UA-Legal-Bench: A Benchmark for Evaluating Large Language Models on Ukrainian Legal Reasoning
Pith reviewed 2026-06-29 12:12 UTC · model grok-4.3
The pith
UA-Legal-Bench reveals sharply task-dependent few-shot effects and that accuracy misleads on imbalanced Ukrainian legal tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
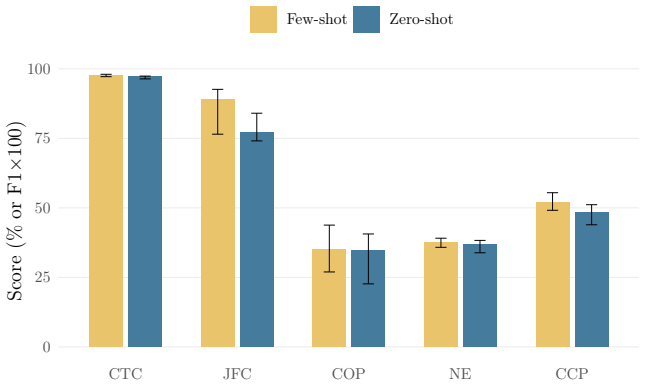
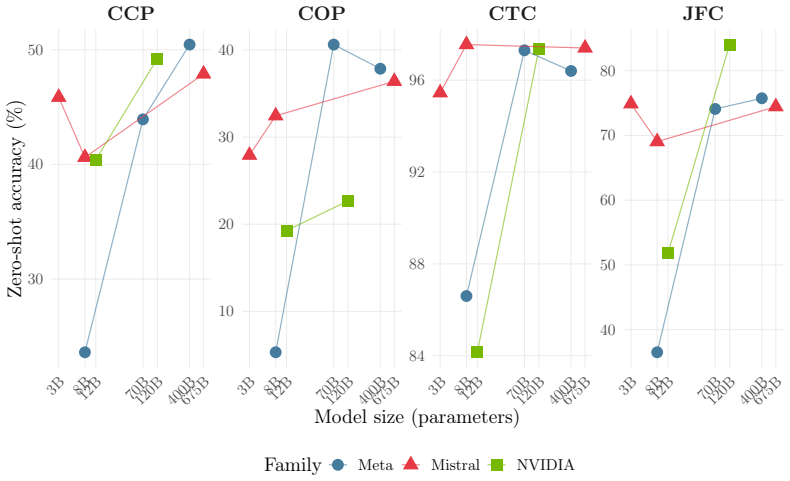
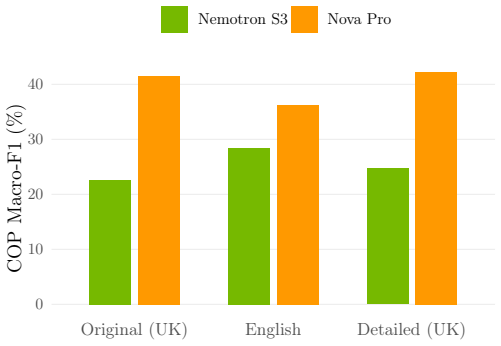
UA-Legal-Bench is a five-task benchmark for evaluating LLMs on Ukrainian legal reasoning built from the EDRSR corpus. The benchmark tasks are case-type classification, judgment form classification, case-outcome prediction, legal norm extraction, and cause category prediction. Evaluations reveal sharply task-dependent few-shot effects and demonstrate that accuracy is misleading on imbalanced legal tasks.
What carries the argument
The UA-Legal-Bench benchmark consisting of five tasks evaluated under zero-shot and 3-shot prompting on samples from the Unified State Register of Court Decisions.
If this is right
- Few-shot prompting must be selected per task rather than applied uniformly in legal applications.
- Macro-F1 should replace accuracy as the primary metric for imbalanced legal classification problems.
- Within-family scaling shows 8B models can match larger models on surface-level tasks but the benefit threshold varies by model family.
- The benchmark enables direct comparison of LLMs on non-English legal reasoning without relying on English-centric proxies.
Where Pith is reading between the lines
- Benchmarks of this kind could reveal similar hidden weaknesses in legal AI systems for other non-Latin script languages.
- Legal technology developers should adopt balanced metrics when training or deploying models that affect court outcomes.
- Public release of the data and predictions supports extensions to additional tasks or direct comparisons with future models.
Load-bearing premise
The five tasks and data samples from the EDRSR corpus are representative of real-world Ukrainian legal reasoning challenges.
What would settle it
A follow-up evaluation on held-out Ukrainian court data in which every model shows consistent few-shot gains across all tasks and the highest-accuracy model also achieves the highest macro-F1 would falsify the central findings.
Figures
read the original abstract
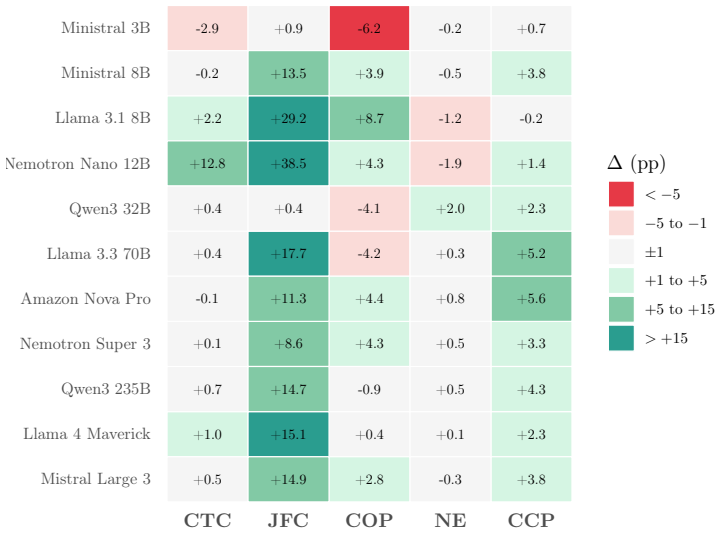
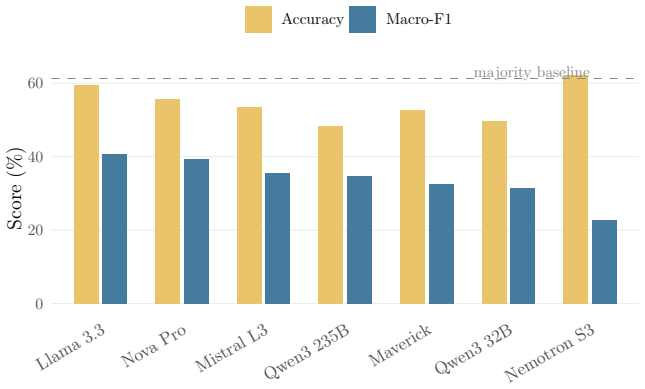
Legal NLP benchmarks are overwhelmingly English-centric, leaving failure modes in morphologically rich, non-Latin-script languages undetected. We introduce UA-Legal-Bench, a five-task benchmark for evaluating large language models on Ukrainian legal reasoning, built from the Unified State Register of Court Decisions (EDRSR) -- one of the world's largest open judicial corpora (99.5 million decisions). The benchmark comprises: (1) case-type classification (4 classes, n=2,000), (2) judgment form classification (4 classes, n=2,000), (3) case-outcome prediction (6 classes, n=800), (4) legal norm extraction (n=1,794), and (5) cause category prediction (22 classes, n=1,871). We evaluate 11 LLMs (3B--675B) from five families under zero-shot and 3-shot prompting via AWS Bedrock with 158K API calls. Our results reveal sharply task-dependent few-shot effects: few-shot prompting improves judgment form classification by up to +38.6 pp but has mixed effects on outcome prediction. We show that accuracy is misleading on imbalanced legal tasks: the model with highest COP accuracy (62%) is a majority-class predictor (macro-F1: 23%), while the genuinely best model scores only 44% macro-F1. Within-family scaling analysis reveals that 8B models can match frontier performance on surface-level tasks but scaling thresholds vary dramatically across families. We release all data, prompts, and model predictions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UA-Legal-Bench, a five-task benchmark (case-type classification, judgment form classification, case-outcome prediction, legal norm extraction, cause category prediction) constructed from the EDRSR corpus of Ukrainian court decisions. It evaluates 11 LLMs (3B–675B parameters) from five families under zero-shot and 3-shot prompting via AWS Bedrock, reporting task-dependent few-shot effects (e.g., up to +38.6 pp gain on judgment form classification), the misleading nature of accuracy on imbalanced tasks (e.g., 62% accuracy model with 23% macro-F1), within-family scaling patterns, and releases all data, prompts, and predictions.
Significance. This benchmark addresses the English-centric limitation in legal NLP by targeting Ukrainian, a morphologically rich non-Latin language, using one of the largest open judicial corpora. The direct empirical results on task-dependent prompting effects and accuracy-vs-macro-F1 discrepancies are supported by the explicit task definitions, sample sizes, and released artifacts, enabling reproduction. The scaling analysis across families provides additional insight into model size thresholds. Full data release strengthens the contribution for future work on non-English legal reasoning.
major comments (2)
- [§3] §3 (Benchmark Construction): The description of how the five tasks and their samples (n=800–2000) were drawn from the 99.5M-decision EDRSR corpus provides insufficient detail on sampling criteria, stratification for class balance, or filtering steps. This is load-bearing for interpreting the reported task-dependent effects and the claim that accuracy is misleading on imbalanced tasks, as selection biases could influence the observed class distributions and model behaviors.
- [§4] §4 (Evaluation Setup): The paper reports results for exactly 3-shot prompting but does not include any ablation or sensitivity analysis on shot count or example selection strategy. This weakens the strength of the claim that few-shot effects are 'sharply task-dependent,' as the +38.6 pp gain on judgment form classification could partly reflect the specific prompting choices rather than a general property of the tasks.
minor comments (3)
- [Table 1, §4.2] Table 1 and §4.2: The class counts and imbalance ratios for the 22-class cause category prediction task are not explicitly tabulated alongside the macro-F1 results, making it harder to directly verify the accuracy-vs-F1 discrepancy for that task.
- [§5] §5 (Scaling Analysis): The within-family scaling plots would benefit from explicit labeling of the 8B model points that 'match frontier performance' on surface-level tasks to allow readers to identify the exact thresholds mentioned.
- [Abstract, §1] Abstract and §1: The total number of API calls (158K) is stated but the per-task or per-model breakdown is not provided, which would help assess the scale of the evaluation.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation of minor revision. The comments highlight opportunities to strengthen reproducibility and the interpretation of our results. We address each major comment below.
read point-by-point responses
-
Referee: §3 (Benchmark Construction): The description of how the five tasks and their samples (n=800–2000) were drawn from the 99.5M-decision EDRSR corpus provides insufficient detail on sampling criteria, stratification for class balance, or filtering steps. This is load-bearing for interpreting the reported task-dependent effects and the claim that accuracy is misleading on imbalanced tasks, as selection biases could influence the observed class distributions and model behaviors.
Authors: We agree that expanded detail on sampling is warranted to support interpretation of class imbalance and task effects. In the revised manuscript we will expand §3 to specify: (i) the filtering criteria applied to EDRSR (complete Ukrainian-language decisions with full metadata), (ii) the stratified random sampling procedure that preserved natural class distributions while guaranteeing minimum per-class representation, and (iii) the fixed random seed used for reproducibility. These additions will be placed in the main text rather than only supplementary material. revision: yes
-
Referee: §4 (Evaluation Setup): The paper reports results for exactly 3-shot prompting but does not include any ablation or sensitivity analysis on shot count or example selection strategy. This weakens the strength of the claim that few-shot effects are 'sharply task-dependent,' as the +38.6 pp gain on judgment form classification could partly reflect the specific prompting choices rather than a general property of the tasks.
Authors: We acknowledge that a full ablation on shot count and example selection would further strengthen the generality claim. However, the 158K API calls already performed make additional experiments resource-intensive. The 3-shot regime follows common practice in legal NLP benchmarks, with examples drawn uniformly at random from a held-out training split. Task dependence is shown by the consistent contrast between zero-shot and this fixed 3-shot protocol across all five tasks. In revision we will add a clarifying paragraph in §4 stating the rationale for 3 shots and explicitly noting the absence of sensitivity analysis as a limitation for future work; no new experiments will be run. revision: partial
Circularity Check
No significant circularity
full rationale
The paper constructs a new benchmark from the external EDRSR corpus and reports direct empirical results from LLM evaluations under explicitly defined zero-shot and 3-shot protocols. No equations, fitted parameters, or derived quantities are present; all reported metrics (accuracy, macro-F1, few-shot deltas) are computed directly from the released predictions on the stated task samples. No self-citations are invoked as load-bearing premises, and the work contains no derivations that could reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, volume 33, pages 1877–1901,
1901
-
[2]
Language Models are Few-Shot Learners
URLhttps://arxiv.org/abs/2005.14165. 11 Ilias Chalkidis, Manos Fergadiotis, Prodromos Malakasiotis, Nikolaos Aletras, and Ion An- droutsopoulos. Legal-BERT: The muppets straight out of law school. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 2898–2904,
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[3]
doi: 10.18653/v1/2020.findings-emnlp.261. Ilias Chalkidis, Abhik Jana, Dirk Hartung, Michael Bommarito, Ion Androutsopoulos, Daniel Mar- tin Katz, and Nikolaos Aletras. Lexglue: A benchmark dataset for legal language understanding in english. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics, pages 4310–4330,
-
[4]
doi: 10.18653/v1/2022.acl-long.297. Timnit Gebru, Jamie Morgenstern, Brenda Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. Datasheets for datasets.Communications of the ACM, 64(12):86–92,
-
[5]
doi: 10.1145/3458723. Margherita Grandini, Enrico Bagli, and Giorgio Visani. Metrics for multi-class classification: An overview.arXiv preprint arXiv:2008.05756,
-
[6]
URLhttps://arxiv.org/abs/2008.05756. Neel Guha, Julian Nyarko, Daniel E Ho, Christopher Ré, Adam Chilton, Aditya Narang, Alex Choi, Claudia Gruber, et al. Legalbench: A collaboratively built benchmark for measuring legal reasoning in large language models. InAdvances in Neural Information Processing Systems, volume 36,
-
[7]
Dan Hendrycks, Collin Burns, Anya Chen, and Spencer Ball
URLhttps://arxiv.org/abs/2308.11462. Dan Hendrycks, Collin Burns, Anya Chen, and Spencer Ball. Cuad: An expert-annotated NLP dataset for legal contract review. InProceedings of the 35th Conference on Neural Information Processing Systems, Datasets and Benchmarks Track,
-
[8]
Daniel Martin Katz, Michael James Bommarito, Shang Gao, and Pablo Arredondo
URLhttps://arxiv.org/abs/ 2103.06268. Daniel Martin Katz, Michael James Bommarito, Shang Gao, and Pablo Arredondo. GPT-4 passes the bar exam.Philosophical Transactions of the Royal Society A, 382(2270),
-
[9]
Joel Niklaus, Veton Matoshi, Pooja Rani, Andrea Galassi, Matthias Stürmer, and Ilias Chalkidis
doi: 10.1098/rsta.2023.0254. Joel Niklaus, Veton Matoshi, Pooja Rani, Andrea Galassi, Matthias Stürmer, and Ilias Chalkidis. Lextreme: A multi-lingual and multi-task benchmark for the legal domain. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 4973–5006,
-
[10]
Joel Niklaus, Veton Matoshi, Matthias Stürmer, Ilias Chalkidis, and Mark Stevenson
doi: 10.18653/v1/2023.findings-emnlp.200. Joel Niklaus, Veton Matoshi, Matthias Stürmer, Ilias Chalkidis, and Mark Stevenson. MultiLe- galPile: A 689gb multilingual legal corpus. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics,
-
[11]
doi: 10.18653/v1/2024.acl-long.805. Volodymyr Ovcharov. The tokenizer tax across 25 European languages: Domain invariance, cross-lingual few-shot effects, and the Ukrainian penalty.arXiv preprint arXiv:2605.24718, 2026a. URLhttps://arxiv.org/abs/2605.24718. Volodymyr Ovcharov. Tokenizer fertility and zero-shot performance of foundation models on Ukrainian...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.acl-long.805 2024
-
[12]
Phillip Rust, Jonas Pfeiffer, Ivan Vulić, Sebastian Ruder, and Iryna Gurevych
URLhttps://arxiv.org/abs/2306.09237. Phillip Rust, Jonas Pfeiffer, Ivan Vulić, Sebastian Ruder, and Iryna Gurevych. How good is your tokenizer? on the monolingual performance of multilingual language models. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics, pages 3118–3135,
-
[13]
12 Oleksiy Syvokon and Mariana Romanyshyn
doi: 10.18653/v1/2021.acl-long.243. 12 Oleksiy Syvokon and Mariana Romanyshyn. The UNLP 2023 shared task on grammatical error correction for Ukrainian. InProceedings of the Second Ukrainian Natural Language Processing Workshop (UNLP) at EACL 2023, pages 1–16,
-
[14]
ZihaoZhao, EricWallace, ShiFeng, DanKlein, andSameerSingh
doi: 10.18653/v1/2023.unlp-1.16. ZihaoZhao, EricWallace, ShiFeng, DanKlein, andSameerSingh. Calibratebeforeuse: Improving few-shot performance of language models. InProceedings of the 38th International Conference on Machine Learning, pages 12697–12706,
-
[15]
Lucia Zheng, Neel Guha, Brandon R Anderson, Peter Henderson, and Daniel E Ho
URLhttps://arxiv.org/abs/2102.09690. Lucia Zheng, Neel Guha, Brandon R Anderson, Peter Henderson, and Daniel E Ho. When does pretraining help? assessing self-supervised learning for law and the CaseHOLD dataset of 53,000+ legal holdings. InProceedings of the 18th International Conference on Artificial Intelligence and Law, pages 159–168,
-
[16]
doi: 10.1145/3462757.3466088. 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.