MusTBENCH: Benchmarking and Advancing Temporal Grounding in Music LLMs
Pith reviewed 2026-06-29 07:57 UTC · model grok-4.3
The pith
Existing music large audio-language models fail at precise temporal grounding in audio, but a four-stage optimization recipe called MusT delivers significant gains on expert-validated tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
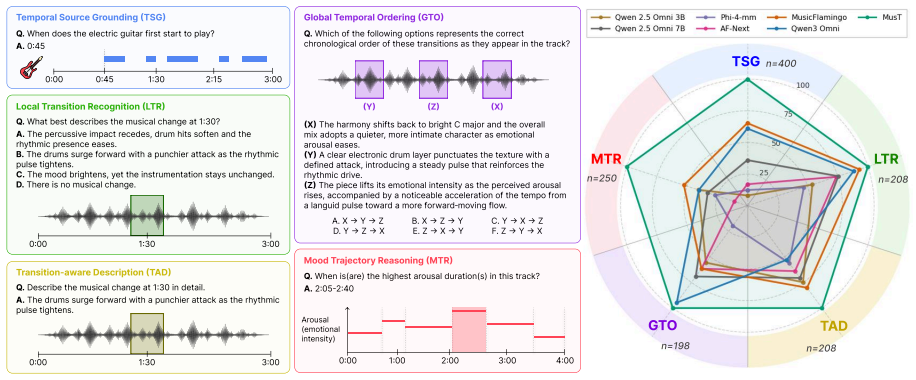
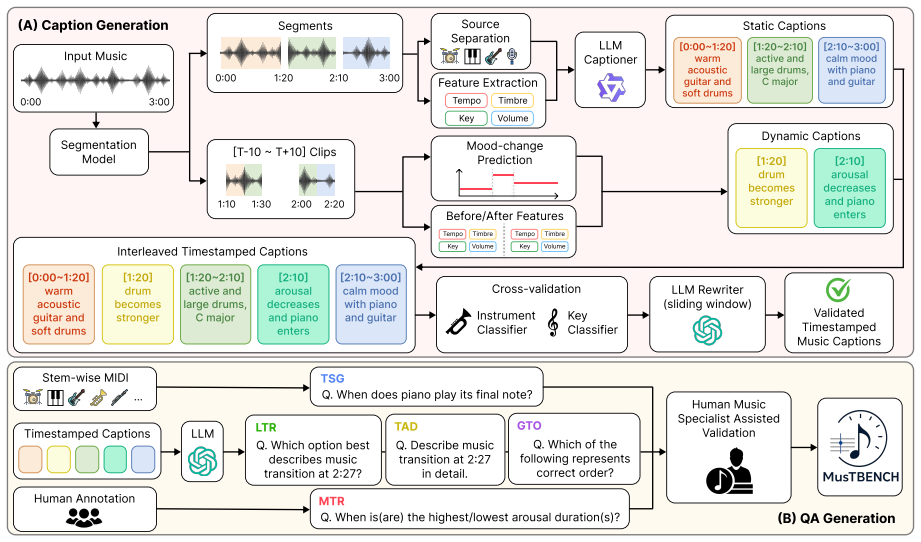
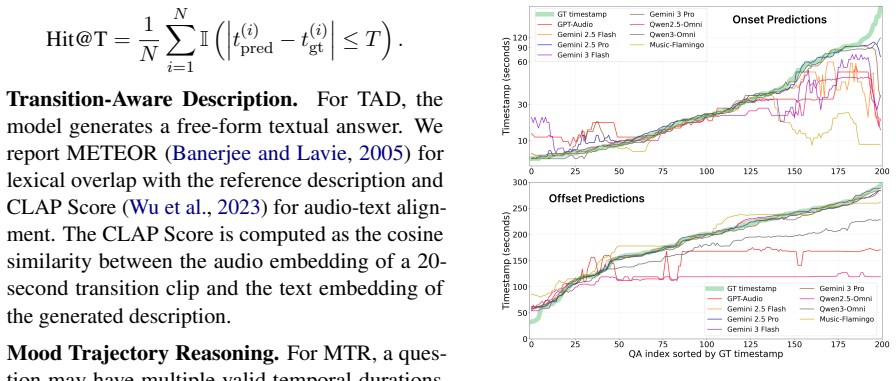
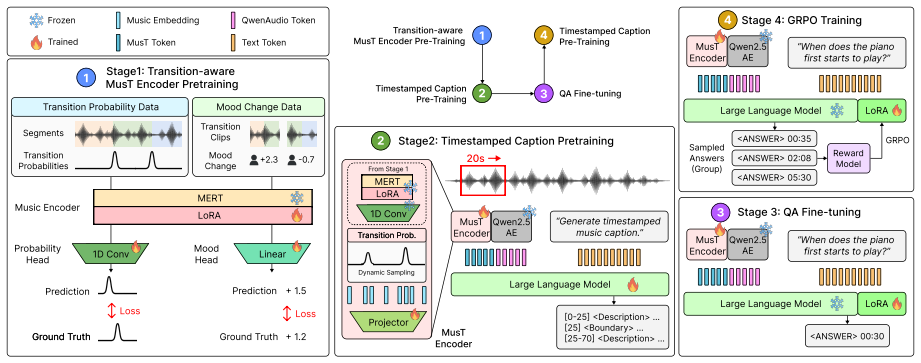
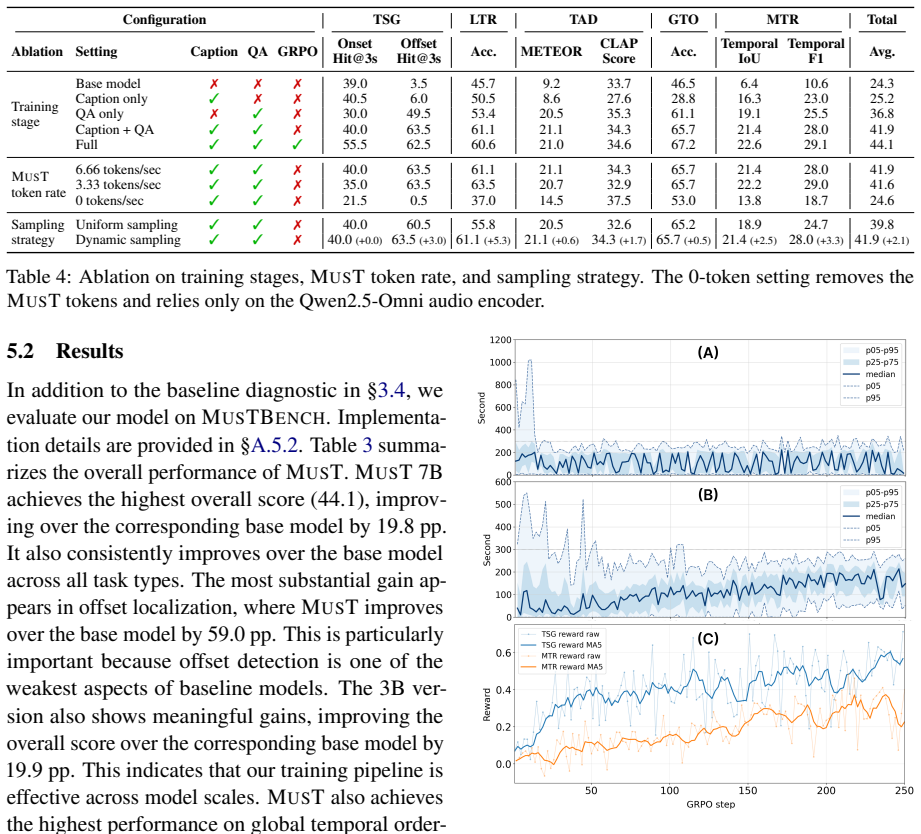
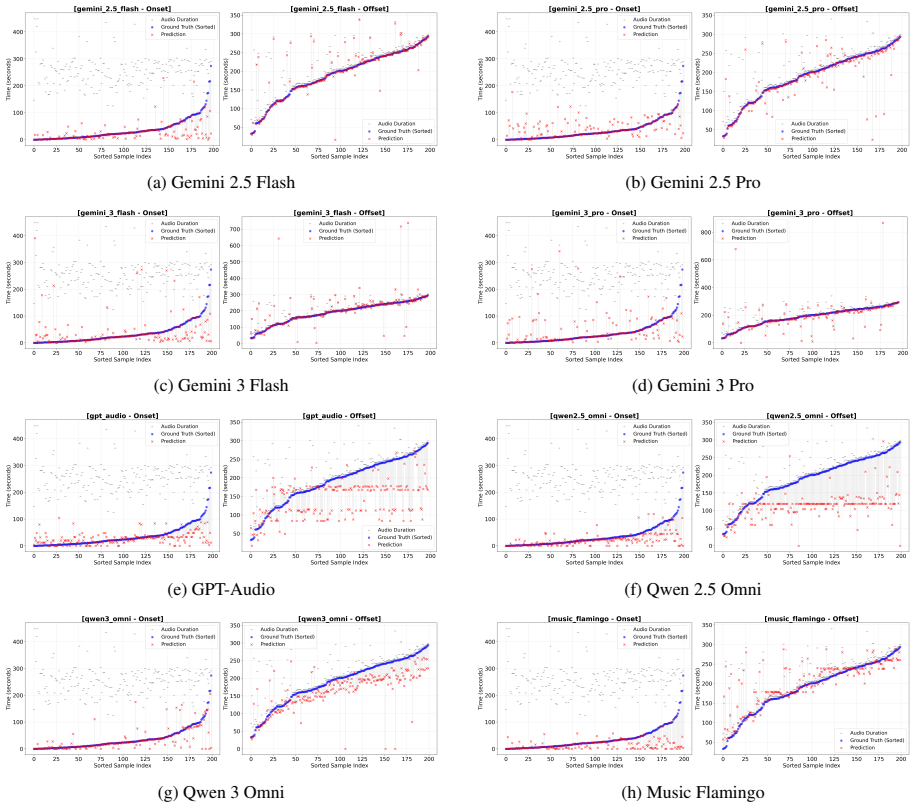
MusTBENCH measures temporal grounding via five expert-validated QA tasks focused on localized musical events. Existing LALMs struggle with precise alignment between responses and audio timestamps. MusT, a four-stage temporal optimization recipe of music encoder adaptation, LLM adaptation, LLM supervised fine-tuning, and RL-based optimization, produces significant improvements over strong baselines.
What carries the argument
MusT, the four-stage temporal optimization recipe that performs music encoder adaptation, LLM adaptation, supervised fine-tuning, and RL-based optimization to improve timing alignment.
If this is right
- MusT-trained models produce responses better aligned with specific timestamps in music audio.
- MusTBENCH becomes a standard test for evaluating future music LLMs on temporal accuracy.
- Focus shifts to handling localized events such as instrument entries and rhythmic transitions.
- Temporal grounding is established as a distinct training target separate from general music content understanding.
Where Pith is reading between the lines
- Similar timing weaknesses likely appear in non-music audio tasks such as speech or environmental sound understanding.
- Improved temporal grounding could support downstream uses like music editing tools or synchronized analysis.
- The benchmark design may need periodic updates to prevent models from overfitting to its specific question patterns.
Load-bearing premise
The five tasks in MusTBENCH, validated by music experts, measure temporal grounding ability without being skewed by question wording or audio clip selection.
What would settle it
A model that scores high on MusTBENCH but still gives incorrect timestamps for the same events when tested on new music clips not used in the benchmark.
Figures



read the original abstract
Recent Large Audio-Language Models (LALMs) have demonstrated promising abilities in understanding musical content. However, whether their responses are grounded in the correct temporal regions of the audio remains underexplored. This limitation is particularly critical for music understanding, where key information often occurs as temporally localized events, such as instrument entries and rhythmic transitions. To address this gap, we introduce MusTBENCH, a music-expert-validated benchmark designed to evaluate temporal grounding in LALMs through five temporally grounded question-answering tasks. To further improve temporal grounding in existing models, we propose MusT, a novel four-stage temporal optimization recipe spanning music encoder adaptation, LLM adaptation, LLM supervised fine-tuning, and RL-based optimization. Experiments on MusTBENCH show that existing LALMs struggle with precise temporal grounding, while MusT brings significant improvements over strong baselines. These results establish temporal grounding as a key missing capability in current LALMs and position MusTBENCH as a challenging benchmark for future research in temporally grounded music understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MusTBENCH, a music-expert-validated benchmark consisting of five temporally grounded question-answering tasks to evaluate precise temporal grounding in Large Audio-Language Models (LALMs) for music. It also proposes MusT, a four-stage optimization recipe (music encoder adaptation, LLM adaptation, supervised fine-tuning, and RL-based optimization) to improve this capability. Experiments indicate that existing LALMs struggle with temporal grounding while MusT yields significant gains over strong baselines.
Significance. If the benchmark construction, validation, and reported gains hold under scrutiny, the work identifies temporal grounding as an underexplored limitation in music LALMs and supplies both an evaluation resource and a training recipe, which could guide subsequent model development in audio-language modeling.
minor comments (1)
- [Abstract] Abstract states that MusT brings 'significant improvements' and that existing LALMs 'struggle,' but provides no quantitative metrics, baseline names, or effect sizes, making it impossible to gauge the practical magnitude of the advance from the provided text alone.
Simulated Author's Rebuttal
We thank the referee for their summary of the manuscript and for noting the potential significance of MusTBENCH as an evaluation resource and MusT as a training recipe. The recommendation is listed as uncertain, but the report contains no specific major comments or requests for clarification. We address this below and remain available to provide further details on benchmark construction, expert validation, or experimental results.
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description introduce MusTBENCH as an externally validated benchmark with five tasks and MusT as a four-stage training recipe. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the text. Claims about LALMs struggling with temporal grounding and MusT improvements are framed as empirical outcomes on the benchmark, without reduction to author-defined inputs by construction. This matches the default non-circular case for benchmark papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Springer. Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, and 1 others. 2024. Qwen2-audio technical report.arXiv preprint arXiv:2407.10759. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Mar- cel Blistein, Ori Ram, Dan Zhang, Evan Ros...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
10 Edith Law, Kris West, Michael I Mandel, Mert Bay, and J Stephen Downie
Tac: Timestamped audio captioning.arXiv preprint arXiv:2602.15766. 10 Edith Law, Kris West, Michael I Mandel, Mert Bay, and J Stephen Downie. 2009. Evaluation of algorithms using games: The case of music tagging. InISMIR, pages 387–392. Guangyao Li, Yake Wei, Yapeng Tian, Chenliang Xu, Ji-Rong Wen, and Di Hu. 2022. Learning to answer questions in dynamic ...
-
[3]
InInter- national Conference on Learning Representations, volume 2024, pages 12181–12204
Mert: Acoustic music understanding model with large-scale self-supervised training. InInter- national Conference on Learning Representations, volume 2024, pages 12181–12204. Shansong Liu, Atin Sakkeer Hussain, Chenshuo Sun, and Ying Shan. 2024a. Music understanding llama: Advancing text-to-music generation with question answering and captioning. InICASSP ...
-
[4]
Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Tay- lor Berg-Kirkpatrick, and Shlomo Dubnov
Muchomusic: Evaluating music understand- ing in multimodal audio-language models.arXiv preprint arXiv:2408.01337. Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Tay- lor Berg-Kirkpatrick, and Shlomo Dubnov. 2023. Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmen- tation. InIEEE International Conference on ...
-
[5]
InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 606–610
Text-to-audio grounding: Building correspon- dence between captions and sound events. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 606–610. IEEE. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others
-
[6]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Jiayu Yao, Shenghua Liu, Yiwei Wang, Rundong Cheng, Lingrui Mei, Baolong Bi, Zhen Xiong, and Xueqi Cheng. 2025. Not in sync: Unveiling temporal bias in audio chat models.arXiv preprint arXiv:2510.12185. A Appendix A.1 Overview This appendix provides additional details on bench- mark construction, mod...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.