The Confidence Shortcut: A Reasoning Failure Mode of Masked Diffusion Models
Pith reviewed 2026-06-29 11:41 UTC · model grok-4.3
The pith
Confidence-based decoding in masked diffusion models produces high-confidence errors on complex reasoning by skipping logical dependencies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
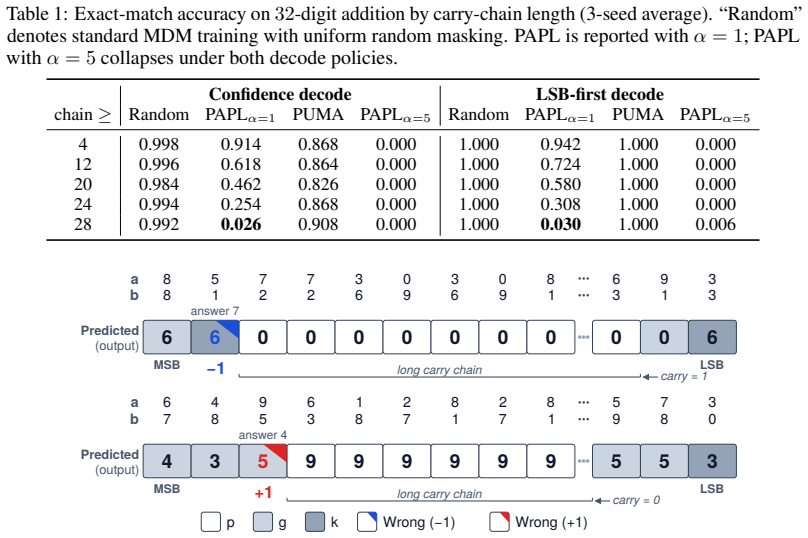
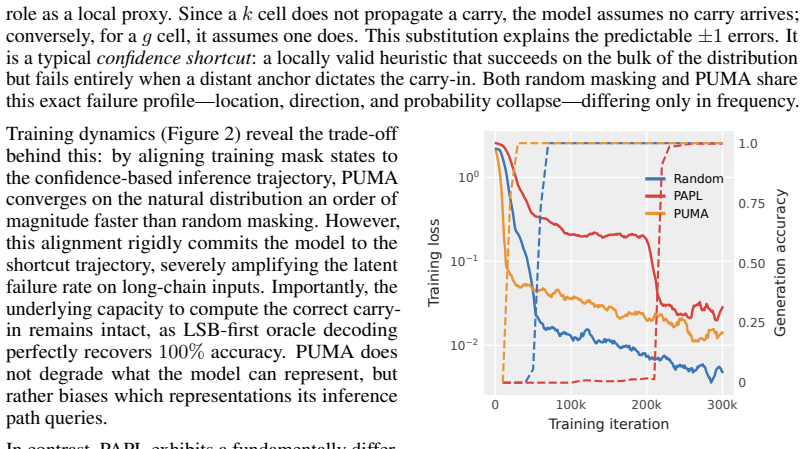
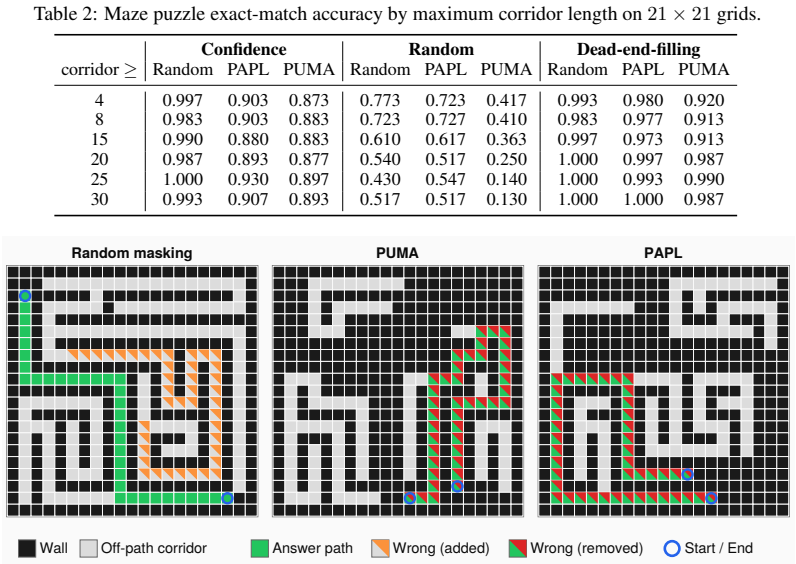
Confidence-based decoding is inherently misaligned with the logical-flow trajectories required for complex reasoning, and that confidence-aligned training actively entrenches this misalignment. On multi-digit addition the strategy prematurely predicts locally easy digits before resolving their long-range dependencies, producing high-confidence errors on challenging inputs. While traditional random masking keeps the failure rate low on this challenging tail, confidence-aligned training amplifies the error rate by an order of magnitude. Across five distinct reasoning tasks this same pattern emerges with task-dependent severity: confidence-based decoding induces failures on highly complex input
What carries the argument
Confidence-based decoding, which selects the next token by highest model confidence instead of logical dependency order during any-order generation.
If this is right
- Confidence-based decoding induces failures on highly complex inputs.
- Confidence-aligned training exacerbates errors on challenging cases by an order of magnitude.
- Random masking maintains low failure rates on the difficult tail despite lower perceived efficiency.
- The misalignment appears across multiple reasoning tasks with varying severity.
Where Pith is reading between the lines
- Alternative decoding rules that enforce dependency order before confidence might reduce these errors.
- Training objectives could be redesigned to reward preservation of full logical trajectories rather than early confident guesses.
- The same shortcut may affect any generative model whose inference favors local certainty over global consistency.
Load-bearing premise
The error patterns on multi-digit addition and the five reasoning tasks are produced by the decoding strategy and training alignment rather than by other model or data factors.
What would settle it
Running the same trained model on multi-digit addition with confidence decoding versus random-order decoding and checking whether the high-confidence error rate drops sharply under the latter.
Figures
read the original abstract
Masked diffusion language models (MDMs) uniquely support any-order generation, with confidence-based decoding currently serving as the de facto standard inference policy. To optimize for this, recent training schemes attempt to align training mask patterns directly with those observed during generation. However, we argue that confidence-based decoding is inherently misaligned with the logical-flow trajectories required for complex reasoning, and that confidence-aligned training actively entrenches this misalignment. We make this concrete using multi-digit addition, where the decoding strategy prematurely predicts locally easy digits before resolving their long-range dependencies, producing high-confidence errors on challenging inputs. While traditional random masking keeps the failure rate low on this challenging tail, confidence-aligned training amplifies the error rate by an order of magnitude. Across five distinct reasoning tasks, this same pattern emerges with task-dependent severity: confidence-based decoding induces failures on highly complex inputs, and confidence-aligned training exacerbates them. In contrast, random masking -- despite its perceived inefficiency -- robustly preserves the reasoning-trajectory conditionals essential for solving the challenging tail.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that confidence-based decoding is inherently misaligned with the logical-flow trajectories required for complex reasoning in masked diffusion language models (MDMs), and that confidence-aligned training actively entrenches this misalignment. It supports this via multi-digit addition experiments showing premature local predictions and order-of-magnitude error amplification under confidence-aligned training versus random masking, with analogous patterns (task-dependent severity) observed across five reasoning tasks where random masking better preserves performance on challenging inputs.
Significance. If the central empirical patterns hold after controls, the result would be significant for MDM research: it identifies a concrete failure mode in the de facto inference policy and its training alignment, with direct implications for using these models on reasoning tasks. The explicit contrast to random masking (despite its inefficiency) supplies a useful baseline and falsifiable prediction about tail performance.
major comments (2)
- [§4] §4 (multi-digit addition): the central claim that confidence-based decoding causes premature local predictions breaking long-range dependencies requires isolating the decoding strategy from training-objective differences; the reported order-of-magnitude amplification is shown only under joint changes to both, leaving open whether the effect is attributable to decoding alone or to other factors such as mask distribution.
- [§5] §5 (five reasoning tasks): the attribution of failures to misalignment with 'logical-flow trajectories' is load-bearing for the broader conclusion, yet the manuscript provides no formal characterization or metric for these trajectories and reports no ablation holding model capacity and data fixed while swapping only the inference-time decoding policy.
minor comments (1)
- [Abstract] Abstract: the five tasks are not named; listing them would allow readers to assess how representative they are of the claimed class of reasoning problems.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Below we respond point-by-point to the major comments, clarifying the scope of our claims and committing to targeted revisions that strengthen the isolation of effects.
read point-by-point responses
-
Referee: [§4] §4 (multi-digit addition): the central claim that confidence-based decoding causes premature local predictions breaking long-range dependencies requires isolating the decoding strategy from training-objective differences; the reported order-of-magnitude amplification is shown only under joint changes to both, leaving open whether the effect is attributable to decoding alone or to other factors such as mask distribution.
Authors: The manuscript emphasizes the practical combination of confidence-aligned training and confidence-based decoding, which is the de facto standard for MDMs and the setting in which the shortcut manifests most strongly. The order-of-magnitude gap versus random masking therefore reflects this joint regime. We agree that isolating the decoding policy alone would sharpen the attribution. In the revision we will add an ablation that fixes the training objective (random masking) and varies only the inference-time decoding policy on the identical model and data, directly testing whether the premature local predictions arise from the decoding strategy itself. revision: yes
-
Referee: [§5] §5 (five reasoning tasks): the attribution of failures to misalignment with 'logical-flow trajectories' is load-bearing for the broader conclusion, yet the manuscript provides no formal characterization or metric for these trajectories and reports no ablation holding model capacity and data fixed while swapping only the inference-time decoding policy.
Authors: The phrase 'logical-flow trajectories' is used descriptively to denote the ordered resolution of long-range dependencies required by each task (e.g., carry propagation in addition). The multi-digit addition experiments supply a concrete, verifiable instance of this ordering. While we do not supply a general formal metric, the consistent pattern across five tasks supports the empirical claim. To meet the request for a controlled ablation, the revised manuscript will include results obtained from models trained under a single fixed objective, with model capacity and data held constant, while only the inference-time decoding policy is swapped. revision: yes
Circularity Check
No circularity; empirical argument with no derivations or self-referential fits
full rationale
The paper advances its central claim through empirical comparisons of error rates under confidence-based vs. random masking on addition and reasoning tasks. No equations, parameter-fitting steps, or derivations appear in the abstract or described content. The argument does not reduce any prediction or uniqueness claim to a self-citation chain or input by construction; observed patterns are presented as evidence rather than tautological outputs of the method itself. This is the expected non-finding for an empirical study without mathematical self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LogicDiff: Logic-Guided Denoising Improves Zero-Shot Reasoning in Masked Diffusion Language Models
Shaik Aman. Logicdiff: Logic-guided denoising improves reasoning in masked diffusion language models.arXiv preprint arXiv:2603.26771,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Hikaru Asano, Tadashi Kozuno, Kuniaki Saito, and Yukino Baba. Where-to-unmask: Ground- truth-guided unmasking order learning for masked diffusion language models.arXiv preprint arXiv:2602.09501,
-
[3]
Changxiao Cai and Gen Li. Confidence-based decoding is provably efficient for diffusion language models.arXiv preprint arXiv:2603.22248,
-
[4]
Stream of search (sos): Learning to search in language.arXiv preprint arXiv:2404.03683,
Kanishk Gandhi, Denise Lee, Gabriel Grand, Muxin Liu, Winson Cheng, Archit Sharma, and Noah D Goodman. Stream of search (sos): Learning to search in language.arXiv preprint arXiv:2404.03683,
-
[5]
Shansan Gong, Ruixiang Zhang, Huangjie Zheng, Jiatao Gu, Navdeep Jaitly, Lingpeng Kong, and Yizhe Zhang. Diffucoder: Understanding and improving masked diffusion models for code generation.arXiv preprint arXiv:2506.20639,
-
[6]
Zemin Huang, Zhiyang Chen, Zijun Wang, Tiancheng Li, and Guo-Jun Qi. Reinforcing the diffusion chain of lateral thought with diffusion language models.arXiv preprint arXiv:2505.10446,
-
[7]
Michael Igorevich Ivanitskiy, Rusheb Shah, Alex F Spies, Tilman Räuker, Dan Valentine, Can Rager, Lucia Quirke, Chris Mathwin, Guillaume Corlouer, Cecilia Diniz Behn, et al. A configurable library for generating and manipulating maze datasets.arXiv preprint arXiv:2309.10498,
-
[8]
Seemingly Simple Planning Problems are Computationally Challenging: The Countdown Game
Michael Katz, Harsha Kokel, and Sarath Sreedharan. Seemingly simple planning problems are computationally challenging: The countdown game.arXiv preprint arXiv:2508.02900,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Stop Training for the Worst: Progressive Unmasking Accelerates Masked Diffusion Training
Jaeyeon Kim, Jonathan Geuter, David Alvarez-Melis, Sham Kakade, and Sitan Chen. Stop training for the worst: Progressive unmasking accelerates masked diffusion training.arXiv preprint arXiv:2602.10314, 2026b. Nayoung Lee, Kartik Sreenivasan, Jason D. Lee, Kangwook Lee, and Dimitris Papailiopoulos. Teaching arithmetic to small transformers. InICLR,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution.arXiv preprint arXiv:2310.16834,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji- Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data
Jingyang Ou, Shen Nie, Kaiwen Xue, Fengqi Zhu, Jiacheng Sun, Zhenguo Li, and Chongxuan Li. Your absorbing discrete diffusion secretly models the conditional distributions of clean data.arXiv preprint arXiv:2406.03736,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Earl J St Sauver. Think first, diffuse fast: Improving diffusion language model reasoning via autoregressive plan conditioning.arXiv preprint arXiv:2603.13243,
-
[14]
URL https: //github.com/t-dillon/tdoku. Guan Wang, Jin Li, Yuhao Sun, Xing Chen, Changling Liu, Yue Wu, Meng Lu, Sen Song, and Yasin Abbasi Yadkori. Hierarchical reasoning model.arXiv preprint arXiv:2506.21734, 2025a. Guanghan Wang, Gilad Turok, Yair Schiff, Marianne Arriola, and V olodymyr Kuleshov. d2: Improved techniques for training reasoning diffusio...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
First, we train small task-specific transformers (≈0.4 M to ≈21 M parameters) and use greedy (deterministic) decoding throughout
11 A Limitations Two methodological assumptions deserve mention. First, we train small task-specific transformers (≈0.4 M to ≈21 M parameters) and use greedy (deterministic) decoding throughout. The confidence- shortcut mechanism plausibly persists at larger scales and under stochastic decoding—locally-easy positions whose values depend on long unresolved...
2021
-
[16]
show an entropy-sum variant is provably efficient under conditions unrelated to logical-flow structure. Structural alternatives to confidence decoding have also been proposed: logic-role classifiers that unmask premises first [Aman, 2026], planners that imitate ground-truth oracles [Asano et al., 2026], and autoregressive plans prepended as frozen scaffol...
2026
-
[17]
Set sizes.Train: 20,000 instances
Under uniform operand sampling, chains of length≥28appear in well under1%of training samples. Set sizes.Train: 20,000 instances. Test: 10,000 random instances plus 500 instances per stratifica- tion level for the carry-chain sweep. C.2 Maze Task and source.We adapt the maze-completion task of Ivanitskiy et al. [2023]: given the start and goal positions of...
2023
-
[18]
no stepping stone
with operatorsMIN,MAX,MEDIANandSUM-MOD-10, restricted to operands 0–9. We modify the original formulation to require the model to produce intermediate values for every sub-expression, not only the root, so the answer region exposes the full computation graph. Vocabulary.Digits 0–9, operator characters X (MAX), N (MIN), D (MEDIAN), S (SUM-MOD-10), brackets...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.