Personal Visual Memory from Explicit and Implicit Evidence
Pith reviewed 2026-06-29 12:38 UTC · model grok-4.3
The pith
VisualMem augments text memory with a dedicated visual module that stores explicit and implicit personal facts from images using conversational context to resolve identity and ownership.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
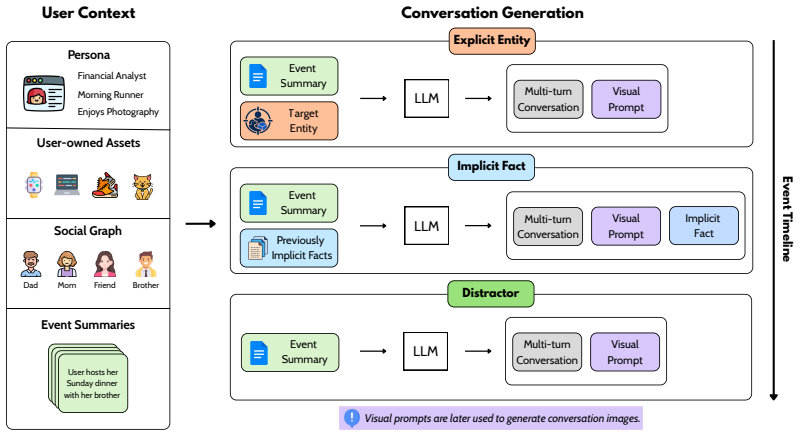
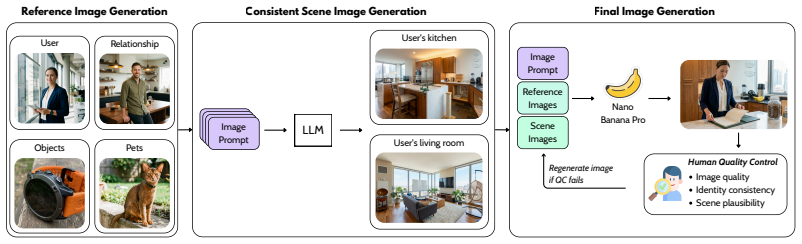
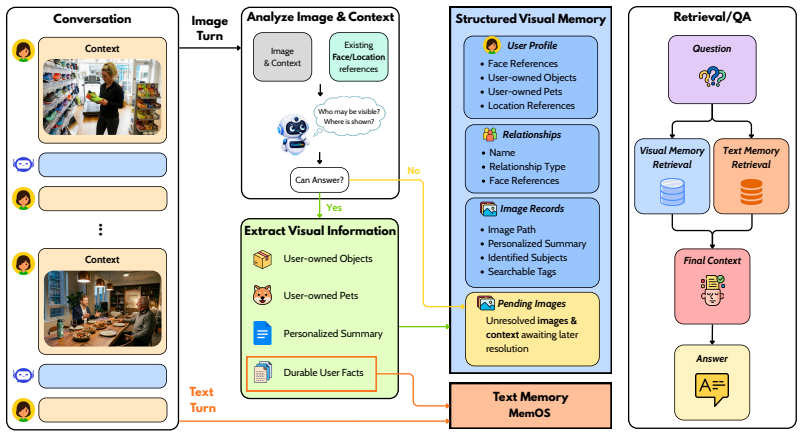
The paper establishes that personal visual memory requires explicit handling of both explicit evidence, such as recurring user-associated entities in images, and implicit evidence, such as latent user facts from visual or multimodal cues, because these cannot be recovered from text alone. VisualMem achieves this by maintaining a structured personal visual memory module alongside a text-memory backend, using conversational context to resolve identity, ownership, and durable user facts instead of reducing images to captions.
What carries the argument
The structured personal visual memory module that augments a text-memory backend and resolves identity, ownership, and durable user facts from images via conversational context.
If this is right
- VisualMem substantially outperforms prior memory systems on the personal visual memory benchmark.
- VisualMem remains competitive on standard text-memory benchmarks.
- Personal visual memory forms a distinct and important component of long-term memory for personalized AI agents.
- Handling images through context-based resolution rather than captions preserves user-specific details needed for later questions.
Where Pith is reading between the lines
- The same context-resolution approach could be tested on other multimodal inputs such as video clips to capture additional durable user facts.
- Current vision-language models may need targeted improvements in identity tracking to support this style of memory module at scale.
- Benchmarks that mix explicit and implicit visual evidence could be adapted to evaluate memory systems in domains like personal robotics or health monitoring.
Load-bearing premise
The benchmark questions require visual evidence that cannot be recovered from text alone and the visual module correctly resolves identity and ownership without errors from ambiguous images or context.
What would settle it
A collection of benchmark questions where all needed information appears in the text turns alone, or a set of images where the visual module produces incorrect identity or ownership resolutions due to ambiguity.
Figures













read the original abstract
Long-term memory is increasingly important for personalized AI agents, yet existing benchmarks and methods remain largely text-centric. Even when images are included, the user-specific information needed for later questions is typically recoverable from text alone, and most memory systems reduce image turns to generic captions. Yet images often carry personal information that text rarely states -- both explicit evidence, such as recurring user-associated entities, and implicit evidence, such as latent user facts inferred from visual or multimodal cues. We introduce a benchmark for personal visual memory that targets both forms of evidence, and propose VisualMem, a hybrid visual--text architecture that augments a text-memory backend with a structured personal visual memory module. Rather than collapsing images into captions, VisualMem uses conversational context to resolve identity, ownership, and durable user facts. Experiments show that VisualMem substantially outperforms prior memory systems on our benchmark while remaining competitive on standard text-memory benchmarks, indicating that personal visual memory is a distinct and important component of long-term memory for personalized AI agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing memory systems for personalized AI agents are largely text-centric and reduce images to generic captions, missing personal information in explicit (user-associated entities) and implicit (latent user facts) visual evidence. It introduces a new benchmark targeting both forms of evidence, proposes VisualMem as a hybrid visual-text architecture augmenting a text-memory backend with a structured personal visual memory module that resolves identity, ownership, and durable facts from conversational context, and reports that VisualMem substantially outperforms prior memory systems on the new benchmark while remaining competitive on standard text-memory benchmarks.
Significance. If the benchmark is shown to contain questions whose answers depend on visual evidence not recoverable from text or captions, the result would establish personal visual memory as a distinct and important component for long-term memory in multimodal agents, moving beyond caption-based approaches. The work provides a new benchmark and architecture direction, though its impact hinges on validation of the benchmark's visual dependency.
major comments (1)
- [Benchmark description] Benchmark construction (as described in the abstract and implied methods): no concrete protocol, question examples, or ablation is provided showing that a non-trivial fraction of questions cannot be answered from text context alone or that text-only baselines fail on the visual subset. This is load-bearing for the central claim that performance gains demonstrate a distinct visual memory module rather than improved multimodal integration.
minor comments (1)
- The abstract asserts 'substantial outperformance' without naming specific baselines, metrics, or statistical significance; adding these details would strengthen the experimental claim even if moved to the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the emphasis on validating the benchmark's visual dependency. We address the major comment below and commit to revisions that directly strengthen the evidence for the central claim.
read point-by-point responses
-
Referee: [Benchmark description] Benchmark construction (as described in the abstract and implied methods): no concrete protocol, question examples, or ablation is provided showing that a non-trivial fraction of questions cannot be answered from text context alone or that text-only baselines fail on the visual subset. This is load-bearing for the central claim that performance gains demonstrate a distinct visual memory module rather than improved multimodal integration.
Authors: We agree that the current manuscript description is insufficient to establish this point rigorously. The abstract is necessarily high-level, and the methods section does not yet contain the requested concrete protocol, question examples, or ablation. In the revised version we will add: (1) an explicit benchmark-construction protocol with sampling criteria that isolate visual-dependent questions, (2) representative question examples paired with their text-only and visual-only variants, and (3) an ablation in which text-only memory baselines are evaluated on the visual-evidence subset, quantifying the fraction of questions that cannot be answered from text or captions alone. These additions will directly support the claim that performance gains arise from the distinct visual memory module. revision: yes
Circularity Check
No significant circularity; paper is empirical with no derivation chain
full rationale
The manuscript presents an empirical contribution: a new benchmark targeting personal visual memory and a hybrid VisualMem architecture evaluated via performance comparisons on that benchmark plus standard text-memory tasks. No equations, parameters fitted to subsets then renamed as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text or abstract. The central claim (VisualMem outperforms priors on the visual benchmark while remaining competitive on text benchmarks) is supported by external experimental results rather than any reduction of outputs to inputs by construction. This is the normal case of a self-contained empirical paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Images in conversations often contain personal information (explicit entities or implicit facts) that cannot be recovered from accompanying text alone.
invented entities (1)
-
structured personal visual memory module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Evaluating very long-term conversational memory of llm agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851–13870, 2024
2024
-
[2]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- memeval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Bowen Jiang, Yuan Yuan, Maohao Shen, Zhuoqun Hao, Zhangchen Xu, Zichen Chen, Ziyi Liu, Anvesh Rao Vijjini, Jiashu He, Hanchao Yu, et al. Personamem-v2: Towards person- alized intelligence via learning implicit user personas and agentic memory.arXiv preprint arXiv:2512.06688, 2025
-
[4]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
MemOS: A Memory OS for AI System
Zhiyu Li, Chenyang Xi, Chunyu Li, Ding Chen, Boyu Chen, Shichao Song, Simin Niu, Hanyu Wang, Jiawei Yang, Chen Tang, et al. Memos: A memory os for ai system.arXiv preprint arXiv:2507.03724, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Eunhae Lee. Towards ethical personal ai applications: Practical considerations for ai assistants with long-term memory.arXiv preprint arXiv:2409.11192, 2024
-
[7]
Private attribute inference from images with vision-language models.Advances in Neural Information Processing Systems, 37:103619–103651, 2024
Batuhan Tömekçe, Mark Vero, Robin Staab, and Martin Vechev. Private attribute inference from images with vision-language models.Advances in Neural Information Processing Systems, 37:103619–103651, 2024
2024
-
[8]
Imagine yourself: Tuning-free personalized image generation.arXiv preprint arXiv:2409.13346, 2024
Zecheng He, Bo Sun, Felix Juefei-Xu, Haoyu Ma, Ankit Ramchandani, Vincent Cheung, Siddharth Shah, Anmol Kalia, Harihar Subramanyam, Alireza Zareian, et al. Imagine yourself: Tuning-free personalized image generation.arXiv preprint arXiv:2409.13346, 2024
-
[9]
Personalized representation from personalized generation.ArXiv, abs/2412.16156, 2024
Shobhita Sundaram, Julia Chae, Yonglong Tian, Sara Beery, and Phillip Isola. Personalized representation from personalized generation.ArXiv, abs/2412.16156, 2024
-
[10]
Yuang Peng, Yuxin Cui, Haomiao Tang, Zekun Qi, Runpei Dong, Jing Bai, Chunrui Han, Zheng Ge, Xiangyu Zhang, and Shu-Tao Xia. Dreambench++: A human-aligned benchmark for personalized image generation.arXiv preprint arXiv:2406.16855, 2024
-
[11]
Memorybank: Enhancing large language models with long-term memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 19724–19731, 2024
2024
-
[12]
Perltqa: A personal long-term memory dataset for memory clas- sification, retrieval, and fusion in question answering
Yiming Du, Hongru Wang, Zhengyi Zhao, Bin Liang, Baojun Wang, Wanjun Zhong, Zezhong Wang, and Kam-Fai Wong. Perltqa: A personal long-term memory dataset for memory clas- sification, retrieval, and fusion in question answering. InProceedings of the 10th SIGHAN Workshop on Chinese Language Processing (SIGHAN-10), pages 152–164, 2024
2024
-
[13]
Needle in a multimodal haystack.Advances in Neural Information Processing Systems, 37:20540–20565, 2024
Weiyun Wang, Shuibo Zhang, Yiming Ren, Yuchen Duan, Tiantong Li, Shuo Liu, Mengkang Hu, Zhe Chen, Kaipeng Zhang, Lewei Lu, et al. Needle in a multimodal haystack.Advances in Neural Information Processing Systems, 37:20540–20565, 2024
2024
-
[14]
Multimodal needle in a haystack: Benchmarking long- context capability of multimodal large language models
Hengyi Wang, Haizhou Shi, Shiwei Tan, Weiyi Qin, Wenyuan Wang, Tunyu Zhang, Akshay Nambi, Tanuja Ganu, and Hao Wang. Multimodal needle in a haystack: Benchmarking long- context capability of multimodal large language models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human ...
2025
-
[15]
Visual haystacks: A vision-centric needle-in-a-haystack benchmark
Tsung-Han Wu, Giscard Biamby, Jerome Quenum, Ritwik Gupta, Joseph E Gonzalez, Trevor Darrell, and David M Chan. Visual haystacks: A vision-centric needle-in-a-haystack benchmark. arXiv preprint arXiv:2407.13766, 2024. 10
-
[16]
Retrieval augmenta- tion reduces hallucination in conversation
Kurt Shuster, Spencer Poff, Moya Chen, Douwe Kiela, and Jason Weston. Retrieval augmenta- tion reduces hallucination in conversation. InFindings of the Association for Computational Linguistics: EMNLP 2021, pages 3784–3803, 2021
2021
-
[17]
In-context retrieval-augmented language models.Transactions of the Association for Computational Linguistics, 11:1316–1331, 2023
Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. In-context retrieval-augmented language models.Transactions of the Association for Computational Linguistics, 11:1316–1331, 2023
2023
-
[18]
Replug: Retrieval-augmented black-box language models
Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Richard James, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. Replug: Retrieval-augmented black-box language models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8371–8384, 2024
2024
-
[19]
Meminsight: Autonomous memory augmentation for llm agents
Rana Salama, Jason Cai, Michelle Yuan, Anna Currey, Monica Sunkara, Yi Zhang, and Yassine Benajiba. Meminsight: Autonomous memory augmentation for llm agents. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 33124–33140, 2025
2025
-
[20]
MemVerse: Multimodal Memory for Lifelong Learning Agents
Junming Liu, Yifei Sun, Weihua Cheng, Haodong Lei, Yirong Chen, Licheng Wen, Xuemeng Yang, Daocheng Fu, Pinlong Cai, Nianchen Deng, et al. Memverse: Multimodal memory for lifelong learning agents.arXiv preprint arXiv:2512.03627, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
LightMem: Lightweight and Efficient Memory-Augmented Generation
Jizhan Fang, Xinle Deng, Haoming Xu, Ziyan Jiang, Yuqi Tang, Ziwen Xu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, et al. Lightmem: Lightweight and efficient memory- augmented generation.arXiv preprint arXiv:2510.18866, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
SimpleMem: Efficient Lifelong Memory for LLM Agents
Jiaqi Liu, Yaofeng Su, Peng Xia, Siwei Han, Zeyu Zheng, Cihang Xie, Mingyu Ding, and Huaxiu Yao. Simplemem: Efficient lifelong memory for llm agents.arXiv preprint arXiv:2601.02553, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Memgpt: towards llms as operating systems
Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonza- lez. Memgpt: towards llms as operating systems. 2023
2023
-
[24]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Self-rag: Learn- ing to retrieve, generate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learn- ing to retrieve, generate, and critique through self-reflection. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[26]
From RAG to Memory: Non-Parametric Continual Learning for Large Language Models
Bernal Jiménez Gutiérrez, Yiheng Shu, Weijian Qi, Sizhe Zhou, and Yu Su. From rag to memory: Non-parametric continual learning for large language models.arXiv preprint arXiv:2502.14802, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Personalized multimodal large language models: A survey.arXiv preprint arXiv:2412.02142, 2024
Junda Wu, Hanjia Lyu, Yu Xia, Zhehao Zhang, Joe Barrow, Ishita Kumar, Mehrnoosh Mirtaheri, Hongjie Chen, Ryan A Rossi, Franck Dernoncourt, et al. Personalized multimodal large language models: A survey.arXiv preprint arXiv:2412.02142, 2024
-
[28]
Myvlm: Personalizing vlms for user-specific queries
Yuval Alaluf, Elad Richardson, Sergey Tulyakov, Kfir Aberman, and Daniel Cohen-Or. Myvlm: Personalizing vlms for user-specific queries. InEuropean Conference on Computer Vision, pages 73–91. Springer, 2024
2024
-
[29]
Yo’llava: Your personalized language and vision assistant.Advances in Neural Information Processing Systems, 37:40913–40951, 2024
Thao Nguyen, Haotian Liu, Yuheng Li, Mu Cai, Utkarsh Ojha, and Yong Jae Lee. Yo’llava: Your personalized language and vision assistant.Advances in Neural Information Processing Systems, 37:40913–40951, 2024
2024
-
[30]
Yo’chameleon: Personalized vision and language generation.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
Thao Nguyen, Krishna Kumar Singh, Jing Shi, Trung Bui, Yong Jae Lee, and Yuheng Li. Yo’chameleon: Personalized vision and language generation.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[31]
Rap: Retrieval- augmented personalization for multimodal large language models
Haoran Hao, Jiaming Han, Changsheng Li, Yu-Feng Li, and Xiangyu Yue. Rap: Retrieval- augmented personalization for multimodal large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14538–14548, 2025. 11
2025
-
[32]
Training- free personalization via retrieval and reasoning on fingerprints
Deepayan Das, Davide Talon, Yiming Wang, Massimiliano Mancini, and Elisa Ricci. Training- free personalization via retrieval and reasoning on fingerprints. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9683–9692, 2025
2025
-
[33]
PersonaVLM: Long-Term Personalized Multimodal LLMs
Chang Nie, Chaoyou Fu, Yifan Zhang, Haihua Yang, and Caifeng Shan. Personavlm: Long-term personalized multimodal llms.arXiv preprint arXiv:2604.13074, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Tameing long contexts in personalization: Towards training-free and state-aware mllm personalized assistant
Rongpei Hong, Jian Lang, Ting Zhong, Yong Wang, and Fan Zhou. Tameing long contexts in personalization: Towards training-free and state-aware mllm personalized assistant. In Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pages 452–463, 2026
2026
-
[35]
Scaling Synthetic Data Creation with 1,000,000,000 Personas
T Ge, X Chan, X Wang, D Yu, H Mi, and D Yu. Scaling synthetic data creation with 1,000,000,000 personas. arxiv 2024.arXiv preprint arXiv:2406.20094
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Bowen Jiang, Zhuoqun Hao, Young-Min Cho, Bryan Li, Yuan Yuan, Sihao Chen, Lyle Ungar, Camillo J Taylor, and Dan Roth. Know me, respond to me: Benchmarking llms for dynamic user profiling and personalized responses at scale.arXiv preprint arXiv:2504.14225, 2025. 12 A Broader Impacts This work may have positive impact by improving long-term multimodal memor...
-
[37]
You must generate a heterogeneous social circle including: •Family & Romantic:Parents, siblings, cousins, spouse/partner, or children
Rich Diversity & Balance:Do NOT fill the list with only coworkers. You must generate a heterogeneous social circle including: •Family & Romantic:Parents, siblings, cousins, spouse/partner, or children. •Social & Community:Childhood friends, college roommates, neighbors, gym/hobby acquaintances. •Professional & Academic:Mentors, direct reports, investors, ...
-
[38]
social_relationship
Visuals:The detailed_identity field must be a photorealistic image prompt describing physical appearance, outfit, and environment. Do not describe personality here. The person is looking towards the camera. Output Format:Return ONLY valid JSON. { "social_relationship": { "{idx_persona}_0": { "name": "[Name]", "description": "[Age, job, and why they intera...
-
[39]
2.Brainstorm Assets:Create a diverse list of 5 to 8 distinct assets
Analyze the Persona:Review the user’s occupation, hobbies, income, and living situation to determine what items or pets they would realistically own. 2.Brainstorm Assets:Create a diverse list of 5 to 8 distinct assets. •Objects:Include items like specific vehicles, customized electronics, favorite accessories, or hobby equipment. •Agents:Include pets, e.g...
-
[40]
assets": [ {
Visual Specificity:For every asset, provide a dense, hyper-realistic physical description. Include colors, textures, materials, size, and distinctive marks, e.g., scratches, stickers, or unique patterns, so it can be consistently rendered in text-to-image prompts. Output Format:Return ONLY valid JSON. { "assets": [ { "asset_id": "asset_01", "name": "[Shor...
-
[41]
question_hint
Strict Character Tags:Inside the <image> tags, you MUST NOT use names. Substitute them exactly as provided, e.g., <main>or {target_person_id}. Output Format:Return ONLY valid JSON. { "question_hint": { "target_person_id": "{target_person_id}", "identity_concealment_check": "[Briefly quote the text showing how identity was handled, e.g., ’Look at my outfit...
-
[42]
question_hint
Visual Content & Clothing:You MUST describe the clothing/outfit for every character present in the tag, e.g., <0_1> wearing a lab coat. Do not describe facial features. Output Format:Return ONLY valid JSON. { "question_hint": { "target_asset_id": "[Extract the asset_id from the Target Asset]", "generic_reference_used": "[The simple term used in the prompt...
-
[43]
question_hint
Visual Content & Clothing:Describe clothing/outfit, pose, action, and environment for every tagged character. Do NOT describe physical facial features. Output Format:Return ONLY valid JSON. { "question_hint": { "implicit_fact": "[The specific attribute, e.g., User plays Soccer]", "visual_proxy": "[The visual object, e.g., Muddy Cleats]", "textual_proxy": ...
-
[44]
conversation
Visual Content & Clothing:You MUST describe the clothing/outfit for every character present in the tag, e.g., <0_1> wearing a lab coat. Do not describe physical facial features. Output Format:Return ONLY valid JSON. { "conversation": [ {"role": "user", "content": "..."}, {"role": "assistant", "content": "..."}, ] } Figure 13: Prompt template for generatin...
-
[45]
variant_hint
Visual Content & Clothing:You MUST describe the clothing/outfit for every character present in the tag, e.g., <0_1> wearing a lab coat. Do not describe physical facial features. Output Format:Return ONLY valid JSON. { "variant_hint": { "variant_asset_id": "[Extract the variation_id from the Variant Asset]", "generic_reference_used": "[The simple term you ...
-
[46]
If the correct answer is a specific 15-word description, the traps must also be specific 15-word descriptions
Equal Specificity:All four options MUST have the same length, tone, and level of detail. If the correct answer is a specific 15-word description, the traps must also be specific 15-word descriptions. 4.No Context Matching:The correct option must not share synonyms or environmental clues with the question
-
[47]
The ground truth should be equally likely to be A, B, C, or D
Strict Randomization:Randomize which letter, A–D, contains the correct answer. The ground truth should be equally likely to be A, B, C, or D. 6.Determine Query Modality: •Text Only:User asks a question directly. •Image Based:User uploads a new image and asks a question about it. Formatting Rules for Query Image Prompt 1.Format:‘<image> [Visual Prompt] </image>’
-
[48]
questions
Tags:Use <main> or IDs, e.g., <0_0>, ONLY if the person is physically in the frame. If it is an object close-up, do not use tags. 3.Content:Describe clothing/environment if tags are used. Output Format:Return ONLY valid JSON. { "questions": [ { "id": 1, "type": "text", "query_image_prompt": null, "question": "[The natural language question without any tag...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.