dai, Siyu Zhu, and Ping Tan. Neural window fully-connected crfs for monocu- lar depth estimation. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 3916–3925, 2022. 2
2022
-
[57]
Towards ro- bust monocular depth estimation in non-lambertian surfaces
Junrui Zhang, Jiaqi Li, Yachuan Huang, Yiran Wang, Jinghong Zheng, Liao Shen, and Zhiguo Cao. Towards ro- bust monocular depth estimation in non-lambertian surfaces. InEuropean Conference on Computer Vision, pages 175–
-
[58]
Lit: Light-field inference of transparency for refractive object localization.IEEE Robotics and Automation Letters, 5(3):4548–4555, 2020
Zheming Zhou, Xiaotong Chen, and Odest Chadwicke Jenk- ins. Lit: Light-field inference of transparency for refractive object localization.IEEE Robotics and Automation Letters, 5(3):4548–4555, 2020
2020
-
[59]
Rgb-d local implicit function for depth completion of transparent objects
Luyang Zhu, Arsalan Mousavian, Yu Xiang, Hammad Mazhar, Jozef van Eenbergen, Shoubhik Debnath, and Di- eter Fox. Rgb-d local implicit function for depth completion of transparent objects. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 4649–4658, 2021. 3
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.