PEFT-Arena: Understanding Parameter-Efficient Finetuning from a Stability-Plasticity Perspective
Pith reviewed 2026-06-29 13:56 UTC · model grok-4.3
The pith
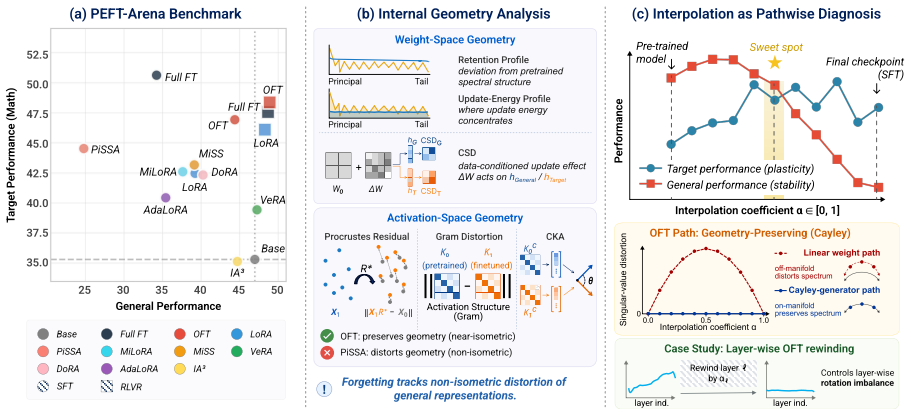
PEFT methods exhibit distinct stability-plasticity profiles, with orthogonal finetuning reaching the best Pareto frontier under matched parameter budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
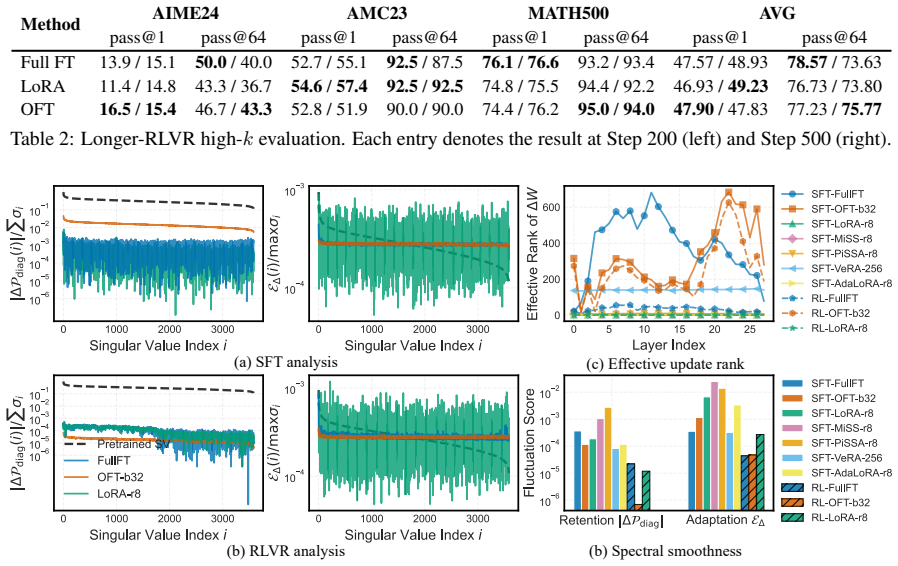
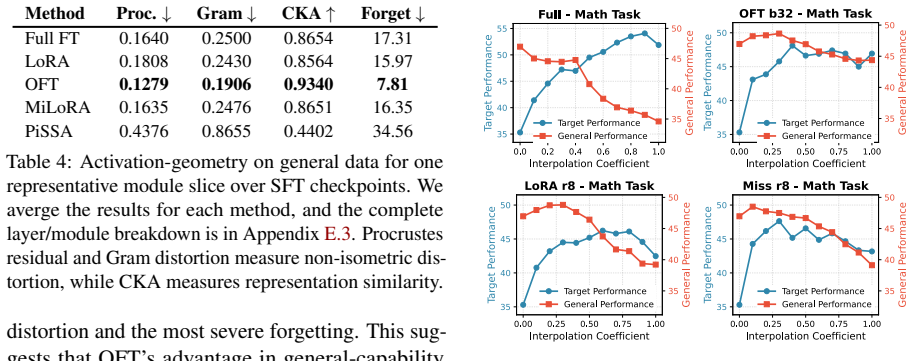
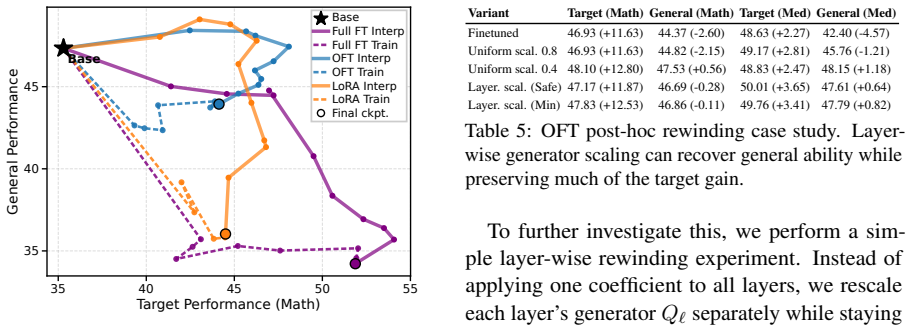
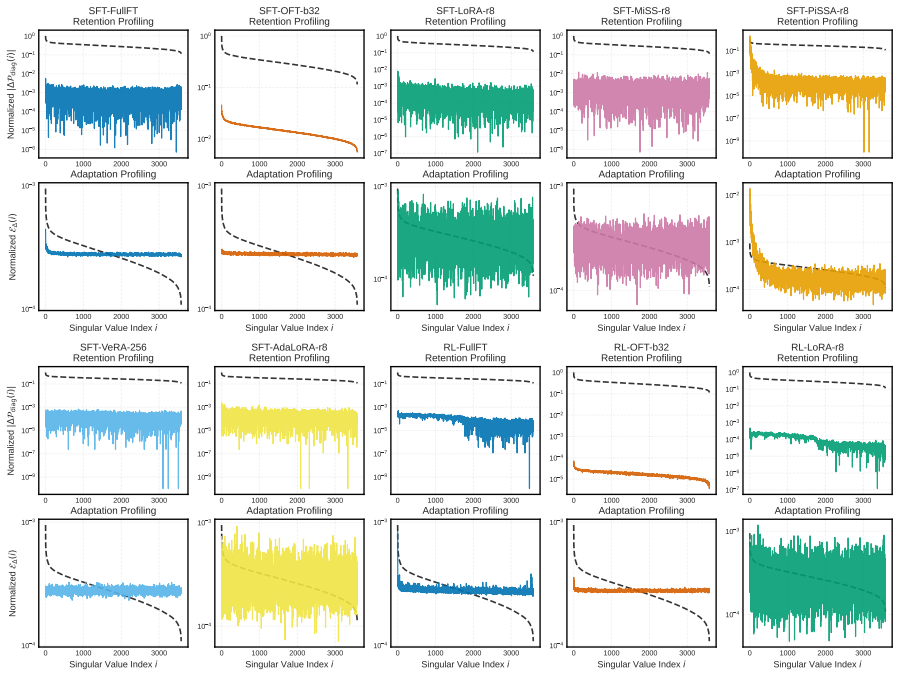
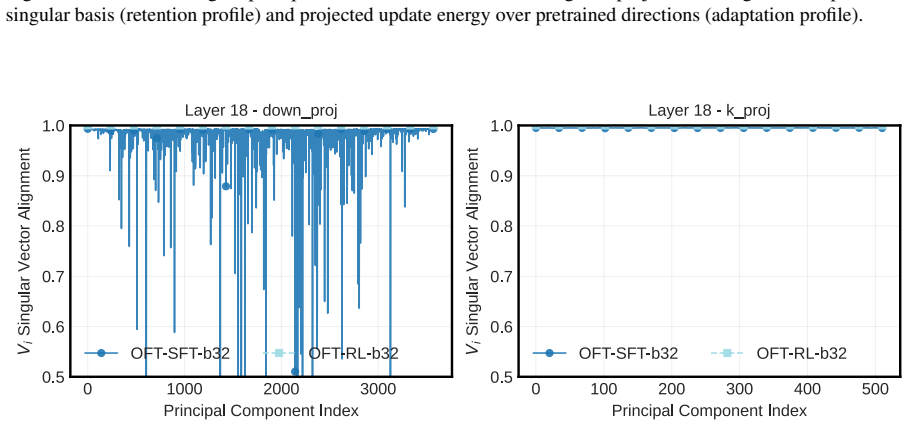
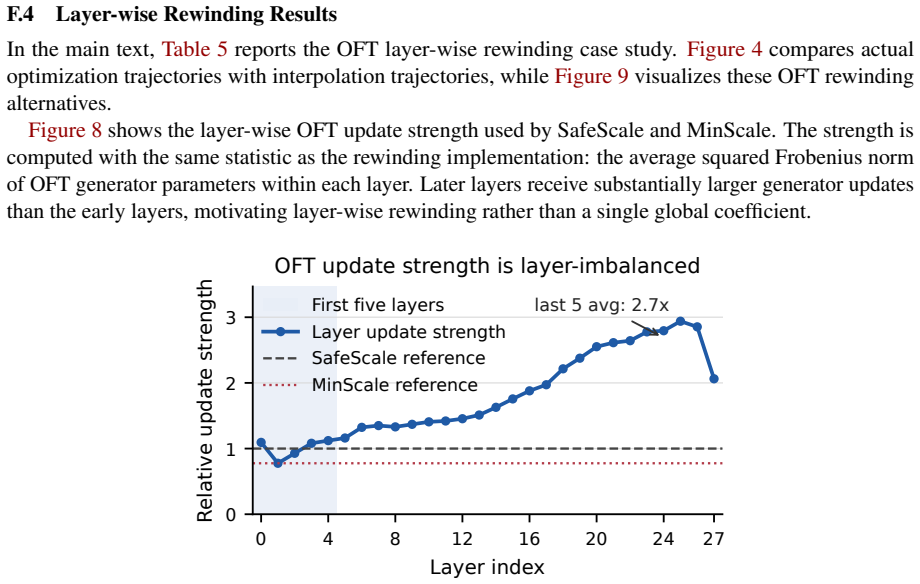
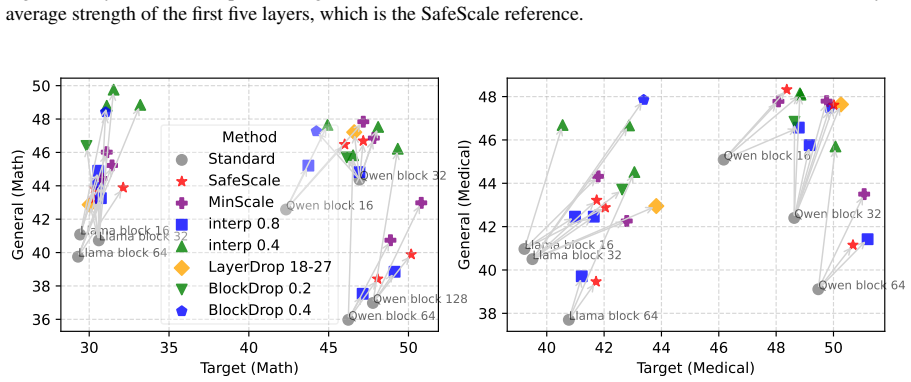
PEFT-Arena jointly tracks downstream accuracy and retention of general capabilities to expose the stability-plasticity dilemma in finetuning. Across methods, distinct profiles appear on this trade-off; orthogonal finetuning occupies the most favorable Pareto frontier at comparable parameter budgets. Weight-space spectral analysis shows how each parameterization interacts with the pretrained singular-value structure. Activation-space retention metrics tie forgetting to non-isometric distortion of general-capability representations. Supervised finetuning checkpoints frequently overshoot a superior earlier operating point, which path-wise rewinding can recover post hoc.
What carries the argument
PEFT-Arena benchmark that jointly measures downstream performance and general capability retention to quantify the stability-plasticity trade-off.
If this is right
- Different PEFT methods produce reliably distinct stability-plasticity profiles.
- Orthogonal finetuning achieves the strongest combined downstream gain and retention under matched parameter budgets.
- Forgetting correlates with non-isometric distortion of general representations in activation space.
- Spectral properties of updates in weight space determine compatibility with pretrained singular-value structure.
- Final supervised finetuning checkpoints commonly overshoot an earlier point of better retention that path-wise rewinding can restore.
Where Pith is reading between the lines
- When retention of broad capabilities matters more than peak task accuracy, orthogonal methods become the default choice under fixed budgets.
- The geometric diagnostics could be used to screen candidate PEFT designs before full benchmark runs.
- Trajectory monitoring during training might replace single final-checkpoint evaluation as standard practice.
- The same stability-plasticity lens could be applied to continual learning settings beyond single-task adaptation.
Load-bearing premise
The chosen downstream performance and capability retention metrics accurately reflect the stability-plasticity trade-off without being distorted by task selection, model scale, or evaluation protocol details.
What would settle it
Re-running PEFT-Arena on a new collection of tasks or at a different model scale and obtaining a substantially altered ordering of methods along the Pareto frontier between downstream gain and retention loss.
Figures
read the original abstract
Parameter-efficient finetuning (PEFT) has become the standard approach for adapting large language models, yet evaluations largely emphasize downstream accuracy while overlooking the retention of pretrained capabilities. We argue that PEFT should be assessed through the stability-plasticity dilemma: the trade-off between target-task adaptation and resistance to forgetting. We introduce PEFT-Arena, a benchmark that jointly measures downstream performance and general capability retention. Across methods, we find distinct stability-plasticity profiles; under comparable parameter budgets, orthogonal finetuning achieves the most favorable Pareto frontier. To explain these differences, we analyze PEFT updates from two geometric perspectives. In weight space, spectral analysis reveals how parameterizations interact with the pretrained singular-value structure. In activation space, retention metrics show whether finetuning preserves or distorts general-capability representations, with forgetting linked to non-isometric representation distortion. Finally, an analysis shows that final SFT checkpoints often overshoot a better target-retention operating point. Inspired by this, we present case studies of a post-hoc improvement with path-wise rewinding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PEFT-Arena, a benchmark jointly measuring downstream task performance and retention of general capabilities to evaluate PEFT methods through the stability-plasticity trade-off. It reports that methods exhibit distinct profiles and that, under comparable parameter budgets, orthogonal finetuning achieves the most favorable Pareto frontier. Geometric analyses in weight space (spectral structure) and activation space (isometry/distortion) are used to explain differences, with an additional observation that final SFT checkpoints often overshoot better operating points and case studies of path-wise rewinding for post-hoc gains.
Significance. If the empirical ordering holds under controlled conditions, the work supplies a useful shift in PEFT evaluation away from accuracy-only metrics toward explicit trade-off measurement, together with geometric diagnostics that link parameterization choices to forgetting. The benchmark and rewinding case studies constitute concrete, falsifiable contributions that could be adopted by the community. The paper is an empirical benchmark study without machine-checked proofs or parameter-free derivations.
major comments (2)
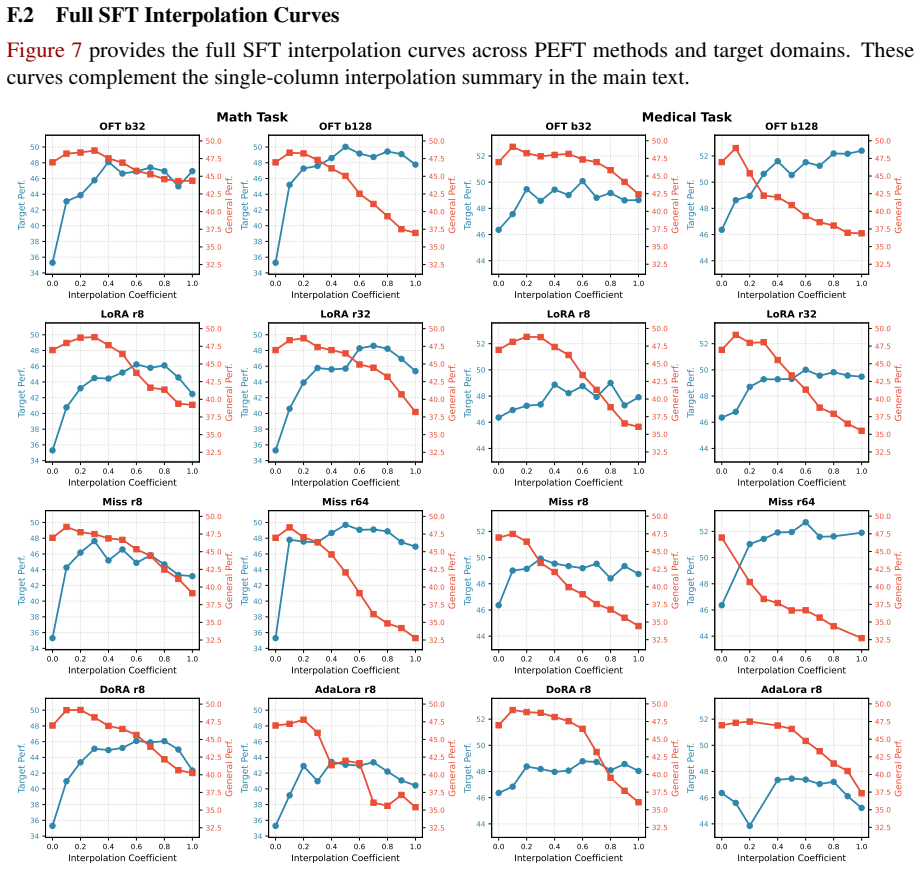
- [§3 and §4] §3 (PEFT-Arena definition) and §4 (results): the central claim that orthogonal finetuning achieves the most favorable Pareto frontier requires that the chosen downstream tasks and retention suite isolate the stability-plasticity trade-off. The manuscript provides no analysis or ablation showing robustness of the ranking to task selection or to the precise definition of the retention metrics; without these controls the observed frontier could be an artifact of the particular evaluation protocol.
- [§4] §4 (experimental protocol): the abstract and results sections state clear empirical findings on Pareto frontiers but report neither the number of independent runs, random seeds, statistical significance tests, nor exclusion criteria for outlier checkpoints. This information is load-bearing for any claim that one method dominates the frontier.
minor comments (1)
- [Figures 2-4] Figure captions and axis labels in the Pareto plots should explicitly state whether points represent single runs or means, and whether error bars or confidence intervals are shown.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for robustness checks and clearer statistical reporting. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [§3 and §4] §3 (PEFT-Arena definition) and §4 (results): the central claim that orthogonal finetuning achieves the most favorable Pareto frontier requires that the chosen downstream tasks and retention suite isolate the stability-plasticity trade-off. The manuscript provides no analysis or ablation showing robustness of the ranking to task selection or to the precise definition of the retention metrics; without these controls the observed frontier could be an artifact of the particular evaluation protocol.
Authors: We agree that explicit sensitivity analysis would strengthen the claim. The PEFT-Arena tasks were selected to span diverse domains (reasoning, knowledge recall, and instruction following) and the retention suite uses established general-capability benchmarks; however, the manuscript does not contain ablations on task subsets or alternative retention metric formulations. In the revision we will add a dedicated subsection with such ablations, confirming that the Pareto ordering, including the position of orthogonal finetuning, is stable under reasonable variations of the evaluation protocol. revision: yes
-
Referee: [§4] §4 (experimental protocol): the abstract and results sections state clear empirical findings on Pareto frontiers but report neither the number of independent runs, random seeds, statistical significance tests, nor exclusion criteria for outlier checkpoints. This information is load-bearing for any claim that one method dominates the frontier.
Authors: We accept this point. All reported results were obtained from three independent random seeds per method, with means and standard deviations shown in the figures; no checkpoints were excluded as outliers. The revised manuscript will state these details explicitly in §4, add a statistical significance analysis (paired t-tests across seeds) for the frontier comparisons, and include the seed values and run counts in the experimental protocol description. revision: yes
Circularity Check
No circularity: empirical benchmark with post-hoc analyses
full rationale
The paper is an empirical benchmark study that introduces PEFT-Arena to measure downstream performance and general capability retention across PEFT methods, then reports observed stability-plasticity profiles and a Pareto frontier ranking. These are direct measurements from experiments, not quantities derived from fitted parameters or self-referential definitions. The weight-space spectral analysis and activation-space isometry checks are interpretive post-hoc examinations of the empirical results. No equations reduce claims to inputs by construction, no uniqueness theorems are imported via self-citation, and no ansatz or renaming patterns appear. The derivation chain consists of experimental protocol followed by observation and geometric interpretation, remaining self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions that benchmark metrics for downstream accuracy and capability retention reflect meaningful stability-plasticity trade-offs
Reference graph
Works this paper leans on
-
[1]
New insights on reducing abrupt representa- tion change in online continual learning. InICLR. Hanjie Chen, Zhouxiang Fang, Yash Singla, and Mark Dredze. 2025. Benchmarking large language models on answering and explaining challenging medical questions. InNAACL. Jiaao Chen, Aston Zhang, Xingjian Shi, Mu Li, Alex Smola, and Diyi Yang. 2023. Parameter-effici...
-
[2]
Mozhdeh Gheini, Xiang Ren, and Jonathan May
Krona: Parameter efficient tuning with kro- necker adapter.arXiv preprint arXiv:2212.10650. Mozhdeh Gheini, Xiang Ren, and Jonathan May. 2021. Cross-attention is all you need: Adapting pretrained transformers for machine translation. InEMNLP. Demi Guo, Alexander M Rush, and Yoon Kim. 2021. Parameter-efficient transfer learning with diff prun- ing.ACL. Jun...
-
[3]
Let’s verify step by step.arXiv preprint arXiv:2305.20050. Jiacheng Lin, Zhongruo Wang, Kun Qian, Tian Wang, Arvind Srinivasan, Hansi Zeng, Ruochen Jiao, Xie Zhou, Jiri Gesi, Dakuo Wang, and 1 others. 2025. Sft doesn’t always hurt general capabilities: Revisiting domain-specific fine-tuning in llms.arXiv preprint arXiv:2509.20758. Yong Lin, Hangyu Lin, We...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Orthogonal over-parameterized training. In CVPR. Weiyang Liu, Zeju Qiu, Yao Feng, Yuliang Xiu, Yuxuan Xue, Longhui Yu, Haiwen Feng, Zhen Liu, Juyeon Heo, Songyou Peng, Yandong Wen, Michael J. Black, Adrian Weller, and Bernhard Schölkopf. 2024b. Parameter-efficient orthogonal finetuning via butter- fly factorization. InICLR. 10 Xiao Liu, Kaixuan Ji, Yichen...
-
[5]
PiSSA: Principal Singular Values and Sin- gular Vectors Adaptation of Large Language Models. NeurIPS. Martial Mermillod, Aurélia Bugaiska, and Patrick Bonin. 2013. The stability-plasticity dilemma: Inves- tigating the continuum from catastrophic forgetting to age-limited learning effects.Frontiers in psychology, 4:504. Ari Morcos, Maithra Raghu, and Samy ...
-
[6]
5 technical report.arXiv preprint
Qwen2. 5 technical report.arXiv preprint. Sihan Yang, Kexuan Shi, and Weiyang Liu. 2026. Orthogonal model merging.arXiv preprint arXiv:2602.05943. Elad Ben Zaken, Yoav Goldberg, and Shauli Ravfogel
-
[7]
BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models. In ACL. Qingru Zhang, Minshuo Chen, Alexander Bukharin, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. 2023. Adalora: Adaptive budget allocation for parameter-efficient fine-tuning. InICLR. Yuanhan Zhang, Kaiyang Zhou, and Ziwei Liu. 2024. Neural prompt search...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
The path not taken: Rlvr provably learns off the principals.arXiv preprint arXiv:2511.08567. Yuxin Zuo, Shang Qu, Yifei Li, Zhang-Ren Chen, Xuekai Zhu, Ermo Hua, Kaiyan Zhang, Ning Ding, and Bowen Zhou. 2025. MedxpertQA: Benchmark- ing expert-level medical reasoning and understanding. InICML. 12 Appendix Table of Contents A Related Work 14 B Implementatio...
-
[9]
These methods primarily combine multiple task-specialized models
merge task vectors within input-representation space. These methods primarily combine multiple task-specialized models. Our use of interpolation is related in form but different in purpose. Rather than proposing a new model-merging technique, merging multiple task-specialized models, or targeting distribution-shift robustness, we use interpolation as a pa...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.