Learnable Assessment Skills for LLM-based Automated Scoring: Rubric Construction via Iterative Optimization
Pith reviewed 2026-06-29 08:05 UTC · model grok-4.3
The pith
LLMs can learn item-independent assessment skills to construct rubrics that improve automated scoring and often surpass expert ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that assessment skills can be formalized as item-independent natural-language procedural knowledge and learned via an iterative optimization framework that refines learnable rules using LLM-driven diagnosis of scoring errors and validation-gated selection, enabling rubric construction that requires no expert input and yields superior scoring performance compared to dataset-provided expert rubrics across all ten ASAP-SAS items.
What carries the argument
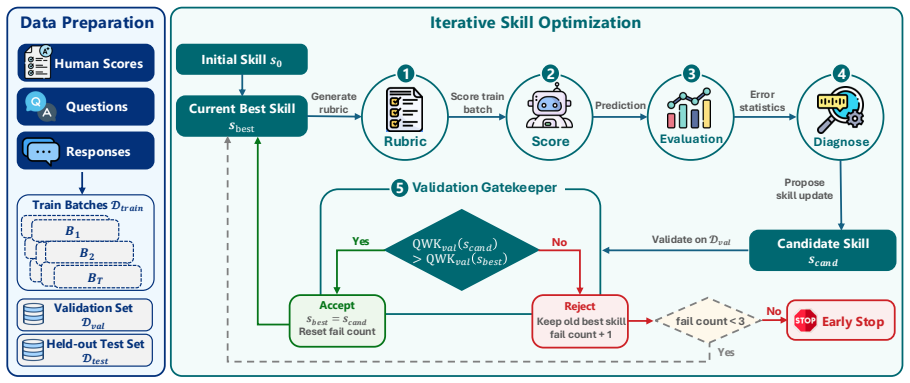
Iterative framework that decomposes a skill into a fixed scaffold and learnable item-agnostic rules, refined through LLM-driven diagnosis of scoring errors and validation-gated selection.
If this is right
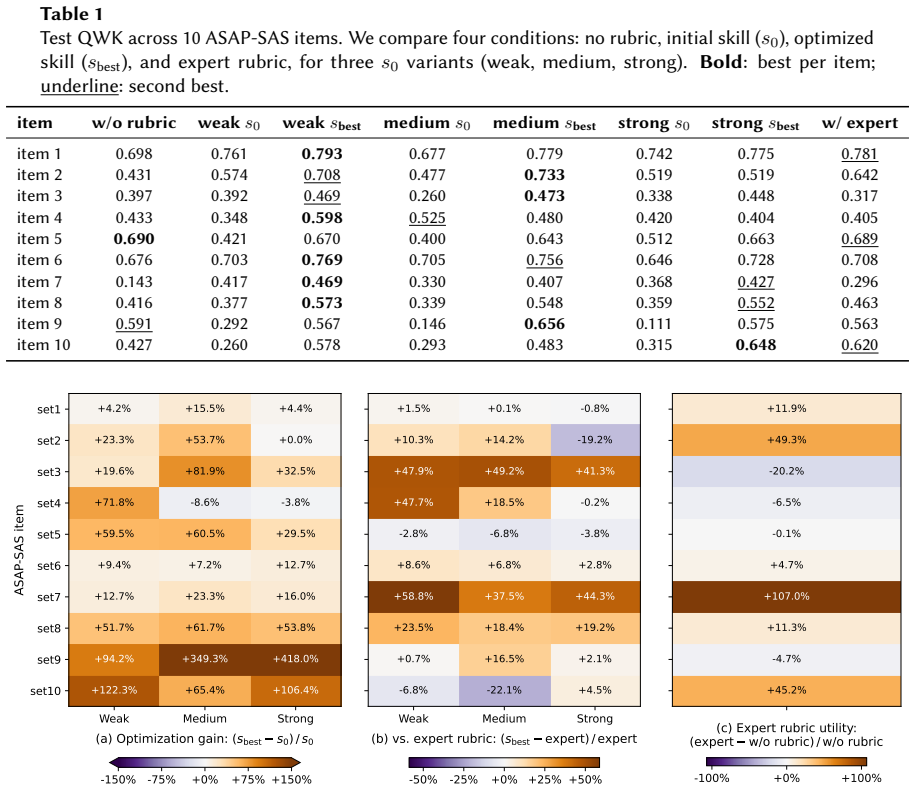
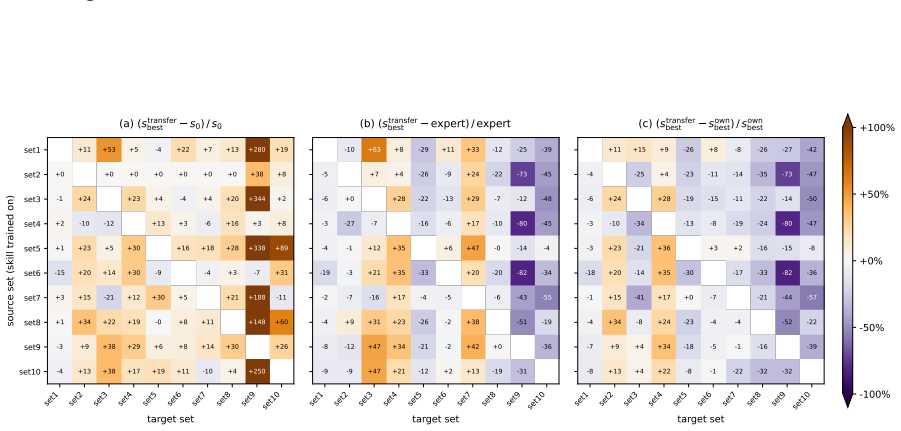
- Optimized skills substantially improve LLM-based scoring on all ten ASAP-SAS items.
- Learned skills frequently surpass the dataset-provided expert rubric.
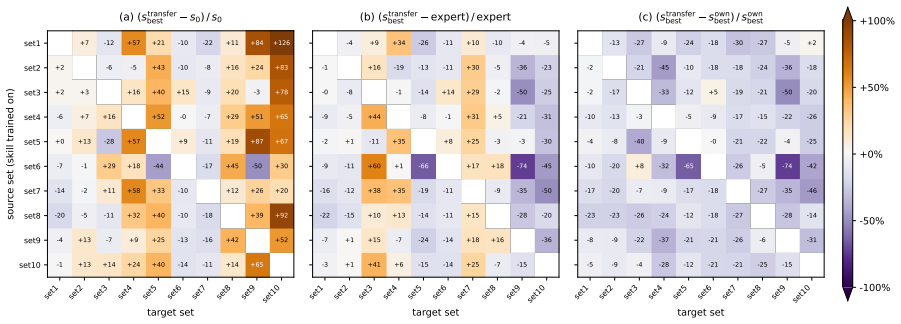
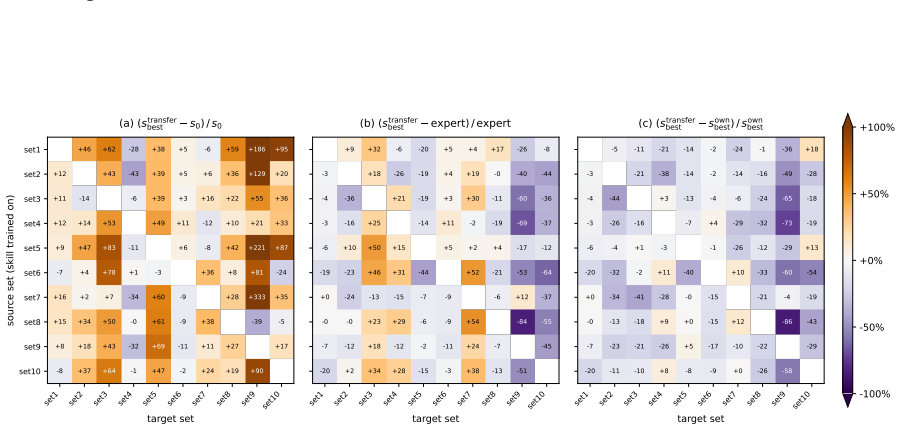
- Cross-item transfer experiments show that learned skills capture both generalizable and item-specific patterns.
Where Pith is reading between the lines
- If the skills transfer reliably to new domains, they could allow fully automated initialization of scoring systems for novel tasks without any human rubric authoring.
- The same validation-gated refinement loop might be applied to optimize other stages of the scoring workflow beyond rubric construction.
- The presence of both generalizable and item-specific patterns suggests hybrid systems could combine shared rules with lightweight per-item adaptation.
Load-bearing premise
The iterative refinement process driven by LLM diagnosis of errors and gated by validation performance produces rules that capture genuine assessment heuristics rather than overfitting to the training and validation splits.
What would settle it
Apply the learned skills to a fresh set of items drawn from a different assessment domain and measure whether scoring accuracy fails to exceed the expert-rubric baseline.
Figures
read the original abstract
LLM-based automated scoring approaches near-human performance, but scaling to new tasks remains bottlenecked by the per-item human configuration of upstream stages such as rubric construction. Human experts bypass this bottleneck through evaluation heuristics developed over extensive practice. We ask whether LLMs can learn similar heuristics directly from scoring experience, and formalize this as the concept of assessment skills: item-independent natural-language procedural knowledge that guides LLMs through specific stages of the scoring workflow. Focusing on rubric construction as a first instantiation, we propose an iterative framework that decomposes a skill into a fixed scaffold and learnable item-agnostic rules, refining the rules through LLM-driven diagnosis of scoring errors and validation-gated selection. The framework requires no expert-written rubric. On all ten ASAP-SAS items, optimized skills substantially improve LLM-based scoring and frequently surpass the dataset-provided expert rubric. Cross-item transfer experiments further reveal that learned skills capture both generalizable and item-specific patterns.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 'assessment skills' as item-independent natural-language procedural knowledge for LLM-based scoring workflows, instantiated here via rubric construction. It proposes an iterative optimization framework that decomposes skills into a fixed scaffold plus learnable rules, refined through LLM-driven diagnosis of scoring errors and selection gated by validation performance. No expert rubric is required. Experiments on all ten ASAP-SAS items report that the optimized skills yield substantial scoring improvements and often outperform the dataset-provided expert rubrics; cross-item transfer experiments indicate capture of both generalizable and item-specific patterns.
Significance. If the central claim holds—that the learned rules reflect genuine, transferable assessment heuristics rather than optimization artifacts—the work would meaningfully reduce the human configuration bottleneck in automated scoring. The empirical demonstration across ten items and the cross-item transfer results would constitute a concrete advance in showing that LLMs can acquire procedural evaluation knowledge from experience without expert supervision.
major comments (2)
- [Abstract / Iterative Framework] Abstract and Methods (iterative framework description): The validation-gated selection process—refining rules via LLM error diagnosis and retaining those that improve validation performance—directly risks selecting rules that exploit split-specific patterns or noise in the ASAP-SAS data rather than robust heuristics. Because the same validation data is used repeatedly across iterations for both diagnosis and selection, the reported gains and cross-item transfer results may reflect overfitting artifacts; this undermines the interpretation that the skills capture genuine assessment procedural knowledge. A nested cross-validation scheme or fully held-out test set for final reporting is required to substantiate the claims.
- [Results] Results (performance claims across ten items): The abstract states consistent gains and frequent outperformance of the expert rubric but supplies no error bars, statistical significance tests, exact number of iterations, or details on how the validation set was partitioned from training and test data. Without these, it is impossible to determine whether the improvements are reliable or whether post-hoc choices in the loop inflate the reported cross-item transfer effects.
minor comments (2)
- [Framework Definition] The paper should clarify the precise definition and fixed scaffold components of an 'assessment skill' with an explicit example in the main text rather than leaving the decomposition implicit.
- [Discussion] Add a limitations section discussing potential sensitivity of the LLM diagnosis step to the choice of base model and prompt phrasing.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract / Iterative Framework] Abstract and Methods (iterative framework description): The validation-gated selection process—refining rules via LLM error diagnosis and retaining those that improve validation performance—directly risks selecting rules that exploit split-specific patterns or noise in the ASAP-SAS data rather than robust heuristics. Because the same validation data is used repeatedly across iterations for both diagnosis and selection, the reported gains and cross-item transfer results may reflect overfitting artifacts; this undermines the interpretation that the skills capture genuine assessment procedural knowledge. A nested cross-validation scheme or fully held-out test set for final reporting is required to substantiate the claims.
Authors: We acknowledge the validity of this concern regarding potential overfitting from repeated use of the validation set in the iterative loop. While the cross-item transfer experiments provide some evidence of generalization beyond single-item splits, we agree that a more rigorous validation strategy is needed. In the revised manuscript, we will incorporate a nested cross-validation scheme to ensure that the learned assessment skills reflect robust heuristics rather than artifacts of the data splits. revision: yes
-
Referee: [Results] Results (performance claims across ten items): The abstract states consistent gains and frequent outperformance of the expert rubric but supplies no error bars, statistical significance tests, exact number of iterations, or details on how the validation set was partitioned from training and test data. Without these, it is impossible to determine whether the improvements are reliable or whether post-hoc choices in the loop inflate the reported cross-item transfer effects.
Authors: We agree that the current presentation lacks sufficient statistical details to fully substantiate the claims. We will revise the results section to include error bars, report the exact number of iterations used, provide clear details on the data partitioning, and include statistical significance tests for the performance improvements across the ten items. revision: yes
Circularity Check
No circularity; empirical optimization on external dataset benchmarks
full rationale
The paper describes an iterative LLM-driven framework for refining assessment skills (item-agnostic rules) via error diagnosis and validation-gated selection, with all claims resting on measured performance gains on the ASAP-SAS dataset and cross-item transfer tests. No equations, derivations, or self-citations are invoked that reduce any result to its inputs by construction; the process is algorithmic and externally benchmarked rather than self-definitional or fitted-input-renamed-as-prediction. The framework is therefore self-contained against the reported dataset metrics.
Axiom & Free-Parameter Ledger
invented entities (1)
-
assessment skills
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A. Pack, A. Barrett, J. Escalante, Large language models and automated essay scoring of english language learner writing: Insights into validity and reliability, Computers and Education: Artificial Intelligence 6 (2024) 100234
2024
-
[2]
Impey, M
C. Impey, M. Wenger, N. Garuda, S. Golchin, S. Stamer, Using large language models for auto- mated grading of student writing about science, International Journal of Artificial Intelligence in Education 35 (2025) 1825–1859
2025
-
[3]
F. Tang, W. Gao, L. Peng, J. Zhan, Agibench: a multi-granularity, multimodal, human-referenced, auto-scoring benchmark for large language models, in: International Symposium on Benchmarking, Measuring and Optimization, Springer, 2023, pp. 137–152
2023
-
[4]
Yamamoto, N
M. Yamamoto, N. Umemura, H. Kawano, Automated essay scoring system based on rubric, in: International Conference on Applied Computing and Information Technology, Springer, 2017, pp. 177–190
2017
-
[5]
M. Xue, X. Xiao, Y. Liu, M. Wilson, On the consistency of automatic scoring with large language models, Educational and Psychological Measurement (2026) 00131644261418138
2026
-
[6]
X. Xia, N. Yuruk, Y. Wang, X. Zhai, Using learning progressions to guide ai feedback for science learning, arXiv preprint arXiv:2603.03249 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
W. Xie, J. Niu, C. J. Xue, N. Guan, Grade like a human: Rethinking automated assessment with large language models, in: Proceedings of the International Conference on Research in Adaptive and Convergent Systems, 2025, pp. 1–8
2025
-
[8]
Y. Wang, Z. Ding, X. Wu, S. Sun, N. Liu, X. Zhai, Autoscore: Enhancing automated scoring with multi-agent large language models via structured component recognition, in: Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, 2026, pp. 40898–40906
2026
-
[9]
X. Tang, G. A. Ambrose, Y. Cheng, Designing reliable llm-assisted rubric scoring for constructed responses: Evidence from physics exams, arXiv preprint arXiv:2604.12227 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [10]
- [11]
-
[12]
X. Wei, Q. Zong, X. Li, E. J. Yu, S. Li, Qurl: Rubrics as judge for open-ended question answering, in: The Fourteenth International Conference on Learning Representations, 2026
2026
-
[13]
Shinn, F
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, S. Yao, Reflexion: Language agents with verbal reinforcement learning, Advances in neural information processing systems 36 (2023) 8634–8652
2023
-
[14]
A. Zhao, D. Huang, Q. Xu, M. Lin, Y.-J. Liu, G. Huang, Expel: Llm agents are experiential learners, in: Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, 2024, pp. 19632–19642
2024
- [15]
-
[16]
L. A. Agrawal, S. Tan, D. Soylu, N. Ziems, R. Khare, K. Opsahl-Ong, A. Singhvi, H. Shandilya, M. J. Ryan, M. Jiang, et al., Gepa: Reflective prompt evolution can outperform reinforcement learning, arXiv preprint arXiv:2507.19457 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [17]
-
[18]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al., Qwen3 technical report, arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, I. Stoica, Efficient memory management for large language model serving with pagedattention, in: Proceedings of the 29th symposium on operating systems principles, 2023, pp. 611–626
2023
-
[20]
URL: https://openai.com/index/ gpt-5-4-thinking-system-card/, accessed: 2026-04-25
OpenAI, Gpt-5.4 thinking system card, 2026. URL: https://openai.com/index/ gpt-5-4-thinking-system-card/, accessed: 2026-04-25. A. Initial Skill Variants We experiment with three versions of the human-authored scaffold 𝑠0. Their full texts are provided below. Weak𝑠 0 Generate a scoring rubric for the test item. Medium𝑠 0 You are an expert in educational a...
2026
-
[21]
Identify what the student is being asked to do (e.g., list, describe, explain, compare, analyze)
ANALYZE THE TASK: Read the item carefully. Identify what the student is being asked to do (e.g., list, describe, explain, compare, analyze). Determine the subject area and the core concept being assessed
-
[22]
Each key element should be an independently verifiable claim or piece of information
IDENTIFY KEY ELEMENTS: Based on the task requirements and your domain knowledge, list all the specific, scorable pieces of evidence that a complete and correct response should contain. Each key element should be an independently verifiable claim or piece of information
-
[23]
Use the number of key elements addressed as the primary basis for distinguishing score levels
DEFINE SCORE LEVELS: Map the key elements to score levels. Use the number of key elements addressed as the primary basis for distinguishing score levels. Assign the highest score to responses that address all or nearly all key elements, and the lowest score to responses that address none
-
[24]
WRITE SCORE DESCRIPTORS: For each score level, write a brief descriptor that specifies what a response at that level looks like, referencing the key elements
-
[25]
Specify how these should be handled
ANTICIPATE VARIATION: List common alternative phrasings, partial understandings, or borderline cases that scorers may encounter. Specify how these should be handled. OUTPUT FORMAT: - Key Elements: [numbered list] - Scoring Scale: [score levels with descriptors] - Scoring Notes: [edge cases and acceptable variations] B. Prompt Templates Rubric Generation P...
-
[26]
EXPLORE Read all error cases. Report what you observe about the distribution: Which confusion patterns are most common? (human score → model score) Which direction dominates (over-scoring, under-scoring, or mixed)? Are there structural features shared by many errors (response length, presence of specific reasoning patterns, types of content)? Quote specif...
-
[27]
Name each cluster by the pattern it represents, not by its symptom
CLUSTER Group the errors into a small number (2–5) of error clusters, where each cluster contains errors that plausibly share the same underlying cause. Name each cluster by the pattern it represents, not by its symptom. List which specific cases belong to each cluster
-
[28]
EXPLAIN EACH CLUSTER For each cluster, answer: - What is the underlying failure pattern that produces these errors? - What does the rubric do wrong in the face of this pattern? - What does the current skill fail to instruct that led the rubric to be this way?
-
[29]
REVISE THE SKILL For each cluster’s root cause, propose a modification to the skill. The modification must: - Target a skill instruction, not a rubric content item - Be general (work for any subject, any item) - Be concrete enough that the next rubric generation would behave differently Output the full revised skill. During steps 1–3 you may quote specifi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.