AREA: Attribute Extraction and Aggregation for CLIP-Based Class-Incremental Learning
Pith reviewed 2026-06-29 13:38 UTC · model grok-4.3
The pith
Decomposing CLIP's visual-textual matching into attribute extraction and aggregation stages lets each be stabilized separately to limit forgetting when new classes arrive.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
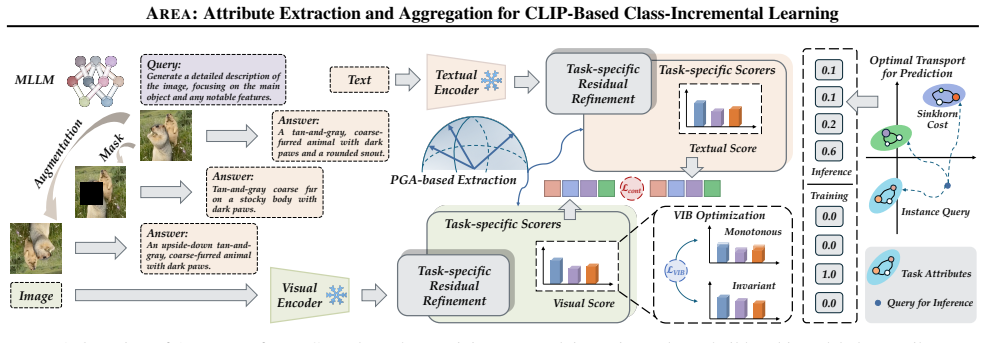
By treating the CLIP similarity computation as two separable stages, attribute extraction can be stabilized by anchoring class-level visual and textual attributes on the hyperspherical embedding space via principal geodesic analysis, while attribute aggregation can be stabilized by learning lightweight task-specific experts equipped with scoring and residual refinement under a variational information bottleneck; at inference, optimal transport routes predictions over the resulting task attribute manifolds, yielding higher accuracy than prior state-of-the-art CLIP-based class-incremental methods across standard benchmarks.
What carries the argument
The two-stage decomposition of CLIP matching into extraction (anchored by principal geodesic analysis on the hypersphere) and aggregation (handled by task-specific experts plus optimal-transport routing).
If this is right
- New classes can be added without storing or revisiting data from earlier tasks while retaining higher accuracy on those earlier tasks.
- Task-specific experts allow modular parameter updates that limit interference between successive tasks.
- Optimal transport routing selects relevant attribute manifolds at inference time, producing more concise predictions than single shared classifiers.
- The variational information bottleneck regularizer keeps the expert modules from overfitting to the attributes of the current task alone.
Where Pith is reading between the lines
- The same extraction-aggregation split could be tested on other vision-language models whose embeddings lie on hyperspheres.
- The routing step might be adapted to reduce memory use when many tasks must be kept active at once.
- If attribute manifolds turn out to be approximately linear, simpler linear routing could replace optimal transport with little loss.
- The approach suggests examining whether similar decomposition helps incremental learning when the base model is not CLIP but a different contrastive architecture.
Load-bearing premise
The visual-textual matching process in CLIP can be usefully decomposed into distinct attribute extraction and attribute aggregation stages whose biases can be independently stabilized using only current-task data without access to prior classes.
What would settle it
An experiment that removes the principal geodesic analysis anchoring and the task-expert modules, then measures whether accuracy on previous classes falls back to the level of a standard CLIP fine-tuning baseline when new classes are added.
Figures
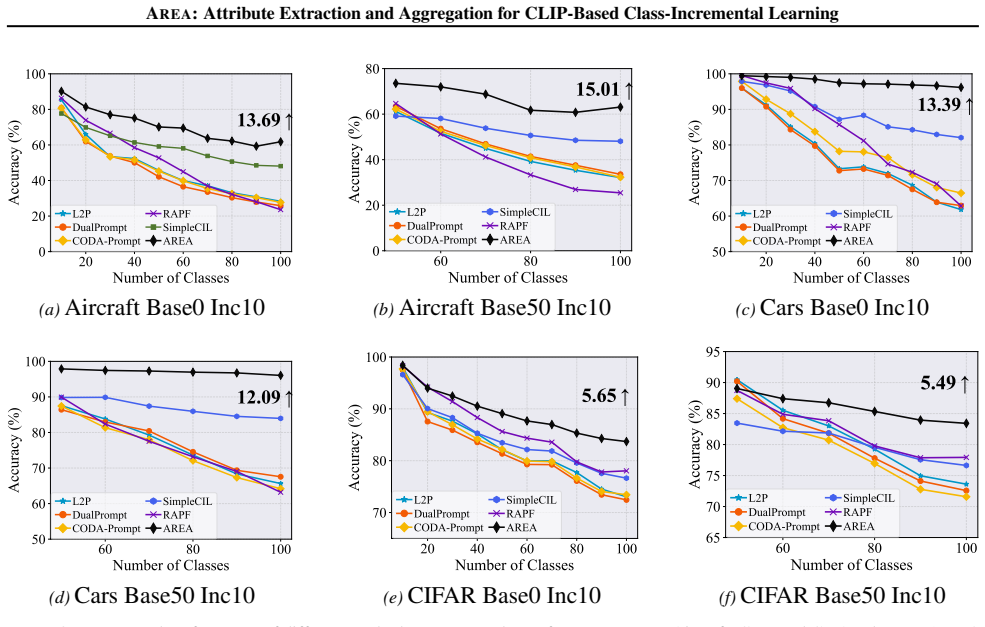
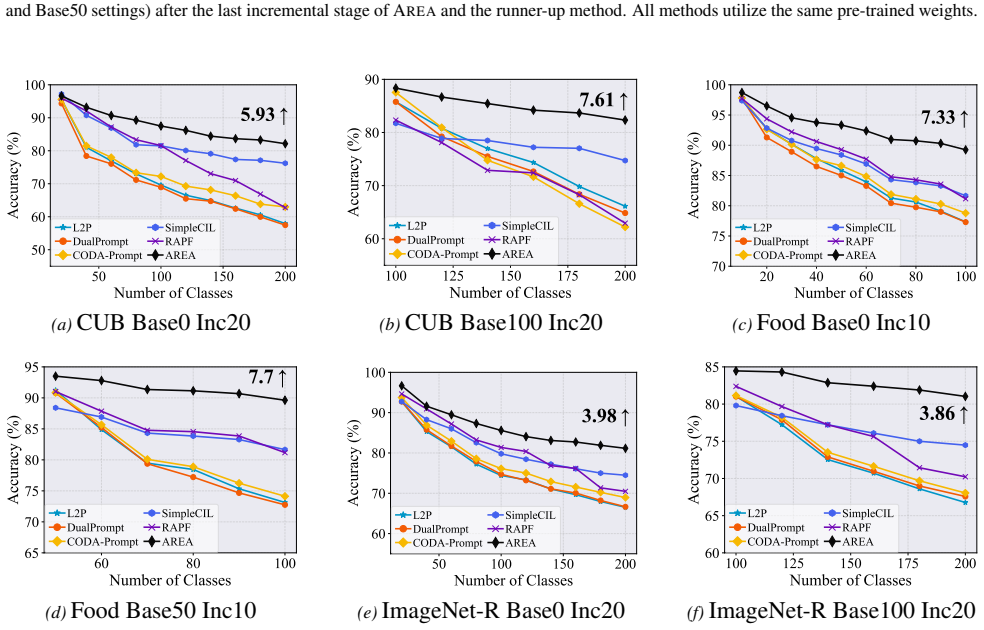
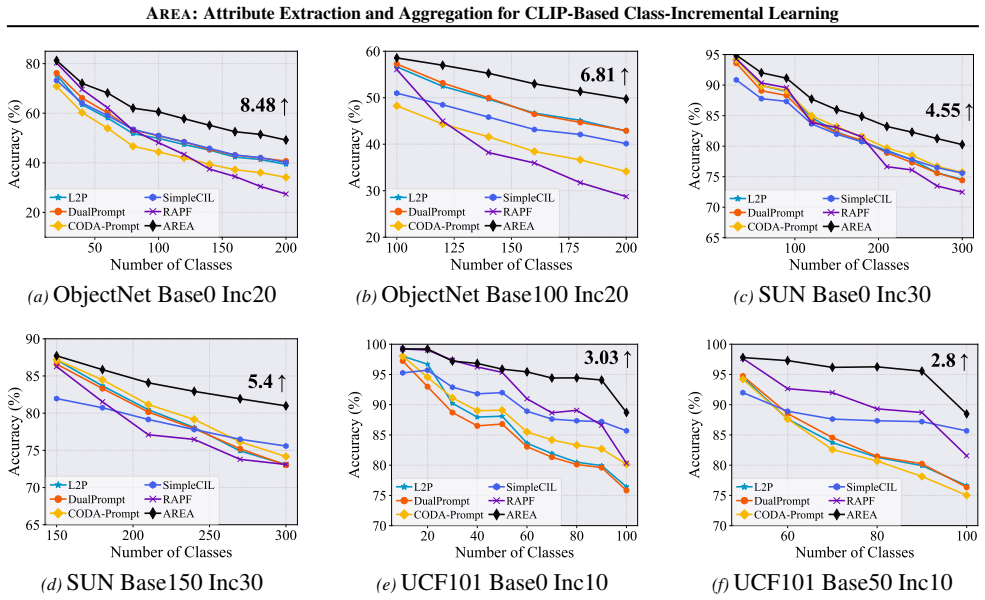
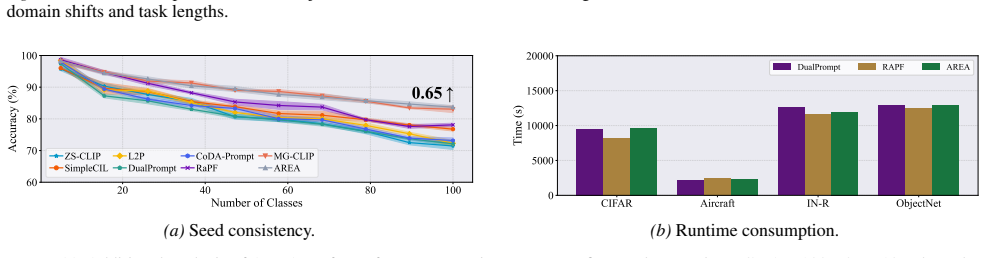
read the original abstract
Class-Incremental Learning (CIL) is important in building real-world learning systems. In CLIP-based CIL, the model performs classification by comparing similarity between visual and textual embeddings obtained from template prompts, e.g., ``a photo of a [CLASS]''. This seemingly monolithic matching process can be decomposed into two conceptually distinct stages: attribute extraction and attribute aggregation. For example, a model may recognize cat using attributes such as fur texture and whiskers. When learning a new class like car, the model must extract additional attributes like wheels and adjust how they are aggregated in the shared representation space. However, since only data from the current task is available, incremental updates can bias both attribute extraction and aggregation toward new classes, leading to catastrophic forgetting. Therefore, we propose AREA for attribute extraction and aggregation in CLIP-based CIL. To stabilize extraction, we anchor class-level visual and textual attributes on the hyperspherical embedding space via principal geodesic analysis. To stabilize aggregation, we learn lightweight task-specific experts with scoring and residual refinement, regularized by a variational information bottleneck objective. During inference, we perform routing over task attribute manifolds via optimal transport for more concise prediction. Experiments show that AREA consistently outperforms SOTA methods. Code is available at https://github.com/LAMDA-CL/ICML2026-AREA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AREA, a method for CLIP-based class-incremental learning that decomposes visual-textual similarity computation into attribute extraction and attribute aggregation stages. Extraction is stabilized by anchoring class-level visual and textual attributes via principal geodesic analysis on the hyperspherical embedding space. Aggregation is stabilized via lightweight task-specific experts employing scoring and residual refinement, regularized by a variational information bottleneck objective. Inference performs routing over task attribute manifolds using optimal transport. The paper claims that AREA consistently outperforms state-of-the-art methods in experiments while avoiding replay or access to prior classes.
Significance. If the decomposition into independently stabilizable stages holds and the PGA anchors plus VIB-regularized experts demonstrably isolate updates from prior-class interference, the work would offer a meaningful advance in replay-free CIL for vision-language models. The combination of hyperspherical anchoring and optimal-transport routing constitutes a technically distinctive approach that, if validated through ablations, could influence subsequent embedding-stabilization research.
major comments (2)
- [Abstract] Abstract: the central claim that attribute extraction and aggregation biases can be independently stabilized using only current-task data rests on an unverified decomposition; no derivation or ablation is supplied showing that PGA anchors computed on new-task features remain stable for prior classes or that VIB experts isolate aggregation parameters from extraction drift through the shared CLIP backbone.
- [Abstract] Abstract: the outperformance claim over SOTA methods is load-bearing yet unsupported by any reported experimental details, ablation results, or stability metrics for prior classes, rendering it impossible to assess whether the proposed stabilizations actually deliver the claimed gains without replay.
minor comments (1)
- [Abstract] The abstract would benefit from a concise statement of the precise form of the variational information bottleneck objective and the optimal-transport cost used for routing.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on our work. We address each major comment point by point below, clarifying the manuscript's content and indicating where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that attribute extraction and aggregation biases can be independently stabilized using only current-task data rests on an unverified decomposition; no derivation or ablation is supplied showing that PGA anchors computed on new-task features remain stable for prior classes or that VIB experts isolate aggregation parameters from extraction drift through the shared CLIP backbone.
Authors: The decomposition is introduced as a conceptual framing in the introduction and formalized in Section 3.1 based on the additive structure of attributes within CLIP's hyperspherical embeddings. Supporting empirical evidence appears in Sections 4.3 and 4.4, where ablations measure prior-class similarity preservation under PGA anchors computed only on current-task data and quantify reduced parameter drift in aggregation experts under the VIB objective. A formal derivation of statistical independence is not provided, as the approach is driven by empirical stabilization results rather than theoretical guarantees. We will revise the abstract to explicitly reference these stability ablations. revision: yes
-
Referee: [Abstract] Abstract: the outperformance claim over SOTA methods is load-bearing yet unsupported by any reported experimental details, ablation results, or stability metrics for prior classes, rendering it impossible to assess whether the proposed stabilizations actually deliver the claimed gains without replay.
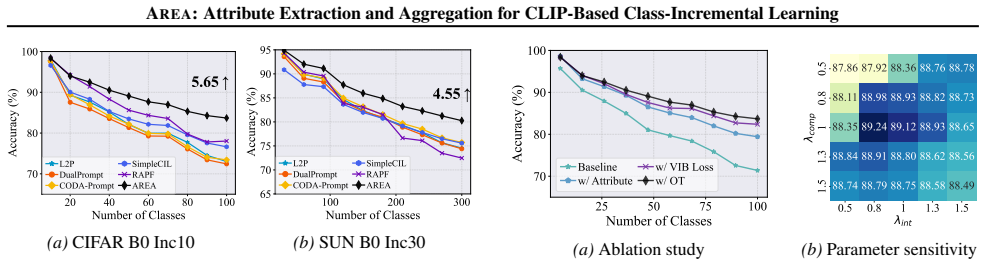
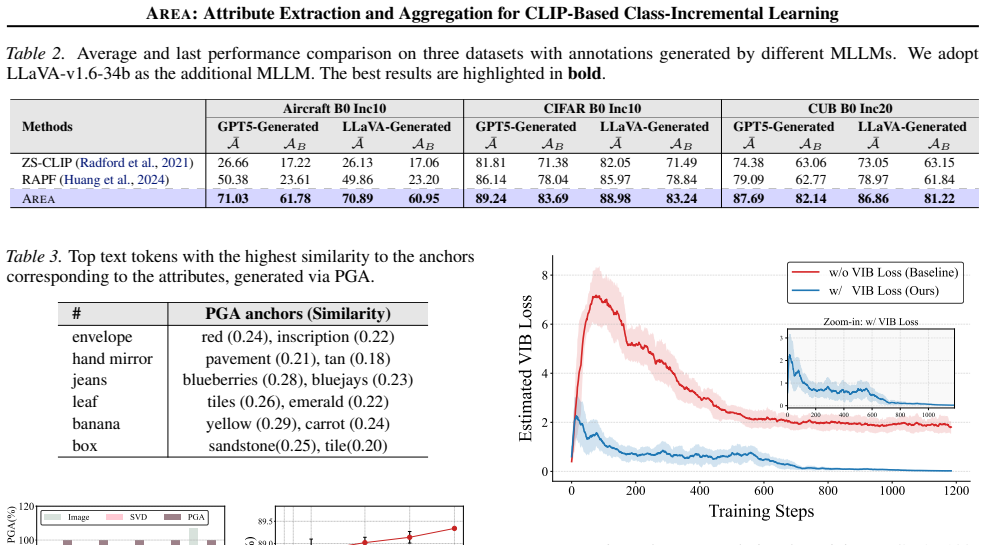
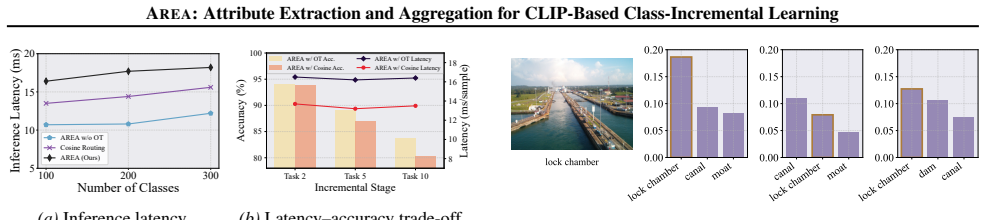
Authors: Detailed experimental comparisons to SOTA methods, ablation studies isolating each component, and stability metrics (including per-class forgetting rates on prior tasks) are reported in Section 4, with quantitative results in Tables 1–4 and Figures 2–5 across multiple CIL benchmarks. These demonstrate consistent gains without replay. We agree the abstract would be improved by summarizing key performance numbers and will revise it to include these highlights while retaining the reference to the full experimental section. revision: yes
Circularity Check
No circularity: derivation relies on proposed stabilizations without self-referential reduction to inputs
full rationale
The provided abstract and description present a conceptual decomposition of CLIP similarity into extraction (stabilized by PGA on hypersphere) and aggregation (stabilized by task experts + VIB + OT routing) stages, with empirical outperformance claimed. No equations, fitted parameters renamed as predictions, or self-citations are quoted that would make any claimed stabilization equivalent to its own inputs by construction. The methods are introduced as independent stabilizations on current-task data; absent explicit reductions in the text, the chain does not collapse to tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., and Zhou, J. Qwen-vl: A versatile vision- language model for understanding, localization, text read- ing, and beyond.arXiv preprint arXiv:2308.12966,
work page internal anchor Pith review Pith/arXiv arXiv
- [2]
-
[3]
Fine-Grained Visual Classification of Aircraft
10 AREA: Attribute Extraction and Aggregation for CLIP-Based Class-Incremental Learning Maji, S., Rahtu, E., Kannala, J., Blaschko, M., and Vedaldi, A. Fine-grained visual classification of aircraft.arXiv preprint arXiv:1306.5151,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Rebuffi, S.-A., Kolesnikov, A., Sperl, G., and Lampert, C. H. icarl: Incremental classifier and representation learning. InCVPR, pp. 2001–2010,
2001
-
[5]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Soomro, K., Zamir, A. R., and Shah, M. Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Sun, H. and Zhou, D.-W. C3box: A clip-based class-incremental learning toolbox.arXiv preprint arXiv:2601.20852,
-
[7]
Clip model is an efficient continual learner.arXiv preprint arXiv:2210.03114,
Thengane, V ., Khan, S., Hayat, M., and Khan, F. Clip model is an efficient continual learner.arXiv preprint arXiv:2210.03114,
-
[8]
The Caltech-UCSD Birds-200-2011 Dataset
Wah, C., Branson, S., Welinder, P., Perona, P., and Belongie, S. The Caltech-UCSD Birds-200-2011 Dataset. Tech- nical Report CNS-TR-2011-001, California Institute of Technology,
2011
-
[9]
HERMAN: Hierarchical Representation Matching for CLIP-based Class-Incremental Learning
Wang, Z., Zhang, Z., Ebrahimi, S., Sun, R., Zhang, H., Lee, C., Ren, X., Su, G., Perot, V ., Dy, J. G., and Pfister, T. Dualprompt: Complementary prompting for rehearsal- free continual learning. InECCV, pp. 631–648, 2022a. Wang, Z., Zhang, Z., Lee, C.-Y ., Zhang, H., Sun, R., Ren, X., Su, G., Perot, V ., Dy, J., and Pfister, T. Learning to prompt for con...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
SAME: Stabilized Mixture-of-Experts for Multimodal Continual Instruction Tuning
Xie, Z.-H., Tang, J.-T., Shi, Y .-C., Ye, H.-J., Zhan, D.-C., and Zhou, D.-W. Same: Stabilized mixture-of-experts for multimodal continual instruction tuning.arXiv preprint arXiv:2602.01990, 2026a. 11 AREA: Attribute Extraction and Aggregation for CLIP-Based Class-Incremental Learning Xie, Z.-H., Wang, Y ., Sun, H., Ye, H.-J., Zhan, D.-C., and Zhou, D.-W....
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Meta-transformer: A uni- fied framework for multimodal learning.arXiv preprint arXiv:2307.10802,
Zhang, Y ., Gong, K., Zhang, K., Li, H., Qiao, Y ., Ouyang, W., and Yue, X. Meta-transformer: A uni- fied framework for multimodal learning.arXiv preprint arXiv:2307.10802,
-
[12]
As shown in Tab. 8, replacing PGA with PCA reduces both semantic alignment and final continual learning accuracy, demonstrating the importance of respecting the hyperspherical geometry of CLIP representations. The two simplified inference variants also underperform the full model. Using similarity-only prediction removes the routing confidence provided by...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.