HunterAgent: Neuro-Symbolic Attack Trace Reconstruction under Anti-Forensics
Pith reviewed 2026-06-29 07:02 UTC · model grok-4.3
The pith
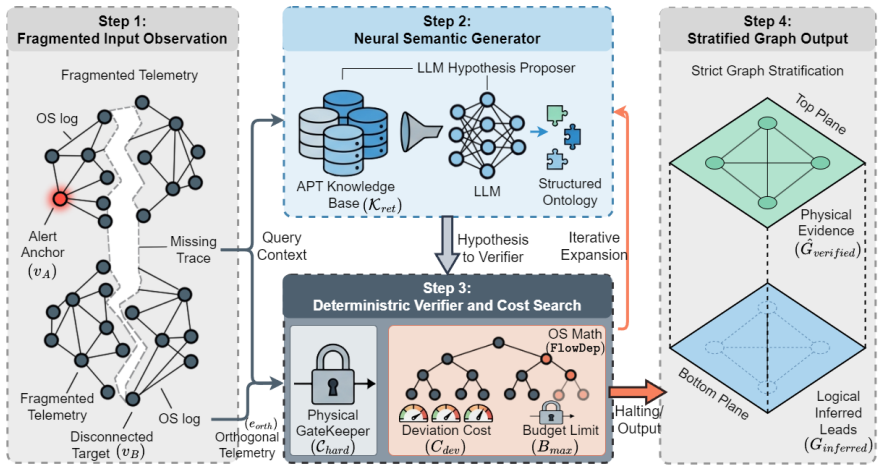
HunterAgent reconstructs severed attack traces by having an LLM propose links that a symbolic verifier then grounds in surviving telemetry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
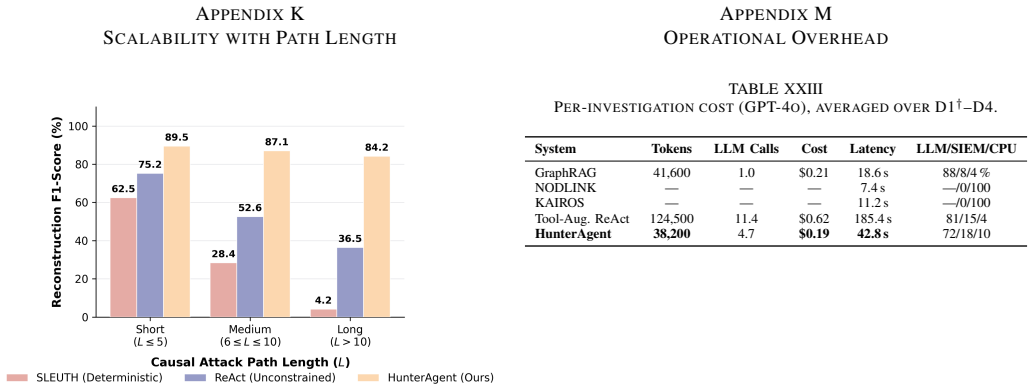
HunterAgent reframes trace reconstruction as cost-bounded heuristic graph search under partial observability. It uses an asymmetric Generator-Verifier pipeline in which the LLM proposes semantic hypotheses within a typed ontology and the verifier grounds each hypothesis through identifier-level collisions on surviving orthogonal telemetry. Hops are scored by a calibrated cost that mixes semantic divergence with OS temporal potential; schema violations are hard-pruned. A length-discounted epistemic budget prevents inferential drift and forces graceful halting. Under strict LOFO cross-validation the system reaches 86.1 percent mean F1, reduces path-level hallucination from 61.5 percent to 6.4
What carries the argument
Asymmetric Generator-Verifier pipeline that scores candidate hops with a cost combining semantic divergence and OS temporal potential while hard-pruning schema violations.
If this is right
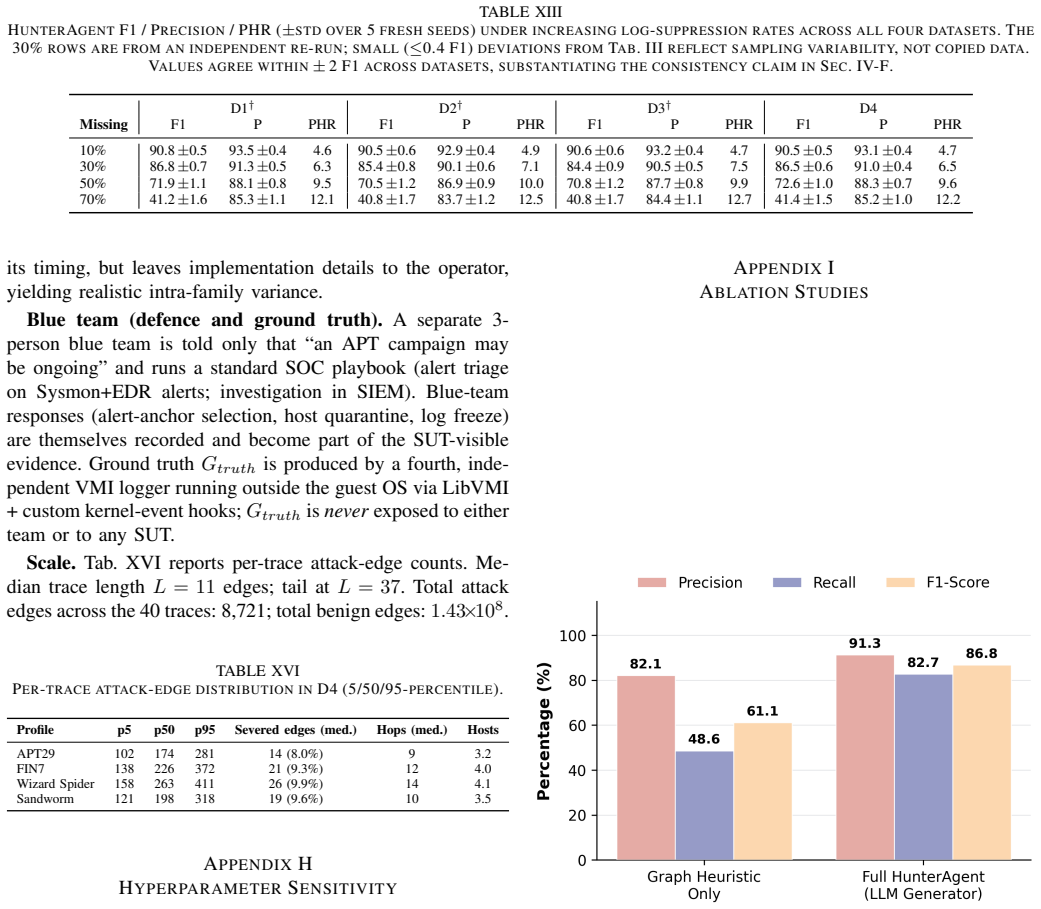
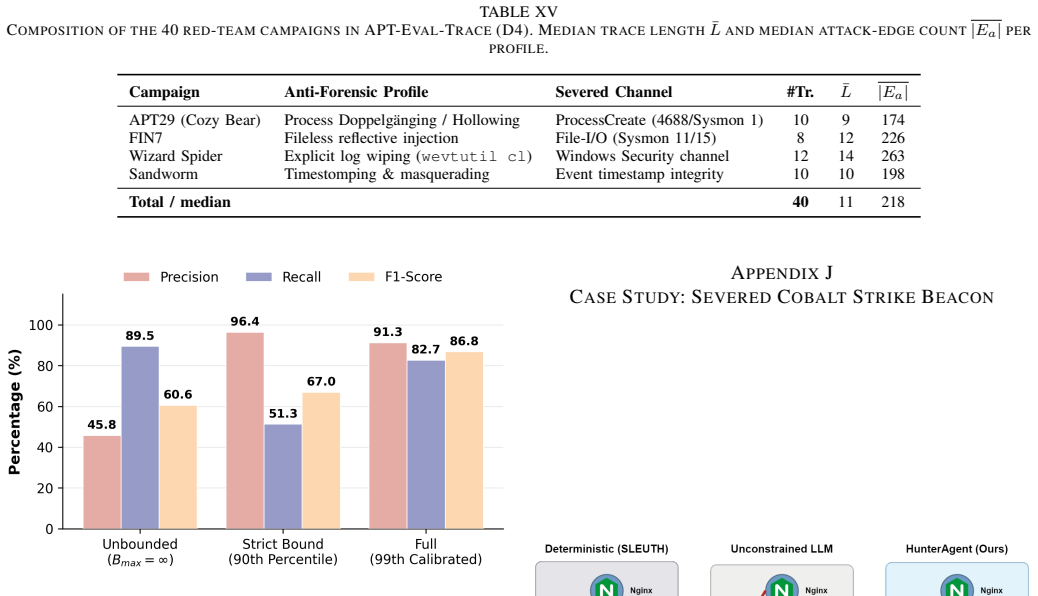
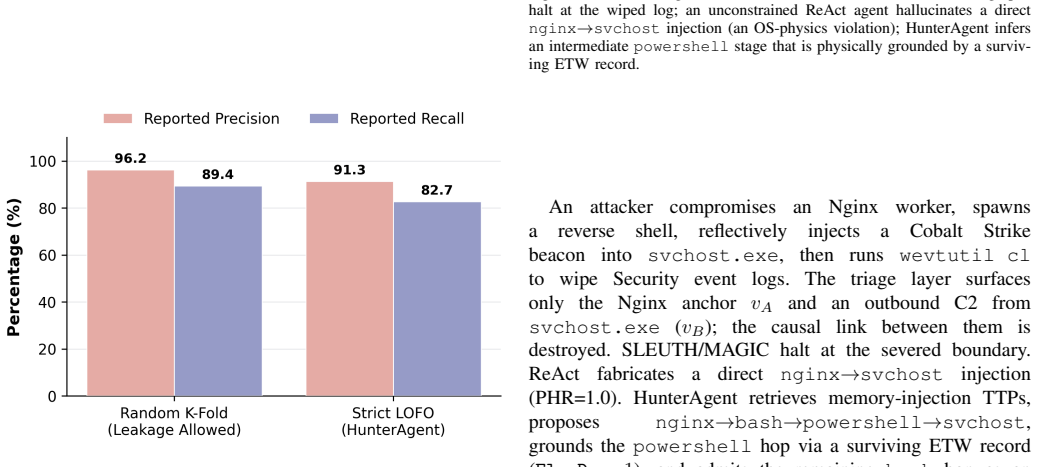
- Precision stays at or above 84 percent even when 70 percent of logs are wiped.
- Path-level hallucination falls from 61.5 percent to 6.4 percent relative to unconstrained LLM agents.
- The system halts safely without fabricating links in 95.7 percent of heavy-wiping cases.
- Mean F1 reaches 86.1 percent across three public benchmarks plus an in-house 40-trace set, exceeding the strongest prior agentic baseline by 26.7 F1 points.
Where Pith is reading between the lines
- The same generator-verifier split could be applied to reconstructing causal sequences in other domains that produce partially erased event logs, such as distributed system debugging.
- Adding more types of orthogonal telemetry as verifiers would likely raise recall without lowering the precision floor.
- The calibrated hop-cost function could be replaced by a learned model trained on verified traces, provided the verifier layer remains to enforce OS constraints.
Load-bearing premise
At least one orthogonal telemetry source survives the anti-forensic activity.
What would settle it
Run the system on a dataset in which every orthogonal telemetry source (process IDs, file hashes, network flows) has been fully erased; measure whether precision remains above 84 percent or the system halts without producing a path.
Figures


read the original abstract
Modern alert-triage systems reduce SOC burden by filtering false positives, but flagging a high-risk alert is only the start of incident response. Threat hunting requires reconstructing causal attack chains across heterogeneous, partially corrupted logs. Against APTs using anti-forensics (parent-PID spoofing, log wiping, fileless execution), provenance graphs split into disjoint subgraphs and fail. Unconstrained LLM agents fabricate causal links violating OS physics, producing fluent but forensically inadmissible narratives. We propose HunterAgent, a neuro-symbolic framework that reframes trace reconstruction as cost-bounded heuristic graph search under partial observability. It uses an asymmetric Generator-Verifier pipeline: the LLM proposes semantic hypotheses within a typed ontology, while a verifier grounds each via identifier-level collisions on surviving orthogonal telemetry. To resolve severed traces, we score hops using a calibrated cost combining semantic divergence and OS temporal potential; schema violations are hard-pruned. A length-discounted epistemic budget prevents inferential drift and forces graceful halting. Under strict LOFO cross-validation on three public benchmarks and an in-house 40-trace dataset, HunterAgent achieves 86.1% mean F1, outperforming the top agentic baseline by 26.7 F1 and KAIROS by 17.1 F1, while cutting path-level hallucination from 61.5% to 6.4%. Under 70% log wiping, recall drops but precision stays >=84%, with 95.7% halting safely. All results hold under the realistic assumption that at least one orthogonal telemetry source survives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HunterAgent, a neuro-symbolic framework for reconstructing causal attack traces from heterogeneous, partially corrupted logs under anti-forensics (e.g., parent-PID spoofing, log wiping). It uses an asymmetric Generator-Verifier pipeline in which an LLM proposes semantic hypotheses within a typed ontology while a verifier grounds links via identifier-level collisions on surviving orthogonal telemetry; hops are scored by a calibrated cost combining semantic divergence and OS temporal potential, with hard pruning of schema violations and a length-discounted epistemic budget to enforce graceful halting. Under LOFO cross-validation on three public benchmarks plus an in-house 40-trace dataset, it reports 86.1% mean F1 (outperforming the top agentic baseline by 26.7 F1 and KAIROS by 17.1 F1), reduces path-level hallucination from 61.5% to 6.4%, and maintains precision >=84% with 95.7% safe halting under 70% log wiping—all conditioned on the assumption that at least one orthogonal telemetry source survives.
Significance. If the reported improvements hold, the work supplies a concrete, cost-bounded neuro-symbolic method that demonstrably reduces hallucination relative to unconstrained LLM agents while preserving forensic admissibility constraints. The explicit LOFO cross-validation on public benchmarks, the quantitative hallucination metric, and the graceful-degradation results under partial wiping constitute measurable strengths that could inform practical SOC tooling.
major comments (2)
- [Abstract] Abstract (final sentence) and the description of the verifier: the central performance claims (86.1% F1, 6.4% hallucination, 95.7% safe halting) and the neuro-symbolic guarantee are explicitly conditioned on 'at least one orthogonal telemetry source survives.' No evaluation or ablation is supplied for the zero-survival regime; in that boundary case the verifier cannot operate via identifier-level collisions and the system reduces to the unconstrained LLM agent the introduction criticizes for fabricating OS-violating links. This assumption is load-bearing for the claimed robustness.
- [Abstract / Methods (cost function definition)] The cost function (semantic divergence + OS temporal potential) is described as 'calibrated' with a free length-discount factor for the epistemic budget, yet no pre-specified parameter values, external grounding procedure, or sensitivity analysis is provided; this leaves open whether the reported F1 gains are robust or post-hoc tuned on the evaluation sets.
minor comments (2)
- [Abstract] The abstract supplies no experimental protocol details, error bars, or verification that the cost function and epistemic budget were not tuned post-hoc; these should be added to the evaluation section for reproducibility.
- [Verifier description] Notation for the typed ontology and the precise definition of 'identifier-level collisions' should be formalized with an equation or pseudocode in the verifier subsection.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will make the indicated revisions to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract (final sentence) and the description of the verifier: the central performance claims (86.1% F1, 6.4% hallucination, 95.7% safe halting) and the neuro-symbolic guarantee are explicitly conditioned on 'at least one orthogonal telemetry source survives.' No evaluation or ablation is supplied for the zero-survival regime; in that boundary case the verifier cannot operate via identifier-level collisions and the system reduces to the unconstrained LLM agent the introduction criticizes for fabricating OS-violating links. This assumption is load-bearing for the claimed robustness.
Authors: We acknowledge that all reported results and the neuro-symbolic guarantee are conditioned on survival of at least one orthogonal telemetry source, as stated in the abstract. This reflects the verifier's reliance on identifier-level collisions, which cannot occur with zero survival; in that regime the system would reduce to the LLM generator alone. We agree the boundary case should be addressed explicitly. We will revise the abstract's final sentence for greater precision and add a limitations paragraph clarifying that complete log wiping (zero survival) falls outside the evaluated scope, as forensic reconstruction under that condition is not feasible within the current verifier design. revision: yes
-
Referee: [Abstract / Methods (cost function definition)] The cost function (semantic divergence + OS temporal potential) is described as 'calibrated' with a free length-discount factor for the epistemic budget, yet no pre-specified parameter values, external grounding procedure, or sensitivity analysis is provided; this leaves open whether the reported F1 gains are robust or post-hoc tuned on the evaluation sets.
Authors: The cost parameters were pre-specified via calibration on a held-out development set disjoint from all evaluation benchmarks. We will expand the Methods section to report the exact parameter values, the calibration procedure, and a sensitivity analysis across plausible ranges of the length-discount factor, confirming that the reported F1 improvements remain stable. revision: yes
Circularity Check
No circularity; results benchmarked on external public datasets with explicit assumption stated
full rationale
The provided abstract and text report empirical performance (86.1% F1, etc.) under LOFO cross-validation on three public benchmarks plus an in-house dataset. The key assumption ('at least one orthogonal telemetry source survives') is stated explicitly as a boundary condition rather than derived. No equations, self-citations, fitted parameters renamed as predictions, or ansatzes are quoted that would reduce any claimed derivation to its own inputs by construction. The cost function is referenced but not shown in a form that exhibits self-definitional or fitted-input circularity. This is the normal case of a paper whose central claims rest on external benchmarks rather than internal redefinition.
Axiom & Free-Parameter Ledger
free parameters (1)
- length-discount factor for epistemic budget
Reference graph
Works this paper leans on
-
[1]
Nodoze: Combatting threat alert fatigue with automated provenance triage,
W. U. Hassan, S. Guo, D. Li, Z. Chen, K. Jee, Z. Li, and A. Bates, “Nodoze: Combatting threat alert fatigue with automated provenance triage,” innetwork and distributed systems security symposium, 2019
2019
-
[2]
Holmes: real-time apt detection through correlation of suspicious information flows,
S. M. Milajerdi, R. Gjomemo, B. Eshete, R. Sekar, and V . Venkatakrish- nan, “Holmes: real-time apt detection through correlation of suspicious information flows,” in2019 IEEE symposium on security and privacy (SP). IEEE, 2019, pp. 1137–1152
2019
-
[3]
Selfprompt: Au- tonomously evaluating llm robustness via domain-constrained knowl- edge guidelines and refined adversarial prompts,
A. Pei, Z. Yang, S. Zhu, R. Cheng, and J. Jia, “Selfprompt: Au- tonomously evaluating llm robustness via domain-constrained knowl- edge guidelines and refined adversarial prompts,” inProceedings of the 31st International Conference on Computational Linguistics, 2025, pp. 6840–6854
2025
-
[4]
Prov2vec: Learning provenance graph representation for unsupervised apt detection,
B. Bhattarai and H. H. Huang, “Prov2vec: Learning provenance graph representation for unsupervised apt detection,”arXiv preprint arXiv:2310.00843, 2023
-
[5]
You are what you do: Hunting stealthy malware via data provenance analysis
Q. Wang, W. U. Hassan, D. Li, K. Jee, X. Yu, K. Zou, J. Rhee, Z. Chen, W. Cheng, C. A. Gunteret al., “You are what you do: Hunting stealthy malware via data provenance analysis.” inNDSS, 2020
2020
-
[6]
{SLEUTH}: Real- time attack scenario reconstruction from{COTS}audit data,
M. N. Hossain, S. M. Milajerdi, J. Wang, B. Eshete, R. Gjomemo, R. Sekar, S. Stoller, and V . Venkatakrishnan, “{SLEUTH}: Real- time attack scenario reconstruction from{COTS}audit data,” in26th USENIX Security Symposium (USENIX Security 17), 2017, pp. 487–504
2017
-
[7]
Tactical provenance analysis for endpoint detection and response systems,
W. U. Hassan, A. Bates, and D. Marino, “Tactical provenance analysis for endpoint detection and response systems,” in2020 IEEE symposium on security and privacy (SP). IEEE, 2020, pp. 1172–1189
2020
-
[8]
Sometimes, you aren’t what you do: Mimicry attacks against provenance graph host intrusion detection systems,
A. Goyal, X. Han, G. Wang, and A. Bates, “Sometimes, you aren’t what you do: Mimicry attacks against provenance graph host intrusion detection systems,” in30th Network and Distributed System Security Symposium, 2023
2023
-
[9]
Graph-based anomaly apt attack detection via threat intelli- gence,
C.-I. Fan, C.-H. Shie, Y .-C. Chang, T. Ban, T. Morikawa, and T. Taka- hashi, “Graph-based anomaly apt attack detection via threat intelli- gence,”IEEE Transactions on Emerging Topics in Computing, 2026
2026
-
[10]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” inThe eleventh international conference on learning representations, 2022
2022
-
[11]
Application of large language models in cybersecurity: A systematic literature review,
I. Hasanov, S. Virtanen, A. Hakkala, and J. Isoaho, “Application of large language models in cybersecurity: A systematic literature review,”IEEE access, vol. 12, pp. 176 751–176 778, 2024
2024
-
[12]
Beyond detection: large language models and next-generation cybersecurity,
A. Ali and M. C. Ghanem, “Beyond detection: large language models and next-generation cybersecurity,”SHIFRA, vol. 2025, pp. 81–97, 2025
2025
-
[13]
Heuristic-induced multimodal risk distribution jailbreak attack for multimodal large language models,
T. Ma, X. Jia, R. Duan, X. Li, Y . Huang, X. Jia, Z. Chu, and W. Ren, “Heuristic-induced multimodal risk distribution jailbreak attack for multimodal large language models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 2686–2696
2025
-
[14]
X. Jia, J. Liao, Q. Guo, T. Ma, S. Qin, R. Duan, T. Li, Y . Huang, Z. Zeng, D. Wuet al., “Omnisafebench-mm: A unified benchmark and toolbox for multimodal jailbreak attack-defense evaluation,”arXiv preprint arXiv:2512.06589, 2025
-
[15]
Reinforcement learning from multi-role debates as feedback for bias mitigation in llms,
R. Cheng, H. Ma, S. Cao, J. Li, A. Pei, Z. Wang, P. Ji, H. Wang, and J. Huo, “Reinforcement learning from multi-role debates as feedback for bias mitigation in llms,”arXiv preprint arXiv:2404.10160, 2024
-
[16]
Agr: Age group fairness reward for bias mitigation in llms,
S. Cao, R. Cheng, and Z. Wang, “Agr: Age group fairness reward for bias mitigation in llms,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[17]
Oyster-i: Beyond refusal–constructive safety alignment for responsible language models,
R. Duan, J. Liu, X. Jia, S. Zhao, R. Cheng, F. Wang, C. Wei, Y . Xie, C. Liu, D. Liet al., “Oyster-i: Beyond refusal–constructive safety alignment for responsible language models,”arXiv preprint arXiv:2509.01909, 2025
- [18]
-
[19]
Steering the Verifiability of Multimodal AI Hallucinations
J. Pang, R. Cheng, Z. Ye, X. Ma, Z. Wu, X. Huang, and Y .-G. Jiang, “Steering the verifiability of multimodal ai hallucinations,”arXiv preprint arXiv:2604.06714, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
D. Edge, H. Trinh, N. Cheng, J. Bradley, A. Chao, A. Mody, S. Truitt, D. Metropolitansky, R. O. Ness, and J. Larson, “From local to global: A graph rag approach to query-focused summarization,”arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Neuro-Symbolic AI for Cybersecurity: State of the Art, Challenges, and Opportunities
S. B. Hakim, M. Adil, A. Velasquez, S. Xu, and H. H. Song, “Neuro- symbolic ai for cybersecurity: State of the art, challenges, and opportu- nities,”arXiv preprint arXiv:2509.06921, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Experimenting with neurosymbolic ai for defending against cyber attacks,
M. W. Eckhoff, J. Halvorsen, B. J. Hansen, M. Eian, V . Mavroeidis, R. A. Chetwyn, G. Skjøtskift, and G. Grov, “Experimenting with neurosymbolic ai for defending against cyber attacks,”Neurosymbolic Artificial Intelligence Journal, 2025
2025
- [23]
-
[24]
Omegalog: High-fidelity attack investigation via transparent multi-layer log analy- sis,
W. U. Hassan, M. A. Noureddine, P. Datta, and A. Bates, “Omegalog: High-fidelity attack investigation via transparent multi-layer log analy- sis,” inNetwork and distributed system security symposium, 2020
2020
-
[25]
Kairos: Practical intrusion detection and investigation using whole- system provenance,
Z. Cheng, Q. Lv, J. Liang, Y . Wang, D. Sun, T. Pasquier, and X. Han, “Kairos: Practical intrusion detection and investigation using whole- system provenance,” in2024 IEEE Symposium on Security and Privacy (SP). IEEE, 2024, pp. 3533–3551
2024
-
[26]
Nodlink: An online system for fine-grained apt attack detection and investigation,
S. Li, F. Dong, X. Xiao, H. Wang, F. Shao, J. Chen, Y . Guo, X. Chen, and D. Li, “Nodlink: An online system for fine-grained apt attack detection and investigation,”arXiv preprint arXiv:2311.02331, 2023
-
[27]
{ATLAS}: A sequence-based learning approach for attack investigation,
A. Alsaheel, Y . Nan, S. Ma, L. Yu, G. Walkup, Z. B. Celik, X. Zhang, and D. Xu, “{ATLAS}: A sequence-based learning approach for attack investigation,” in30th USENIX security symposium (USENIX security 21), 2021, pp. 3005–3022
2021
-
[28]
Unicorn: Runtime provenance-based detector for advanced persistent threats,
X. Han, T. Pasquier, A. Bates, J. Mickens, and M. Seltzer, “Unicorn: Runtime provenance-based detector for advanced persistent threats,” arXiv preprint arXiv:2001.01525, 2020
-
[29]
Alert prioritization techniques in security monitoring: A focus on severity averaging and alert entities,
C. Bassey, S. Idowu, and C. Ojo, “Alert prioritization techniques in security monitoring: A focus on severity averaging and alert entities,” Saudi J. Eng. Technol., vol. 9, no. 07, pp. 334–339, 2024
2024
-
[30]
Information- dense reasoning for efficient and auditable security alert triage,
G. Zhao, Y . Zhang, C. Tian, D. Xie, H. Liu, and B. Wang, “Information- dense reasoning for efficient and auditable security alert triage,”arXiv preprint arXiv:2512.08169, 2025
-
[31]
Pbi-attack: Prior-guided bimodal interactive black-box jailbreak attack for toxicity maximization,
R. Cheng, Y . Ding, S. Cao, R. Duan, X. Jia, S. Yuan, S. Qin, Z. Wang, and X. Jia, “Pbi-attack: Prior-guided bimodal interactive black-box jailbreak attack for toxicity maximization,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 609–628
2025
-
[32]
Tuni: A textual unimodal detector for identity inference in clip models,
S. Li, R. Cheng, and X. Jia, “Tuni: A textual unimodal detector for identity inference in clip models,” inProceedings of the Sixth Workshop on Privacy in Natural Language Processing, 2025, pp. 1–13
2025
-
[33]
Gibberish is all you need for membership inference detection in contrastive language-audio pretraining,
R. Cheng, Y . Ding, S. Cao, and Z. Wang, “Gibberish is all you need for membership inference detection in contrastive language-audio pretraining,” inProceedings of the 2025 International Conference on Multimedia Retrieval, 2025, pp. 108–116
2025
-
[34]
S. Zhao, R. Duan, J. Liu, X. Jia, F. Wang, C. Wei, R. Cheng, Y . Xie, C. Liu, Q. Guoet al., “Strata-sword: A hierarchical safety evaluation towards llms based on reasoning complexity of jailbreak instructions,” arXiv preprint arXiv:2509.01444, 2025
-
[35]
Membership Inference for Contrastive Pre-training Models with Text-only PII Queries
R. Cheng, Y . Ding, J. Zhao, H. Zhang, H. Ma, T. Zhang, Y . Huang, and X. Li, “Membership inference for contrastive pre-training models with text-only pii queries,”arXiv preprint arXiv:2603.14222, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
G. Deng, Y . Liu, V . Mayoral-Vilches, P. Liu, Y . Li, Y . Xu, T. Zhang, Y . Liu, M. Pinzger, and S. Rass, “Pentestgpt: An llm-empowered automatic penetration testing tool,”arXiv preprint arXiv:2308.06782, 2023
-
[37]
Secllm: Enhancing security smell detection in iac with large language models,
G. De Vito, F. Palomba, and F. Ferrucci, “Secllm: Enhancing security smell detection in iac with large language models,”IEEE Access, vol. 13, pp. 204 480–204 498, 2025
2025
-
[38]
Craken: Cybersecurity llm agent with knowledge-based execution,
M. Shao, H. Xi, N. Rani, M. Udeshi, V . S. C. Putrevu, K. Milner, B. Dolan-Gavitt, S. K. Shukla, P. Krishnamurthy, F. Khorramiet al., “Craken: Cybersecurity llm agent with knowledge-based execution,” arXiv preprint arXiv:2505.17107, 2025
-
[39]
Llm-driven provenance forensics for threat investigation and detection,
K. Mukherjee and M. Kantarcioglu, “Llm-driven provenance forensics for threat investigation and detection,”arXiv preprint arXiv:2508.21323, 2025
-
[40]
arXiv preprint arXiv:2509.18970 , year=
X. Lin, Y . Ning, J. Zhang, Y . Dong, Y . Liu, Y . Wu, X. Qi, N. Sun, Y . Shang, K. Wanget al., “Llm-based agents suffer from hallucina- tions: A survey of taxonomy, methods, and directions,”arXiv preprint arXiv:2509.18970, 2025
-
[41]
The emerged security and privacy of llm agent: A survey with case studies,
F. He, T. Zhu, D. Ye, B. Liu, W. Zhou, and P. S. Yu, “The emerged security and privacy of llm agent: A survey with case studies,”ACM Computing Surveys, vol. 58, no. 6, pp. 1–36, 2025
2025
-
[42]
Ecoalign: An economically rational framework for efficient lvlm alignment,
R. Cheng, H. Ma, T. Ma, and H. Zhang, “Ecoalign: An economically rational framework for efficient lvlm alignment,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[43]
Adversarial Orthogonal Disentanglement for LVLM Hallucination Mitigation
R. Cheng, H. Ma, Z. Hai, Y . Huang, R. Duan, T. Zhang, X. Yang, Z. Ye, and X. Ma, “Adversarial orthogonal disentanglement for lvlm hallucination mitigation,” 2026. [Online]. Available: https://arxiv.org/abs/2605.25377
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Mitre att&ck: Design and philosophy,
B. E. Strom, A. Applebaum, D. P. Miller, K. C. Nickels, A. G. Pennington, and C. B. Thomas, “Mitre att&ck: Design and philosophy,” 2018
2018
-
[45]
Analyzing the usefulness of the darpa transparent computing e5 dataset in apt detection research,
G. Ouyang, Y . Huang, and C. Zhang, “Analyzing the usefulness of the darpa transparent computing e5 dataset in apt detection research,” inInternational Conference on Computer, Artificial Intelligence, and Control Engineering (CAICE 2022), vol. 12288. SPIE, 2022, pp. 400– 409
2022
-
[46]
Analyzing the usefulness of the darpa optc dataset in cyber threat detection research,
M. M. Anjum, S. Iqbal, and B. Hamelin, “Analyzing the usefulness of the darpa optc dataset in cyber threat detection research,” inProceedings of the 26th ACM symposium on access control models and technologies, 2021, pp. 27–32
2021
-
[47]
Inductive representation learning on large graphs,
W. L. Hamilton, R. Ying, and J. Leskovec, “Inductive representation learning on large graphs,” inAdvances in Neural Information Processing Systems (NeurIPS), 2017. APPENDIXA EVADEKITPERTURBATIONPSEUDOCODE EVADEKITtakes a labelled traceT= ( ˆG,L)from any of the public benchmarks (D1, D2, D3) and produces the perturbed traceT † = ( ˆG†,L)visible to the SUT,...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.