Balancing Multimodal Learning through Label Space Reshaping
Pith reviewed 2026-06-30 16:17 UTC · model grok-4.3
The pith
Reshaping the shared label space equalizes mapping difficulty across modalities and reduces imbalance in multimodal learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
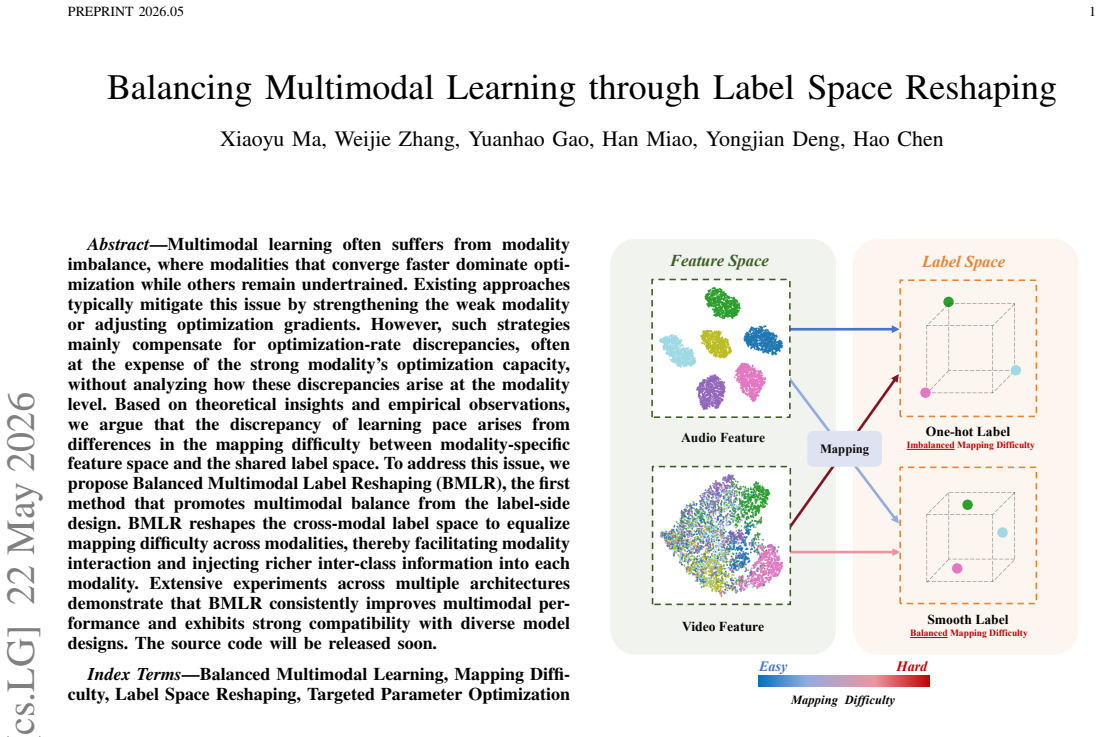
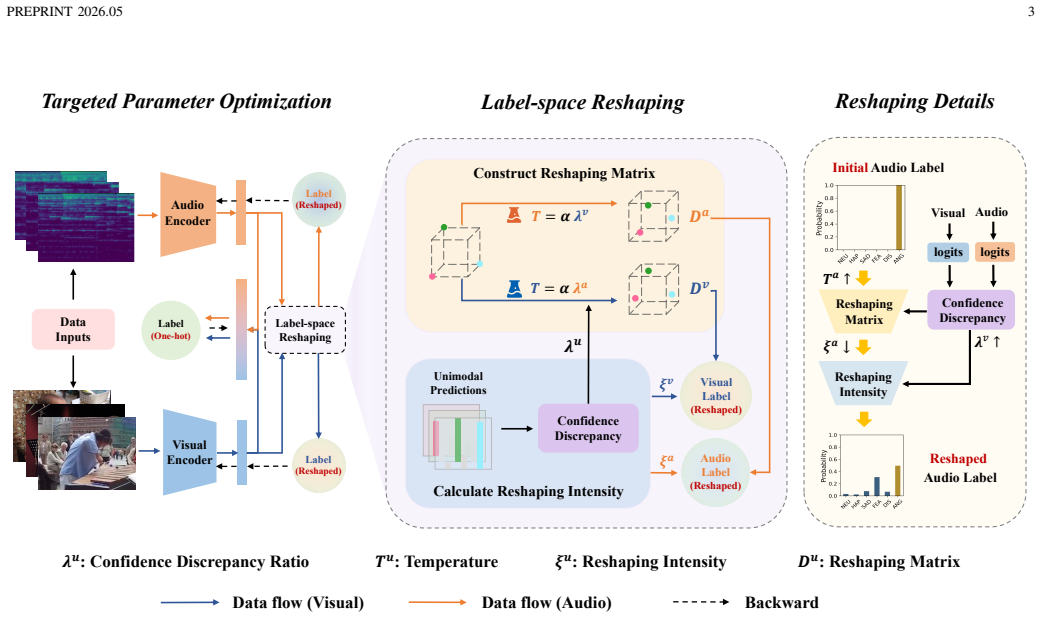
The discrepancy of learning pace arises from differences in the mapping difficulty between modality-specific feature space and the shared label space. BMLR reshapes the cross-modal label space to equalize mapping difficulty across modalities, thereby facilitating modality interaction and injecting richer inter-class information into each modality.
What carries the argument
Balanced Multimodal Label Reshaping (BMLR), a label-side redesign that alters the shared label space to equalize the mapping difficulty each modality faces when connecting its features to the labels.
If this is right
- BMLR raises final multimodal accuracy on multiple architectures without restricting the strong modality.
- The method works with a range of existing model designs, showing label-space adjustment is compatible rather than competitive with gradient-based fixes.
- By injecting richer inter-class information, each modality gains better cross-modal signals during training.
- The approach treats the label space as the adjustable element rather than feature extractors or loss weights.
Where Pith is reading between the lines
- If mapping difficulty governs balance, the same label-space idea could be tested on other multi-stream settings such as multi-task or multi-view learning.
- The claim implies that future work could measure mapping difficulty directly, for example by tracking how quickly each modality's features separate the reshaped labels.
- Label reshaping might interact with data-augmentation strategies that already alter class boundaries.
Load-bearing premise
Differences in how hard it is for each modality to map its features onto the shared labels are the main driver of learning-pace imbalance, and changing the labels can remove that difference without creating new optimization problems.
What would settle it
A controlled experiment in which label-space reshaping is applied yet the originally faster modality still dominates training and the slower one remains under-trained would falsify the claim that mapping difficulty is the primary cause.
Figures
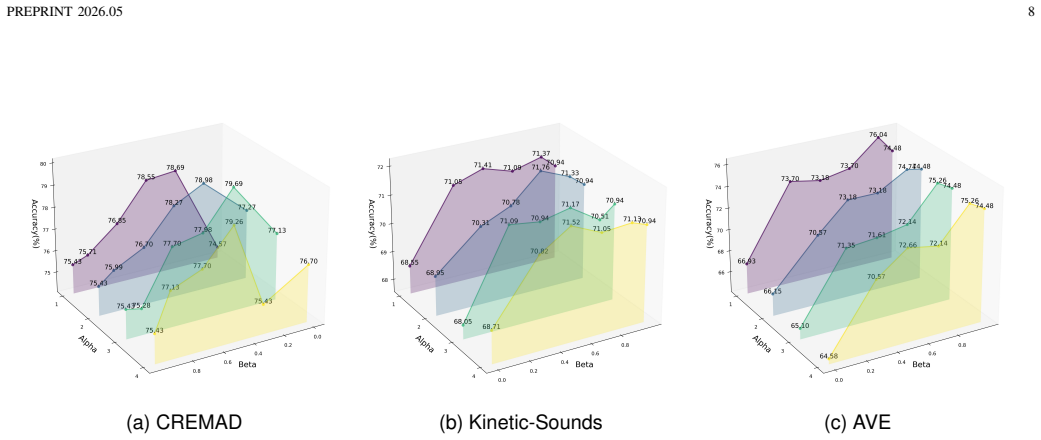
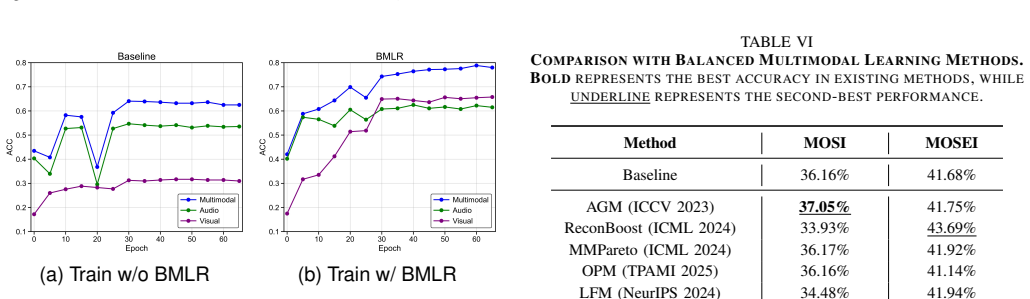
read the original abstract
Multimodal learning often suffers from modality imbalance, where modalities that converge faster dominate optimization while others remain undertrained. Existing approaches typically mitigate this issue by strengthening the weak modality or adjusting optimization gradients. However, such strategies mainly compensate for optimization rate discrepancies, often at the expense of the strong modality's optimization capacity, without analyzing how these discrepancies arise at the modality level. Based on theoretical insights and empirical observations, we argue that the discrepancy of learning pace arises from differences in the mapping difficulty between modality-specific feature space and the shared label space. To address this issue, we propose Balanced Multimodal Label Reshaping (BMLR), the first method that promotes multimodal balance from the label-side design. BMLR reshapes the cross-modal label space to equalize mapping difficulty across modalities, thereby facilitating modality interaction and injecting richer inter-class information into each modality. Extensive experiments across multiple architectures demonstrate that BMLR consistently improves multimodal performance and exhibits strong compatibility with diverse model designs. The source code will be released soon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that modality imbalance in multimodal learning arises from differences in 'mapping difficulty' between modality-specific feature spaces and the shared label space. It proposes Balanced Multimodal Label Reshaping (BMLR) as the first label-side method to equalize this difficulty via cross-modal label-space reshaping, thereby improving modality interaction and performance. The claim is said to rest on theoretical insights and empirical observations, with experiments showing consistent gains and compatibility across architectures.
Significance. If the central causal claim and the BMLR operator can be rigorously formalized and shown to preserve task semantics while equalizing convergence without degrading the strong modality, the label-space perspective could complement existing gradient- and feature-based imbalance mitigations. The manuscript does not yet supply the required derivations, metrics, or ablation evidence to establish this.
major comments (3)
- [Abstract] Abstract: The central premise—that learning-pace discrepancy 'arises from differences in the mapping difficulty between modality-specific feature space and the shared label space'—is stated without any formal definition, metric (e.g., feature-to-logit distance, per-modality convergence rate), or derivation. This absence makes the causal attribution load-bearing yet unevaluable and leaves the motivation for BMLR ungrounded.
- [Abstract] Abstract / Method (BMLR description): No explicit reshaping operator, loss term, or proof is supplied showing that label-space reshaping equalizes mapping difficulty while preserving label semantics and without introducing new optimization pathologies for the stronger modality. The claim that BMLR 'facilitates modality interaction and injects richer inter-class information' therefore remains an assertion rather than a demonstrated property.
- [Abstract] Abstract: The manuscript asserts 'theoretical insights and empirical observations' yet provides neither referenced equations, convergence analysis, nor quantitative details of the observations (e.g., per-modality loss curves or mapping-difficulty measurements). Consequently the empirical support for the mapping-difficulty hypothesis cannot be assessed.
minor comments (1)
- The abstract states that source code 'will be released soon' but supplies no link or reproducibility statement; a concrete release plan or supplementary material would strengthen the submission.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and motivation. We address each point below and will strengthen the formal presentation in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central premise—that learning-pace discrepancy 'arises from differences in the mapping difficulty between modality-specific feature space and the shared label space'—is stated without any formal definition, metric (e.g., feature-to-logit distance, per-modality convergence rate), or derivation. This absence makes the causal attribution load-bearing yet unevaluable and leaves the motivation for BMLR ungrounded.
Authors: We agree the abstract presents the premise at a high level without the supporting definitions or metrics. In the revised version we will add a concise formal definition of mapping difficulty (including a distance-based metric and per-modality convergence rate) directly in the abstract and expand the derivation in Section 3 to make the causal link explicit and evaluable. revision: yes
-
Referee: [Abstract] Abstract / Method (BMLR description): No explicit reshaping operator, loss term, or proof is supplied showing that label-space reshaping equalizes mapping difficulty while preserving label semantics and without introducing new optimization pathologies for the stronger modality. The claim that BMLR 'facilitates modality interaction and injects richer inter-class information' therefore remains an assertion rather than a demonstrated property.
Authors: The current abstract summarizes BMLR at a high level. The full manuscript defines the reshaping operator and associated loss in the method section; however, we acknowledge the absence of an explicit proof of semantic preservation and convergence behavior. In revision we will insert the operator definition, loss term, and a short proof sketch (with discussion of potential pathologies) into the main text, plus an ablation confirming no degradation of the stronger modality. revision: yes
-
Referee: [Abstract] Abstract: The manuscript asserts 'theoretical insights and empirical observations' yet provides neither referenced equations, convergence analysis, nor quantitative details of the observations (e.g., per-modality loss curves or mapping-difficulty measurements). Consequently the empirical support for the mapping-difficulty hypothesis cannot be assessed.
Authors: We agree that the abstract does not reference the supporting equations or quantitative observations. The experiments section already contains per-modality loss curves and mapping-difficulty measurements, but these are not cited in the abstract. In the revision we will add explicit references to the relevant equations and figures in the abstract and ensure the convergence analysis is highlighted in the main text. revision: yes
Circularity Check
No circularity detected; derivation chain self-contained
full rationale
The paper asserts that learning-pace discrepancy 'arises from differences in the mapping difficulty between modality-specific feature space and the shared label space' based on 'theoretical insights and empirical observations,' then introduces BMLR as a label-side reshaping method. No equations, fitted parameters, self-citations, or uniqueness theorems appear in the provided text that would reduce this premise or the method to its own inputs by construction. The central claim therefore does not collapse into self-definition, renamed fits, or load-bearing self-citation chains, leaving the argument independent of the patterns that trigger circularity flags.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multimodal deep learning
J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee, A. Y . Nget al., “Multimodal deep learning.” inInternational Conference on Machine Learning, vol. 11, 2011, pp. 689–696
2011
-
[2]
A multi- modal saliency model for videos with high audio-visual correspondence,
X. Min, G. Zhai, J. Zhou, X.-P. Zhang, X. Yang, and X. Guan, “A multi- modal saliency model for videos with high audio-visual correspondence,” IEEE Transactions on Image Processing, vol. 29, pp. 3805–3819, 2020
2020
-
[3]
Vision+ x: A survey on multimodal learning in the light of data,
Y . Zhu, Y . Wu, N. Sebe, and Y . Yan, “Vision+ x: A survey on multimodal learning in the light of data,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[4]
Disentangle to fuse: Towards content preservation and cross-modality consistency for multi-modality image fusion,
X. Qin, Y . Cui, S. Sun, R. Chen, W. Ren, A. Knoll, and X. Cao, “Disentangle to fuse: Towards content preservation and cross-modality consistency for multi-modality image fusion,”IEEE Transactions on Image Processing, 2026
2026
-
[5]
What makes training multi-modal classification networks hard?
W. Wang, D. Tran, and M. Feiszli, “What makes training multi-modal classification networks hard?” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2020, pp. 12 695– 12 705
2020
-
[6]
Modality compe- tition: What makes joint training of multi-modal network fail in deep learning?(provably),
Y . Huang, J. Lin, C. Zhou, H. Yang, and L. Huang, “Modality compe- tition: What makes joint training of multi-modal network fail in deep learning?(provably),” inInternational Conference on Machine Learning. PMLR, 2022, pp. 9226–9259
2022
-
[7]
Balanced multimodal learning via on-the-fly gradient modulation,
X. Peng, Y . Wei, A. Deng, D. Wang, and D. Hu, “Balanced multimodal learning via on-the-fly gradient modulation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 8238–8247
2022
-
[8]
Characterizing and overcoming the greedy nature of learning in multi-modal deep neural networks,
N. Wu, S. Jastrzebski, K. Cho, and K. J. Geras, “Characterizing and overcoming the greedy nature of learning in multi-modal deep neural networks,” inInternational Conference on Machine Learning. PMLR, 2022, pp. 24 043–24 055
2022
-
[9]
Balancebench- mark: A survey for multimodal imbalance learning,
S. Xu, M. Cui, C. Huang, H. Wang, and D. Hu, “Balancebench- mark: A survey for multimodal imbalance learning,”arXiv preprint arXiv:2502.10816, 2025
-
[10]
Pmr: Prototypical modal rebalance for multimodal learning,
Y . Fan, W. Xu, H. Wang, J. Wang, and S. Guo, “Pmr: Prototypical modal rebalance for multimodal learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 20 029–20 038
2023
-
[11]
Im- proving multi-modal learning with uni-modal teachers,
C. Du, T. Li, Y . Liu, Z. Wen, T. Hua, Y . Wang, and H. Zhao, “Im- proving multi-modal learning with uni-modal teachers,”arXiv preprint arXiv:2106.11059, 2021
-
[12]
Mmpareto: Boosting multimodal learning with innocent unimodal assistance,
Y . Wei and D. Hu, “Mmpareto: Boosting multimodal learning with innocent unimodal assistance,” inInternational Conference on Machine Learning. PMLR, 2024, pp. 52 559–52 572
2024
-
[13]
Mmcosine: Multi-modal cosine loss towards balanced audio-visual fine-grained learning,
R. Xu, R. Feng, S.-X. Zhang, and D. Hu, “Mmcosine: Multi-modal cosine loss towards balanced audio-visual fine-grained learning,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[14]
Boosting multi-modal model performance with adaptive gradient modulation,
H. Li, X. Li, P. Hu, Y . Lei, C. Li, and Y . Zhou, “Boosting multi-modal model performance with adaptive gradient modulation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 22 214–22 224
2023
-
[15]
Learning to balance the learning rates between various modalities via adaptive tracking factor,
Y . Sun, S. Mai, and H. Hu, “Learning to balance the learning rates between various modalities via adaptive tracking factor,”IEEE Signal Processing Letters, vol. 28, pp. 1650–1654, 2021
2021
-
[16]
arXiv preprint arXiv:2405.07930 , year=
K. Kontras, C. Chatzichristos, M. Blaschko, and M. De V os, “Improving multimodal learning with multi-loss gradient modulation,”arXiv preprint arXiv:2405.07930, 2024
-
[17]
Classifier-guided gradient modula- tion for enhanced multimodal learning,
Z. Guo, T. Jin, J. Chen, and Z. Zhao, “Classifier-guided gradient modula- tion for enhanced multimodal learning,”arXiv preprint arXiv:2411.01409, 2024
-
[18]
Label confusion learning to enhance text classification models,
B. Guo, S. Han, X. Han, H. Huang, and T. Lu, “Label confusion learning to enhance text classification models,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 14, 2021, pp. 12 929–12 936
2021
-
[19]
The devil is in the margin: Margin-based label smoothing for network calibration,
B. Liu, I. Ben Ayed, A. Galdran, and J. Dolz, “The devil is in the margin: Margin-based label smoothing for network calibration,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 80–88
2022
-
[20]
Facilitating multimodal classification via dynamically learning modality gap,
Y . Yang, F. Wan, Q.-Y . Jiang, and Y . Xu, “Facilitating multimodal classification via dynamically learning modality gap,”Advances in Neural Information Processing Systems, vol. 37, pp. 62 108–62 122, 2024
2024
-
[21]
Understanding unimodal bias in multimodal deep linear networks,
Y . Zhang, P. E. Latham, and A. Saxe, “Understanding unimodal bias in multimodal deep linear networks,”arXiv preprint arXiv:2312.00935, 2023
-
[22]
Label distribution learning,
X. Geng, “Label distribution learning,”IEEE Transactions on Knowl- edge and Data Engineering, vol. 28, no. 7, pp. 1734–1748, 2016
2016
-
[23]
Rebalanced vision-language retrieval considering structure-aware distillation,
Y . Yang, W. Xi, L. Zhou, and J. Tang, “Rebalanced vision-language retrieval considering structure-aware distillation,”IEEE Transactions on Image Processing, vol. 33, pp. 6881–6892, 2024
2024
-
[24]
Gradient and structure consistency in multimodal emotion recognition,
Q. Shi, M. Ye, W. Huang, B. Du, and X. Zong, “Gradient and structure consistency in multimodal emotion recognition,”IEEE Transactions on Image Processing, 2025
2025
-
[25]
Re- conboost: Boosting can achieve modality reconcilement
C. Hua, Q. Xu, S. Bao, Z. Yang, and Q. Huang, “Reconboost: Boosting can achieve modality reconcilement,”arXiv preprint arXiv:2405.09321, 2024
-
[26]
On-the-fly modulation for balanced multimodal learning,
Y . Wei, D. Hu, H. Du, and J.-R. Wen, “On-the-fly modulation for balanced multimodal learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[27]
Learning to rebalance multi-modal optimization by adaptively masking subnetworks,
Y . Yang, H. Pan, Q.-Y . Jiang, Y . Xu, and J. Tang, “Learning to rebalance multi-modal optimization by adaptively masking subnetworks,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 6, pp. 4553–4566, 2025
2025
-
[28]
Multimodal representation learning by alternating unimodal adaptation,
X. Zhang, J. Yoon, M. Bansal, and H. Yao, “Multimodal representation learning by alternating unimodal adaptation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 27 456–27 466
2024
-
[29]
Improving multimodal learning balance and sufficiency through data remixing,
X. Ma, H. Chen, and Y . Deng, “Improving multimodal learning balance and sufficiency through data remixing,” inInternational Conference on Machine Learning. PMLR, 2025, pp. 41 827–41 836
2025
-
[30]
Boosting multimodal learning via disen- tangled gradient learning,
S. Wei, C. Luo, and Y . Luo, “Boosting multimodal learning via disen- tangled gradient learning,”arXiv preprint arXiv:2507.10213, 2025
-
[31]
Rethinking the inception architecture for computer vision,
C. Szegedy, V . Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2016, pp. 2818–2826
2016
-
[32]
Regularizing Neural Networks by Penalizing Confident Output Distributions
G. Pereyra, G. Tucker, J. Chorowski, Ł. Kaiser, and G. Hinton, “Reg- ularizing neural networks by penalizing confident output distributions,” arXiv preprint arXiv:1701.06548, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Knowledge distillation: A survey,
J. Gou, B. Yu, S. J. Maybank, and D. Tao, “Knowledge distillation: A survey,”International Journal of Computer Vision, vol. 129, no. 6, pp. 1789–1819, 2021
2021
-
[34]
arXiv preprint arXiv:2505.04560 (2025)
G. Wang, Z. Yang, Z. Wang, S. Wang, Q. Xu, and Q. Huang, “Abkd: Pursuing a proper allocation of the probability mass in knowledge distillation viaα-β-divergence,”arXiv preprint arXiv:2505.04560, 2025
-
[35]
A general dynamic knowledge distillation method for visual analytics,
Z. Tu, X. Liu, and X. Xiao, “A general dynamic knowledge distillation method for visual analytics,”IEEE Transactions on Image Processing, vol. 31, pp. 6517–6531, 2022
2022
-
[36]
Is label smoothing truly incompatible with knowledge distillation: An empirical study,
Z. Shen, Z. Liu, D. Xu, Z. Chen, K.-T. Cheng, and M. Savvides, “Is label smoothing truly incompatible with knowledge distillation: An empirical study,”arXiv preprint arXiv:2104.00676, 2021
-
[37]
Audio-visual scene analysis with self- supervised multisensory features,
A. Owens and A. A. Efros, “Audio-visual scene analysis with self- supervised multisensory features,”Springer, Cham, 2018. PREPRINT 2026.05 10
2018
-
[38]
Affect recognition from face and body: early fusion vs. late fusion,
H. Gunes and M. Piccardi, “Affect recognition from face and body: early fusion vs. late fusion,” in2005 IEEE International Conference on Systems, Man and Cybernetics, vol. 4. IEEE, 2005, pp. 3437–3443
2005
-
[39]
Enhancing multimodal co- operation via sample-level modality valuation,
Y . Wei, R. Feng, Z. Wang, and D. Hu, “Enhancing multimodal co- operation via sample-level modality valuation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 27 338–27 347
2024
-
[40]
Crema-d: Crowd-sourced emotional multimodal actors dataset,
H. Cao, D. G. Cooper, M. K. Keutmann, R. C. Gur, A. Nenkova, and R. Verma, “Crema-d: Crowd-sourced emotional multimodal actors dataset,”IEEE Transactions on Affective Computing, vol. 5, no. 4, pp. 377–390, 2014
2014
-
[41]
Look, listen and learn,
R. Arandjelovic and A. Zisserman, “Look, listen and learn,” inProceed- ings of the IEEE/CVF Cnternational Conference on Computer Vision, 2017, pp. 609–617
2017
-
[42]
The Kinetics Human Action Video Dataset
W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijaya- narasimhan, F. Viola, T. Green, T. Back, P. Natsevet al., “The kinetics human action video dataset,”arXiv preprint arXiv:1705.06950, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Audio-visual event localization in unconstrained videos,
Y . Tian, J. Shi, B. Li, Z. Duan, and C. Xu, “Audio-visual event localization in unconstrained videos,” inProceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 247–263
2018
-
[44]
Multimodal sentiment analysis with word-level fusion and reinforcement learning,
M. Chen, S. Wang, P. P. Liang, T. Baltru ˇsaitis, A. Zadeh, and L.-P. Morency, “Multimodal sentiment analysis with word-level fusion and reinforcement learning,” inProceedings of the 19th ACM International Conference on Multimodal Interaction, 2017, pp. 163–171
2017
-
[45]
Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph,
A. B. Zadeh, P. P. Liang, S. Poria, E. Cambria, and L.-P. Morency, “Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph,” inProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2018, pp. 2236–2246
2018
-
[46]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778
2016
-
[47]
librosa: Audio and music signal analysis in python
B. McFee, C. Raffel, D. Liang, D. P. Ellis, M. McVicar, E. Battenberg, and O. Nieto, “librosa: Audio and music signal analysis in python.”SciPy, vol. 2015, pp. 18–24, 2015
2015
-
[48]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in Neural Information Processing Systems, vol. 30, 2017
2017
-
[49]
Adam: A Method for Stochastic Optimization
D. P. Kingma, “Adam: A method for stochastic optimization,”arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[50]
Cal- ibrating multimodal learning,
H. Ma, Q. Zhang, C. Zhang, B. Wu, H. Fu, J. T. Zhou, and Q. Hu, “Cal- ibrating multimodal learning,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 23 429–23 450
2023
-
[51]
Multimodal pre- training with self-distillation for product understanding in e-commerce,
S. Liu, L. Li, J. Song, Y . Yang, and X. Zeng, “Multimodal pre- training with self-distillation for product understanding in e-commerce,” inProceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, 2023, pp. 1039–1047
2023
-
[52]
Diagnosing and relearning for balanced multimodal learning,
Y . Wei, S. Li, R. Feng, and D. Hu, “Diagnosing and relearning for balanced multimodal learning,” inEuropean Conference on Computer Vision, 2024
2024
-
[53]
Audio-visual scene analysis with self- supervised multisensory features,
A. Owens and A. A. Efros, “Audio-visual scene analysis with self- supervised multisensory features,” inProceedings of the European Con- ference on Computer Vision (ECCV), 2018, pp. 631–648
2018
-
[54]
Film: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville, “Film: Visual reasoning with a general conditioning layer,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 32, no. 1, 2018
2018
-
[55]
Efficient large-scale multi-modal classification,
D. Kiela, E. Grave, A. Joulin, and T. Mikolov, “Efficient large-scale multi-modal classification,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 32, no. 1, 2018
2018
-
[56]
Visualizing data using t-sne
L. Van der Maaten and G. Hinton, “Visualizing data using t-sne.”Journal of Machine Learning Research, vol. 9, no. 11, 2008
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.