LogDx-CI: Benchmarking Log Reduction Tools for LLM Root-Cause Diagnosis
Pith reviewed 2026-06-29 16:06 UTC · model grok-4.3
The pith
Hybrid grep and tail routers lead the cost-quality trade-off for LLM diagnosis of CI failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
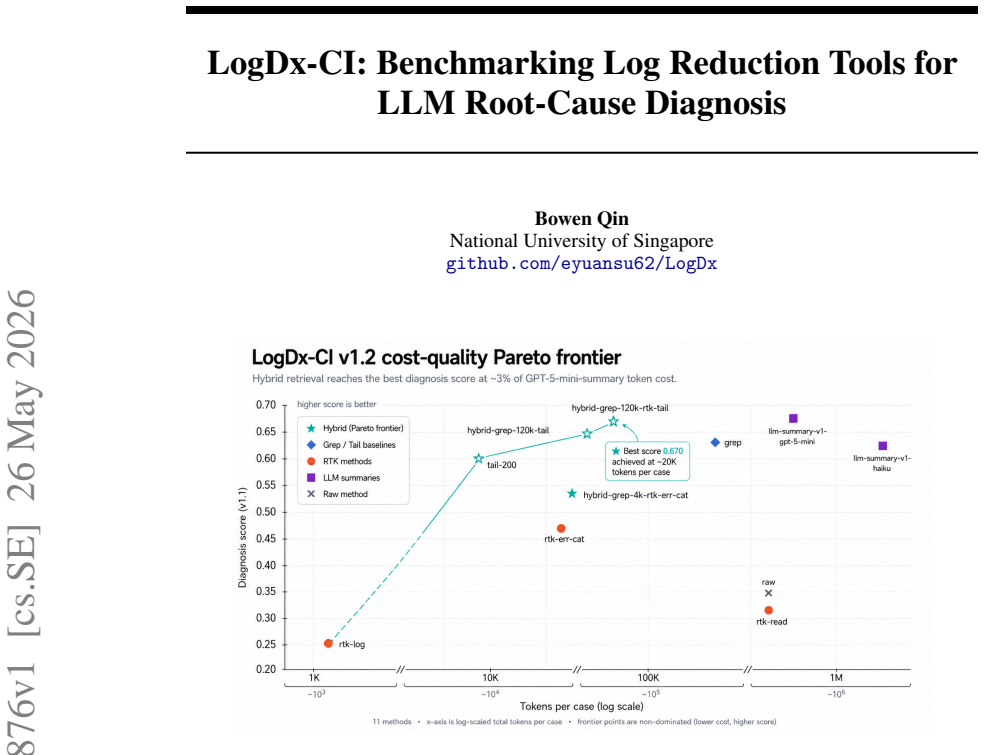
LogDx-CI evaluates eleven reduction methods (raw logs, tail, grep, three RTK variants, two LLM map-reduce summarizers, and three hybrid routers) on thirty-five real GitHub Actions failures. Diagnosis quality is scored by Claude Haiku 4.5, Claude Sonnet 4.6, OpenAI gpt-5-mini, and a Sonnet 4.6 agent. Hybrid grep+tail routers occupy the leading position on the cost-quality frontier at scores of 0.670 and 0.666 for approximately $0.03 per case, matching standalone grep quality at 4.5 times fewer tokens. In the agent-loop regime the quality spread across methods collapses by a factor of seven while cost differences persist because weak contexts force two to four times more tool calls. A cross-fa
What carries the argument
LogDx-CI benchmark that scores log-reduction methods by the downstream quality of LLM root-cause diagnosis on thirty-five real CI failure cases.
If this is right
- Hybrid routers can cut token consumption by 4.5 times while preserving diagnosis quality comparable to full grep.
- Agent loops compress quality variation across reduction methods but still incur higher total cost when the initial reduction is weak.
- Cross-family LLM pairs for summarization and diagnosis improve performance over matched-family pairs on this task.
- The gpt-5-mini summarizer emerges as the lowest-cost high-quality reducer when paired with an agent.
Where Pith is reading between the lines
- Production LLM debugging agents would likely benefit from hybrid reduction even when follow-up tool calls are available, because lower initial token counts still reduce overall spend.
- The benchmark could be extended to other log domains such as application runtime errors or security incidents to test whether the hybrid advantage generalizes.
- If the thirty-five cases prove unrepresentative, the Pareto ranking of reduction methods might shift on broader corpora.
Load-bearing premise
The thirty-five GitHub Actions failure cases together with the LLM-assigned diagnosis quality scores are representative of real-world root-cause identification performance.
What would settle it
A follow-up study that runs the identical reduction methods on one hundred new failure cases drawn from multiple CI systems and compares the LLM diagnosis scores against independent human-expert labels.
Figures
read the original abstract
CI failure logs are large (median 5k lines, max 200k in this corpus) and noisy. Coding agents that try to debug them depend on an upstream tool to reduce the log to a manageable context, but the field has had no public empirical comparison of which reductions preserve enough evidence for downstream LLM diagnosis. We introduce LogDx-CI, a benchmark that compares 11 context-reduction tools (raw, tail, grep, three RTK modes, two real LLM map-reduce summarizers, three hybrid routers) on 35 real GitHub Actions failure cases, scored by 3 LLM debugger families (Claude Haiku 4.5, Claude Sonnet 4.6, OpenAI gpt-5-mini) plus a Sonnet 4.6 tool-using agent. We report three load-bearing findings. (1)~Hybrid grep+tail routers dominate the cost-quality Pareto frontier; the top two methods score 0.670 / 0.666 at $\sim$ \$0.03 per case, same-ballpark quality as standalone grep at $4.5\times$ fewer tokens. (2)~In the agent-loop regime, the quality range across reduction tools collapses $7\times$ (single-shot spread 0.42 $\to$ agent-loop spread 0.059); the agent rescues weak contexts via follow-up tool calls. However, cost differences persist: weak contexts force the agent to issue 2--4$\times$ more tool calls to recover. (3)~A cross-family LLM-summary pair (gpt-5-mini summarizer feeding a Claude Haiku debugger) beats the same-family pair by $+0.071$ averaged across four diagnoser variants, falsifying the self-call-bias hypothesis on this task. The gpt-5-mini summarizer is also the agent-loop \#1 method (score 0.749) at $0.37$ tool-calls per case and $10\times$ lower reducer cost than the Haiku summarizer (\$0.18 vs \$1.75 per case). All data, code, per-case bundles, and reproducibility infrastructure are public.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LogDx-CI, a benchmark comparing 11 log reduction tools (raw, tail, grep, RTK variants, LLM map-reduce summarizers, and hybrid routers) on 35 real GitHub Actions failure cases. Quality is measured via LLM-assigned diagnosis scores from Claude Haiku 4.5, Claude Sonnet 4.6, gpt-5-mini, and a Sonnet agent loop. It reports that hybrid grep+tail routers dominate the cost-quality Pareto frontier (top scores 0.670/0.666 at ~$0.03/case), agent loops collapse quality variance 7x (0.42 to 0.059) while cost gaps persist, and cross-family summarizer-debugger pairs outperform same-family pairs by +0.071, falsifying self-bias.
Significance. If the LLM diagnosis scores are accepted as valid proxies for root-cause performance, the work supplies the first public empirical comparison of log reduction methods for LLM debugging agents, with clear practical implications for cost-efficient CI pipelines. The public release of all data, code, per-case bundles, and reproducibility infrastructure is a notable strength that supports verification and extension.
major comments (3)
- [Abstract] Abstract: All three load-bearing findings (hybrid Pareto dominance at 0.670/0.666, 7x agent-loop variance collapse, and +0.071 cross-family advantage) are computed exclusively from LLM-assigned diagnosis quality scores. No human-expert ratings, inter-rater agreement, or correlation with actual fix success are reported, leaving open the possibility that systematic scorer bias could reorder the 11 methods and alter the reported dominance or falsification result.
- [Abstract] Abstract: The manuscript provides no details on the exact scoring rubric, case selection criteria for the 35 GitHub Actions failures, or how the quality scores (e.g., 0.670, 0.666, 0.749) are aggregated across the three LLM families, which directly limits verification of the central empirical claims.
- [Abstract] Abstract: The agent-loop spread reduction (single-shot 0.42 to agent-loop 0.059) and the claim that weak contexts force 2-4x more tool calls are presented without specifying the precise calculation of spread or whether the agent re-uses the same reduction tool in follow-ups, both of which are necessary to interpret the rescue effect.
minor comments (1)
- [Abstract] Abstract: The median (5k) and max (200k) log lengths are stated but the distribution across the 35 cases is not summarized, which would help readers assess representativeness.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We respond point-by-point to the three major comments below, indicating where revisions will be incorporated to address concerns about transparency and limitations.
read point-by-point responses
-
Referee: [Abstract] Abstract: All three load-bearing findings (hybrid Pareto dominance at 0.670/0.666, 7x agent-loop variance collapse, and +0.071 cross-family advantage) are computed exclusively from LLM-assigned diagnosis quality scores. No human-expert ratings, inter-rater agreement, or correlation with actual fix success are reported, leaving open the possibility that systematic scorer bias could reorder the 11 methods and alter the reported dominance or falsification result.
Authors: We acknowledge that the reliance on LLM-assigned diagnosis scores as the sole quality metric is a limitation of the current study, as no human-expert ratings, inter-rater agreement statistics, or correlation with actual developer fix success are provided. The paper positions these scores as a practical proxy following established LLM-as-a-judge practices, and the use of four distinct diagnoser variants (including cross-family comparisons) was intended to surface rather than conceal bias. We will revise the manuscript to add an explicit Limitations subsection discussing the proxy nature of the metric, the absence of human validation, and the risk that scorer bias could affect rankings. A full human study lies outside the scope of this work. revision: yes
-
Referee: [Abstract] Abstract: The manuscript provides no details on the exact scoring rubric, case selection criteria for the 35 GitHub Actions failures, or how the quality scores (e.g., 0.670, 0.666, 0.749) are aggregated across the three LLM families, which directly limits verification of the central empirical claims.
Authors: The full manuscript's Methods section specifies the 5-point diagnosis rubric (covering root-cause identification, evidence completeness, and suggested fix actionability), the case selection process (35 public GitHub Actions failures drawn from a larger corpus with manually verified root causes), and aggregation (simple mean across the four diagnoser outputs). These details were omitted from the abstract for brevity. We will revise the abstract and add a concise summary table in the main text to make the rubric, selection criteria, and aggregation procedure immediately verifiable without requiring the full methods read. revision: yes
-
Referee: [Abstract] Abstract: The agent-loop spread reduction (single-shot 0.42 to agent-loop 0.059) and the claim that weak contexts force 2-4x more tool calls are presented without specifying the precise calculation of spread or whether the agent re-uses the same reduction tool in follow-ups, both of which are necessary to interpret the rescue effect.
Authors: Spread is defined as the range (maximum minus minimum) of mean diagnosis scores across the 11 reduction methods. The agent re-uses the identical reduction tool for all follow-up calls on a given case; the reduction occurs once upstream, after which the agent issues additional tool calls (e.g., grep or read_file) on the already-reduced context. We will revise the relevant section to include the explicit spread formula, a short pseudocode snippet for the agent loop, and a clarification that the same reducer is fixed per case. This will make the 7 imes variance collapse and the 2–4× tool-call inflation directly interpretable. revision: yes
Circularity Check
Pure empirical benchmark with no derivations or self-referential steps
full rationale
The paper performs direct experimental measurements of 11 reduction methods on 35 fixed GitHub Actions cases, scored by three LLM families plus one agent loop. All reported scores (0.670/0.666 Pareto, 7× collapse, +0.071 cross-family) are computed from these measurements with no equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations. The central claims rest on external data collection and LLM scoring rather than any internal reduction to the paper's own assumptions or prior results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM judgments of diagnosis quality from reduced logs serve as a reliable proxy for true root-cause identification performance
Reference graph
Works this paper leans on
-
[1]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
URLhttps://arxiv.org/abs/2310.11511. Min Du and Feifei Li. Spell: Streaming parsing of system event logs. InIEEE International Conference on Data Mining (ICDM), pages 859–864,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Ragas: Automated Evaluation of Retrieval Augmented Generation
URL https://arxiv.org/ abs/2309.15217. Pinjia He, Jieming Zhu, Zibin Zheng, and Michael R. Lyu. Drain: An online log parsing approach with fixed depth tree. InIEEE International Conference on Web Services (ICWS), pages 33–40,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
doi: 10.1109/ICWS.2017.13. Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InInternational Conference on Learning Representations (ICLR),
-
[4]
Lost in the middle: How language models use long contexts
URL https://arxiv. org/abs/2307.03172. Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-Eval: NLG evaluation using GPT-4 with better human alignment. InConference on Empirical Methods in Natural Language Processing (EMNLP),
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
URLhttps://arxiv.org/abs/2303.16634. rtk-ai. RTK: Rust token killer. https://github.com/rtk-ai/rtk,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
URLhttps://arxiv.org/abs/2404.07972. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
URL https://arxiv. org/abs/2306.05685. Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A realistic web environment for building autonomous agents. InInternational Conference on Learning Representations (ICLR),
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
WebArena: A Realistic Web Environment for Building Autonomous Agents
URLhttps://arxiv.org/abs/2307.13854. Jieming Zhu, Shilin He, Jinyang Liu, Pinjia He, Qi Xie, Zibin Zheng, and Michael R. Lyu. Tools and benchmarks for automated log parsing. InIEEE/ACM International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), pages 121–130,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.