Influence-Guided Symbolic Regression: Scientific Discovery via LLM-Driven Equation Search with Granular Feedback
Pith reviewed 2026-06-29 13:00 UTC · model grok-4.3
The pith
Influence scores let LLMs prune equation terms and surface a DNA methylation link later confirmed in lab experiments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
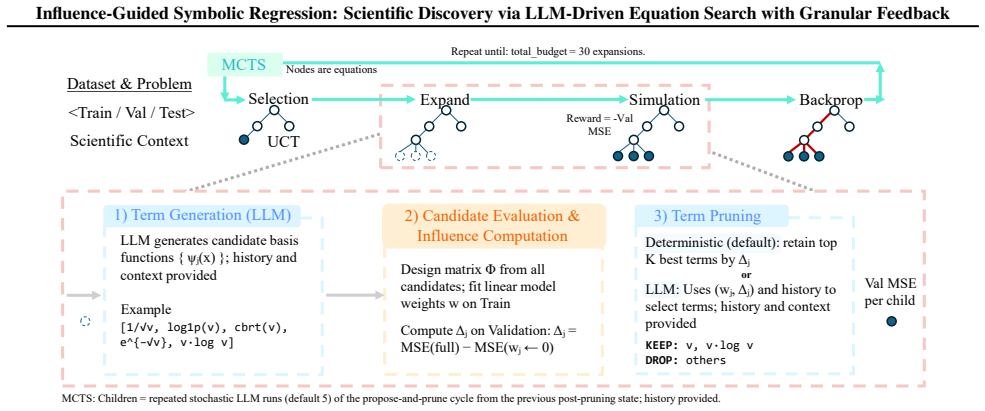
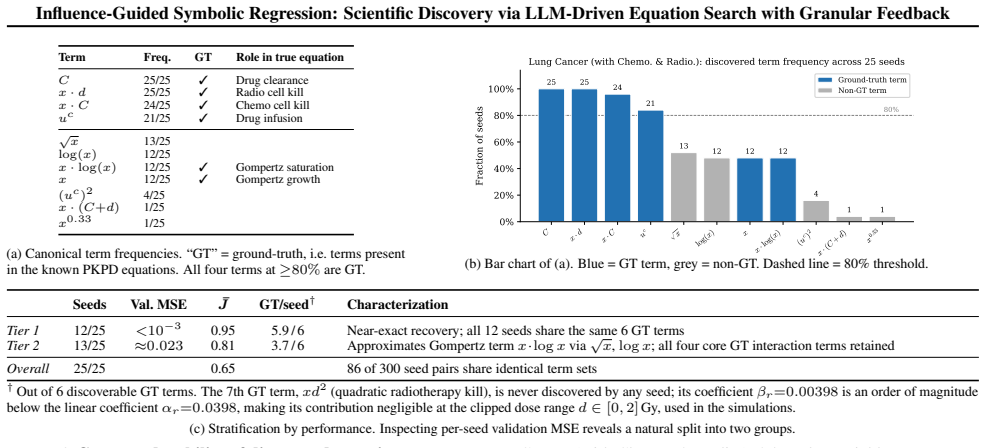
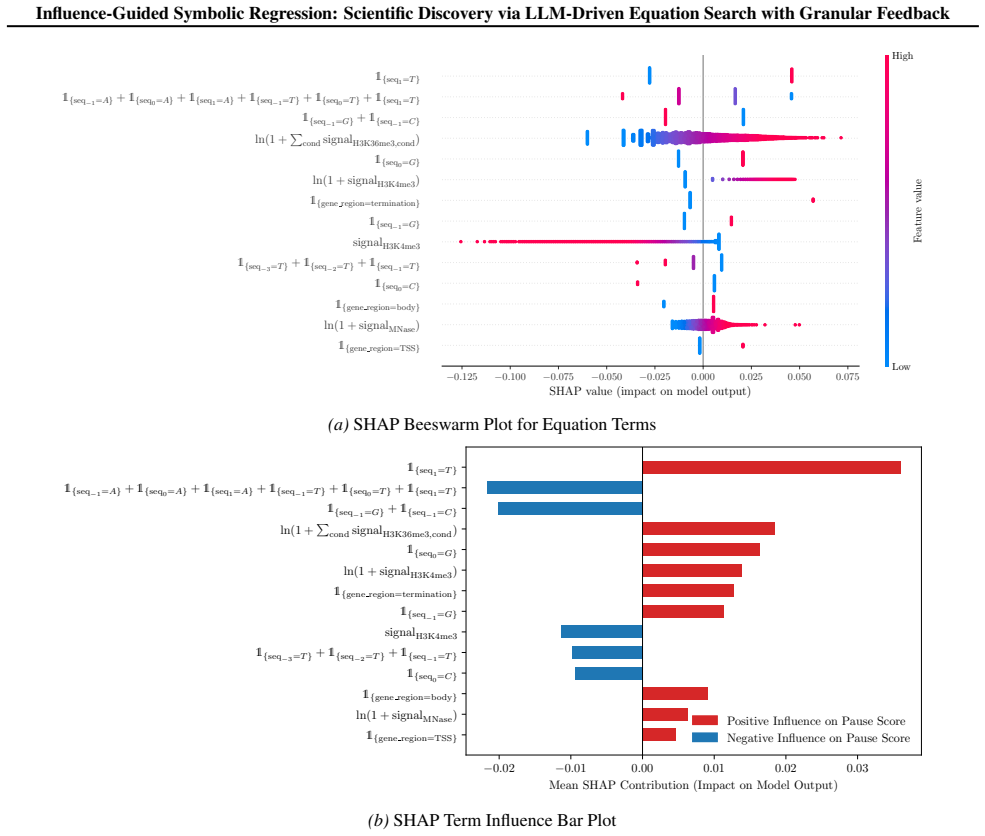
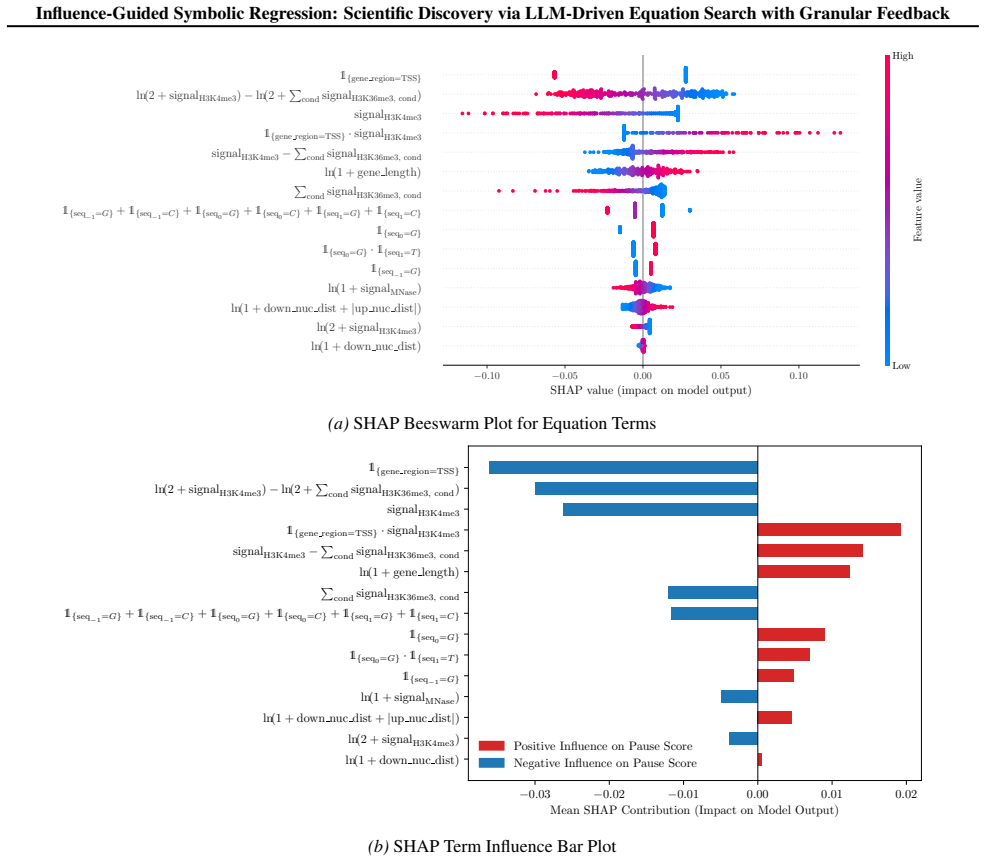
IGSR frames equation discovery as an iterative loop in which an LLM generates candidate basis functions, each is scored by its marginal effect on out-of-sample accuracy, and the scores are used to prune the active set; the pruned set is then explored inside a Monte Carlo tree search. When applied to real genomic measurements this loop identified a previously unreported connection between DNA methylation levels and RNA Polymerase II pausing whose validity was later corroborated by independent laboratory experiments.
What carries the argument
Granular influence scores Δ_j that quantify each candidate basis function's marginal contribution to generalization accuracy and thereby guide term pruning inside an MCTS search.
If this is right
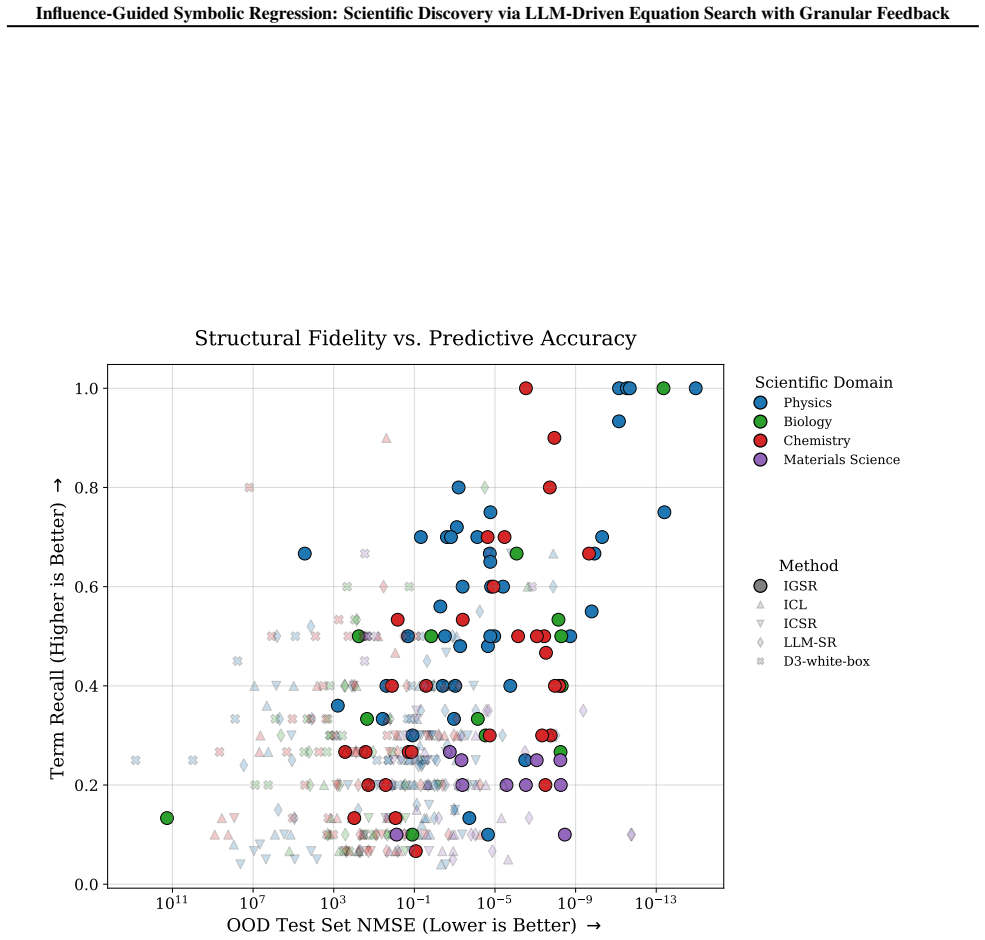
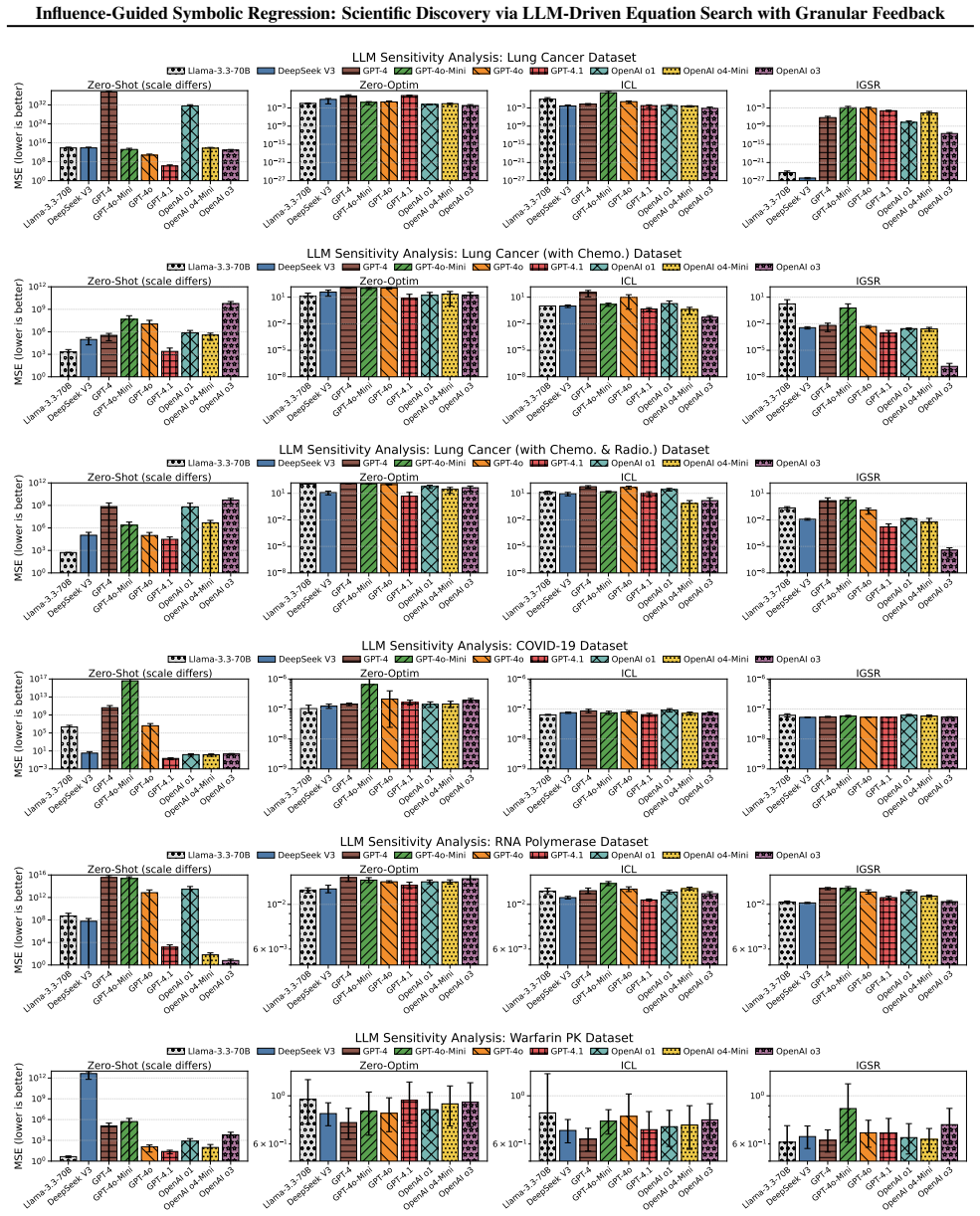
- The method recovers known functional relationships in pharmacological PKPD models and epidemiological simulations.
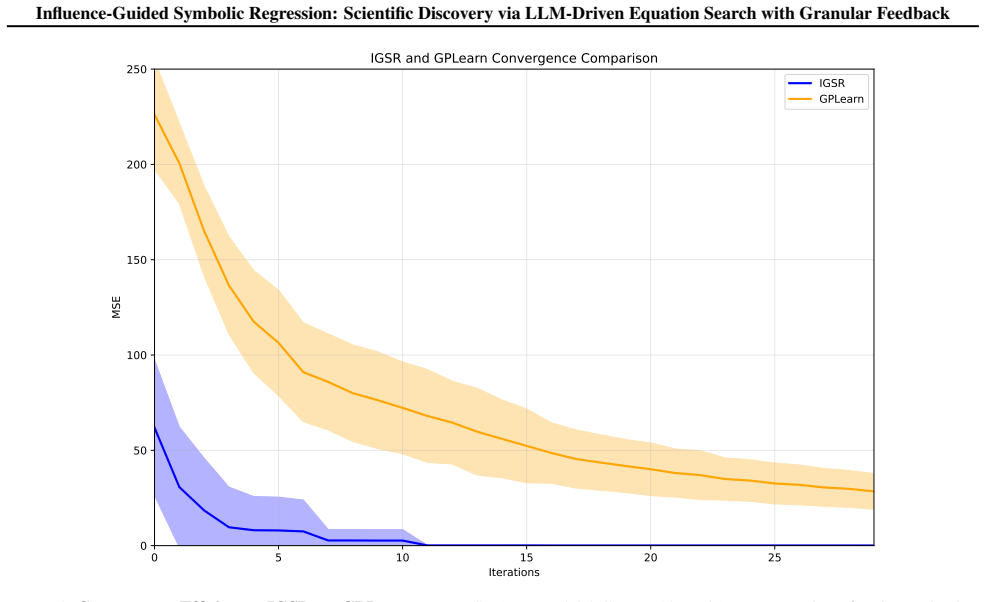
- On LLM-SRBench and similar suites it produces accurate equations while using fewer terms than scalar-feedback baselines.
- Application to high-dimensional biological data yields hypotheses that can be tested directly in the laboratory.
- The combination of influence pruning and MCTS maintains a balance between exploring novel functional forms and exploiting high-performing components.
Where Pith is reading between the lines
- The same granular scoring approach could be applied to other high-dimensional scientific datasets to generate testable hypotheses without requiring exhaustive manual feature engineering.
- If influence scores prove stable across modest data perturbations, the pruning step could be reused inside non-linear or kernel-based regression frameworks.
- Extending the linear-model assumption to allow direct generation of nonlinear terms would enlarge the space of equations the method can discover.
Load-bearing premise
The influence scores computed from marginal contribution to generalization accuracy are stable enough to prune candidate terms without discarding important ones or retaining noise.
What would settle it
Re-running the genomic case study on independent data splits or with different random seeds and obtaining proposed relationships that fail to replicate in subsequent wet-lab tests would show the discovery claim does not hold.
Figures



read the original abstract
Large Language Models (LLMs) offer a promising avenue for scientific discovery, yet their application to symbolic regression is often constrained by inefficient search strategies and coarse feedback signals. Current methods typically guide LLMs using scalar metrics (e.g., global Mean Squared Error), which fail to identify which components of a proposed equation are driving performance or causing error. We introduce \textit{Influence-Guided Symbolic Regression} (IGSR), a method that frames equation discovery as an iterative two-step process combining diverse term generation with rigorous selection: an LLM generates candidate basis functions $\psi_j(\mathbf{x})$ for a linear model, which are then evaluated using granular influence scores $\Delta_j$. These scores quantify each term's marginal contribution to generalization accuracy, enabling an influence-guided pruning process that systematically refines the model structure. Integrating this mechanism into a Monte Carlo Tree Search (MCTS) enables navigating the combinatorial search space while balancing exploration of novel functional forms with exploitation of high-influence components. We demonstrate IGSR's effectiveness on a diverse suite of benchmarks, including LLM-SRBench, pharmacological PKPD models, an epidemiological simulation, and real-world genomic data. Notably, we validate the framework's capacity for genuine discovery in a case study using a high-dimensional biological dataset, in which IGSR identified a novel relationship between DNA methylation and RNA Polymerase II pausing; a hypothesis that was subsequently supported via wet-lab experimentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Influence-Guided Symbolic Regression (IGSR), which frames symbolic regression as an iterative LLM-driven process: LLMs generate candidate basis functions ψ_j(x) for a linear model, these are scored by influence scores Δ_j measuring each term's marginal contribution to generalization accuracy, the scores drive pruning of the basis, and the process is embedded in Monte Carlo Tree Search (MCTS) to balance exploration and exploitation. The method is evaluated on LLM-SRBench, PKPD models, an epidemiological simulation, and a high-dimensional genomic dataset; the central discovery claim is that IGSR identified a novel relationship between DNA methylation and RNA Polymerase II pausing that was subsequently corroborated by wet-lab experimentation.
Significance. If the influence scores are shown to be stable and the pruning mechanism demonstrably isolates true signal in noisy genomic data, the work would strengthen the case for granular, component-level feedback in LLM-based scientific discovery pipelines. The wet-lab validation of the genomic finding is a concrete strength that goes beyond synthetic benchmarks and directly addresses the goal of genuine discovery.
major comments (2)
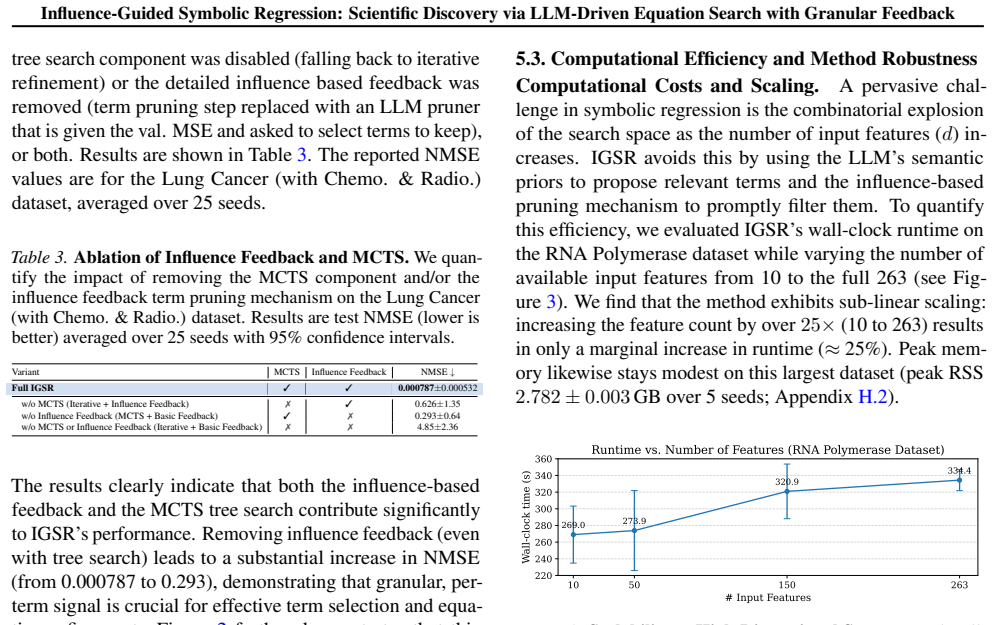
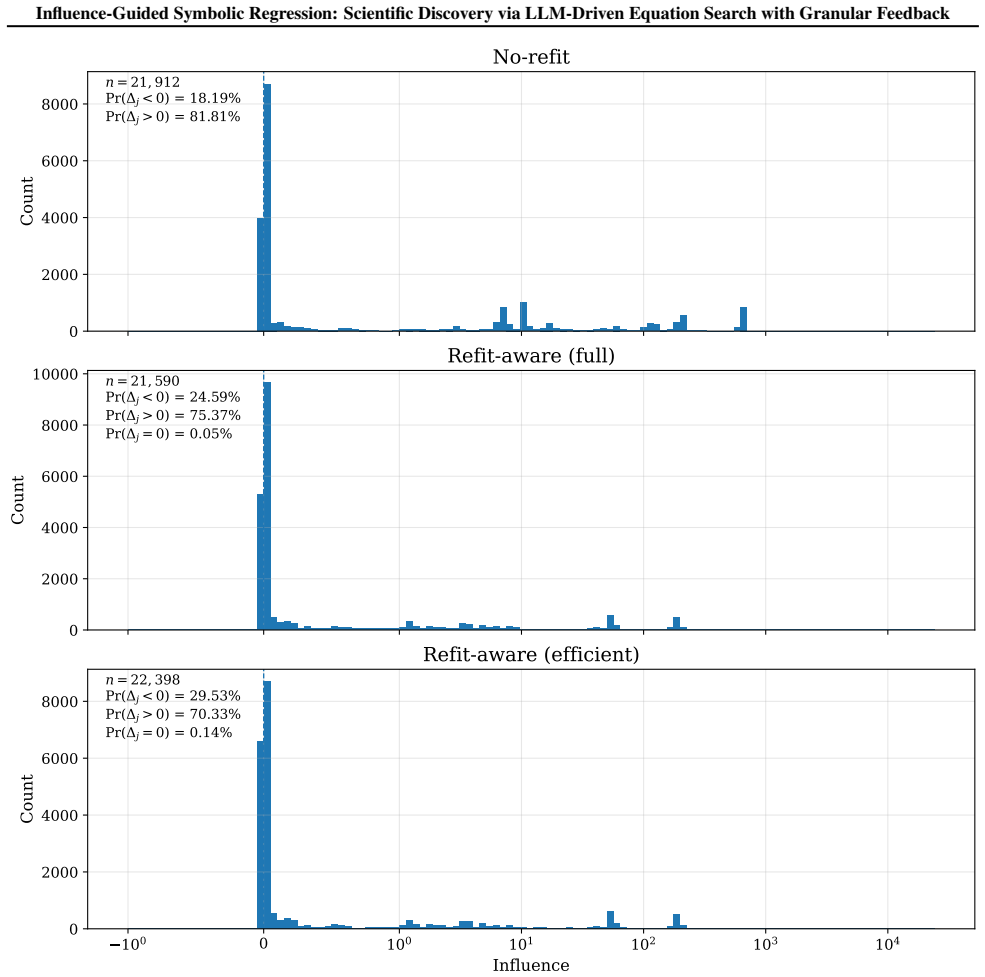
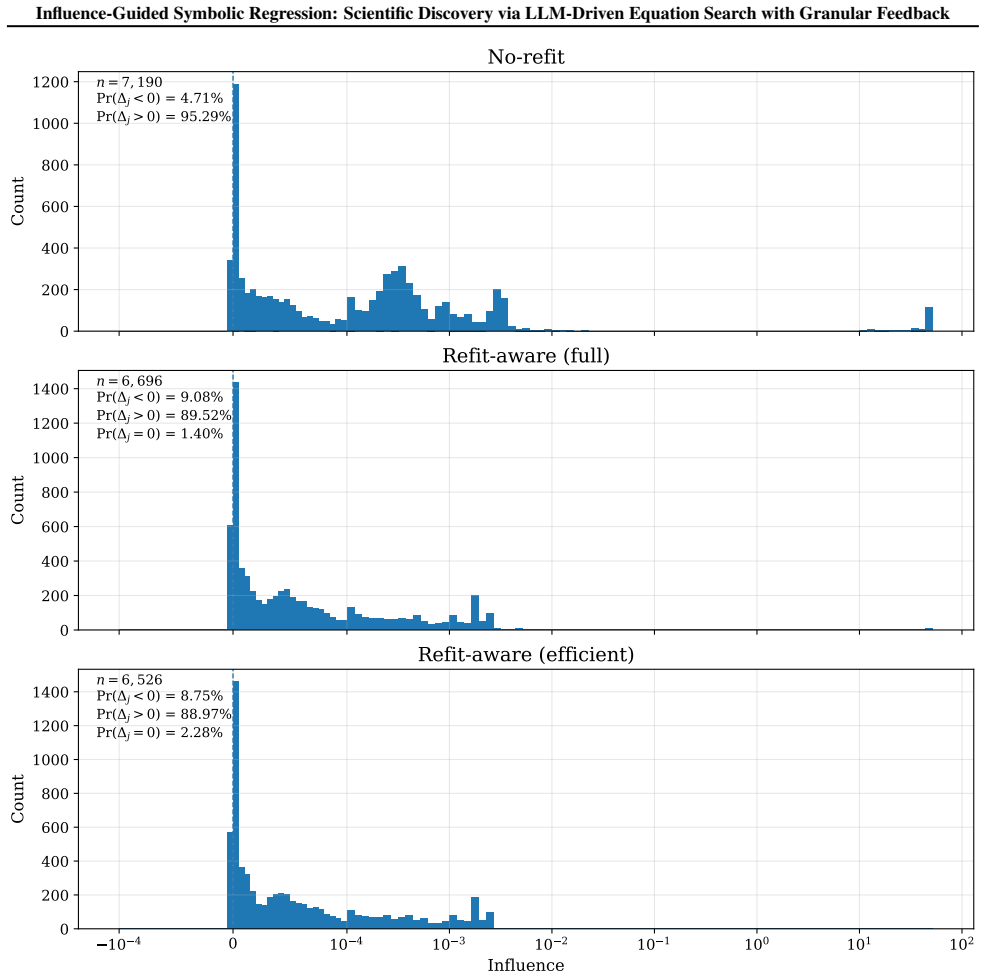
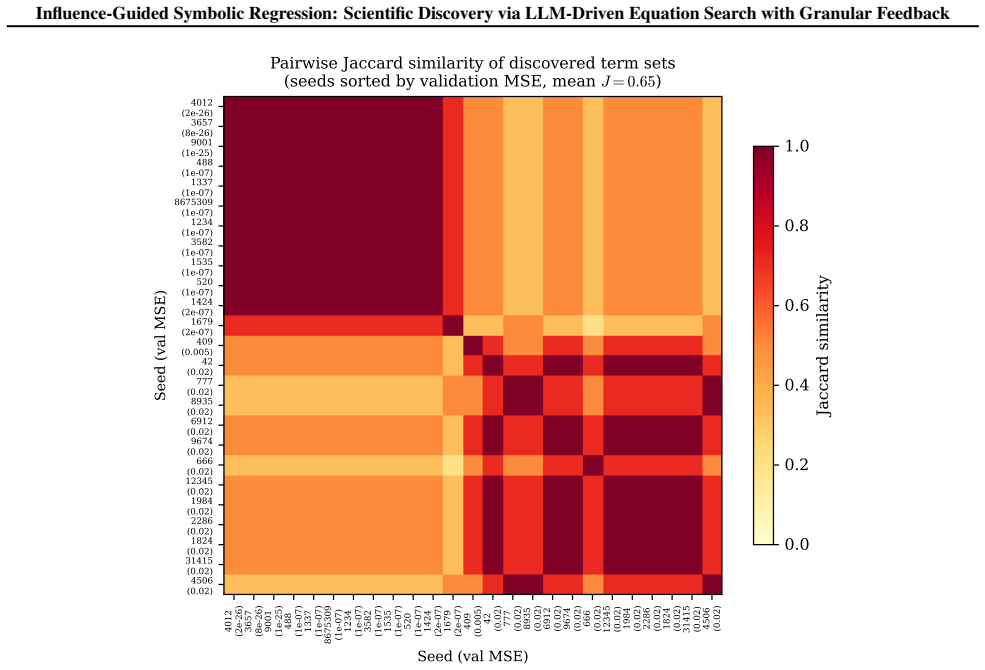
- [§4.3] §4.3 (genomic case study) and the description of Δ_j: the discovery claim rests on influence-guided pruning reliably retaining the DNA-methylation term while discarding spurious basis functions, yet no analysis of Δ_j variance under data perturbations, cross-validation folds, or feature correlations (typical of methylation data) is provided; without this, it is impossible to rule out that the retained relationship is an artifact of unstable rankings rather than method-driven signal.
- [Method] Method section (definition and use of Δ_j): the marginal-contribution definition of Δ_j is presented as enabling systematic refinement, but no quantitative check (e.g., rank stability across bootstrap samples or ablation of the pruning step) is reported to confirm that the scores are sufficiently accurate to drive reliable MCTS search in high-dimensional regimes.
minor comments (2)
- [Abstract] Abstract and §3: pseudocode or explicit formula for computing Δ_j from the linear model is absent, making it difficult for readers to reproduce the influence-guided pruning step.
- [Results] Figure captions and tables: several benchmark tables lack error bars or statistical significance tests comparing IGSR against the scalar-MSE baselines, weakening the quantitative claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments regarding the stability and validation of the influence scores Δ_j. These points are well-taken and we outline targeted revisions below to address them directly.
read point-by-point responses
-
Referee: [§4.3] §4.3 (genomic case study) and the description of Δ_j: the discovery claim rests on influence-guided pruning reliably retaining the DNA-methylation term while discarding spurious basis functions, yet no analysis of Δ_j variance under data perturbations, cross-validation folds, or feature correlations (typical of methylation data) is provided; without this, it is impossible to rule out that the retained relationship is an artifact of unstable rankings rather than method-driven signal.
Authors: We agree that explicit stability analysis of Δ_j would strengthen the genomic results. In the revised manuscript we will add quantitative experiments reporting the variance of Δ_j under data perturbations, across cross-validation folds, and accounting for feature correlations typical of methylation data. These results will be presented alongside the existing wet-lab validation to demonstrate that the retained DNA-methylation term reflects stable signal. revision: yes
-
Referee: [Method] Method section (definition and use of Δ_j): the marginal-contribution definition of Δ_j is presented as enabling systematic refinement, but no quantitative check (e.g., rank stability across bootstrap samples or ablation of the pruning step) is reported to confirm that the scores are sufficiently accurate to drive reliable MCTS search in high-dimensional regimes.
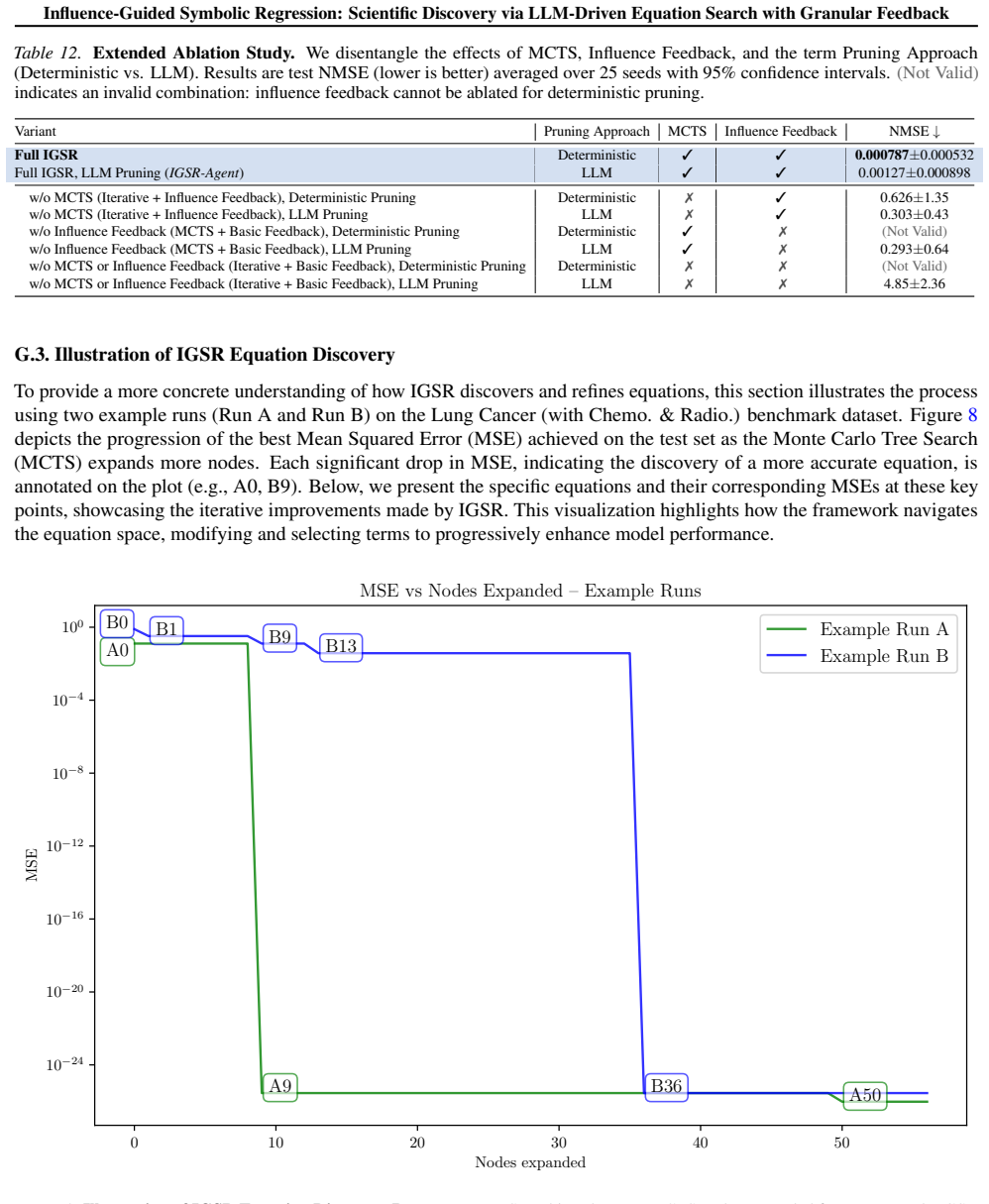
Authors: We concur that additional quantitative checks on Δ_j reliability are warranted for high-dimensional settings. The revision will include (i) rank-stability metrics computed across bootstrap samples and (ii) an ablation comparing MCTS performance with and without the influence-guided pruning step. These additions will confirm that the marginal scores support reliable search. revision: yes
Circularity Check
No significant circularity; central discovery claim rests on external wet-lab validation
full rationale
The paper defines influence scores Δ_j from marginal contribution to generalization accuracy and uses them to prune basis functions inside an MCTS loop. However, the load-bearing scientific claim—a novel DNA-methylation / RNA-Pol-II relationship—is presented as having been subsequently confirmed by independent wet-lab experimentation rather than being a quantity defined by the fitted model or by self-citation. No derivation step reduces the reported discovery or performance gain to a quantity that is identical to the method's own inputs by construction. The evaluation protocol is described as external generalization accuracy on held-out data and real biological follow-up, satisfying the criteria for a self-contained, non-circular result.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large language models can generate candidate basis functions ψ_j(x) that are relevant to the target phenomenon
- domain assumption Marginal influence scores Δ_j can be computed that faithfully reflect each term's contribution to generalization accuracy
invented entities (1)
-
Influence score Δ_j
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A scalable tree boosting system
ACM, 2016. doi: 10.1145/2939672.2939785. URL https://doi.org/10.1145/2939672.2939785. Chen, T. Q., Rubanova, Y ., Bettencourt, J., and Duve- naud, D. Neural ordinary differential equations. In Bengio, S., Wallach, H. M., Larochelle, H., Grau- man, K., Cesa-Bianchi, N., and Garnett, R. (eds.), Advances in Neural Information Processing Systems 31: Annual Co...
-
[2]
URL https://doi.org/10.1080/00401706.1980.10486199
doi: 10.1080/00401706.1980.10486199. URL https://doi.org/10.1080/00401706.1980.10486199. Covert, I., Lundberg, S. M., and Lee, S. Understanding global feature contributions with additive importance measures. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.),Advances in Neural Information Processing Systems 33: Annual Conference o...
-
[3]
URL https://doi.org/10.18653/v1/2023.acl-industry.4
doi: 10.18653/V1/2023.ACL-INDUSTRY .4. URL https://doi.org/10.18653/v1/2023.acl-industry.4. Janssen, A., Bennis, F. C., and Mathˆot, R. A. A. Adoption of machine learning in pharmacometrics: An overview of recent implementations and their considerations.Phar- maceutics, 14(9):1814, August 2022. Jonkers, I. and Lis, J. T. Getting up to speed with transcrip...
-
[4]
URL http://proceedings.mlr.press/v119/kumar20e. html. Lee, M. K., Park, N. H., Lee, S. Y ., and Kim, T. Context-dependent and locus-specific role of H3K36 methylation in transcriptional regulation.Journal of Molecular Biology, 437(1):168796, 2025. ISSN 0022-
2025
-
[5]
doi: https://doi.org/10.1016/j.jmb.2024.168796. URL https://www.sciencedirect.com/science/article/pii/ S0022283624004182. Controlling Transcription Elonga- tion and Termination. Lei, J., G’Sell, M., Rinaldo, A., Tibshirani, R. J., and Wasserman, L. Distribution-free predictive inference for regression.Journal of the American Statistical Associa- tion, 113...
-
[6]
doi: 10.1145/2939672.2939778. URL https://doi. org/10.1145/2939672.2939778. Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead.Nature Machine Intelligence, 1(5): 206–215, May 2019. ISSN 2522-5839. doi: 10. 1038/s42256-019-0048-x. URL https://doi.org/10.1038/ s42256-019-0048-x. Rumelha...
-
[7]
ISSN 1476-4687. doi: 10.1038/nature13045. URL https://doi.org/10.1038/nature13045. Yang, X., Han, H., De Carvalho, D. D., Lay, F. D., Jones, P. A., and Liang, G. Gene body methylation can alter gene expression and is a therapeutic target in cancer.Cancer Cell, 26(4):577–590, October 2014. Zamft, B., Bintu, L., Ishibashi, T., and Bustamante, C. Nascent RNA...
-
[8]
reasoning
prompts an LLM with a natural-language description of the dataset and prediction task and asks it to generate executable Python code that adds new columns, together with free-form textual justifications of their utility. The proposed transformations are accepted only if they improve validation performance of downstream classifiers such as logistic regress...
2024
-
[9]
Fit the full linear model (e.g., OLS) using the training data(Φ train,y train)to obtain the weightsw
-
[10]
Calculate the predictions ˆyval and the baseline MSEfull on the validation set(Φ val,y val)
-
[11]
change in error if term is removed
For each termψ j (fromk= 1toM): (a) Calculate the predictions of the model without term j (effectively wj = 0, other wk fixed): ˆyval,−j = ˆyval − ϕval,jwj. (b) Calculate MSE −j using ˆyval,−j. (c) Compute∆ j =MSE −j −MSE full. Computational Cost: • Fitting the initial OLS model: TypicallyO(N trainM2 +M 3)ifN train > MorO(N 2 trainM)ifM > N train. • Calcu...
2017
-
[12]
The top K terms are retained, where K corresponds to the sparsity constraint (the keep n terms hyperparameter)
Top-K Selection:The candidate terms are ranked in descending order of their aggregate influence scores ∆agg j . The top K terms are retained, where K corresponds to the sparsity constraint (the keep n terms hyperparameter). This is approach we employ in this work
-
[13]
prefer these kinds of terms because of scientific reason X
Threshold Selection:Terms are retained if their aggregate influence score exceeds a specific threshold, ∆agg j > ϵ . This allows the model complexity to adapt dynamically to the signal-to-noise ratio of the discovered terms. This is an alternative approach worth exploring, but we do not investigate it in this work. This approach effectively decouples the ...
-
[14]
Propose” agent) and another for refining the set of terms based on evaluation feedback (the “Prune
controls how many child nodes are attempted to be generated from a parent node during a single expansion step. 27 Influence-Guided Symbolic Regression: Scientific Discovery via LLM-Driven Equation Search with Granular Feedback Variation between these successors arises from the inherent stochasticity in the LLM’s responses to the propose (and, optionally, ...
-
[15]
Concatenated with the current candidate terms
-
[16]
Propose” Agent:Below is an example response from the LLM acting as the “Propose
Sent to a LLM term pruner agent that will use various computed signals to decide which terms to keep and which to drop. # Instructions: Given below information, propose some candidate terms. The terms can be any valid numpy expressions. Make use of the dataset and problem description to propose relevant terms. Make sure to use the learnings from the histo...
-
[17]
**Inspect every row **
-
[18]
keep" or
**Decide "keep" or "drop" ** for each term using the rule: * Use the heuristic: "delta_k ˜= 0 -> drop", "large delta_k -> keep" and your own judgement
-
[19]
DECISION
**Return** a python dictionary after "DECISION" with exactly the two keys DECISION ‘‘‘ {{ "keep": ["term_a", "term_b", ...], "drop": ["term_c", "term_d", ...] }} ‘‘‘‘ Place each term name in either **keep** or **drop** - never both, never neither. **IMPORTANT:** * Make use of the dataset and problem description to make the best decision. * Make sure to us...
-
[20]
- ‘cancer_volume * radiotherapy_dosage‘ (delta = 197.209) is highly impactful
**Highly influential terms **: - ‘cancer_volume * chemo_concentration‘ (delta = 638.509) is critical. - ‘cancer_volume * radiotherapy_dosage‘ (delta = 197.209) is highly impactful. - ‘np.sqrt(cancer_volume)‘ (delta = 110.587) has substantial influence. - ‘np.log(1 + cancer_volume)‘ (delta = 17.6803)
-
[21]
- ‘chemo_dosage‘, ‘radiotherapy_dosage‘: limited delta values
**Moderately influential / less relevant **: - ‘cancer_volume‘ (delta = 2.7081): core variable, but delta suggests moderate importance. - ‘chemo_dosage‘, ‘radiotherapy_dosage‘: limited delta values
-
[22]
These can be ignored safely
**Negligible**: - Terms involving weighted interactions: e.g., ‘chemo_dosage / (1 + cancer_volume)‘ (delta ˜= 0). These can be ignored safely. --- ### **Analysis for ‘dc_dt‘: **
-
[23]
- ‘chemo_dosage‘ (delta = 18.8115): essential for modeling ‘dc_dt‘
**Highly influential terms **: - ‘np.log(1 + cancer_volume)‘ (delta = 22.3107): critical. - ‘chemo_dosage‘ (delta = 18.8115): essential for modeling ‘dc_dt‘. - ‘np.sqrt(cancer_volume)‘ (delta = 15.8203): quite significant
-
[24]
- ‘cancer_volume‘: relevant, but has relatively small delta compared to other terms
**Moderately influential **: - ‘radiotherapy_dosage‘: important as part of the model. - ‘cancer_volume‘: relevant, but has relatively small delta compared to other terms
-
[25]
**Negligible terms **: - Interactions like ‘radiotherapy_dosage / (1 + cancer_volume)‘ (small delta). --- Considering both outputs, I aim to balance interpretability and prioritization based on influence across both equations. Here is the final decision: --- DECISION ‘‘‘ { "keep": [ "cancer_volume * chemo_concentration", # Very high delta for dv_dt "cance...
-
[26]
These are combined with surviving terms from the previous iteration
The LLM Propose agent suggests new terms, which may contain c(init) syntax. These are combined with surviving terms from the previous iteration
-
[27]
The set of all constantsθfrom all current candidate terms is optimized by minimizingJ(θ)
-
[28]
70 Influence-Guided Symbolic Regression: Scientific Discovery via LLM-Driven Equation Search with Granular Feedback
After optimization, the resulting terms are evaluated on the data splits (train, validation, test). 70 Influence-Guided Symbolic Regression: Scientific Discovery via LLM-Driven Equation Search with Granular Feedback
-
[29]
The Prune agent receives the terms (with their optimized c(value) markers), their fitted outer weightsw j, and their per-term influence scores∆ j
The standard pruning phase proceeds. The Prune agent receives the terms (with their optimized c(value) markers), their fitted outer weightsw j, and their per-term influence scores∆ j
-
[30]
Surviving terms, retaining theirc()markers, are passed to the next iteration
The agent returns keep/drop decisions. Surviving terms, retaining theirc()markers, are passed to the next iteration. This entire cycle is embedded within either the linear iterative refinement or the MCTS search strategy, just as in the standard IGSR framework. G.14.1. PROOF OF CONCEPT EXPERIMENT To provide a clear illustration of the specific advantage o...
-
[31]
This tests whether a non-linear predictor can extract more value from the discovered symbolic features
IGSR + XGBoost:The features ψj(x) discovered by IGSR are frozen and used as inputs to an XGBoost regressor. This tests whether a non-linear predictor can extract more value from the discovered symbolic features. 3.OpenFE + Linear Regression:OpenFE is used to generate and select features, followed by a linear predictor. 4.OpenFE + XGBoost:OpenFE is used to...
-
[32]
Scalability via Priors:IGSR avoids the combinatorial explosion typical of generative feature engineering by using LLM priors to propose semantically relevant features, making it viable for high-dimensional datasets where traditional methods fail
-
[33]
Inherent Interpretability:By optimizing features specifically for a linear backend, IGSR produces a model that is fully interpretable (f(x) = P wjψj(x)). The results show that this interpretability does not come at the cost of accuracy. Extended comparison against additional AFE baselines.The comparison above focuses on OpenFE as a representative non-LLM ...
-
[34]
•depth limit:10
The constant used in the UCT formula to balance exploration and exploitation. •depth limit:10. The maximum depth of the search tree. •rollout is just node reward: True. We utilize Heuristic MCTS where the node’s immediate validation MSE serves as the reward, without performing deep rollouts. 80 Influence-Guided Symbolic Regression: Scientific Discovery vi...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.