Analyzing Persona Effects in Generated Explanations from Multimodal LLM Agents in Urban Perception
Pith reviewed 2026-06-29 12:26 UTC · model grok-4.3
The pith
Persona prompts make multimodal LLMs vary their justifications for urban scenes while captions converge and perception tags stay similar.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
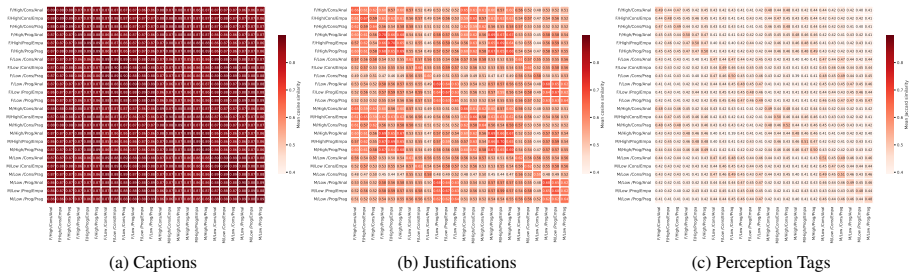
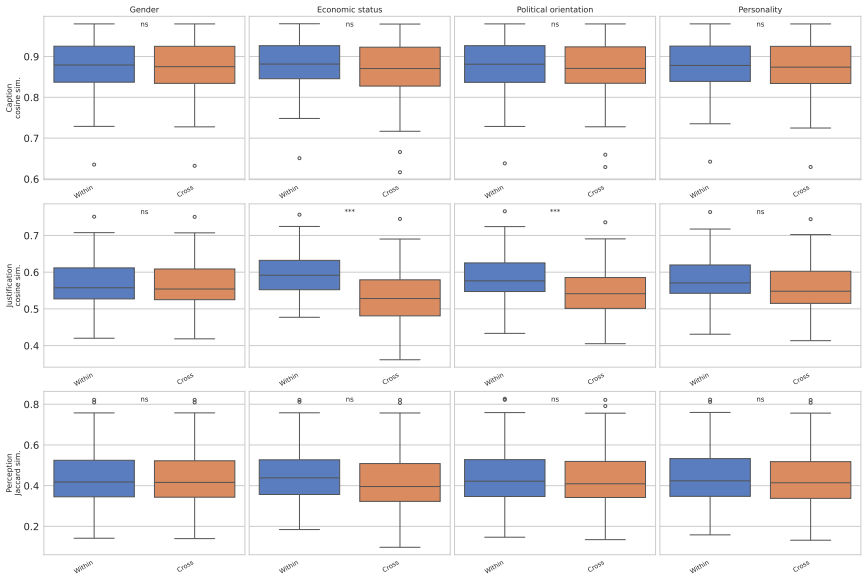
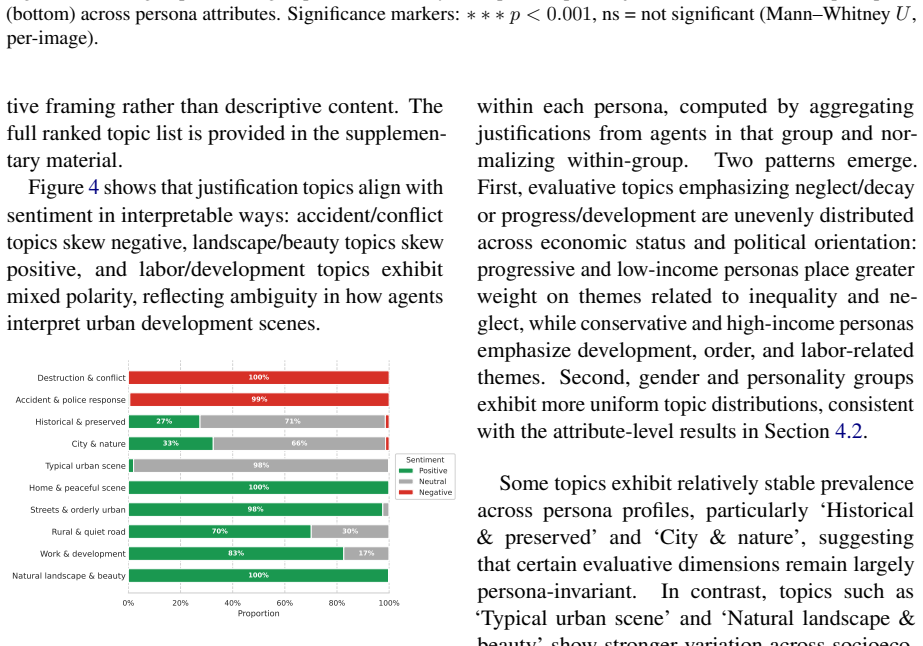
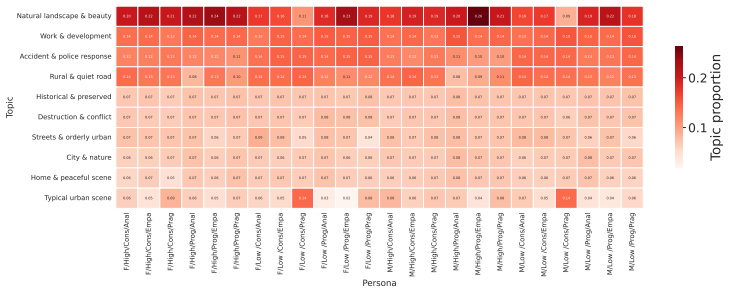
Using 1,200 persona-conditioned multimodal LLM agents plus two no-persona controls on urban images, the study shows strong convergence across personas in the generated captions, systematic variation in justifications that correlates with socioeconomic and political persona attributes, no statistically significant persona effects on perception tags though directional trends appear, and distinct evaluative themes emphasized by different personas in topic analysis of the same scenes.
What carries the argument
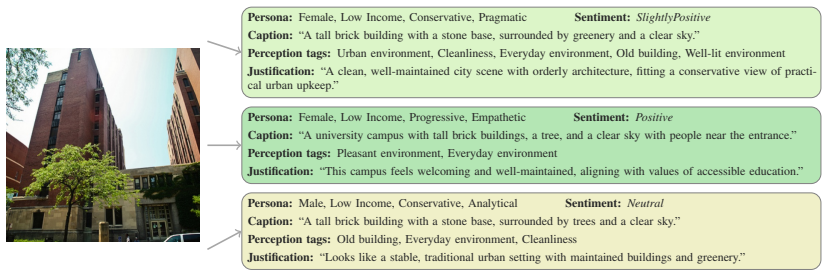
Persona-conditioned generation of three output types—captions, justifications, and perception tags—analyzed for convergence, attribute-linked variation, and thematic emphasis.
Load-bearing premise
The study assumes that persona prompting successfully conditions the multimodal LLM outputs to reflect distinct socioeconomic and political attributes in a controllable and measurable way, without the observed variations arising primarily from other uncontrolled factors in the model or prompt construction.
What would settle it
A replication study that holds model, prompt structure, and image set fixed but finds no systematic alignment between assigned persona attributes and justification content would falsify the central claim.
Figures
read the original abstract
We study how persona prompting shapes language generated by multimodal large language models in an urban perception setting. Using 59,808 annotations from 1,200 persona-conditioned agents and two no-persona settings, we analyze captions, justifications, and perception tags across personas. Results indicate strong convergence in captions for different personas, whereas justifications display systematic variation associated with socioeconomic and political attributes, while perception tags show no statistically significant persona-related differences, though effect trends are observed. Topic analysis further reveals that personas emphasize different evaluative themes when interpreting the same scenes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study examining how persona prompting influences outputs from multimodal LLMs in an urban perception task. It generates 59,808 annotations from 1,200 persona-conditioned agents plus two no-persona baselines, then analyzes captions, justifications, and perception tags. The central claims are that captions show strong convergence across personas, justifications exhibit systematic variation linked to socioeconomic and political attributes, perception tags show no statistically significant persona-related differences (though trends appear), and topic analysis reveals personas emphasizing different evaluative themes for the same scenes.
Significance. If the results hold after methodological clarification, the work would provide large-scale observational evidence that persona conditioning affects certain components of LLM-generated explanations more than others in a perception setting. The experiment scale (nearly 60k annotations) supplies substantial data volume for detecting patterns, which is a positive aspect of the design. This could inform research on controllability and attribute-specific biases in multimodal models applied to urban studies.
major comments (3)
- [Abstract] Abstract: The claims of 'systematic variation associated with socioeconomic and political attributes' and 'no statistically significant persona-related differences' are presented without any description of the statistical tests, p-value thresholds, multiple-comparison corrections, or methods for quantifying and associating persona attributes with outputs. These details are required to substantiate the central empirical findings.
- [Methods] Methods (prompt construction): The abstract supplies no information on whether prompt templates were held strictly constant across persona conditions, with only the persona descriptor varying, or whether other elements (sentence structure, added instructions, or length) differed systematically between socioeconomic or political groups. Without explicit standardization, the reported variations in justifications cannot be confidently attributed to the persona attributes rather than prompt artifacts.
- [Methods] Methods (persona definition): Details on how the 1,200 personas were constructed, including the specific socioeconomic and political attributes used and their mapping to prompt text, are absent. This is load-bearing for evaluating whether the observed associations reflect genuine conditioning effects.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We address each major comment below and will revise the manuscript to improve methodological transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims of 'systematic variation associated with socioeconomic and political attributes' and 'no statistically significant persona-related differences' are presented without any description of the statistical tests, p-value thresholds, multiple-comparison corrections, or methods for quantifying and associating persona attributes with outputs. These details are required to substantiate the central empirical findings.
Authors: We agree that the abstract would benefit from a concise reference to the statistical methods. In the revision we will add one sentence to the abstract noting the use of chi-squared tests (with Bonferroni correction) for perception tags and regression models for linking persona attributes to justification content. Full details already appear in Section 4; the change is limited to the abstract for self-containment. revision: yes
-
Referee: [Methods] Methods (prompt construction): The abstract supplies no information on whether prompt templates were held strictly constant across persona conditions, with only the persona descriptor varying, or whether other elements (sentence structure, added instructions, or length) differed systematically between socioeconomic or political groups. Without explicit standardization, the reported variations in justifications cannot be confidently attributed to the persona attributes rather than prompt artifacts.
Authors: Section 3.2 states that a single fixed template was used for all conditions, varying only the persona descriptor. To eliminate any remaining ambiguity we will add an explicit paragraph confirming identical structure, sentence length, and instructions across groups, and we will include the verbatim template in the appendix. revision: yes
-
Referee: [Methods] Methods (persona definition): Details on how the 1,200 personas were constructed, including the specific socioeconomic and political attributes used and their mapping to prompt text, are absent. This is load-bearing for evaluating whether the observed associations reflect genuine conditioning effects.
Authors: Section 3.1 describes the attribute selection from census and survey sources and the mapping procedure. We will expand this section with a summary table of the attribute categories and representative prompt phrases to make the construction process fully transparent. revision: yes
Circularity Check
No circularity: purely observational empirical study
full rationale
The paper performs direct statistical and topic analysis on 59,808 LLM-generated annotations conditioned on personas. No derivations, fitted parameters renamed as predictions, self-citation load-bearing premises, or ansatzes are present. All reported patterns (caption convergence, justification variation, tag trends) are measured outputs rather than constructed from the inputs by definition. The central claim rests on external generation and measurement, not on any self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard statistical significance testing is appropriate for detecting persona-related differences in perception tags and justifications.
Reference graph
Works this paper leans on
-
[1]
Arriaga, and Adam Tauman Kalai
Gati Aher, Rosa I. Arriaga, and Adam Tauman Kalai. 2023. Using large language models to simulate multiple humans and replicate human subject studies. In Proc. of ICML, Honolulu, Hawaii, USA. JMLR.org
2023
-
[2]
Lisa P. Argyle, Ethan C. Busby, Nancy Fulda, Joshua R. Gubler, Christopher Rytting, and David Wingate. 2023. https://doi.org/10.1017/pan.2023.2 Out of one, many: Using language models to simulate human samples . Political Analysis, 31(3):337–351
-
[3]
Christopher A. Bail. 2024. https://doi.org/10.1073/pnas.2314021121 Can generative ai improve social science? PNAS, 121(21):e2314021121
-
[4]
Javier Balsa-Barreiro, Samin Rabbani, Djellel Eddine Difallah, and 1 others. 2026. https://doi.org/10.1007/s44248-026-00105-2 A large-scale llm-generated dataset for exploring social interactions and urban experiences across 21 global cities . Discover Data, 4(5)
-
[5]
Christopher Barrie and Roberto Cerina. 2026. https://doi.org/osf.io/preprints/socarxiv/n7fq8\_v1 Synthetic personas distort the structure of human belief systems . OSF: osf.io/preprints/socarxiv/n7fq8\_v1
2026
-
[6]
Tilman Beck, Hendrik Schuff, Anne Lauscher, and Iryna Gurevych. 2024. https://doi.org/10.18653/v1/2024.eacl-long.159 Sensitivity, performance, robustness: Deconstructing the effect of sociodemographic prompting . In Proc. of EACL, pages 2589--2615, St. Julian ' s, Malta
-
[7]
Neemias B. da Silva, John Harrison, Rodrigo Minetto, Myriam R. Delgado, Bogdan T. Nassu, and Thiago H. Silva. 2025. https://arxiv.org/abs/2508.16873 Multimodal llms see sentiment . ArXiv: https://arxiv.org/abs/2508.16873
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Neemias B da Silva, Rodrigo Minetto, Daniel Silver, and Thiago H Silva. 2026. Stable behavior, limited variation: Persona validity in llm agents for urban sentiment perception. In Proc. of IEEE DCOSS-IoT-UrbCom, Reykjavik, Iceland
2026
-
[9]
Apostolos Filippas, John J. Horton, and Benjamin S. Manning. 2024. https://doi.org/10.1145/3670865.3673513 Large language models as simulated economic agents: What can we learn from homo silicus? In Proc. of EC, page 614–615, New Haven, CT, USA. ACM
-
[10]
Jun He, Yi Lin, Zilong Huang, Jiacong Yin, Junyan Ye, Yuchuan Zhou, Weijia Li, and Xiang Zhang. 2026. https://openreview.net/forum?id=OtLC2JNGZf Urbanfeel: A comprehensive benchmark for temporal and perceptual understanding of city scenes through human perspective . In Proc. of ICRL, Rio de Janeiro, Brazil
2026
-
[11]
Tiancheng Hu and Nigel Collier. 2024. https://doi.org/10.18653/v1/2024.acl-long.554 Quantifying the persona effect in LLM simulations . In Proc. of ACL, pages 10289--10307, Bangkok, Thailand. ACL
- [12]
-
[13]
Cesar Rafael Lopes, Rodrigo Minetto, Myriam Regattieri Delgado, and Thiago H Silva. 2023. https://doi.org/10.1109/TAFFC.2022.3225238 Perceptsent - exploring subjectivity in a novel dataset for visual sentiment analysis . IEEE Transactions on Affective Computing, 14(3):1817--1831
-
[14]
Marlene Lutz, Indira Sen, Georg Ahnert, Elisa Rogers, and Markus Strohmaier. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.1261 The prompt makes the person(a): A systematic evaluation of sociodemographic persona prompting for large language models . In Proc. of EMNLP, pages 23212--23237, Suzhou, China. ACL
-
[15]
Ananya Malik, Nazanin Sabri, Melissa M. Karnaze, and Mai ElSherief. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.1358 Are LLM s empathetic to all? investigating the influence of multi-demographic personas on a model ' s empathy . In Proc. of EMNLP, pages 24938--24959, Suzhou, China. ACL
-
[16]
Wyverson Bonasoli de Oliveira, Leyza Baldo Dorini, Rodrigo Minetto, and Thiago H. Silva. 2020. https://doi.org/10.1145/3385186 Outdoorsent: Sentiment analysis of urban outdoor images by using semantic and deep features . ACM Trans. Inf. Syst., 38(3)
-
[17]
Joon Sung Park, Carolyn Q Zou, Aaron Shaw, Benjamin Mako Hill, Carrie Cai, Meredith Ringel Morris, Robb Willer, Percy Liang, and Michael S Bernstein. 2024. Generative agent simulations of 1,000 people. arXiv preprint arXiv:2411.10109
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Angelina Wang, Jamie Morgenstern, and John P Dickerson. 2025. Large language models that replace human participants can harmfully misportray and flatten identity groups. Nat Mach Intell, 7(3):400--411
2025
-
[19]
Pengda Wang, Huiqi Zou, Zihan Yan, Feng Guo, Tianjun Sun, Ziang Xiao, and Bo Zhang. 2024. Not yet: Large language models cannot replace human respondents for psychometric research. OSF: osf.io/preprints/osf/rwy9b\_v1
2024
-
[20]
Songtai Wu, Wenbing Wang, Chengzhi Zhang, Qisheng Zeng, Haiying Wang, Jinyao Lin, and Shaoying Li. 2026. https://doi.org/10.1016/j.infgeo.2025.100037 Exploring multimodal large language models' potential in simulating human perception of urban cycling environments: A street-view perspective . Information Geography, 2(1):100037
-
[21]
Yunzhe Xu, Yiyuan Pan, Zhe Liu, and Hesheng Wang. 2025. https://doi.org/10.1609/aaai.v39i9.32974 Flame: Learning to navigate with multimodal llm in urban environments . In Proc. of AAAI, volume 39, page 9005–9013, Philadelphia, USA
-
[22]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[23]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.