Do Agents Need Semantic Metadata? A Comparative Study in Agentic Data Retrieval
Pith reviewed 2026-06-29 09:34 UTC · model grok-4.3
The pith
Semantic metadata enables agents to retrieve FAIR-compliant datasets with 65.7 percent higher precision than open-web search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
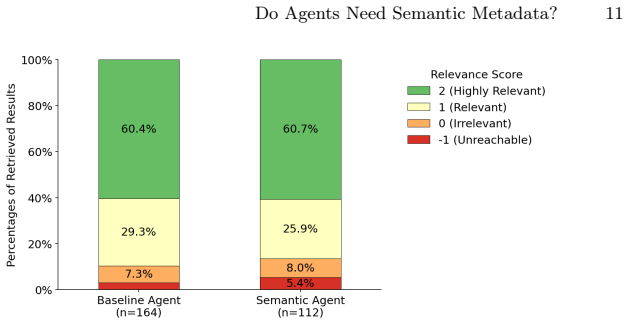
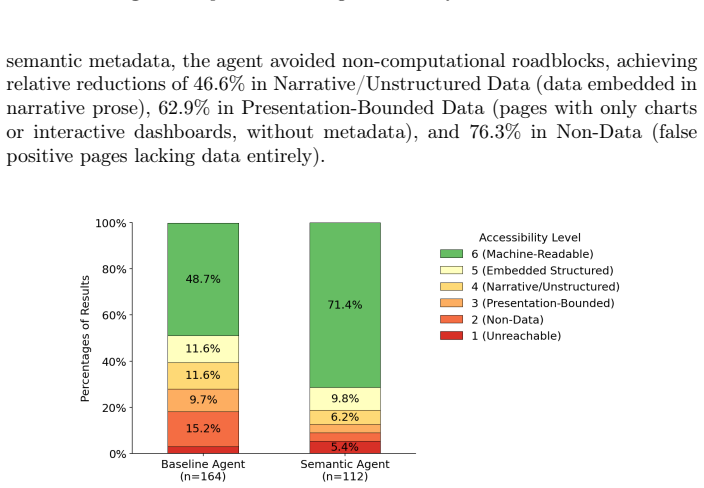
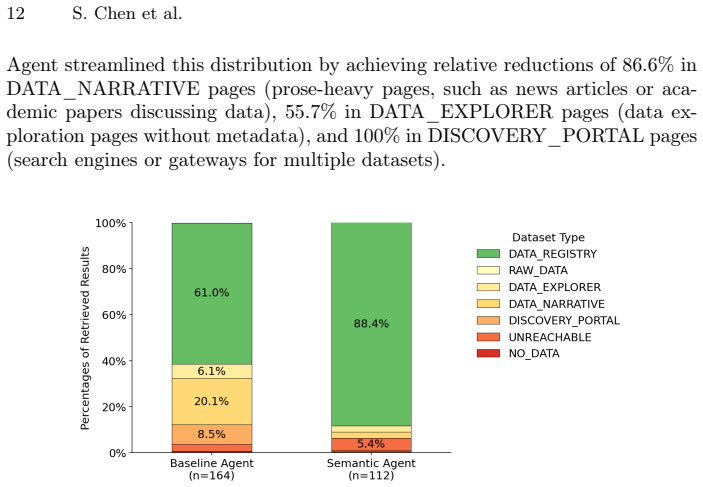
The Semantic Agent achieves 65.7 percent higher overall precision in retrieving FAIR-compliant datasets, including 44.9 percent higher precision on metadata-rich registries and 46.6 percent higher precision on pages with machine-readable downloads, while the Baseline Agent returns prose-heavy pages in 20.1 percent of results and portal landing pages in 8.5 percent of results.
What carries the argument
The side-by-side comparison of Baseline Agent (open-web retrieval) and Semantic Agent (schema.org corpus retrieval) scored by an LLM-as-a-judge pipeline mapped directly to FAIR principles.
If this is right
- Structured semantic metadata is required for reliable execution-oriented autonomous data workflows.
- Unstructured web retrieval supports broad coverage but produces frequent last-mile utility failures.
- Semantic registries deliver higher accuracy on downloadable, machine-actionable datasets.
- Baseline agents answer more questions but at the cost of lower precision on FAIR-compliant results.
Where Pith is reading between the lines
- Hybrid retrieval systems that combine open-web breadth with semantic filtering could improve both coverage and precision.
- The results imply that continued investment in schema.org-style annotation will be needed as agent use grows.
- The same comparative method could be applied to other domains such as code repositories or scientific literature.
Load-bearing premise
The LLM judge accurately and without bias maps retrieved items to semantic relevance, data accessibility, and computational utility under the FAIR principles.
What would settle it
A human-expert re-evaluation of the same retrieved items that finds no meaningful precision gap between the two agents.
Figures

read the original abstract
In the era of autonomous agents, machine-actionable data is critical for data-driven workflows. For more than a decade, semantic metadata like schema.org has anchored the FAIR principles (Findable, Accessible, Interoperable, and Reusable) for machine-actionable data and enabled discovery tools like Google Dataset Search. However, the rise of Large Language Models (LLMs) capable of navigating the unstructured web raises a fundamental question: Is semantic metadata still necessary for agentic data discovery, or can agents reliably retrieve actionable data directly from the web? We present a comparative analysis of agentic data retrieval across two distinct environments: a Baseline Agent searching billions of open-web documents, and a Semantic Agent leveraging a corpus of 90 million datasets using schema.org. We deploy an "LLM-as-a-judge" evaluation pipeline, mapped directly to the FAIR principles, to assess the semantic relevance, data accessibility, and computational utility of the retrieved data. Our results reveal a clear divergence. The Semantic Agent excels at retrieving actionable data, achieving a 44.9% higher precision for metadata-rich registries and a 46.6% higher precision for pages with machine-readable downloads among its returned results. Conversely, the Baseline Agent frequently suffers "Last-Mile Utility" failures, retrieving prose-heavy pages (20.1% of results) and portal landing pages (8.5%) rather than actual data pages. While the Baseline Agent achieves higher coverage by answering 40% more questions, the Semantic Agent delivers greater accuracy, achieving 65.7% higher overall precision in retrieving FAIR-compliant datasets. We conclude that while unstructured retrieval supports broad exploratory tasks, structured ecosystems remain the indispensable foundation for reliable, execution-oriented autonomous workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript compares a Baseline Agent retrieving data from the unstructured open web against a Semantic Agent using a corpus of 90 million schema.org-annotated datasets. Deploying an LLM-as-a-judge pipeline mapped to FAIR principles, it reports that the Semantic Agent achieves 44.9% higher precision on metadata-rich registries, 46.6% higher precision on pages with machine-readable downloads, and 65.7% higher overall precision in retrieving FAIR-compliant datasets, while the Baseline Agent answers 40% more questions but returns prose-heavy pages (20.1%) and portal landing pages (8.5%) more often. The central claim is that semantic metadata remains indispensable for reliable, execution-oriented agentic data retrieval despite lower coverage.
Significance. If the evaluation holds after validation, the work supplies empirical head-to-head evidence on the precision-coverage trade-off in agentic retrieval and the continued utility of structured metadata for FAIR-compliant outcomes. This could inform the design of hybrid discovery systems for autonomous agents.
major comments (2)
- [Evaluation Pipeline (abstract and methods)] The precision deltas (44.9%, 46.6%, 65.7%) and failure-mode percentages (20.1%, 8.5%) are produced exclusively by the LLM-as-a-judge pipeline that scores semantic relevance, accessibility, and computational utility. No prompt text, few-shot examples, temperature, calibration set, or human-rater agreement statistics are supplied, leaving open the possibility of systematic bias favoring the structurally different outputs of the Semantic Agent.
- [Experimental Setup] The Baseline Agent searches billions of open-web documents while the Semantic Agent is restricted to a 90-million dataset corpus; the manuscript does not demonstrate that the query sets or topic distributions are matched, so the direct precision comparison rests on an unshown equivalence between the two environments.
minor comments (1)
- [Abstract] The abstract reports that the Baseline Agent 'answers 40% more questions' without stating the absolute number of queries or the success criterion used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. Below we respond point-by-point to the two major concerns. We will expand the evaluation details for transparency and clarify the experimental design to address the comparison between environments.
read point-by-point responses
-
Referee: [Evaluation Pipeline (abstract and methods)] The precision deltas (44.9%, 46.6%, 65.7%) and failure-mode percentages (20.1%, 8.5%) are produced exclusively by the LLM-as-a-judge pipeline that scores semantic relevance, accessibility, and computational utility. No prompt text, few-shot examples, temperature, calibration set, or human-rater agreement statistics are supplied, leaving open the possibility of systematic bias favoring the structurally different outputs of the Semantic Agent.
Authors: We agree that the current manuscript lacks sufficient detail on the LLM-as-a-judge implementation. In the revision we will add an appendix containing the complete prompt templates (including the explicit mapping to each FAIR principle), few-shot examples, the temperature setting of 0.0, and Cohen's kappa statistics from a 100-query human validation subset. The judge instructions emphasize objective indicators such as presence of downloadable machine-readable files and schema.org compliance, which are format-agnostic; however, the added materials will allow readers to assess and replicate the scoring process directly. revision: yes
-
Referee: [Experimental Setup] The Baseline Agent searches billions of open-web documents while the Semantic Agent is restricted to a 90-million dataset corpus; the manuscript does not demonstrate that the query sets or topic distributions are matched, so the direct precision comparison rests on an unshown equivalence between the two environments.
Authors: The same fixed set of 500 queries is issued to both agents; topic coverage is therefore matched by construction. The environments are deliberately non-equivalent because they represent the two distinct retrieval paradigms under study (unstructured web versus schema.org corpus). Precision is measured on the results each agent actually returns for those identical queries, which directly quantifies the precision-coverage trade-off. We will add a sentence in the methods section explicitly stating that queries are held constant and that the comparison is between paradigms rather than between matched corpora. revision: partial
Circularity Check
No circularity; purely empirical comparison with no derivations or self-referential reductions
full rationale
The paper reports results from running two agents (Baseline and Semantic) on retrieval tasks and scoring outputs via an LLM judge mapped to FAIR criteria. The provided text contains no equations, fitted parameters, predictions derived from inputs, or self-citations used as load-bearing premises. All quantitative claims (e.g., 65.7% higher precision) are presented as direct experimental outcomes rather than reductions of prior results. No patterns from the enumerated list apply.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An LLM judge can reliably score retrieved data on semantic relevance, accessibility, and computational utility according to FAIR principles.
Reference graph
Works this paper leans on
-
[1]
Aghzal, M., Stein, G.J., Yao, Z.: Why Do LLM-based Web Agents Fail? A Hierar- chical Planning Perspective (2026)
2026
-
[2]
W3C recommendation, World Wide Web Consortium (W3C) (2024), https://www.w3.org/TR/vocab- dcat-3/
Albertoni, R., Browning, D., Cox, S.J.D., Gonzalez Beltran, A., Perego, A., Win- stanley, P.: Data catalog vocabulary (DCAT) - version 3. W3C recommendation, World Wide Web Consortium (W3C) (2024), https://www.w3.org/TR/vocab- dcat-3/
2024
-
[3]
Data Intelligence6(2), 457–487 (2024)
Albertoni, R., Browning, D., Cox, S.J.D., Gonzalez-Beltran, A.N., Perego, A., Winstanley, P.: The W3C data catalog vocabulary, version 2: Ratio- nale, design principles, and uptake. Data Intelligence6(2), 457–487 (2024). https://doi.org/10.1162/dint_a_00241
-
[4]
Alrashed, T., Paparas, D., Benjelloun, O., Sheng, Y., Noy, N.: Dataset or Not? A Study on the Veracity of Semantic Markup for Dataset Pages. In: The Semantic Web – ISWC 2021: 20th International Semantic Web Conference, ISWC 2021, Virtual Event, October 24–28, 2021, Proceedings. p. 338–356. Springer-Verlag, Berlin, Heidelberg (2021), https://doi.org/10.100...
-
[5]
Benjelloun, O., Chen, S., Noy, N.: Google Dataset Search by the numbers. In: International Semantic Web Conference (ISWC-2020), In-Use Track (2020), https://arxiv.org/abs/2006.06894
-
[6]
The VLDB Journal29(1), 251–272 (Aug 2019), https://doi.org/10.1007/s00778-019-00564-x
Chapman,A.,Simperl,E.,Koesten,L.,Konstantinidis,G.,Ibáñez,L.D.,Kacprzak, E., Groth, P.: Dataset Search: A Survey. The VLDB Journal29(1), 251–272 (Aug 2019), https://doi.org/10.1007/s00778-019-00564-x
-
[7]
Chezelles, T.L.S.D., Gasse, M., Drouin, A., Caccia, M., Boisvert, L., Thakkar, M., Marty, T., Assouel, R., Shayegan, S.O., Jang, L.K., Lù, X.H., Yoran, O., Kong, D., Xu, F.F., Reddy, S., Cappart, Q., Neubig, G., Salakhutdinov, R., Chapados, N., Lacoste, A.: The BrowserGym Ecosystem for Web Agent Research (2025), https://arxiv.org/abs/2412.05467
-
[8]
Chiang, C.H., Lee, H.y.: Do Metadata and Appearance of the Retrieved Web- pages Affect LLM’s Reasoning in Retrieval-Augmented Generation? In: Belinkov, Y., Kim, N., Jumelet, J., Mohebbi, H., Mueller, A., Chen, H. (eds.) Proceed- ings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Net- works for NLP. pp. 389–406. Association for Computa...
-
[9]
Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody, A., Tru- itt, S., Metropolitansky, D., Ness, R.O., Larson, J.: From Local to Global: A Graph RAG Approach to Query-Focused Summarization (2025), https://arxiv.org/abs/2404.16130
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Google: Agent Development Kit (ADK) (2026), https://adk.dev/, accessed: 2026- 04-22 Do Agents Need Semantic Metadata? 17
2026
-
[11]
Guha, R.V., Brickley, D., Macbeth, S.: Schema.org: evolution of struc- tured data on the web. Commun. ACM59(2), 44–51 (Jan 2016), https://doi.org/10.1145/2844544
-
[12]
In: Bouamor, H., Pino, J., Bali, K
Gur, I., Nachum, O., Miao, Y., Safdari, M., Huang, A., Chowdhery, A., Narang, S., Fiedel, N., Faust, A.: Understanding HTML with Large Language Models. In: Bouamor, H., Pino, J., Bali, K. (eds.) Findings of the Association for Com- putational Linguistics: EMNLP 2023. pp. 2803–2821. Association for Computa- tional Linguistics, Singapore (Dec 2023), https:/...
2023
-
[13]
In: Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., Sabato, S
Humphreys, P.C., Raposo, D., Pohlen, T., Thornton, G., Chhaparia, R., Mul- dal, A., Abramson, J., Georgiev, P., Santoro, A., Lillicrap, T.: A data- driven approach for learning to control computers. In: Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., Sabato, S. (eds.) Proceedings of the 39th International Conference on Machine Learning. Pro...
2022
-
[14]
In: Bouamor, H., Pino, J., Bali, K
Jiang, J., Zhou, K., Dong, Z., Ye, K., Zhao, X., Wen, J.R.: Struct- GPT: A General Framework for Large Language Model to Reason over Structured Data. In: Bouamor, H., Pino, J., Bali, K. (eds.) Proceed- ings of the 2023 Conference on Empirical Methods in Natural Lan- guage Processing. pp. 9237–9251. Association for Computational Linguis- tics, Singapore (D...
-
[15]
Kato, M.P., Ohshima, H., Liu, Y.H., Chen, H.L.: NTCIR-16 Data Search 2 (2022)
2022
-
[16]
In: Proceedings of the 34th In- ternational Conference on Neural Information Processing Systems
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., Riedel, S., Kiela, D.: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In: Proceedings of the 34th In- ternational Conference on Neural Information Processing Systems. NeurIPS ’20, Curran Associates Inc., Red Hook,...
2020
-
[17]
Li, X., Lyu, T., Yang, Y., Shan, L., Yang, S., Zhang, L., Huang, Z., Liu, Q., Li, Y.: Escaping the Context Bottleneck: Active Context Curation for LLM Agents via Reinforcement Learning (2026)
2026
-
[18]
In: Kim, B., Yue, Y., Chaudhuri, S., Fragkiadaki, K., Khan, M., Sun, Y
Liu, X., Yu, H., Zhang, H., Xu, Y., Lei, X., Lai, H., Gu, Y., Ding, H., Men, K., Yang, K., Zhang, S., Deng, X., Zeng, A., Du, Z., Zhang, C., Shen, S., Zhang, T., Su, Y., Sun, H., Huang, M., Dong, Y., Tang, J.: AgentBench: Evaluating LLMs as Agents. In: Kim, B., Yue, Y., Chaudhuri, S., Fragkiadaki, K., Khan, M., Sun, Y. (eds.) International Conference on L...
2024
-
[19]
In: Bouamor, H., Pino, J., Bali, K
Liu, Y., Iter, D., Xu, Y., Wang, S., Xu, R., Zhu, C.: G-eval: NLG Evaluation using GPT-4 with Better Human Alignment. In: Bouamor, H., Pino, J., Bali, K. (eds.) Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 2511–2522. Association for Computational Linguistics, Singapore (Dec 2023), https://aclanthology.org/202...
2023
-
[20]
Information Services and Use37(1), 49–56 (2017)
Mons, B., Neylon, C., Velterop, J., Dumontier, M., da Silva Santos, L.O.B., Wilkin- son, M.D.: Cloudy, increasingly FAIR; revisiting the FAIR Data guiding principles for the European Open Science Cloud. Information Services and Use37(1), 49–56 (2017)
2017
-
[21]
WebGPT: Browser-assisted question-answering with human feedback
Nakano, R., Hilton, J., Balaji, S., Wu, J., Ouyang, L., Kim, C., Hesse, C., Jain, S., Kosaraju, V., Saunders, W., Jiang, X., Cobbe, K., Eloundou, T., Krueger, G., But- 18 S. Chen et al. ton, K., Knight, M., Chess, B., Schulman, J.: WebGPT: Browser-assisted question- answering with human feedback (2022), https://arxiv.org/abs/2112.09332
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Noy, N., Burgess, M., Brickley, D.: Google Dataset Search: Building a Search En- gineforDatasetsinanOpenWebEcosystem.In:TheWorldWideWebConference. p. 1365–1375. WWW ’19, Association for Computing Machinery, New York, NY, USA (2019), https://doi.org/10.1145/3308558.3313685
-
[23]
Overwijk, A., Xiong, C., Callan, J.: ClueWeb22: 10 Billion Web Docu- ments with Rich Information. In: Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. p. 3360–3362. SIGIR ’22, Association for Computing Machin- ery, New York, NY, USA (2022). https://doi.org/10.1145/3477495.3536321, https://doi...
-
[24]
IEEE Transactions on Knowledge and Data Engineering36, 7 (2024), 3580–3601
Pan, S., Luo, L., Wang, Y., Chen, C., Wang, J., Wu, X.: Unify- ing Large Language Models and Knowledge Graphs: A Roadmap. IEEE Transactions on Knowledge and Data Engineering36(7), 3580–3599 (2024). https://doi.org/10.1109/TKDE.2024.3352100
-
[25]
Park, J.S., O’Brien, J., Cai, C.J., Morris, M.R., Liang, P., Bernstein, M.S.: Generative agents: Interactive simulacra of human behavior. In: Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology. UIST ’23, Association for Computing Machinery, New York, NY, USA (2023), https://doi.org/10.1145/3586183.3606763
-
[26]
Patil, S.G., Zhang, T., Wang, X., Gonzalez, J.E.: Gorilla: Large Language Model ConnectedwithMassiveAPIs.AdvancesinNeuralInformationProcessingSystems 37, 126544–126565 (2024)
2024
-
[27]
In: The Twelfth International Conference on Learning Represen- tations
Qin, Y., Liang, S., Ye, Y., Zhu, K., Yan, L., Lu, Y., Lin, Y., Cong, X., Tang, X., Qian, B., et al.: ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. In: The Twelfth International Conference on Learning Represen- tations. ICLR ’24, https://openreview.net/forum?id=dHng2O0Jjr
-
[28]
In: Proceedings of the 37th International Conference on Neural Information Processing Systems
Schick, T., Dwivedi-Yu, J., Dessí, R., Raileanu, R., Lomeli, M., Hambro, E., Zettle- moyer, L., Cancedda, N., Scialom, T.: Toolformer: Language Models Can Teach Themselves to Use Tools. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. NeurIPS ’23, Curran Associates Inc., Red Hook, NY, USA
-
[29]
Harvard Data Science Review (Special Issue 4) (apr 2 2024), https://hdsr.mitpress.mit.edu/pub/psnc8zsr
Sostek, K., Russell, D.M., Goyal, N., Alrashed, T., Dugall, S., Noy, N.: Discov- ering Datasets on the Web Scale: Challenges and Recommendations for Google Dataset Search. Harvard Data Science Review (Special Issue 4) (apr 2 2024), https://hdsr.mitpress.mit.edu/pub/psnc8zsr
2024
-
[30]
In: Proceedings of the ACM on Web Conference 2025
Tan, J., Dou, Z., Wang, W., Wang, M., Chen, W., Wen, J.R.: HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems. In: Proceedings of the ACM on Web Conference 2025. p. 1733–1746. WWW ’25, Association for Computing Machinery, New York, NY, USA (2025), https://doi.org/10.1145/3696410.3714546
-
[31]
Scientific Data8(1), 192 (2021), https://doi.org/10.1038/s41597-021-00981-0
Tedersoo, L., Küngas, R., Oras, E., Köster, K., Eenmaa, H., Leijen, Ä., Pedaste, M., Raju, M., Astapova, A., Lukner, H., Kogermann, K., Sepp, T.: Data shar- ing practices and data availability upon request differ across scientific disciplines. Scientific Data8(1), 192 (2021), https://doi.org/10.1038/s41597-021-00981-0
-
[32]
Upadhyay, S., Pradeep, R., Thakur, N., Craswell, N., Lin, J.: UMBRELA: UMbrela is the (Open-Source Reproduction of the) Bing RELevance Assessor. arXiv:2406.06519 (2024) Do Agents Need Semantic Metadata? 19
-
[33]
In: Advances in Neural Information Processing Systems
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E., Le, Q., Zhou, D.: Chain- of-Thought Prompting Elicits Reasoning in Large Language Models. In: Advances in Neural Information Processing Systems. vol. 35, pp. 24824–24837 (2022)
2022
-
[34]
The FAIR Guiding Principles for scientific data management and stewardship
Wilkinson, M.D., Dumontier, M., Aalbersberg, I.J., Appleton, G., Axton, M., Baak, A., Blomberg, N., Boiten, J.W., da Silva Santos, L.B., Bourne, P.E., et al.: The FAIR Guiding Principles for Scientific Data Management and Stewardship. Scientific Data3(1), 1–9 (2016), https://doi.org/10.1038/sdata.2016.18
-
[35]
In: The Eleventh International Conference on Learning Representations (2023), https://openreview.net/forum?id=WE_vluYUL-X
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K.R., Cao, Y.: ReAct: Synergizing Reasoning and Acting in Language Models. In: The Eleventh International Conference on Learning Representations (2023), https://openreview.net/forum?id=WE_vluYUL-X
2023
-
[36]
In: Proceedings of the 37th International Con- ference on Neural Information Processing Systems
Zheng, L., Chiang, W.L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E.P., Zhang, H., Gonzalez, J.E., Stoica, I.: Judging LLM-as-a-judge with MT-bench and Chatbot Arena. In: Proceedings of the 37th International Con- ference on Neural Information Processing Systems. NeurIPS ’23, Curran Associates Inc., Red Hook, NY, USA (2023)
2023
-
[37]
(eds.) International Conference on Learning Representations
Zhou, S., Xu, F.F., Zhu, H., Zhou, X., Lo, R., Sridhar, A., Cheng, X., Ou, T., Bisk, Y., Fried, D., Alon, U., Neubig, G.: WebArena: A Realistic Web Environment for BuildingAutonomousAgents.In:Kim,B.,Yue,Y.,Chaudhuri,S.,Fragkiadaki,K., Khan, M., Sun, Y. (eds.) International Conference on Learning Representations. ICLR ’24, vol. 2024, pp. 15585–15606
2024
-
[38]
PLoS one15(9), e0239283 (2020), https://doi.org/10.1371/journal.pone.0239283
Zuiderwijk, A., Shinde, R., Jeng, W.: What Drives and Inhibits Researchers to Share and Use Open Research Data? A Systematic Literature Review to Analyze Factors Influencing Open Research Data Adoption. PLoS one15(9), e0239283 (2020), https://doi.org/10.1371/journal.pone.0239283
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.