Multi-Resolution End-to-End Deep Neural Network for Optimizing Latency-Accuracy Tradeoff in Autonomous Driving
Pith reviewed 2026-06-29 11:20 UTC · model grok-4.3
The pith
A multi-resolution CNN selects input scale at runtime to improve safety metrics under a latency budget in autonomous driving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A convolutional neural network equipped with per-resolution batch normalization and resolution retargeting can choose its input resolution dynamically at inference time to respect a latency budget, resulting in lower rates of lane invasions, red-light violations, and collisions across CARLA driving routes than any single fixed-resolution counterpart.
What carries the argument
per-resolution batch normalization, which normalizes activations separately for each supported input resolution to support stable training and runtime scale selection
Load-bearing premise
Per-resolution batch normalization combined with resolution retargeting enables effective multi-resolution training and runtime selection without introducing significant accuracy loss or training instability compared to standard single-resolution training.
What would settle it
Evaluating the multi-resolution model on identical CARLA routes against the strongest fixed-resolution baseline and observing no reduction in lane invasions, red-light infractions, or collisions.
Figures

read the original abstract
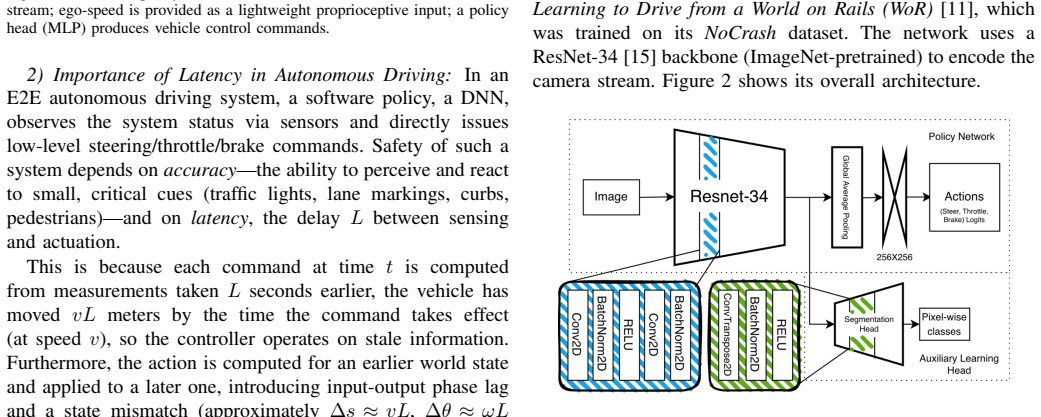
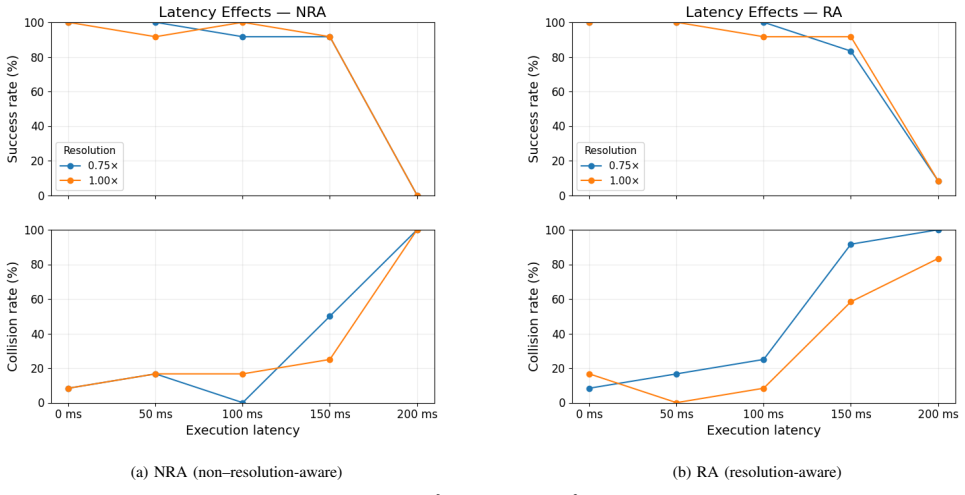
Latency-accuracy tradeoffs are fundamental in real-time applications of deep neural networks (DNNs) for cyber-physical systems. In autonomous driving, in particular, safety depends on both prediction quality and the end-to-end delay from sensing to actuation. We observe that (1) when latency is accounted for, the latency-optimal network configuration varies with scene context and compute availability; and (2) a single fixed-resolution model becomes suboptimal as conditions change. We present a multi-resolution, end-to-end deep neural network for the CARLA urban driving challenge using monocular camera input. Our approach employs a convolutional neural network (CNN) that supports multiple input resolutions through per-resolution batch normalization, enabling runtime selection of an ideal input scale under a latency budget, as well as resolution retargeting, which allows multi-resolution training without access to the original training dataset. We implement and evaluate our multi-resolution end-to-end CNN in CARLA to explore the latency-safety frontier. Results show consistent improvements in per-route safety metrics - lane invasions, red-light infractions, and collisions - relative to fixed-resolution baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a multi-resolution end-to-end CNN for the CARLA urban driving task that uses per-resolution batch normalization and resolution retargeting to support runtime input-scale selection under latency constraints. It claims that this architecture yields consistent improvements in per-route safety metrics (lane invasions, red-light infractions, collisions) relative to fixed-resolution baselines.
Significance. If the multi-resolution model truly matches or exceeds the per-scale accuracy of dedicated single-resolution models, the approach would provide a practical mechanism for context-aware latency-accuracy adaptation in real-time cyber-physical systems. The resolution-retargeting technique for training without the original dataset is a pragmatic engineering contribution.
major comments (1)
- [Abstract] The headline safety-metric gains rest on the assumption that the shared multi-resolution model, when evaluated at any chosen scale, performs at least as well as a model trained from scratch at that exact scale. No ablation, per-resolution accuracy table, or direct comparison of multi-resolution weights against single-resolution counterparts at identical input resolutions is supplied; without this evidence the observed gains cannot be attributed to the multi-resolution capability rather than unequal training effort or baseline construction.
minor comments (1)
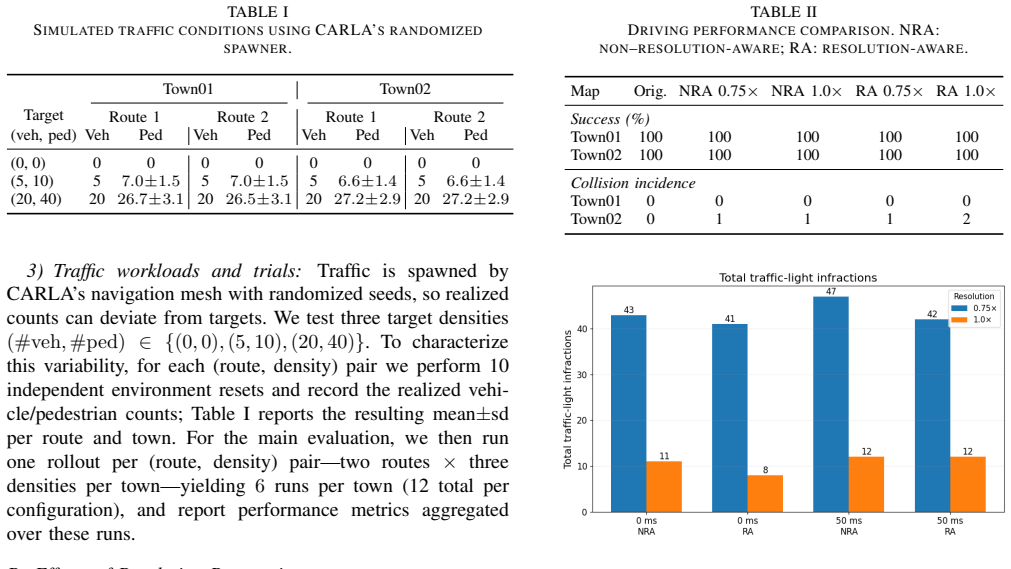
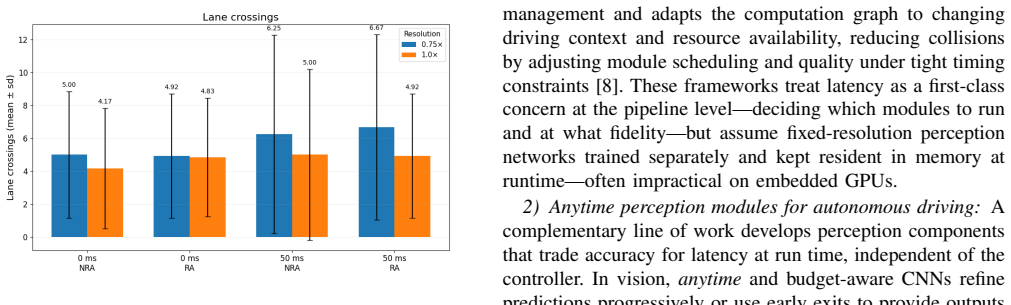
- The abstract states that results were obtained in CARLA but provides no information on the number of routes, evaluation protocol, statistical significance, or variance across runs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The major comment correctly identifies a missing comparison that is needed to strengthen the attribution of results to the multi-resolution design. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] The headline safety-metric gains rest on the assumption that the shared multi-resolution model, when evaluated at any chosen scale, performs at least as well as a model trained from scratch at that exact scale. No ablation, per-resolution accuracy table, or direct comparison of multi-resolution weights against single-resolution counterparts at identical input resolutions is supplied; without this evidence the observed gains cannot be attributed to the multi-resolution capability rather than unequal training effort or baseline construction.
Authors: We agree that a direct per-resolution comparison is required to substantiate the claims. The current manuscript does not include an ablation table contrasting the multi-resolution model (evaluated at each scale) against dedicated single-resolution models trained from scratch at the same resolutions. In the revised manuscript we will add this ablation, reporting lane invasions, red-light infractions, and collisions for both the shared model and the scale-specific baselines at each input resolution. This will allow readers to verify that performance is preserved or improved by the multi-resolution architecture (including per-resolution batch normalization) rather than differences in training effort. revision: yes
Circularity Check
No circularity; empirical evaluation of multi-resolution architecture
full rationale
The paper proposes a multi-resolution CNN using per-resolution batch normalization and resolution retargeting, then evaluates it empirically in the CARLA simulator against fixed-resolution baselines. All load-bearing claims (safety metric improvements) rest on reported simulator runs rather than any derivation, fitted parameter renamed as prediction, or self-citation chain. No equations, uniqueness theorems, or ansatzes are invoked that could reduce to the inputs by construction. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
End to End Learning for Self-Driving Cars
M. Bojarski, D. Del Testa, D. Dworakowski, B. Firner, B. Flepp, P. Goyal, L. D. Jackel, M. Monfort, U. Mulleret al., “End to end learning for self-driving cars,”arXiv:1604.07316, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
End- to-end driving via conditional imitation learning,
F. Codevilla, M. M ¨uller, A. L´opez, V . Koltun, and A. Dosovitskiy, “End- to-end driving via conditional imitation learning,” inICRA. IEEE, 2018
2018
-
[3]
End-to-end autonomous driving: Challenges and frontiers,
L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger, and H. Li, “End-to-end autonomous driving: Challenges and frontiers,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[4]
Alvinn: An autonomous land vehicle in a neural network,
D. A. Pomerleau, “Alvinn: An autonomous land vehicle in a neural network,”Advances in neural information processing systems, vol. 1, 1988
1988
-
[5]
A. Khalil and J. Kwon, “Plm-net: Perception latency mitigation network for vision-based lateral control of autonomous vehicles,” arXiv:2407.16740, 2024
-
[6]
Deeppicarmicro: Applying tinyml to autonomous cyber physical systems,
M. Bechtel, Q. Weng, and H. Yun, “Deeppicarmicro: Applying tinyml to autonomous cyber physical systems,” inRTCSA. IEEE, 2022
2022
-
[7]
Speed/accuracy trade-offs for modern convolutional object detectors,
J. Huang, V . Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y . Song, S. Guadarramaet al., “Speed/accuracy trade-offs for modern convolutional object detectors,” inCVPR. IEEE, 2017
2017
-
[8]
D3: a dynamic deadline-driven approach for building autonomous vehicles,
I. Gog, S. Kalra, P. Schafhalter, J. E. Gonzalez, and I. Stoica, “D3: a dynamic deadline-driven approach for building autonomous vehicles,” inEuroSys. ACM, 2022
2022
-
[9]
Resolution switchable networks for runtime efficient image recognition,
Y . Wang, F. Sun, D. Li, and A. Yao, “Resolution switchable networks for runtime efficient image recognition,” inECCV. Springer, 2020
2020
-
[10]
Dy- namic resolution network,
M. Zhu, K. Han, E. Wu, Q. Zhang, Y . Nie, Z. Lan, and Y . Wang, “Dy- namic resolution network,”Advances in Neural Information Processing Systems, vol. 34, 2021
2021
-
[11]
Learning to drive from a world on rails,
D. Chen, V . Koltun, and P. Kr¨ahenb¨uhl, “Learning to drive from a world on rails,” inICCV. IEEE, 2021
2021
-
[12]
End-to-end training of deep visuomotor policies,
S. Levine, C. Finn, T. Darrell, and P. Abbeel, “End-to-end training of deep visuomotor policies,”Journal of Machine Learning Research, vol. 17, no. 39, 2016
2016
-
[13]
Deeppicar: A low- cost deep neural network-based autonomous car,
M. G. Bechtel, E. McEllhiney, M. Kim, and H. Yun, “Deeppicar: A low- cost deep neural network-based autonomous car,” inRTCSA. IEEE, 2018
2018
-
[14]
How fast is too fast? the role of perception latency in high-speed sense and avoid,
D. Falanga, S. Kim, and D. Scaramuzza, “How fast is too fast? the role of perception latency in high-speed sense and avoid,”IEEE Robotics and Automation Letters, vol. 4, no. 2, 2019
2019
-
[15]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016
2016
-
[16]
Pcla: A framework for testing autonomous agents in the carla simulator,
M. J. Tehrani, J. Kim, and P. Tonella, “Pcla: A framework for testing autonomous agents in the carla simulator,” inFSE, 2025
2025
-
[17]
Pylot: A modular platform for exploring latency-accuracy tradeoffs in autonomous vehicles,
I. Gog, S. Kalra, P. Schafhalter, M. A. Wright, J. E. Gonzalez, and I. Stoica, “Pylot: A modular platform for exploring latency-accuracy tradeoffs in autonomous vehicles,” inICRA. IEEE, 2021
2021
-
[18]
Anytime stereo image depth estimation on mobile devices,
Y . Wang, Z. Lai, G. Huang, B. H. Wang, L. Van Der Maaten, M. Camp- bell, and K. Q. Weinberger, “Anytime stereo image depth estimation on mobile devices,” inICRA. IEEE, 2019
2019
-
[19]
Adadet: An adaptive object detection system based on early-exit neural networks,
L. Yang, Z. Zheng, J. Wang, S. Song, G. Huang, and F. Li, “Adadet: An adaptive object detection system based on early-exit neural networks,” IEEE Transactions on Cognitive and Developmental Systems, vol. 16, no. 1, 2023
2023
-
[20]
D. Kuhse, H. Teper, S. Buschj ¨ager, C.-Y . Wang, and J.-J. Chen, “You only look once at anytime (anytimeyolo): Analysis and optimization of early-exits for object-detection,”arXiv:2503.17497, 2025
-
[21]
Mural: A multi-resolution anytime framework for lidar object detection deep neural networks,
A. Soyyigit, S. Yao, and H. Yun, “Mural: A multi-resolution anytime framework for lidar object detection deep neural networks,” inRTCSA. IEEE, 2025
2025
-
[22]
Anytime-lidar: Deadline-aware 3d object detection,
——, “Anytime-lidar: Deadline-aware 3d object detection,” inRTCSA. IEEE, 2022
2022
-
[23]
Valo: a versatile anytime framework for lidar-based object detection deep neural networks,
——, “Valo: a versatile anytime framework for lidar-based object detection deep neural networks,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 43, no. 11, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.