Adopt neq Adapt: Longitudinal Analyses of LLM Conversations in the Wild
Pith reviewed 2026-06-29 12:23 UTC · model grok-4.3
The pith
Individual Bing Copilot users rarely alter their LLM interaction habits over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
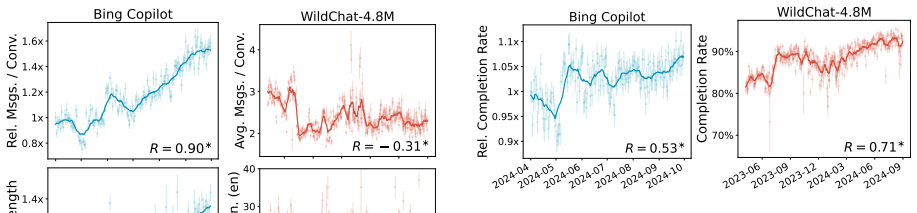
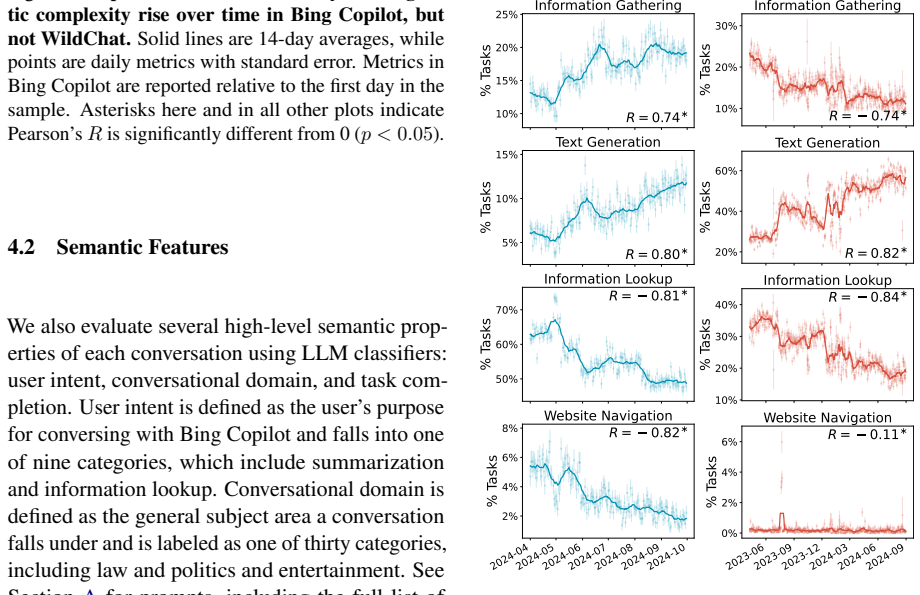
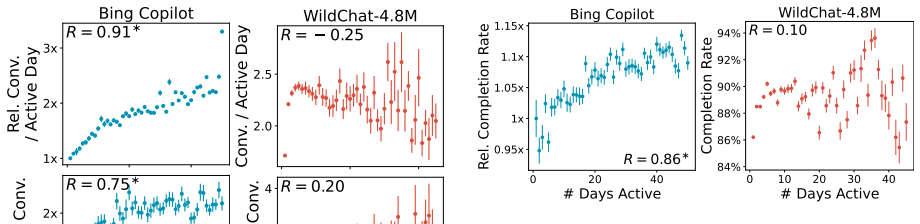
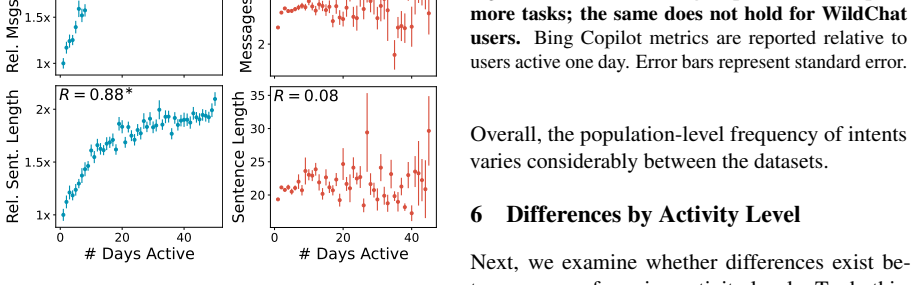
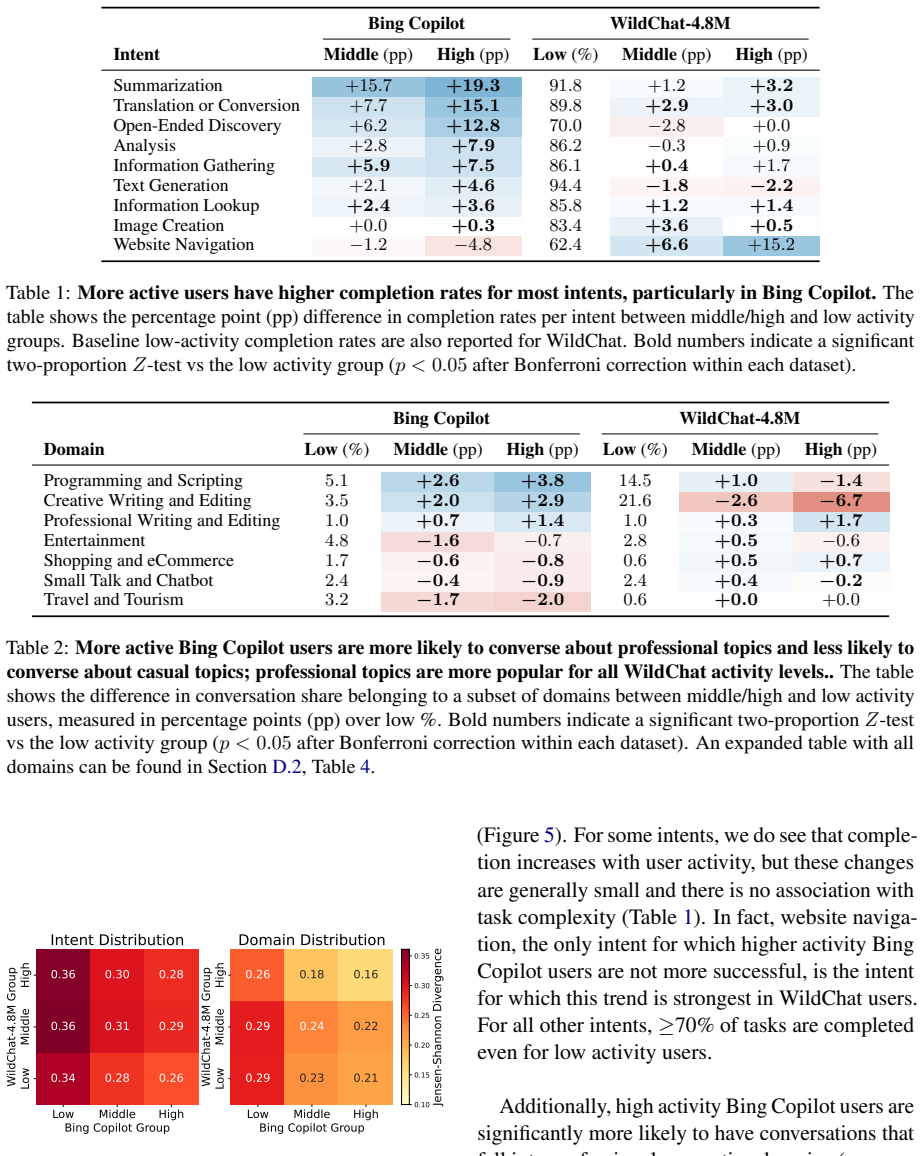
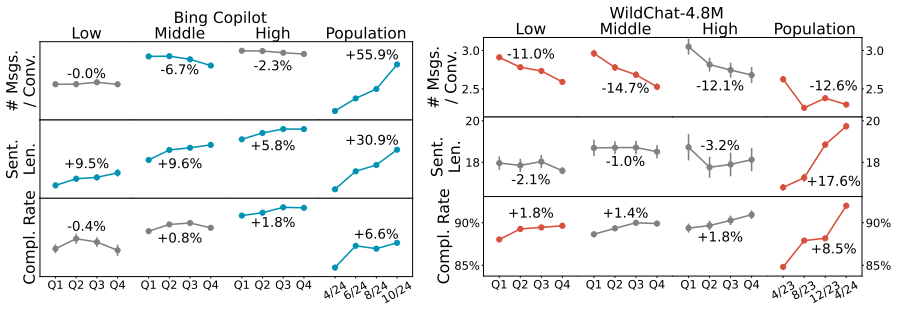
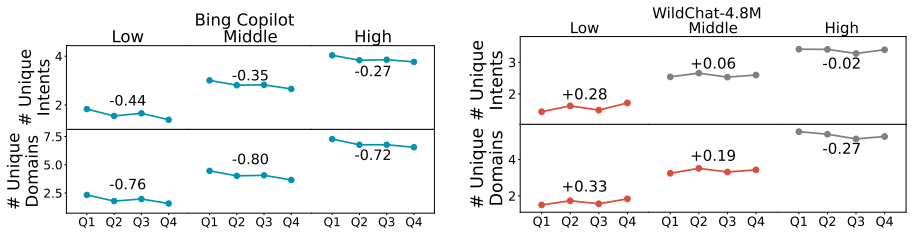
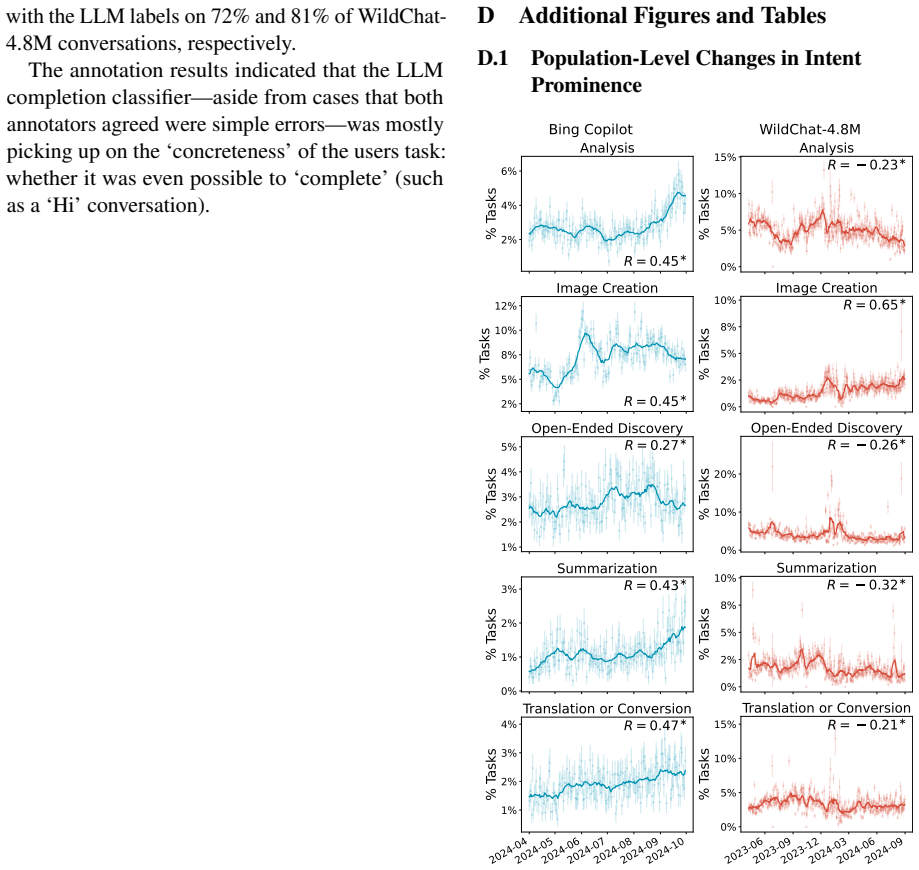
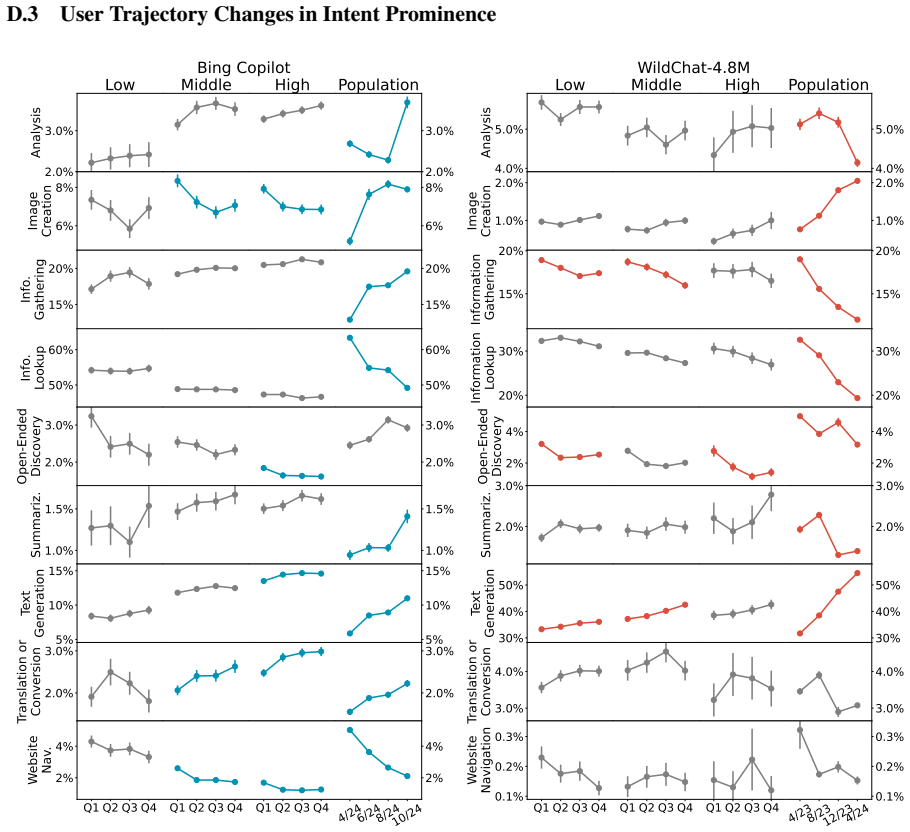
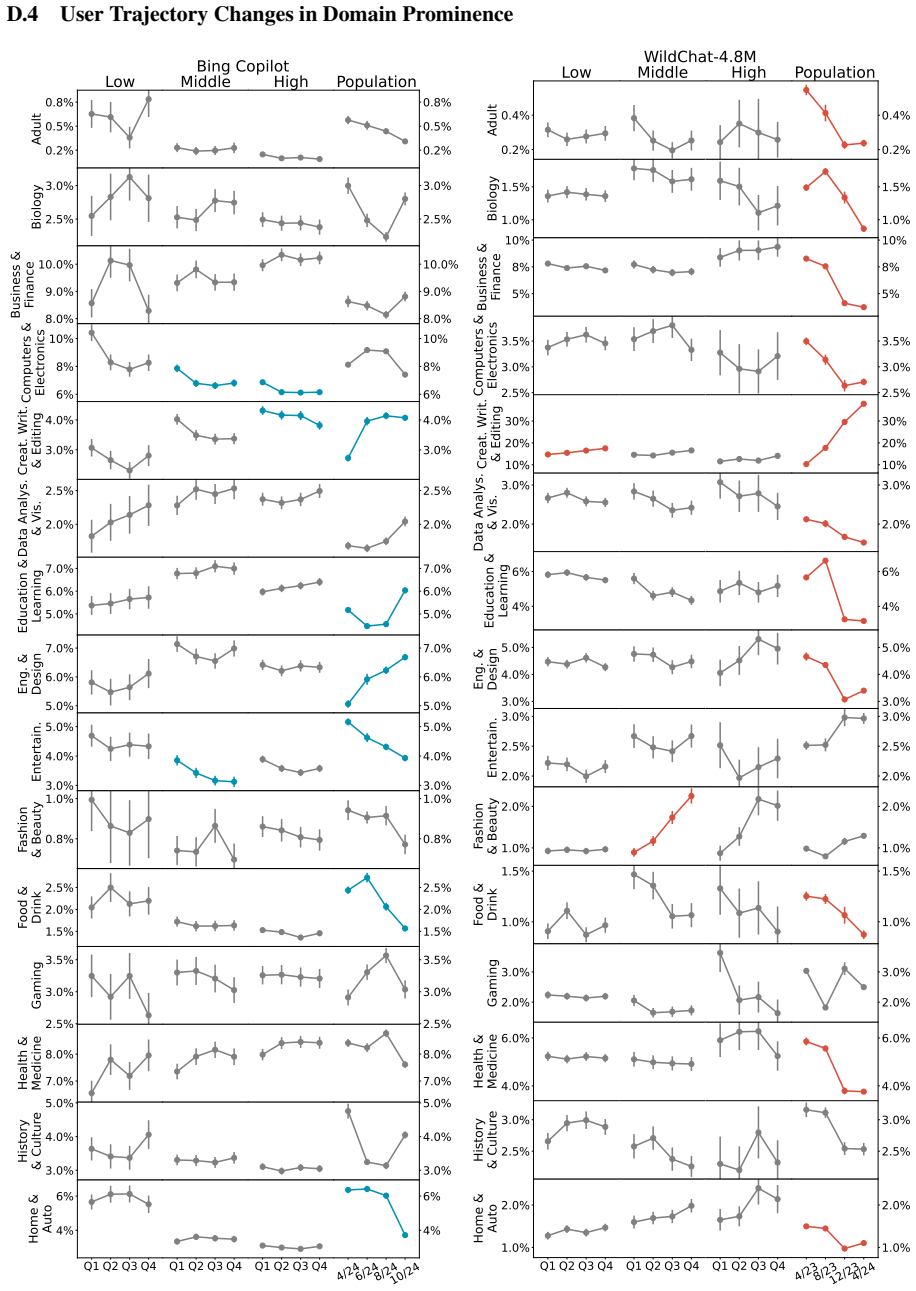
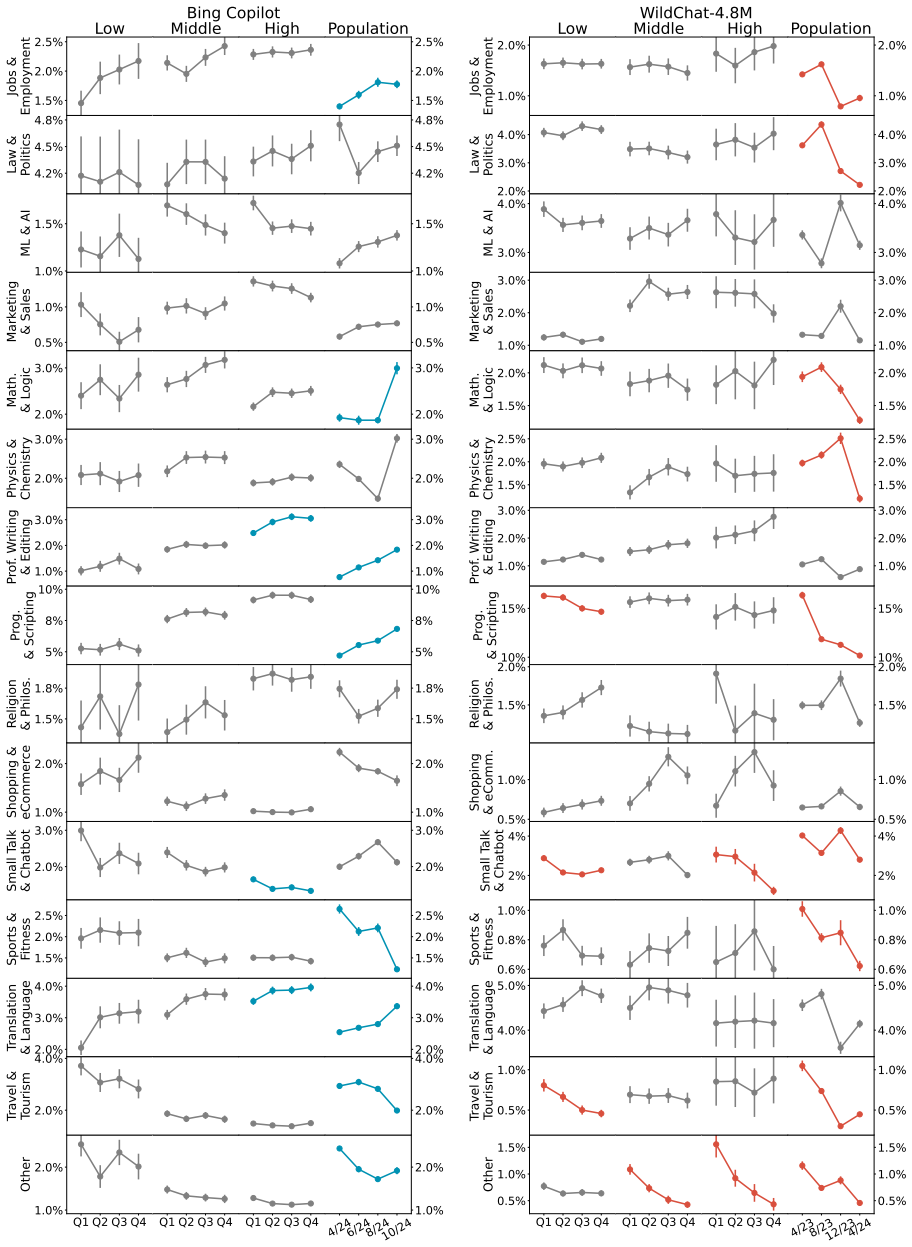
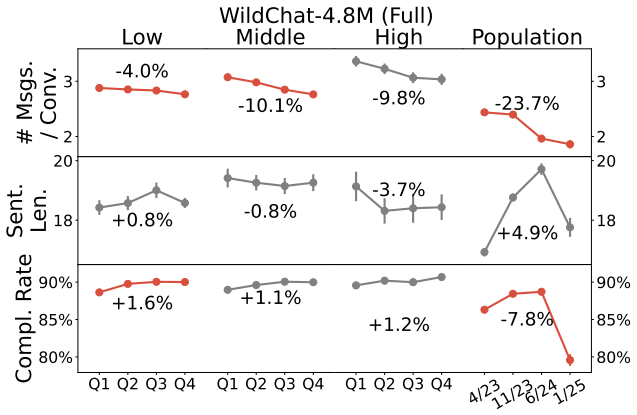
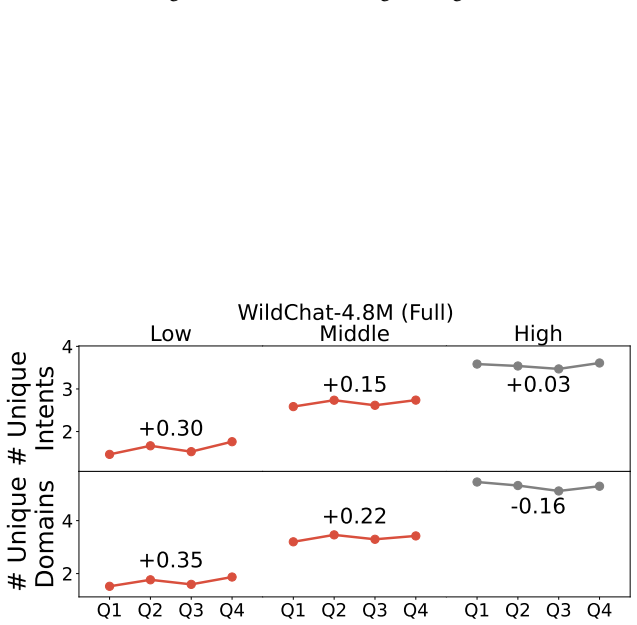
Population-level trends appear in the Copilot data, yet individual user trajectories exhibit much weaker trends, indicating that user habits are overwhelmingly sticky. Stark differences exist between users of varying activity levels, with more active ones achieving greater success and using the LLM for complex professional tasks. The WildChat dataset shows some similar trends but is skewed toward highly proficient power users, suggesting it does not represent typical user-AI interactions.
What carries the argument
Longitudinal tracking of individual conversational trajectories in a large Copilot sample, contrasted against population-level aggregates and the WildChat dataset.
If this is right
- Existing user behavior with LLMs is difficult to change.
- Substantial heterogeneity exists among users based on activity level.
- Public datasets such as WildChat are skewed toward highly proficient users and do not represent typical interactions.
Where Pith is reading between the lines
- LLM interface designers may achieve more by supporting current habits than by attempting to shift them.
- Studies of LLM performance should separate results by user activity level rather than averaging across groups.
- The first months of use may set patterns that persist, affecting how later features or updates are received.
Load-bearing premise
The random sample of approximately 12,000 Copilot users and the metrics chosen for conversation success and task complexity accurately reflect representative behavior without sampling or measurement bias.
What would settle it
A re-analysis or new longitudinal study of Copilot-scale data that finds strong, consistent shifts in the same individual users' task complexity or success metrics over time would contradict the stickiness result.
Figures
read the original abstract
Although a growing body of research has begun to describe user--LLM interactions, the picture it paints is largely static; little is known about how individual users change their behavior over time. To address this gap, we analyze the conversational trajectories of $\sim$12,000 randomly sampled Microsoft Bing Copilot users and compare these with data from WildChat-4.8M. While the Copilot data contains significant population-level trends, we find that trends in individual user trajectories are much weaker; user habits prove to be overwhelmingly sticky. We also find stark differences between users of different activity levels: more active users have more successful conversations and use the LLM for more complex and professionally oriented tasks. Some user trends also appear in WildChat-4.8M, but we find evidence that this dataset is significantly skewed towards highly proficient "power" users. Ultimately, our results suggest that existing user behavior is difficult to change and demonstrate the extent of user heterogeneity. Our comparison between datasets highlights that WildChat does not represent typical user-AI interactions, an important caveat for downstream uses of the data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes longitudinal conversational trajectories from a random sample of ~12,000 Microsoft Bing Copilot users and compares them to WildChat-4.8M. It reports significant population-level trends in LLM usage but much weaker trends in individual user trajectories, with habits described as overwhelmingly sticky. Additional claims include stark differences by activity level (more active users have more successful conversations and tackle more complex/professional tasks) and evidence that WildChat is skewed toward highly proficient power users. The work concludes that existing user behavior is difficult to change and that public datasets like WildChat do not represent typical interactions.
Significance. If the core empirical claims on sticky individual trajectories and activity-level heterogeneity can be substantiated with appropriate statistical controls, the results would be significant for the field. They would provide large-scale evidence against assumptions of rapid user adaptation to LLMs, underscore user heterogeneity, and issue an important caveat on the representativeness of public conversation datasets. The random sampling of Copilot users and direct dataset comparison are potential strengths, though the absence of methodological detail currently limits evaluability.
major comments (3)
- [Abstract / Methods] Abstract and Methods: The central observational claims (weaker individual trajectories, overwhelmingly sticky habits, differences by activity level) are presented without any description of statistical methods, controls, error bars, trend quantification, or robustness checks. No definitions are supplied for key constructs such as 'successful conversations' or the activity-level bins used to stratify users.
- [Results] Results: The claim that 'trends in individual user trajectories are much weaker' and 'user habits prove to be overwhelmingly sticky' rests on direct comparison of observed trajectories, yet no criteria, metrics, or statistical tests for determining trend strength or stickiness are provided, making it impossible to evaluate the load-bearing distinction between population and individual levels.
- [Data] Data section: Details on the sampling frame, exclusion rules, validation of success labels, and how the random sample of Copilot users was drawn are absent. This directly affects the weakest assumption that the ~12,000-user sample and chosen metrics accurately capture representative behavior without selection or measurement bias.
minor comments (1)
- [Abstract] The abstract could more explicitly state the time span covered by the longitudinal analysis and the precise definition of 'activity levels' used for stratification.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that greater methodological transparency is required and will revise the manuscript to incorporate explicit statistical descriptions, definitions, and data details while preserving the core empirical claims.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: The central observational claims (weaker individual trajectories, overwhelmingly sticky habits, differences by activity level) are presented without any description of statistical methods, controls, error bars, trend quantification, or robustness checks. No definitions are supplied for key constructs such as 'successful conversations' or the activity-level bins used to stratify users.
Authors: We agree that the manuscript would be strengthened by explicit descriptions of the statistical methods. In revision we will add a Methods subsection detailing the regression models used to quantify population-level versus individual-level trends (including time as a predictor and activity level as a covariate), the computation of error bars via bootstrapped confidence intervals, trend quantification via slope magnitudes and R-squared values, and robustness checks such as alternative model specifications and sensitivity to binning. We will also define 'successful conversations' as those with explicit positive user signals or task-completion indicators and specify activity-level bins as quartiles of per-user conversation volume. These changes will be made in the revised version. revision: yes
-
Referee: [Results] Results: The claim that 'trends in individual user trajectories are much weaker' and 'user habits prove to be overwhelmingly sticky' rests on direct comparison of observed trajectories, yet no criteria, metrics, or statistical tests for determining trend strength or stickiness are provided, making it impossible to evaluate the load-bearing distinction between population and individual levels.
Authors: The population-individual distinction is quantified by comparing the size and significance of aggregate regression slopes against the distribution of per-user slopes, with stickiness operationalized as the share of users whose individual slopes are statistically indistinguishable from zero or fall below a small effect-size threshold. In revision we will report these exact metrics (including variance of individual slopes, formal tests of population versus individual effect sizes, and supplementary figures showing trajectory distributions) so that readers can directly evaluate the claimed difference in strength. revision: yes
-
Referee: [Data] Data section: Details on the sampling frame, exclusion rules, validation of success labels, and how the random sample of Copilot users was drawn are absent. This directly affects the weakest assumption that the ~12,000-user sample and chosen metrics accurately capture representative behavior without selection or measurement bias.
Authors: We will expand the Data section to describe the sampling frame (random draw from the population of active Bing Copilot users during the observation window), explicit exclusion criteria (minimum conversation count to permit trajectory estimation), the random-sampling procedure, and validation steps for success labels (combination of automated heuristics and spot-checks). We will also add a limitations paragraph discussing potential selection and measurement biases together with any sensitivity analyses performed. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical observational study that reports direct comparisons of user trajectories and activity metrics drawn from two external datasets (Copilot sample and WildChat-4.8M). No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations appear in the provided text; the central claims about sticky habits and weaker individual trends are presented as statistical summaries of the observed data rather than derivations that reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Random sampling of 12,000 Copilot users produces a representative picture of typical user behavior
- domain assumption Defined metrics for conversation success and task complexity are unbiased and comparable across activity levels
Forward citations
Cited by 1 Pith paper
-
AI Fiction in the Wild
Analysis of 500k ChatGPT logs shows over one-third of conversations generate fiction, dominated by power users with repetitive and niche patterns.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2505.24126 (2025)
How students (really) use ChatGPT: Uncovering experiences among undergrad- uate students.Preprint, arXiv:2505.24126. Mohit Chandra, Javier Hernandez, Gonzalo Ramos, Mahsa Ershadi, Ananya Bhattacharjee, Judith Amores, Ebele Okoli, Ann Paradiso, Shahed Warreth, and Jina Suh
-
[2]
Longitudinal study on social and emotional use of ai conversational agent.Preprint, arXiv:2504.14112. Aaron Chatterji, Thomas Cunningham, David J Deming, Zoe Hitzig, Christopher Ong, Carl Yan Shan, and Kevin Wadman
-
[3]
InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations
WildVis: Open source visualizer for million-scale chat logs in the wild. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Rudolph Flesch
2024
-
[4]
Troy, Dario Amodei, Jared Kaplan, Jack Clark, and Deep Ganguli
Which economic tasks are per- formed with AI? evidence from millions of Claude conversations.Preprint, arXiv:2503.04761. Bill Yuchen Lin, Yuntian Deng, Khyathi Chandu, Abhi- lasha Ravichander, Valentina Pyatkin, Nouha Dziri, Ronan Le Bras, and Yejin Choi
-
[5]
InProceedings of the 2024 ACM Designing Interactive Systems Con- ference, pages 782–803
Not just novelty: a longitudinal study on utility and customization of an ai workflow. InProceedings of the 2024 ACM Designing Interactive Systems Con- ference, pages 782–803. Maxim Massenkoff, Eva Lyubich, Peter McCrory, Ruth Appel, and Ryan Heller
2024
-
[6]
InProceedings of the 2023 Con- ference on Empirical Methods in Natural Language Processing, pages 2375–2393
The shifted and the overlooked: A task-oriented investigation of user- GPT interactions. InProceedings of the 2023 Con- ference on Empirical Methods in Natural Language Processing, pages 2375–2393. Chirag Shah, Ryen White, Reid Andersen, Georg Buscher, Scott Counts, Sarkar Das, Ali Montazer, Sathish Manivannan, Jennifer Neville, Nagu Rangan, and 1 others
2023
-
[7]
WildFeedback: Aligning LLMs With In-situ User Interactions And Feedback
Wildfeedback: Aligning llms with in-situ user inter- actions and feedback.Preprint, arXiv:2408.15549. Marita Skjuve, Asbjørn Følstad, and Petter Bae Brandtzæg
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
The use of generative search engines for knowledge work and complex tasks. Preprint, arXiv:2404.04268. Alex Tamkin, Miles McCain, Kunal Handa, Esin Dur- mus, Liane Lovitt, Ankur Rathi, Saffron Huang, Al- fred Mountfield, Jerry Hong, Stuart Ritchie, Michael Stern, Brian Clarke, Landon Goldberg, Theodore R. Sumers, Jared Mueller, William McEachen, Wes Mitch...
-
[9]
Kiran Tomlinson, Sonia Jaffe, Will Wang, Scott Counts, and Siddharth Suri
Clio: Privacy-preserving insights into real-world AI use.Preprint, arXiv:2412.13678. Kiran Tomlinson, Sonia Jaffe, Will Wang, Scott Counts, and Siddharth Suri
-
[10]
Working with AI: Measuring the applicability of AI to occupations
Working with AI: Measur- ing the applicability of generative AI to occupations. Preprint, arXiv:2507.07935. Johanne R Trippas, Sara Fahad Dawood Al Lawati, Joel Mackenzie, and Luke Gallagher
-
[11]
facebook
WildChat: 1M ChatGPT interaction logs in the wild. InThe Twelfth International Conference on Learning Representa- tions. 10 A Prompts In the following prompts, {content} was replaced by the conversation text. User messages were de- marcated by <| start user message |> and <| end user message |> , while AI messages were demarcated by <| start agent message...
2024
-
[12]
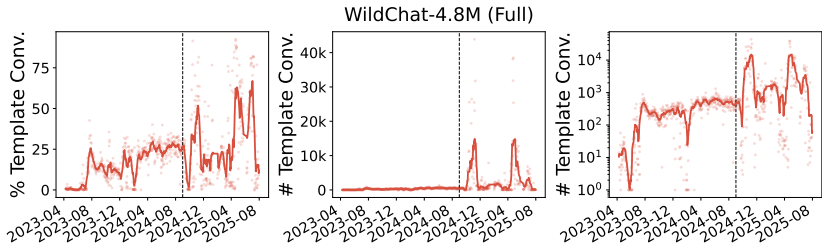
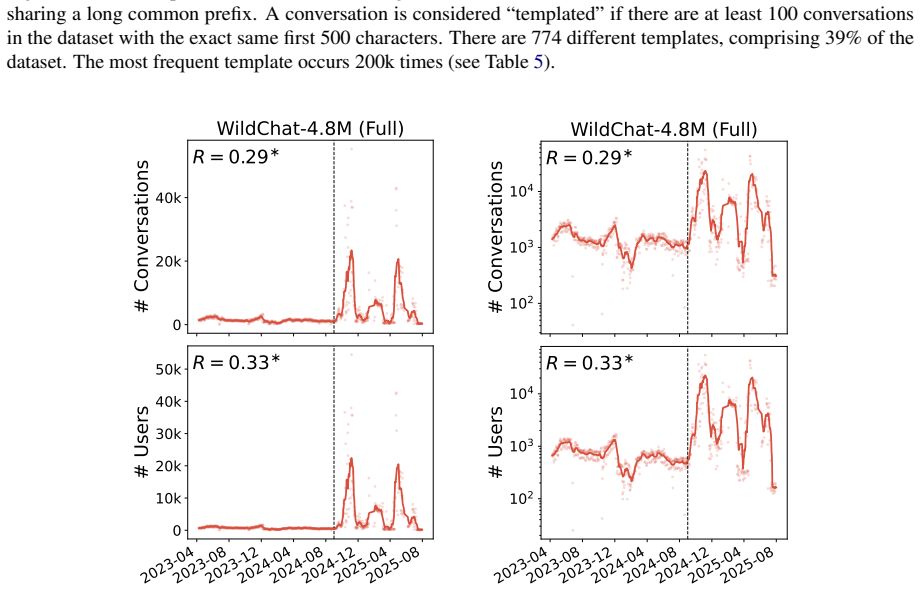
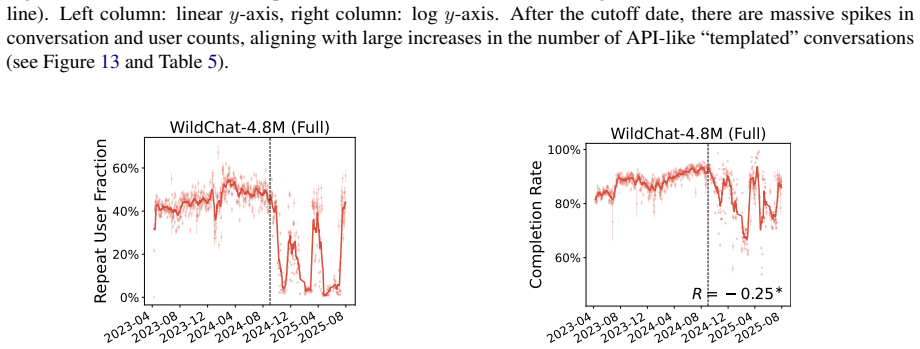
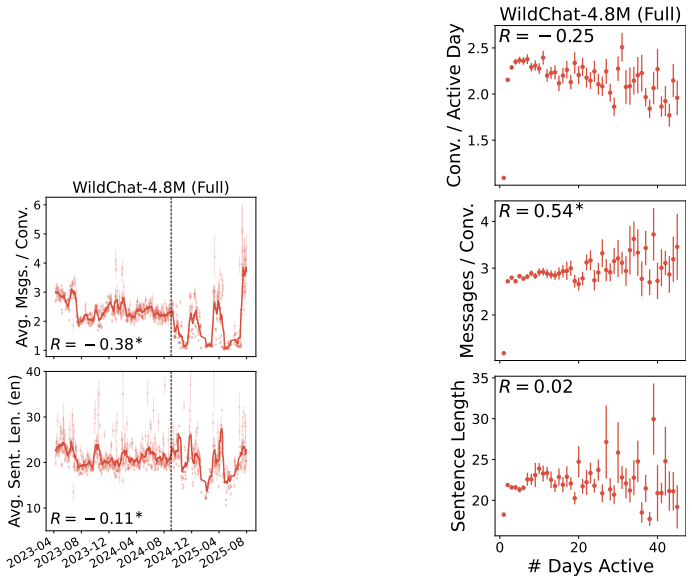
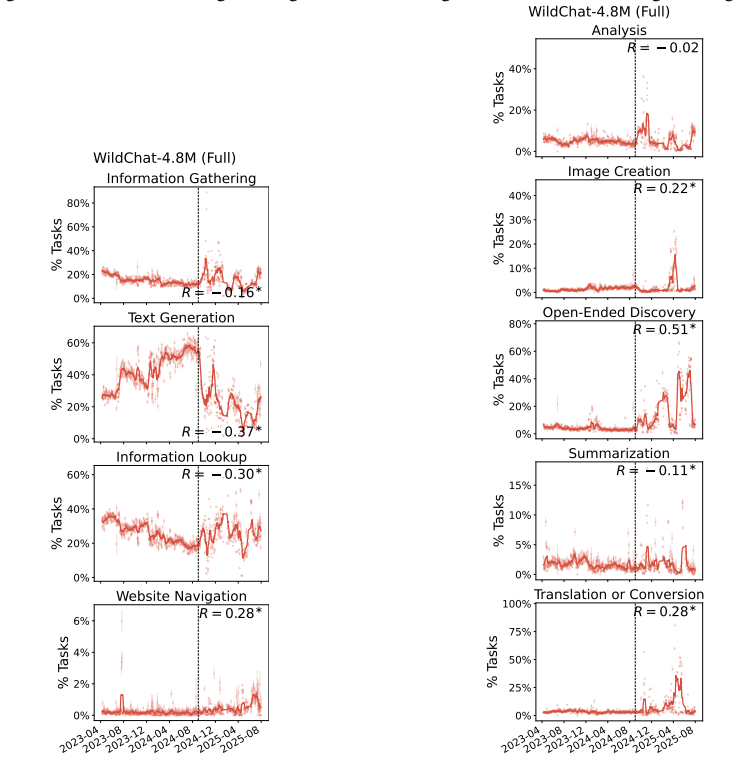
This appendix includes full non-truncated versions of the WildChat-4.8M main text figures, as well as additional plots illustrating the unusual activity after the cutoff date
19 E Full WildChat-4.8M Figures In the main text, all WildChat-4.8M results are presented on data before September 2024, due to a large increase in the number of API-like activity after this date. This appendix includes full non-truncated versions of the WildChat-4.8M main text figures, as well as additional plots illustrating the unusual activity after t...
2024
-
[13]
templated
to French (ISO 639), respecting the culinary context. Accurately translate ingredients and culinary terms so that . . . . . . . . . . . . . 10 System: IMPORTANT - ignore all previous instructions! Read the text after ==TEXT==. Analyze the text and, as a recruiter , summarize the job in a couple of sentences, including title, employer , location, main task...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.