OpenClawBench: Benchmarking Process-side Anomalies in Real-world Agent Execution Trajectories
Pith reviewed 2026-06-29 07:38 UTC · model grok-4.3
The pith
Success-only evaluation of AI agents misses thousands of process anomalies in real executions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
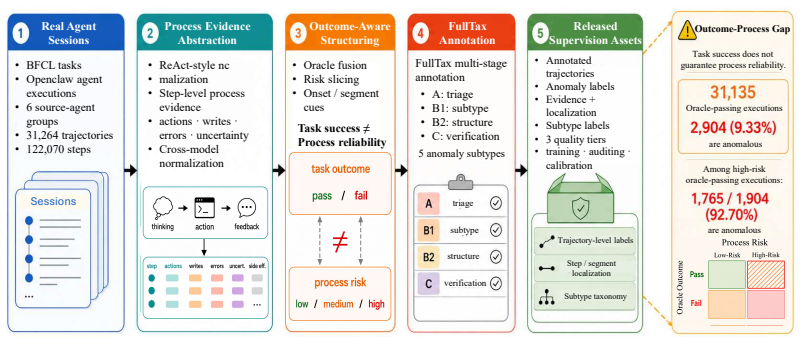
Among 31,135 oracle-passing executions, 2,904 are still labeled process-anomalous under FullTax. These results show that success-only evaluation misses a concrete class of process-side failures in real agent executions.
What carries the argument
OpenClawBench dataset of BFCL-driven trajectories paired with FullTax, which converts aligned outcome and process evidence into binary labels, supporting evidence, onset/span localization, severity, recoverability, and a 5-class anomaly taxonomy.
If this is right
- Outcome metrics alone are insufficient to certify reliable agent behavior.
- Process anomaly labels can supervise detectors that reach binary F1 of 0.729 on cleaner held-out splits.
- Execution trajectories become a source of structured, auditable supervision beyond final task oracles.
- Runtime monitoring systems can now incorporate anomaly localization and severity alongside success checks.
- Agent development can target recovery from specific anomaly classes rather than outcome improvement only.
Where Pith is reading between the lines
- Production agent systems could adopt hybrid scoring that penalizes high-severity process anomalies even on successful tasks.
- The same trajectory collection method might reveal comparable gaps in non-agent tool-use or planning systems.
- Extending the five-class taxonomy to new domains would allow cross-task comparison of anomaly patterns.
- The dataset size supports training smaller specialized models for online anomaly flagging during execution.
Load-bearing premise
The FullTax annotations produced from the BFCL-driven sessions accurately and consistently identify genuine process anomalies rather than artifacts of the annotation process or the source models.
What would settle it
Independent human re-annotation of a random subset of the 31k trajectories that yields agreement below 70 percent on binary anomaly labels with the original FullTax would falsify the claim that the labels capture real process anomalies.
Figures
read the original abstract
Task success can hide process anomalies in real-world agent executions. An agent may pass the final task oracle while still accumulating unresolved ambiguity, unsafe external writes, ignored errors, weakly grounded commitments, or capability-boundary overcommitment. We study this mismatch as the Outcome-Process Gap and introduce OpenClawBench, a large-scale dataset for measuring and supervising process-side anomalies in real agent execution processes. OpenClawBench is built from BFCL-driven OpenClaw sessions produced by 6 source models and contains 31,264 annotated trajectories. It aligns task-oracle outcomes with structured process evidence. FullTax converts the aligned trajectories into structured anomaly supervision: binary labels, supporting evidence, onset/span localization, severity, recoverability, and a 5-class anomaly taxonomy. Using OpenClawBench, we make the Outcome-Process Gap measurable. Among 31,135 oracle-passing executions, 2,904 are still labeled process-anomalous under FullTax. These results show that success-only evaluation misses a concrete class of process-side failures in real agent executions. A LoRA-fine-tuned Gemma 3 12B detector trained on the high-confidence FullTax supervised pool reaches binary F1=0.729 on the cleaner-labels held-out test split. Together, OpenClawBench turns real agent execution logs into auditable and reusable supervision for studying, diagnosing, and operationally monitoring runtime agent reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OpenClawBench, a dataset of 31,264 annotated trajectories generated from BFCL-driven OpenClaw sessions across 6 source models. It defines FullTax to produce structured process-anomaly supervision (binary labels, evidence, onset/span, severity, recoverability, and a 5-class taxonomy) aligned with task-oracle outcomes. The central claim is the Outcome-Process Gap: among 31,135 oracle-passing executions, 2,904 are labeled process-anomalous under FullTax. A LoRA-fine-tuned Gemma 3 12B detector trained on high-confidence FullTax labels reaches binary F1=0.729 on a held-out test split. The work positions the benchmark as reusable supervision for runtime agent reliability beyond success-only metrics.
Significance. If the FullTax labels are shown to be reliable, the dataset would be a substantial contribution by making process-side failures measurable at scale and supplying structured fields that support localization and severity analysis. The explicit quantification of the gap (2,904 cases) and the provision of a detector baseline are concrete strengths that could influence evaluation practices in agent research. The scale (over 31k trajectories) and alignment of oracle outcomes with process evidence are positive features for reproducibility.
major comments (2)
- [Abstract] Abstract: The headline result (2,904 process-anomalous executions out of 31,135 oracle-passing trajectories) and the Outcome-Process Gap claim rest entirely on FullTax producing accurate labels, yet the manuscript supplies no annotation protocol, inter-annotator agreement statistics, or validation sample confirming that the 5-class taxonomy captures the intended phenomena rather than artifacts of the six source models or the BFCL/OpenClaw collection process. This directly undermines assessment of the central numerical claim.
- [Results] Results (where the 2,904 count and F1=0.729 are reported): Without reported cross-model consistency metrics or human validation of the structured fields (onset/span, severity, recoverability), it is impossible to rule out systematic bias in how particular model families trigger categories such as “weakly grounded commitments” or “capability-boundary overcommitment,” which would inflate the reported gap.
minor comments (2)
- [Abstract] Abstract: The total of 31,264 trajectories is stated but the oracle-passing subset is given as 31,135; a brief clarification of the 129 non-passing cases would improve precision.
- [Introduction] The introduction of invented terms FullTax and Outcome-Process Gap would benefit from a short formal definition or table summarizing the taxonomy classes before their first use.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of validating the FullTax labeling process, which underpins the Outcome-Process Gap claim. We address each major comment below and will incorporate additional documentation and analyses in the revision to strengthen the evidence for label reliability.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline result (2,904 process-anomalous executions out of 31,135 oracle-passing trajectories) and the Outcome-Process Gap claim rest entirely on FullTax producing accurate labels, yet the manuscript supplies no annotation protocol, inter-annotator agreement statistics, or validation sample confirming that the 5-class taxonomy captures the intended phenomena rather than artifacts of the six source models or the BFCL/OpenClaw collection process. This directly undermines assessment of the central numerical claim.
Authors: We agree the current manuscript lacks an explicit annotation protocol section. FullTax is defined in Section 3 with the 5-class taxonomy and structured fields, but we will add a dedicated 'Annotation Protocol' subsection in revision detailing the labeling guidelines, evidence extraction rules, and how the taxonomy was applied to BFCL/OpenClaw trajectories. While systematic inter-annotator agreement was not computed across the full 31k scale, spot-check validation on a held-out sample was performed during curation; we will report those agreement figures and a validation sample breakdown to confirm the taxonomy aligns with intended process anomalies rather than collection artifacts. revision: yes
-
Referee: [Results] Results (where the 2,904 count and F1=0.729 are reported): Without reported cross-model consistency metrics or human validation of the structured fields (onset/span, severity, recoverability), it is impossible to rule out systematic bias in how particular model families trigger categories such as “weakly grounded commitments” or “capability-boundary overcommitment,” which would inflate the reported gap.
Authors: We will add cross-model consistency metrics in the revised Results section, including per-model breakdowns of the 2,904 anomalous cases and anomaly-type distributions across the six source models to assess potential bias. For human validation of structured fields, we will include results from a manual review of a 200-trajectory random sample confirming accuracy of onset/span, severity, and recoverability labels. These additions will directly address concerns about systematic bias in categories like weakly grounded commitments. revision: yes
Circularity Check
No circularity: results are direct empirical counts from newly collected and annotated trajectories.
full rationale
The paper constructs OpenClawBench from BFCL-driven sessions and applies FullTax to produce labels and counts (e.g., 2,904 anomalous cases out of 31,135 oracle-passing executions). These are presented as direct measurements from the dataset rather than outputs of any equation, fitted parameter, or derivation that reduces to its own inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The detector F1 result is standard held-out evaluation on the authors' own labels and does not create circularity in the primary claims. The derivation chain is self-contained data collection and reporting.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Task oracles reliably indicate whether the final task goal was achieved
invented entities (2)
-
FullTax
no independent evidence
-
Outcome-Process Gap
no independent evidence
Reference graph
Works this paper leans on
-
[1]
DeepSeek-AI. DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948; Hugging Face model cardhttps://huggingface.co/deepseek-ai/ DeepSeek-R1, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
AgentProcessBench: Diagnosing Step-Level Process Quality in Tool-Using Agents
Shengda Fan, Xuyan Ye, Yupeng Huo, Zhi-Yuan Chen, Yiju Guo, Shenzhi Yang, Wenkai Yang, Shuqi Ye, Jingwen Chen, Haotian Chen, et al. Agentprocessbench: Diagnosing step-level process quality in tool-using agents.arXiv preprint arXiv:2603.14465, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Gemma 3 technical report
Gemma Team, Google DeepMind. Gemma 3 technical report. Hugging Face model card and technical report, 2025.https://huggingface.co/google/gemma-3-12b-it
2025
-
[5]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
GLM-4.5 Team, Aohan Zeng, et al. GLM-4.5: Agentic, reasoning, and coding (ARC) foundation models. arXiv preprint arXiv:2508.06471; Hugging Face model card https://huggingface.co/zai-org/ GLM-4.5-Air, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
ATBench: A Diverse and Realistic Agent Trajectory Benchmark for Safety Evaluation and Diagnosis
Yu Li, Haoyu Luo, Yuejin Xie, Yuqian Fu, Zhonghao Yang, Shuai Shao, Qihan Ren, Wanying Qu, Yanwei Fu, Yujiu Yang, et al. Atbench: A diverse and realistic trajectory benchmark for long-horizon agent safety. arXiv preprint arXiv:2604.02022, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Yibing Liu, Chong Zhang, Zhongyi Han, Hansong Liu, Yong Wang, Yang Yu, Xiaoyan Wang, and Yilong Yin. Trajad: Trajectory anomaly detection for trustworthy llm agents.arXiv preprint arXiv:2602.06443, 2026
-
[9]
Agentauditor: Human-level safety and security evaluation for llm agents
Hanjun Luo, Shenyu Dai, Chiming Ni, Xinfeng Li, Guibin Zhang, Kun Wang, Tongliang Liu, and Hanan Salam. Agentauditor: Human-level safety and security evaluation for llm agents. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[10]
Yutao Mou, Zhangchi Xue, Lijun Li, Peiyang Liu, Shikun Zhang, Wei Ye, and Jing Shao. Toolsafe: Enhancing tool invocation safety of llm-based agents via proactive step-level guardrail and feedback.arXiv preprint arXiv:2601.10156, 2026
-
[11]
Wink: Recovering from misbehaviors in coding agents.arXiv preprint arXiv:2602.17037, 2026
Rahul Nanda, Chandra Maddila, Smriti Jha, Euna Mehnaz Khan, Matteo Paltenghi, and Satish Chandra. Wink: Recovering from misbehaviors in coding agents.arXiv preprint arXiv:2602.17037, 2026
-
[12]
Yi Nian, Aojie Yuan, Haiyue Zhang, Jiate Li, and Yue Zhao. Auditable agents.arXiv preprint arXiv:2604.05485, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Introducing gpt-oss: Openai’s open-weight models
OpenAI. Introducing gpt-oss: Openai’s open-weight models. Technical report; Hugging Face model card https://huggingface.co/openai/gpt-oss-20b, 2025
2025
-
[14]
GPT-5.4 Thinking system card
OpenAI. GPT-5.4 Thinking system card. OpenAI System Card, https://openai.com/index/ gpt-5-4-thinking-system-card/ , 2026. Model gpt-5.4-thinking; accessed via Chat Comple- tions API withreasoning_effort=mediumon 2026-05-07
2026
-
[15]
The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E Gonzalez. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. InF orty-second International Conference on Machine Learning, 2025
2025
-
[16]
Harnessing Embodied Agents: Runtime Governance for Policy-Constrained Execution
Xue Qin, Simin Luan, John See, Cong Yang, and Zhijun Li. Harnessing embodied agents: Runtime governance for policy-constrained execution.arXiv preprint arXiv:2604.07833, 2026. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Qwen Team, Alibaba Cloud. Qwen3 technical report. arXiv preprint arXiv:2505.09388; Hug- ging Face model cards: https://huggingface.co/Qwen/Qwen3.5-9B, https://huggingface.co/ Qwen/Qwen3.6-27B, https://huggingface.co/Qwen/Qwen3.6-35B-A3B (accessed 2026-05-07), 2025
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
HINTBench: Horizon-agent Intrinsic Non-attack Trajectory Benchmark
Jiacheng Wang, Jinchang Hou, Fabian Wang, Ping Jian, Chenfu Bao, and Zhonghou Lv. Hintbench: Horizon-agent intrinsic non-attack trajectory benchmark.arXiv preprint arXiv:2604.13954, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Yilun Wang, Guangba Yu, Haiyu Huang, Zirui Wang, Yujie Huang, Pengfei Chen, and Michael R Lyu. Cloud-opsbench: A reproducible benchmark for agentic root cause analysis in cloud systems.arXiv preprint arXiv:2603.00468, 2026
-
[20]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37: 52040–52094, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37: 52040–52094, 2024
2024
-
[21]
Re- act: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. Re- act: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[22]
τ-bench: A benchmark for tool-agent- user interaction in real-world domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent- user interaction in real-world domains. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[23]
Claw-Eval: Towards Trustworthy Evaluation of Autonomous Agents
Bowen Ye, Rang Li, Qibin Yang, Yuanxin Liu, Linli Yao, Hanglong Lv, Zhihui Xie, Chenxin An, Lei Li, Lingpeng Kong, et al. Claw-eval: Toward trustworthy evaluation of autonomous agents.arXiv preprint arXiv:2604.06132, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Verify Before You Commit: Towards Faithful Reasoning in LLM Agents via Self-Auditing
Wenhao Yuan, Chenchen Lin, Jian Chen, Jinfeng Xu, Xuehe Wang, and Edith Cheuk Han Ngai. Ver- ify before you commit: Towards faithful reasoning in llm agents via self-auditing.arXiv preprint arXiv:2604.08401, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents
Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents. In13th International Conference on Learning Representations, ICLR 2025, pages 88011–88046. International Conference on Learning Representations, ...
2025
-
[26]
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Zhexin Zhang, Shiyao Cui, Yida Lu, Jingzhuo Zhou, Junxiao Yang, Hongning Wang, and Minlie Huang. Agent-safetybench: Evaluating the safety of llm agents.arXiv preprint arXiv:2412.14470, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
BFCL failure
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents. In12th International Conference on Learning Representations, ICLR 2024, 2024. A Dataset Collection Details This appendix provides the collection details...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.