Rethinking FID Through the Geometry of the Reference Dataset
Pith reviewed 2026-06-29 08:37 UTC · model grok-4.3
The pith
The geometry of the reference dataset determines whether FID scores improve with better generated samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
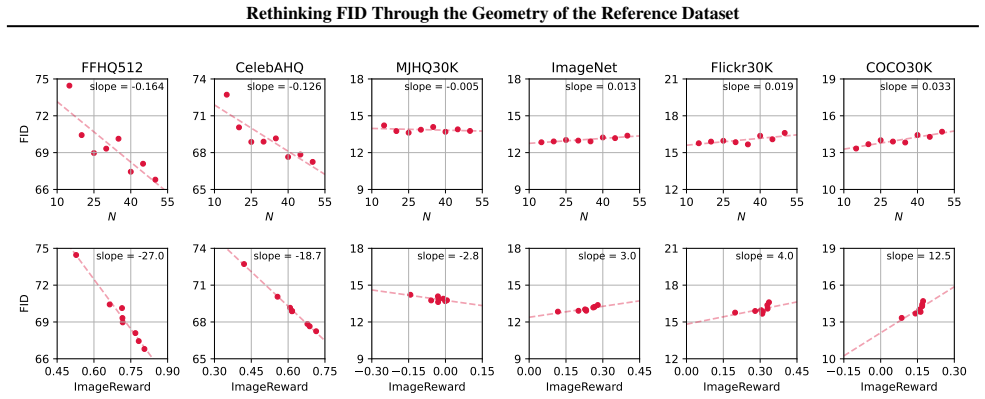
The paper establishes that the observed mismatch between FID and sample quality stems from the geometry of the reference dataset. Specifically, distributional density and effective rank of the reference data significantly predict how FID changes when sample quality is systematically improved. Concentrated reference distributions lead to more consistent FID reductions with quality gains, whereas dispersed ones can cause FID to rise despite quality improvements. This pattern holds across multiple datasets and is corroborated by precision-recall decompositions and ablations on alternative embeddings and metrics.
What carries the argument
The geometry of the reference dataset, captured through its distributional density and effective rank, which governs the sensitivity of FID to sample quality improvements.
If this is right
- Improving sample quality on concentrated reference datasets consistently lowers FID.
- On dispersed reference datasets, FID can worsen as samples improve.
- Precision and recall metrics show attribution consistent with the geometry effect.
- The conclusion is robust to changes in feature space and distance measure.
- Benchmarking practices should account for reference dataset geometry when using FID.
Where Pith is reading between the lines
- Evaluators might need to select or adjust reference datasets based on their density to avoid misleading FID results.
- The geometry dependence could extend to other Fréchet-based or distributional metrics in generative modeling.
- This highlights a general issue in using fixed references for comparing generative models across different domains.
Load-bearing premise
The controlled experiments isolate reference dataset geometry as the cause of FID mismatches without interference from how quality is improved or which feature extractor is used.
What would settle it
A new controlled experiment on six or more datasets where the correlation between reference density, effective rank, and FID trend direction is statistically insignificant would falsify the explanatory power of geometry.
Figures

read the original abstract
Fr\'echet Inception Distance (FID) is widely used to evaluate image generators, yet lower FID does not always correspond to better sample quality. We show that this mismatch depends in part on the geometry of the reference dataset. In a controlled study across six datasets, distributional density and effective rank significantly explain how FID changes as sample quality improves. Concentrated datasets tend to yield more favorable FID trends, whereas more dispersed datasets can make FID worsen despite better samples. Attribution to precision and recall and ablations with alternative feature spaces and distances support the same conclusion. These results suggest that distributional metrics should be interpreted together with the geometry of the reference dataset for more reliable benchmarking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that mismatches between FID and true sample quality improvements arise in part from the geometry of the reference dataset. In a controlled study across six datasets, distributional density and effective rank are shown to significantly explain FID trends as sample quality improves, with concentrated datasets producing more favorable trends and dispersed ones sometimes yielding worsening FID despite better samples. This is further supported by precision/recall attributions and ablations using alternative feature spaces and distances.
Significance. If substantiated by the empirical results, the finding would meaningfully affect benchmarking practices in generative modeling by requiring that FID scores be interpreted in light of reference dataset geometry rather than in isolation. The use of multiple datasets, ablations on feature extractors, and attribution to precision/recall constitutes a strength of the work.
major comments (2)
- [Abstract] Abstract and controlled-study description: the claim that the study isolates reference geometry requires explicit specification of the sample-quality improvement mechanism (progressive generator training, controlled perturbation in pixel/feature space, or other proxy). Without this, it remains possible that the improvement procedure itself correlates with density or rank, so the explanatory power attributed to geometry is not isolated.
- [Results (controlled study)] Results on distributional density and effective rank: the statement that these quantities 'significantly explain' FID changes must be backed by concrete statistical evidence (regression coefficients, R² values, p-values, or cross-validation metrics) rather than qualitative description; the abstract alone does not allow verification of the strength of this relationship.
minor comments (1)
- Provide a table listing the six datasets together with their measured density and effective-rank values to make the geometry characterization reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our controlled study. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract and controlled-study description: the claim that the study isolates reference geometry requires explicit specification of the sample-quality improvement mechanism (progressive generator training, controlled perturbation in pixel/feature space, or other proxy). Without this, it remains possible that the improvement procedure itself correlates with density or rank, so the explanatory power attributed to geometry is not isolated.
Authors: We agree that the abstract should explicitly name the sample-quality improvement mechanism to substantiate the isolation of reference geometry. The full manuscript (Section 3) describes the mechanism as progressive generator training with checkpoints at regular intervals on each of the six datasets. We will revise the abstract to include a concise statement of this mechanism, ensuring readers can evaluate potential correlations with density or rank. revision: yes
-
Referee: [Results (controlled study)] Results on distributional density and effective rank: the statement that these quantities 'significantly explain' FID changes must be backed by concrete statistical evidence (regression coefficients, R² values, p-values, or cross-validation metrics) rather than qualitative description; the abstract alone does not allow verification of the strength of this relationship.
Authors: The results section of the manuscript already reports regression analyses with R² values, coefficients, and p-values demonstrating the explanatory power of density and effective rank. However, the abstract's phrasing does not reference these metrics. We will revise the abstract to briefly note the statistical support (e.g., average R² and significance levels) while directing readers to the detailed regressions in the main text. revision: yes
Circularity Check
No circularity; empirical claims rest on controlled multi-dataset observations without reduction to fitted inputs or self-citations
full rationale
The paper presents an empirical controlled study across six datasets showing that reference dataset density and effective rank correlate with FID trends under improving sample quality. No equations, derivations, or predictions are defined in terms of themselves; no fitted parameters are relabeled as independent predictions; no load-bearing uniqueness theorems or ansatzes are imported via self-citation. The central attribution to geometry is supported by direct measurements and ablations rather than by construction from the paper's own inputs. This matches the default case of a self-contained empirical analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption FID is computed from features extracted by a fixed Inception network in a standard way
Reference graph
Works this paper leans on
-
[1]
Bi´nkowski, M., Sutherland, D. J., Arbel, M., and Gret- ton, A. Demystifying mmd gans.arXiv preprint arXiv:1801.01401,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Choi, J., Kang, J., and Han, B. Enhanced diffusion sam- pling via extrapolation with multiple ode solutions.arXiv preprint arXiv:2504.01855,
-
[3]
arXiv preprint arXiv:2107.07002 , year=
Dehghani, M., Tay, Y ., Gritsenko, A. A., Zhao, Z., Houlsby, N., Diaz, F., Metzler, D., and Vinyals, O. The benchmark lottery.arXiv preprint arXiv:2107.07002,
-
[4]
Progressive Growing of GANs for Improved Quality, Stability, and Variation
Karras, T., Aila, T., Laine, S., and Lehtinen, J. Progres- sive growing of gans for improved quality, stability, and variation.arXiv preprint arXiv:1710.10196,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
The role of imagenet classes in fr´echet incep- tion distance.arXiv preprint arXiv:2203.06026,
Kynk¨a¨anniemi, T., Karras, T., Aittala, M., Aila, T., and Lehtinen, J. The role of imagenet classes in fr´echet incep- tion distance.arXiv preprint arXiv:2203.06026,
-
[6]
Lee, Y ., Pak, B., Hong, J., and Kim, H. Tortoise and hare guidance: Accelerating diffusion model inference with multirate integration.arXiv preprint arXiv:2511.04117,
-
[7]
V ., Jernite, Y ., Thakur, A., V on Platen, P., Patil, S., Chaumond, J., Drame, M., Plu, J., Tunstall, L., et al
5 Rethinking FID Through the Geometry of the Reference Dataset Lhoest, Q., Del Moral, A. V ., Jernite, Y ., Thakur, A., V on Platen, P., Patil, S., Chaumond, J., Drame, M., Plu, J., Tunstall, L., et al. Datasets: A community library for natural language processing. InProceedings of the 2021 conference on empirical methods in natural language processing: s...
2021
-
[8]
Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation
Li, D., Kamko, A., Akhgari, E., Sabet, A., Xu, L., and Doshi, S. Playground v2. 5: Three insights towards enhancing aesthetic quality in text-to-image generation. arXiv preprint arXiv:2402.17245,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., V o, H., Szafraniec, M., Khalidov, V ., Fernandez, P., Haziza, D., Massa, F., El- Nouby, A., et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., and Chen, M. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Denoising Diffusion Implicit Models
Song, J., Meng, C., and Ermon, S. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[12]
6 Rethinking FID Through the Geometry of the Reference Dataset Table 5.Details of datasets used for experiments. Dataset Image count Caption source HuggingFace identifier FFHQ 70,000 Auto-generatedRyan-sjtu/ffhq512-caption CelebA-HQ 29,987 Auto-generatedoftverse/control-celeba-hq MJHQ-30K 30,000 Midjourney promptsxingjianleng/mjhq30k ImageNet 50,000 Class...
2014
-
[13]
We report the test statisticDand the correspondingp-value
is known to follow a 50:50 mixture ofχ 2 1 andχ 2 2 distributions underH 0 (Stram & Lee, 1994). We report the test statisticDand the correspondingp-value. Moderation Test.We use a similar model to find out if a geometric descriptor covariate Z moderates the relationship betweenXandY. LetZ j be the value ofZfor datasetj. We fit the model Yij =β 0j +β 1jXij...
1994
-
[14]
on the null hypothesis γ11 = 0 and report the corresponding p-value. Also we summarize the magnitude of moderation by the proportion of varianceτ 11 explained by introducingZ(Raudenbush & Bryk, 2002), R2 slope = 1−τ (mod) 11 /τ (omn) 11 .(12) 7 Rethinking FID Through the Geometry of the Reference Dataset C. Theoretical Analysis on a Toy Model In this sect...
2002
-
[15]
However, the six reference datasets span markedly different domains, from single-domain face images to open-domain natural scenes
to isolate the effect of the reference dataset. However, the six reference datasets span markedly different domains, from single-domain face images to open-domain natural scenes. As a result, the generator may fit these domains to different degrees, and such variation could in principle act as an unmeasured covariate alongside dataset geometry. Because we...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.