Reverse Probing: Supervised Token-level Uncertainty Quantification for Large Language Models in Clinical Text
Pith reviewed 2026-06-29 12:19 UTC · model grok-4.3
The pith
Reverse Probing estimates token-level uncertainty in clinical LLM outputs by extracting signals from internal activations using pre-existing labeled summaries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
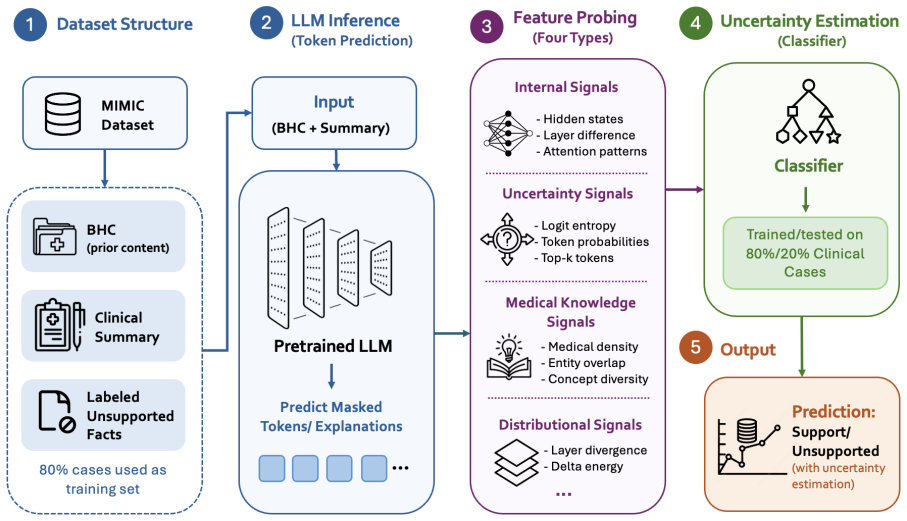
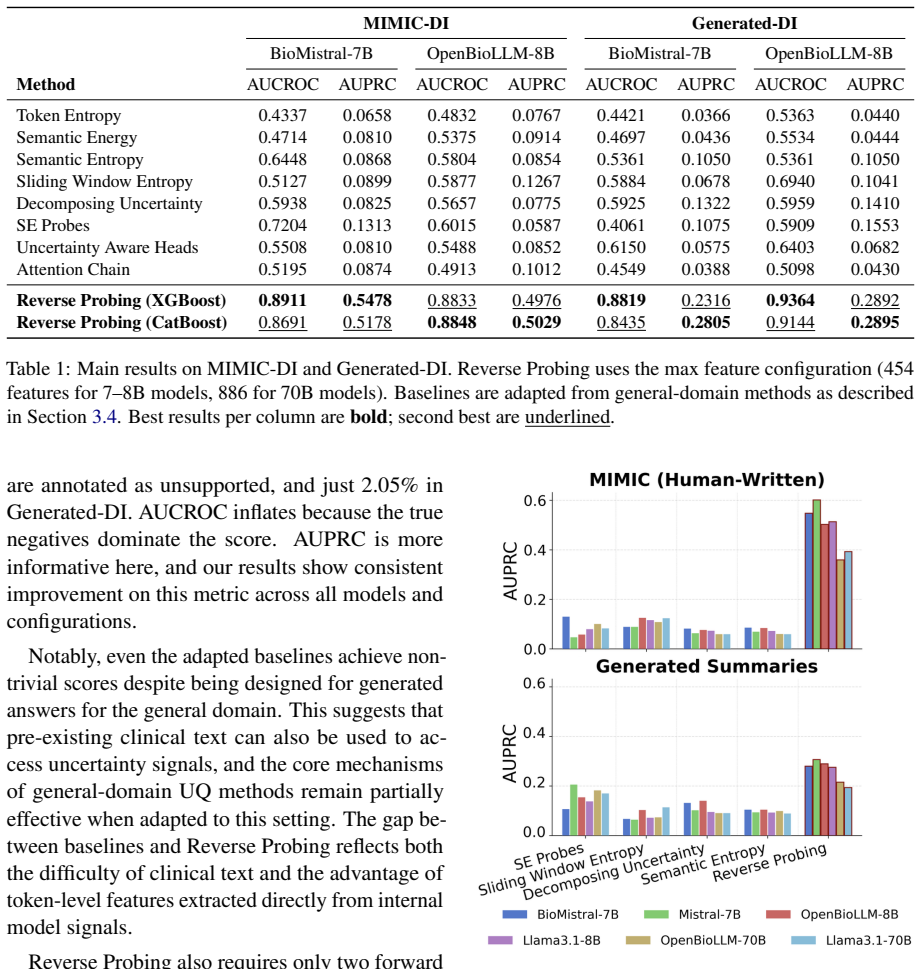
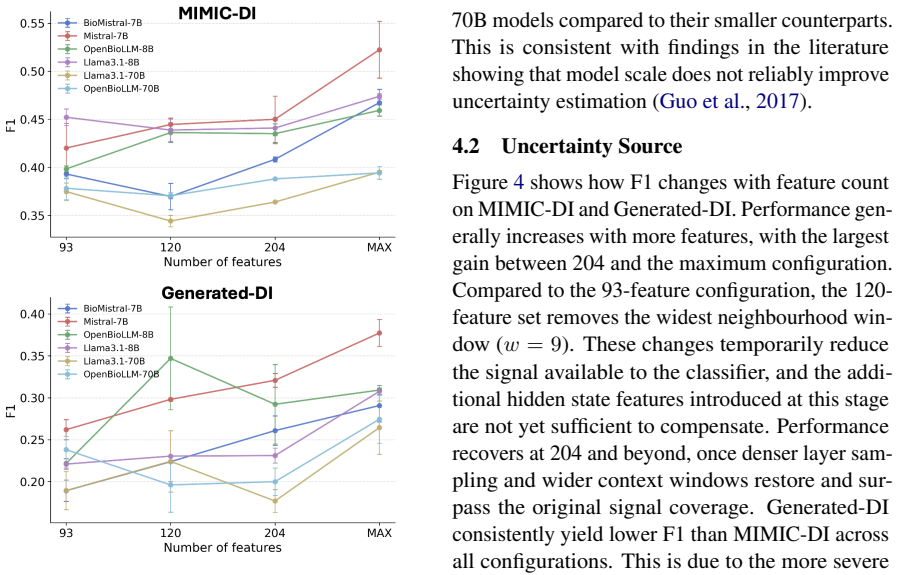
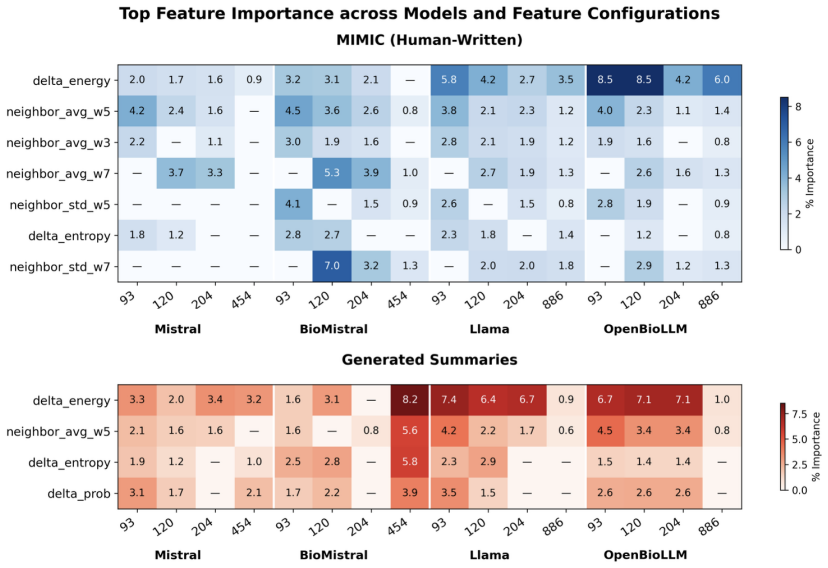
Reverse Probing is the first uncertainty quantification framework specialized for clinical summarization. It estimates token-level uncertainty directly from pre-existing labeled summaries by treating the text as a probe into the model's internal state and extracting signals from four categories of internal activations. On two expert-annotated clinical datasets it outperforms eight adapted baselines on all metrics, reaching up to four times higher AUPRC while lowering inference time and computational costs. Feature analysis identifies delta energy and neighborhood context as the most consistent predictors across models.
What carries the argument
Reverse Probing, a supervised framework that extracts uncertainty signals from four categories of internal activations when the model processes pre-existing labeled summaries, without generating new samples.
If this is right
- Token-level uncertainty estimates become available without repeated sampling of new model outputs.
- Clinical summarization systems can localize specific unsupported content in generated text.
- Uncertainty quantification requires less inference time and compute than sampling-based alternatives.
- Delta energy and neighborhood context features provide consistent signals across different model sizes.
- The method supplies interpretable information on how models internally respond to unsupported clinical content.
Where Pith is reading between the lines
- The activation-based approach could extend to other specialized long-text domains such as legal or technical writing.
- The signals might be used during fine-tuning to reduce generation of unsupported spans.
- Performance depends on access to high-quality labeled summaries, which may limit use in data-scarce settings.
- Further checks could test correlation between these scores and actual factual errors on datasets beyond the two used here.
Load-bearing premise
Internal activations recorded while the model processes pre-existing labeled summaries supply reliable signals of uncertainty about unsupported content in new inputs.
What would settle it
Run Reverse Probing on a fresh clinical dataset containing model-generated unsupported spans and check whether its token-level scores match expert error annotations at rates clearly above the eight baselines.
Figures


read the original abstract
As large language models are increasingly deployed for clinical text, ensuring they can reliably signal their own uncertainty becomes critical. Most existing uncertainty quantification (UQ) methods are designed for open-domain generation and cannot localize uncertainty at the token or span level in long clinical text. We propose Reverse Probing, the first UQ framework specialized for clinical summarization, which estimates token-level uncertainty directly from pre-existing labeled summaries. Rather than sampling new outputs, Reverse Probing treats the text as a probe into the model's internal state, extracting uncertainty signals from four categories of internal activations. We evaluate on two expert-annotated clinical datasets and outperform eight adapted baselines on all metrics, achieving up to 4 times higher AUPRC while reducing inference time and computational costs. Feature analysis reveals that delta energy and neighborhood context are the most consistent predictors across all models. This study offers interpretable insights into how models internally respond to unsupported clinical content.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Reverse Probing, a supervised token-level uncertainty quantification framework for LLMs in clinical summarization. It extracts signals from four categories of internal activations while the model processes pre-existing labeled summaries, trains probes on these signals to detect uncertainty on unsupported content, and reports evaluation on two expert-annotated datasets where it outperforms eight adapted baselines on all metrics with up to 4× higher AUPRC, lower inference time, and lower computational cost. Feature analysis identifies delta energy and neighborhood context as the most consistent predictors.
Significance. If the central performance claims and generalizability hold after addressing validation gaps, the work would offer a practical, sampling-free approach to localized UQ in clinical text, which is important for safe LLM deployment in medicine. The use of existing labeled summaries for probe training is a pragmatic advantage over methods requiring new generations, and the reported feature insights could inform future interpretability research in domain-specific settings.
major comments (3)
- [Abstract / Evaluation] Abstract and Evaluation: The abstract states outperformance and 4× AUPRC gains but supplies no dataset sizes, statistical tests, baseline implementation details, or ablation results. These omissions make the quantitative claims impossible to assess and are load-bearing for the central performance argument.
- [Evaluation] Evaluation: No cross-domain or out-of-distribution experiments are reported despite the acknowledged domain specificity of clinical text (terminology, note structure, entity distributions). This leaves untested whether the four activation categories capture model-intrinsic uncertainty signals or merely dataset-specific patterns learned from the training summaries, which directly affects the claim of applicability to new clinical inputs.
- [Methods] Methods: The four categories of internal activations used for signal extraction are referenced but not formally defined or motivated with equations or pseudocode in the visible text. Without this, it is difficult to evaluate whether the approach is reproducible or truly novel relative to existing activation-based probing techniques.
minor comments (2)
- [Abstract] The abstract mentions 'reducing inference time and computational costs' but does not quantify the savings or compare wall-clock times against the baselines; a table with these metrics would strengthen the efficiency claim.
- [Evaluation] Clarify the exact token-level labeling scheme used for the expert-annotated datasets (e.g., how unsupported spans are marked) to allow readers to judge label quality.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating where we agree and plan revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation: The abstract states outperformance and 4× AUPRC gains but supplies no dataset sizes, statistical tests, baseline implementation details, or ablation results. These omissions make the quantitative claims impossible to assess and are load-bearing for the central performance argument.
Authors: We agree that the abstract's brevity limits the inclusion of supporting details. The full manuscript reports the sizes of the two expert-annotated datasets, baseline implementation specifics in the Evaluation section, ablation studies, and statistical significance testing for the reported gains. We will revise the abstract to incorporate dataset sizes and a brief mention of statistical support for the performance improvements, within length constraints. revision: partial
-
Referee: [Evaluation] Evaluation: No cross-domain or out-of-distribution experiments are reported despite the acknowledged domain specificity of clinical text (terminology, note structure, entity distributions). This leaves untested whether the four activation categories capture model-intrinsic uncertainty signals or merely dataset-specific patterns learned from the training summaries, which directly affects the claim of applicability to new clinical inputs.
Authors: This is a fair and important point regarding generalizability. Our experiments use two distinct expert-annotated clinical datasets to demonstrate consistency, but we did not conduct explicit cross-domain or OOD evaluations. We will add a limitations discussion acknowledging this gap and the risk of dataset-specific patterns, while noting that the activation categories target model-intrinsic signals; we will also outline plans for future broader validation. revision: partial
-
Referee: [Methods] Methods: The four categories of internal activations used for signal extraction are referenced but not formally defined or motivated with equations or pseudocode in the visible text. Without this, it is difficult to evaluate whether the approach is reproducible or truly novel relative to existing activation-based probing techniques.
Authors: We thank the referee for highlighting this clarity issue. The full Methods section formally defines the four activation categories with equations, motivates their selection, and includes pseudocode for the signal extraction and probing process. We will revise the presentation to make these definitions and motivations more prominent and explicit to support reproducibility and differentiation from prior work. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper introduces Reverse Probing as a supervised framework that trains on internal activations extracted while processing pre-existing labeled summaries to predict token-level uncertainty. Evaluation is performed on two expert-annotated clinical datasets against eight baselines, with reported AUPRC gains. No equations, mathematical derivations, fitted parameters renamed as predictions, or self-citation chains are present in the provided text that would reduce the central claim to its inputs by construction. The approach is a standard feature-based supervised method whose validity rests on empirical performance rather than definitional equivalence or imported uniqueness theorems.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A meta-evaluation of faithfulness metrics for long-form hospital-course summarization. InMa- chine Learning for Healthcare Conference, pages 2–30. PMLR. Olivier Bodenreider. 2004. The unified medical lan- guage system (UMLS): integrating biomedical ter- minology.Nucleic Acids Research, 32(Database issue):D267–D270. Tianqi Chen and Carlos Guestrin. 2016. X...
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[2]
Medical Expert Annotations of Unsupported Facts in Doctor-Written and LLM-Generated Patient Summaries.PhysioNet. Version 1.0.1. Stefan Hegselmann, Zejiang Shen, Florian Gierse, Mon- ica Agrawal, David Sontag, and Xiaoyi Jiang. 2024. A data-centric approach to generate faithful and high quality patient summaries with large language mod- els. InConference o...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs
Lightgbm: a highly efficient gradient boosting decision tree. InProceedings of the 31st Interna- tional Conference on Neural Information Processing Systems, NIPS’17, page 3149–3157, Red Hook, NY , USA. Curran Associates Inc. Jannik Kossen, Jiatong Han, Muhammed Razzak, Lisa Schut, Shreshth Malik, and Yarin Gal. 2024. Se- mantic entropy probes: Robust and ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Yingzhou Lu, Tianyi Chen, Nan Hao, Capucine Van Rechem, Jintai Chen, and Tianfan Fu
Uncertainty estimation and quantification for llms: A simple supervised approach.Preprint, arXiv:2404.15993. Yingzhou Lu, Tianyi Chen, Nan Hao, Capucine Van Rechem, Jintai Chen, and Tianfan Fu. 2024. Un- certainty quantification and interpretability for clin- ical trial approval prediction.Health Data Science, 4:0126. Scott M Lundberg and Su-In Lee. 2017....
-
[5]
Efficient Hallucination Detection for LLMs Using Uncertainty-Aware Attention Heads
Uncertainty-aware attention heads: Efficient unsupervised uncertainty quantification for LLMs. arXiv preprint arXiv:2505.20045. Chenyu Wang, Weichao Zhou, Shantanu Ghosh, Kay- han Batmanghelich, and Wenchao Li. 2025. Seman- tic consistency-based uncertainty quantification for factuality in radiology report generation. InFind- ings of the Association for C...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.