PROTOCOL: Late Interaction Retrieval for Protein Homolog Search
Pith reviewed 2026-06-29 13:15 UTC · model grok-4.3
The pith
Late interaction over per-residue embeddings improves remote protein homolog retrieval compared with pooled vectors or classical alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
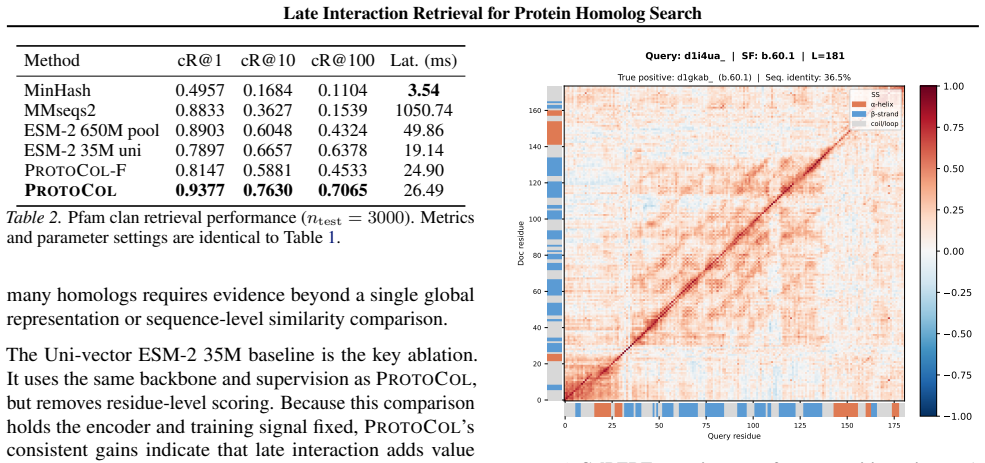
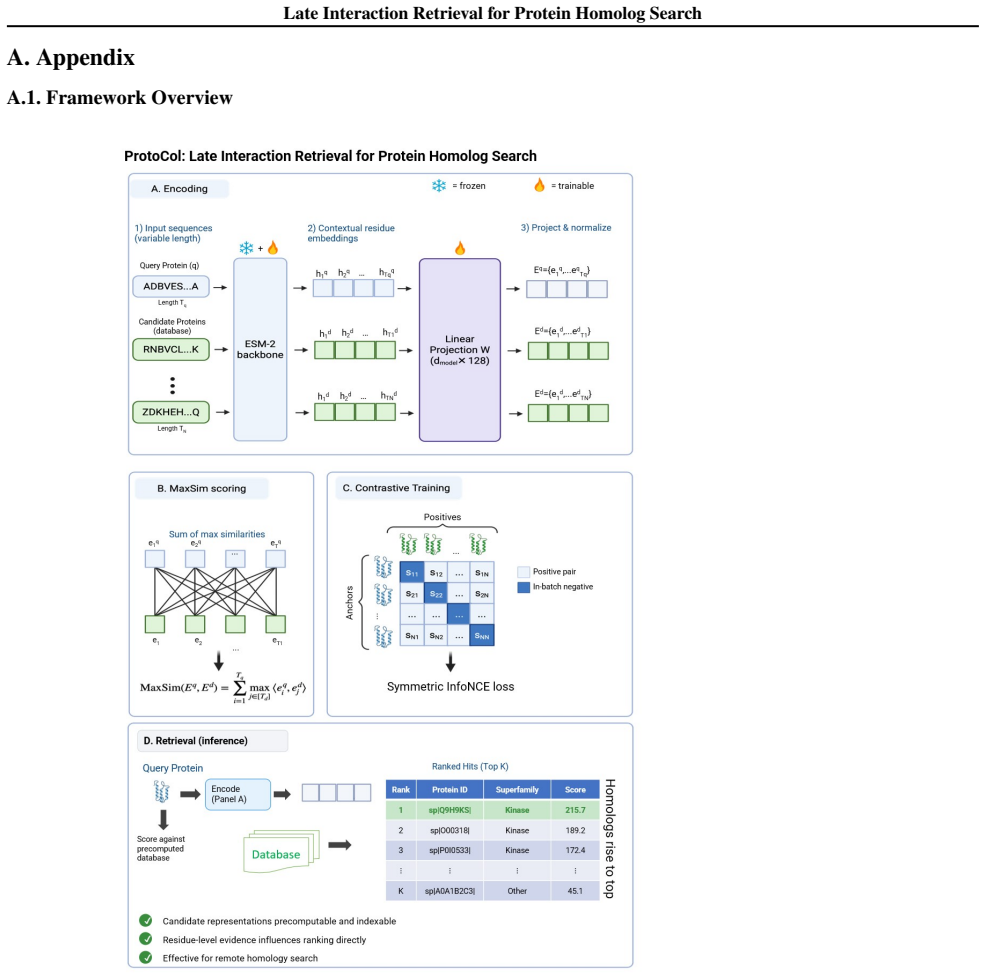
ProtoCol keeps proteins as unordered collections of residue embeddings from a protein language model. Candidates are encoded once and stored. Query-time scoring uses MaxSim, the sum of the maximum cosine similarity each query residue finds among a candidate's residues. On the SCOPe and Pfam remote-homology tasks this late-interaction layer produces higher retrieval accuracy than pooled-embedding or alignment baselines.
What carries the argument
MaxSim late interaction over independently encoded residue embeddings, which compares local patterns without first averaging them into a global vector.
If this is right
- Candidate representations can be pre-computed once and reused for many queries without re-encoding.
- The same residue-level storage supports retrieval at multiple levels of homology without retraining the underlying language model.
- Gains concentrate in the regime where global sequence identity drops below the sensitivity of alignment methods.
- The retrieval step adds no parameters beyond the frozen language-model encoder.
Where Pith is reading between the lines
- The same late-interaction pattern could be applied to other sequence families where local conservation matters more than global identity, such as regulatory DNA motifs.
- If residue sets remain informative, the method could serve as an initial filter before more expensive structure-alignment searches.
- Because encoding and storage are decoupled, the approach scales by adding more stored residue sets rather than retraining.
Load-bearing premise
That the highest pairwise similarity between any two residue embeddings will consistently flag conserved local motifs even when overall sequence similarity is weak.
What would settle it
If a simple average-pooling baseline that uses the identical residue embeddings achieves equal or higher accuracy than ProtoCol on the same SCOPe superfamily and Pfam clan test sets, the claimed benefit of late interaction would not hold.
Figures
read the original abstract
Protein homology search underlies function annotation, structure prediction, and evolutionary analysis, but remains challenging in the "twilight zone," where global sequence similarity is weak and classical alignment methods lose sensitivity. Protein language models provide context-aware representations that could improve alignment sensitivity in this regime. However, prior protein embedding-based retrieval pipelines often pool these representations into a single vector, potentially obscuring local motifs, domains, or conserved residues that reveal remote homology. We introduce ProtoCol, a model which represents proteins as sets of residue embeddings and uses ColBERT-style late interaction to test whether residue-level comparison improves homolog retrieval. ProtoCol encodes proteins independently, keeps candidate representations pre-computable, and scores candidates with MaxSim over residue embeddings. On SCOPe superfamily and Pfam clan benchmarks, ProtoCol outperforms sequence-composition, alignment-based, pooled PLM, and trained single-vector baselines, supporting late interaction as an effective retrieval layer for remote homology search.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ProtoCol, a late-interaction retrieval model for protein homolog search. Proteins are encoded independently as sets of residue embeddings from protein language models; candidates are scored via ColBERT-style MaxSim over these embeddings. The central claim is that this outperforms sequence-composition, alignment-based, pooled-PLM, and trained single-vector baselines on SCOPe superfamily and Pfam clan benchmarks for remote homology detection in the twilight zone.
Significance. If the empirical superiority holds with proper controls and statistical validation, the work would establish late interaction as a practical retrieval layer that preserves local motif information better than global pooling while remaining pre-computable. This could meaningfully improve sensitivity for remote homolog detection, with downstream value for function annotation and evolutionary analysis.
major comments (1)
- [Abstract] Abstract (and entire manuscript): the claim that 'ProtoCol outperforms sequence-composition, alignment-based, pooled PLM, and trained single-vector baselines' on SCOPe superfamily and Pfam clan benchmarks is asserted without any numbers, tables, figures, error bars, statistical tests, data-split descriptions, candidate-set construction details, PLM choice, fine-tuning status, or MaxSim implementation. This omission is load-bearing for the central empirical claim and prevents any assessment of whether late interaction, rather than baseline implementation or data artifacts, drives the reported gains.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comment correctly identifies that the abstract and manuscript require substantially more quantitative and methodological detail to support the central empirical claims. We will revise the manuscript to address this.
read point-by-point responses
-
Referee: [Abstract] Abstract (and entire manuscript): the claim that 'ProtoCol outperforms sequence-composition, alignment-based, pooled PLM, and trained single-vector baselines' on SCOPe superfamily and Pfam clan benchmarks is asserted without any numbers, tables, figures, error bars, statistical tests, data-split descriptions, candidate-set construction details, PLM choice, fine-tuning status, or MaxSim implementation. This omission is load-bearing for the central empirical claim and prevents any assessment of whether late interaction, rather than baseline implementation or data artifacts, drives the reported gains.
Authors: We agree that the abstract as written provides only a qualitative summary and that the manuscript must make the supporting evidence fully transparent. The revised version will expand the abstract to report key performance numbers (with error bars and statistical tests where appropriate) for the SCOPe and Pfam benchmarks. We will also add or expand a methods subsection that explicitly describes: (i) the data splits and candidate-set construction, (ii) the specific PLM used and its fine-tuning status, and (iii) the precise MaxSim implementation. These additions will allow readers to evaluate whether the observed gains are attributable to late interaction rather than implementation details. revision: yes
Circularity Check
No circularity; empirical claims rest on external benchmarks
full rationale
The manuscript presents ProtoCol as an application of ColBERT-style late interaction to residue embeddings from protein language models, then reports direct empirical outperformance on SCOPe superfamily and Pfam clan benchmarks against sequence-composition, alignment-based, pooled PLM, and single-vector baselines. No equations, parameter-fitting steps, uniqueness theorems, or self-citations appear in the provided text that would reduce any claimed result to a redefinition or re-use of the paper's own inputs. The central claim is therefore an independent empirical comparison rather than a constructed prediction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Residue embeddings from protein language models preserve local motif information useful for remote homology detection
Reference graph
Works this paper leans on
-
[1]
URL https://aclanthology.org/2023. findings-emnlp.110/. Dhulipala, L., Hadian, M., Jayaram, R., Lee, J., and Mir- rokni, V . Muvera: Multi-vector retrieval via fixed di- mensional encoding.Advances in Neural Information Processing Systems, 37:101042–101073, 2024. Eddy, S. R. Accelerated profile HMM searches.PLOS Computational Biology, 7(10):e1002195, 2011...
-
[2]
ISSN 0305-1048. doi: 10.1093/nar/gkaa913. URL https://doi.org/10.1093/nar/gkaa913. Reimers, N. and Gurevych, I. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. InProceed- ings of the 2019 Conference on Empirical Methods in Natural Language Processing, pp. 3982–3992, 2019. Santhanam, K., Khattab, O., Potts, C., and Zaharia, M. Plaid: an eff...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.