On the Road to Personalized Code Intelligence: Portraiting and Assisting Developers Based on Their In-IDE Behaviors
Pith reviewed 2026-06-29 06:52 UTC · model grok-4.3
The pith
VirtualME extracts in-IDE behaviors to build four-dimensional developer personas that improve personalized code Q&A answers by 33.8 percent on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
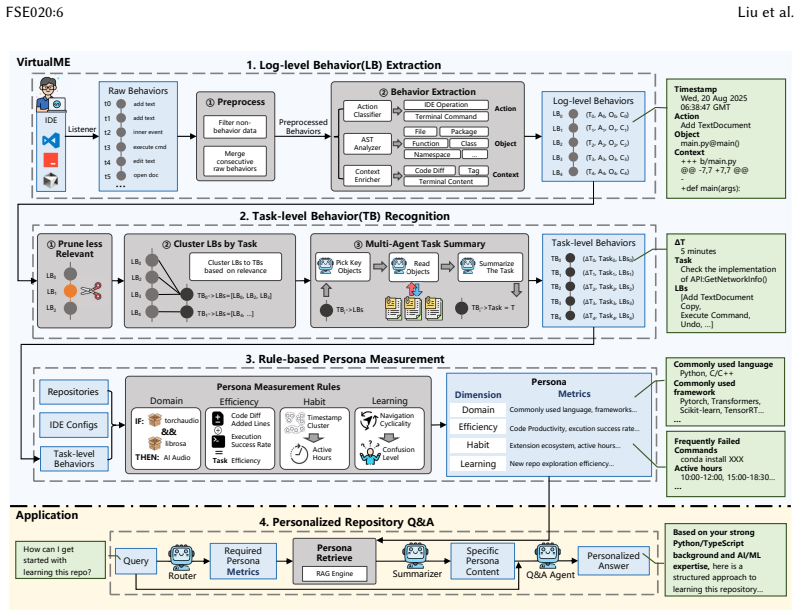
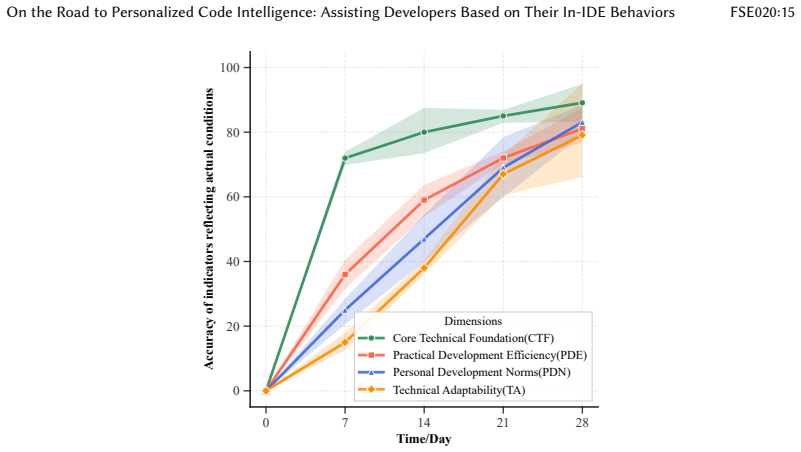
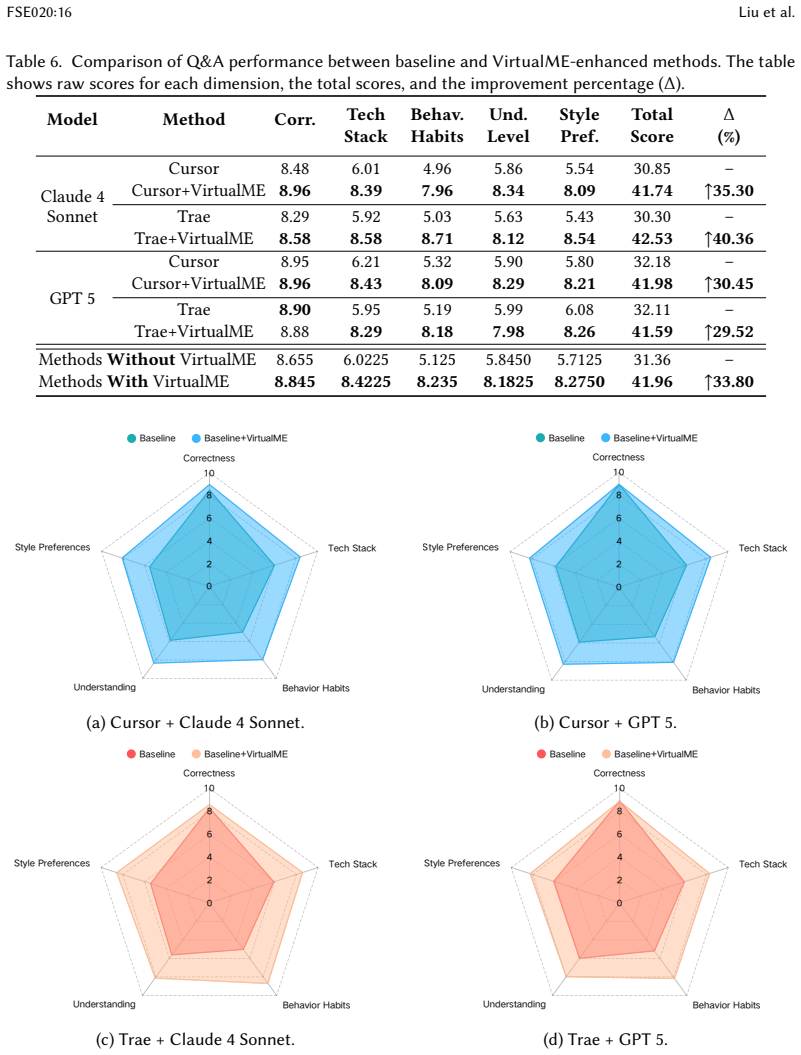
VirtualME is an IDE-embedded data infrastructure with three components: log-level behavior extraction from IDE logs, task-level behavior recognition that aggregates logs via a multi-agent pipeline, and developer-personality measurement that uses a rule engine to produce a four-dimensional persona covering technology stack, ability, behavioral habits, and learning style. When the persona is injected into a Q&A agent for repository-level knowledge questions, the resulting answers outperform generic baselines on five dimensions by an average 33.80 percent improvement, as shown on a multi-repository benchmark constructed from real-world developer trajectories.
What carries the argument
VirtualME, the three-component IDE infrastructure that extracts log-level behaviors, aggregates them to task level with a multi-agent pipeline, and distills four-dimensional personas (technology stack, ability, behavioral habits, learning style) via a rule engine for use in personalized agents.
If this is right
- Repository-level Q&A agents can incorporate developer personas to raise answer quality across multiple evaluation dimensions.
- Continuous capture of in-IDE actions supplies the raw data needed for adaptive rather than one-size-fits-all code tools.
- The pipeline balances correctness and personalization when evaluated on real developer trajectories.
- Four-dimensional personas distilled from behavior logs can be reused as input to other assistance systems.
Where Pith is reading between the lines
- If the personas remain stable over time, they could extend to tasks such as personalized code completion or refactoring suggestions.
- The multi-agent aggregation method might be applied to other development environments to test cross-IDE consistency of task recognition.
- Longitudinal collection of the same developer's data could reveal how personas shift with experience or project changes.
Load-bearing premise
The multi-agent pipeline and rule engine produce task-level behaviors and personas that genuinely reflect stable, actionable developer differences rather than artifacts of the logging or aggregation process.
What would settle it
A test in which the same developer repeats identical tasks and the extracted personas change substantially, or in which Q&A performance shows no gain when correct personas are replaced by randomly assigned ones in the evaluation.
Figures
read the original abstract
With the advent of large language models, research in automated software engineering has increasingly focused on leveraging these models to achieve a deeper semantic understanding of code or to engineer sophisticated agent-based processes. However, this research trajectory has largely overlooked a critical factor: the developers themselves. Programming is a deeply individualized activity; developers exhibit significant variation in their tool-chain preferences, domain-specific expertise, and problem-solving strategies. Consequently, the current paradigm of one-size-fits-all code intelligence systems struggles to accommodate the needs of individual developers. To address this gap, we introduce VirtualME, a novel IDE-embedded data infrastructure designed to model the developer by continuously capturing and interpreting their dynamic programming behaviors and preferences. VirtualME contains three components. (1) Log-level Behavior Extraction: it captures and extracts developers' log-level behaviors from IDE. (2) Task-level Behavior Recognition: it aggregates log-level behaviors into task-level behaviors via a multi-agent pipeline. (3) Developer-personality Measurement: it builds a rule engine to distill a four-dimensional developer persona: technology stack, ability, behavioral habits, and learning style. On top of VirtualME, we propose a solution for personalized repository-level knowledge Q&A by integrating the developer persona into the Q&A agent. We evaluated VirtualME by building a multi-repository benchmark with real-world developer trajectories, balancing correctness and personalization. Experimental results show that VirtualME-enhanced answers outperform generic baselines on five dimensions, yielding an average 33.80% improvement. Our results demonstrate that abundant, continuous developer-behavior data can pave the new way for adaptive and personalized code intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VirtualME, an IDE-embedded infrastructure with three components—log-level behavior extraction from IDE logs, multi-agent aggregation into task-level behaviors, and a rule engine producing a four-dimensional developer persona (technology stack, ability, behavioral habits, learning style)—then integrates the persona into a Q&A agent for personalized repository-level answers. It reports building a multi-repository benchmark from real developer trajectories and an average 33.80% improvement over generic baselines across five dimensions.
Significance. If the personas prove stable and the improvement is robust to benchmark construction and confounds, the work could open a path toward adaptive code intelligence that exploits continuous in-IDE behavioral data rather than one-size-fits-all models.
major comments (3)
- [Evaluation] Evaluation section: the abstract states a 33.80% average improvement but supplies no information on benchmark construction, baseline definitions, statistical tests, or potential confounds, so the data cannot be assessed against the claim.
- [Developer-personality Measurement] Developer-personality Measurement component: the four-dimensional persona is obtained solely via multi-agent aggregation and a deterministic rule engine; no human-subject check (self-rating, expert labeling, or test-retest stability) is reported to confirm the resulting persona vectors are reproducible across sessions or predictive of actual developer preferences rather than sensitive to logging granularity or rule thresholds.
- [Personalized repository-level knowledge Q&A] Personalized Q&A solution: the headline improvement is produced by feeding the persona into the Q&A agent, yet without independent validation that the personas capture stable traits, the measured gain could be an artifact of benchmark construction rather than evidence for the claimed personalization mechanism.
minor comments (2)
- [Abstract] The acronym 'VirtualME' is introduced without expansion or etymology.
- [Evaluation] The claim of 'balancing correctness and personalization' in the benchmark is stated without describing the balancing procedure or metrics used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in evaluation and validation. We will revise the manuscript to address each point by expanding details, adding a limitations discussion, and including threats-to-validity analysis. All changes will be made without overstating current evidence.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the abstract states a 33.80% average improvement but supplies no information on benchmark construction, baseline definitions, statistical tests, or potential confounds, so the data cannot be assessed against the claim.
Authors: We will revise the Evaluation section (and update the abstract if space permits) to provide explicit details on benchmark construction from real developer trajectories across multiple repositories, precise definitions of the generic baselines, the statistical tests performed, and an analysis of potential confounds such as trajectory selection bias. The full paper already describes the benchmark at a high level; the revision will make all methodological elements fully reproducible and assessable. revision: yes
-
Referee: [Developer-personality Measurement] Developer-personality Measurement component: the four-dimensional persona is obtained solely via multi-agent aggregation and a deterministic rule engine; no human-subject check (self-rating, expert labeling, or test-retest stability) is reported to confirm the resulting persona vectors are reproducible across sessions or predictive of actual developer preferences rather than sensitive to logging granularity or rule thresholds.
Authors: We agree this is a limitation of the present study. The current design prioritizes deterministic, reproducible extraction from IDE logs via the rule engine. In the revision we will add a dedicated Limitations subsection that explicitly notes the absence of direct human-subject validation (self-ratings, expert labeling, or test-retest) and states plans for future studies. We will also report any available sensitivity analyses on logging granularity and rule thresholds that can be performed on the existing trajectories. revision: yes
-
Referee: [Personalized repository-level knowledge Q&A] Personalized Q&A solution: the headline improvement is produced by feeding the persona into the Q&A agent, yet without independent validation that the personas capture stable traits, the measured gain could be an artifact of benchmark construction rather than evidence for the claimed personalization mechanism.
Authors: The benchmark was deliberately built from real developer trajectories and balanced for both correctness and personalization dimensions. Nevertheless, we acknowledge that stronger evidence of persona stability would strengthen causal claims about the personalization mechanism. The revision will add a Threats to Validity section that discusses benchmark-construction artifacts, includes sensitivity checks on persona inputs, and clarifies the extent to which performance gains can be attributed to the persona versus other factors. revision: yes
Circularity Check
No circularity; system description and benchmark evaluation are independent
full rationale
The paper describes an empirical system (VirtualME) with three components for behavior logging, multi-agent aggregation into tasks, and rule-engine persona construction, followed by integration into a Q&A agent and evaluation on a multi-repository benchmark built from real-world trajectories. No equations, fitted parameters, predictions, or derivations appear in the provided text. The 33.80% improvement is reported as a measured outcome against generic baselines on five dimensions, not a quantity defined by or forced from the persona rules themselves. No self-citations, uniqueness theorems, or ansatzes are invoked. The evaluation benchmark supplies external content against which the personalization mechanism is tested, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption In-IDE logs faithfully capture the behaviors and preferences that determine effective personalization.
invented entities (2)
-
VirtualME
no independent evidence
-
four-dimensional developer persona
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Technical Report
2014.SWECOM: Software Engineering Competency Model, Version 1.0. Technical Report. IEEE Computer Society, Los Alamitos, CA. https://ieeecs-media.computer.org/media/education/swebok/swecom.pdf Accessed: 2025-09-10
2014
-
[2]
Silvia Abrahão, John Grundy, Mauro Pezzè, Margaret-Anne Storey, and Damian A Tamburri. 2025. Software Engineering by and for Humans in an AI Era.ACM Transactions on Software Engineering and Methodology34, 5 (2025), 1–46
2025
-
[3]
Sven Amann, Sebastian Proksch, and Sarah Nadi. 2016. FeedBaG: An interaction tracker for Visual Studio. In2016 IEEE 24th International Conference on Program Comprehension (ICPC). 1–3. doi:10.1109/ICPC.2016.7503741
-
[4]
2025.Claude 4 Technical Report
Anthropic. 2025.Claude 4 Technical Report. Technical Report. Anthropic. https://www.arxiv.org/pdf/2505.09791 arXiv:2505.09791
-
[5]
Anthropic. 2025. Introducing Claude 4. https://www.anthropic.com/news/claude-4. Accessed: 2025-09-12
2025
-
[6]
Cursor — Anysphere. 2025. Cursor (v1.5.11). https://cursor.com/. Version 1.5.11; features include AST traversal and documentation consultation for knowledge-based Q&A in large codebases
2025
-
[7]
Islem Bouzenia and Michael Pradel. 2025. You name it, I run it: An LLM agent to execute tests of arbitrary projects. Proceedings of the ACM on Software Engineering2, ISSTA (2025), 1054–1076
2025
-
[8]
Jialiang Chen, Kaifa Zhao, Jie Liu, Chao Peng, Jierui Liu, Hang Zhu, Pengfei Gao, Ping Yang, and Shuiguang Deng
- [9]
-
[10]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Xiangping Chen, Xing Hu, Yuan Huang, He Jiang, Weixing Ji, Yanjie Jiang, Yanyan Jiang, Bo Liu, Hui Liu, Xiaochen Li, et al. 2025. Deep learning-based software engineering: progress, challenges, and opportunities.Science China Information Sciences68, 1 (2025), 111102
2025
-
[12]
Agnieszka Ciborowska and Kostadin Damevski. 2020. Recognizing developer activity based on joint modeling of code and command interactions.IEEE Access8 (2020), 211653–211664
2020
-
[13]
da Silva, and Luiz Fernando Capretz
Shirley Cruz, Fabio Q.B. da Silva, and Luiz Fernando Capretz. 2015. Forty years of research on personality in software engineering: A mapping study.Computers in Human Behavior46 (2015), 94–113. doi:10.1016/j.chb.2014.12.008
-
[14]
Kostadin Damevski, David C Shepherd, Johannes Schneider, and Lori Pollock. 2016. Mining sequences of developer interactions in visual studio for usage smells.IEEE Transactions on Software Engineering43, 4 (2016), 359–371
2016
-
[15]
Benedito De Oliveira and Fernando Castor. 2024. AthenaLLM: Supporting Experiments with Large Language Models in Software Development. In2024 IEEE/ACM 32nd International Conference on Program Comprehension (ICPC). 69–73
2024
-
[16]
Fatima Abu Deeb, Antonella DiLillo, and Timothy J Hickey. 2018. Using Fine Grained Programming Error Data to Enhance CS1 Pedagogy.. InCSEDU (1). 28–37
2018
-
[17]
Giuseppe Desolda, Andrea Esposito, Francesco Greco, Cesare Tucci, Paolo Buono, and Antonio Piccinno. 2025. Un- derstanding user mental models in AI-driven code completion tools: Insights from an elicitation study.International Journal of Human-Computer Studies205 (2025), 103648. doi:10.1016/j.ijhcs.2025.103648
- [18]
-
[19]
Martin Ester, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu. 1996. Density-based spatial clustering of applications with noise. InInt. Conf. knowledge discovery and data mining, Vol. 240
1996
-
[20]
Shabnam FakhrHosseini, Kathryn Chan, Chaiwoo Lee, Myounghoon Jeon, Heesuk Son, John Rudnik, and Joseph Coughlin. 2024. User adoption of intelligent environments: A review of technology adoption models, challenges, and prospects.International Journal of Human–Computer Interaction40, 4 (2024), 986–998
2024
-
[21]
Angela Fan, Beliz Gokkaya, Mark Harman, Mitya Lyubarskiy, Shubho Sengupta, Shin Yoo, and Jie M Zhang. 2023. Large language models for software engineering: Survey and open problems. In2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE). IEEE, 31–53
2023
-
[22]
Nicole Forsgren, Margaret-Anne Storey, Chandra Maddila, Thomas Zimmermann, Brian Houck, and Jenna Butler. 2021. The SPACE of Developer Productivity: There’s more to it than you think.Queue19, 1 (2021), 20–48
2021
- [23]
-
[24]
Hao Guan, Guangdong Bai, and Yepang Liu. 2025. CrossProbe: LLM-Empowered Cross-Project Bug Detection for Deep Learning Frameworks.Proceedings of the ACM on Software Engineering2, ISSTA (2025), 2430–2452
2025
-
[25]
Junda He, Christoph Treude, and David Lo. 2025. LLM-Based Multi-Agent Systems for Software Engineering: Literature Review, Vision, and the Road Ahead.ACM Transactions on Software Engineering and Methodology34, 5 (2025), 1–30
2025
-
[26]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large language models for software engineering: A systematic literature review.ACM Transactions on Software Engineering and Methodology33, 8 (2024), 1–79
2024
-
[27]
2005.PSP: A Self-Improvement Process for Software Engineers
Watts S Humphrey. 2005.PSP: A Self-Improvement Process for Software Engineers. Addison-Wesley Professional. https://www.sei.cmu.edu/library/abstracts/books/0321305493.cfm Accessed: 2025-09-10
-
[28]
Constantina Ioannou, Andrea Burattin, and Barbara Weber. 2018. Mining developers’ workflows from IDE usage. In International Conference on Advanced Information Systems Engineering. Springer, 167–179
2018
-
[29]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Miikka Kuutila, Mika Mäntylä, Maëlick Claes, Marko Elovainio, and Bram Adams. 2021. Individual differences limit predicting well-being and productivity using software repositories: a longitudinal industrial study.Empirical Software Engineering26, 5 (2021), 88
2021
-
[31]
Miikka Kuutila, Mika V Mäntylä, Maëlick Claes, Marko Elovainio, and Bram Adams. 2018. Using experience sampling to link software repositories with emotions and work well-being. InProceedings of the 12th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement. 1–10
2018
-
[32]
Xinyu Li, Ruiyang Zhou, Zachary C. Lipton, and Liu Leqi. 2024. Personalized Language Modeling from Personalized Human Feedback. arXiv:2402.05133 [cs.CL] https://arxiv.org/abs/2402.05133
-
[33]
Jie Liu, Guohua Wang, Ronghui Yang, Jiajie Zeng, Mengchen Zhao, and Yi Cai. 2025. RTADev: Intention Aligned Multi-Agent Framework for Software Development. InFindings of the Association for Computational Linguistics: ACL
2025
-
[34]
Yiwei Lyu, Paul Pu Liang, Hai Pham, Eduard Hovy, Barnabás Póczos, Ruslan Salakhutdinov, and Louis-Philippe Morency
-
[35]
StylePTB: A Compositional Benchmark for Fine-grained Controllable Text Style Transfer. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tur, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy ...
- [36]
-
[37]
Walid Maalej, Mathias Ellmann, and Romain Robbes. 2017. Using contexts similarity to predict relationships between tasks.Journal of Systems and Software128 (2017), 267–284
2017
-
[38]
Georgios Makridis, Georgios Fragiadakis, Jorge Oliveira, Tomaz Saraiva, Philip Mavrepis, Georgios Fatouros, and Dimosthenis Kyriazis. 2025. HumAIne-Chatbot: Real-Time Personalized Conversational AI via Reinforcement Learning. arXiv:2509.04303 [cs.HC] https://arxiv.org/abs/2509.04303
-
[39]
Noble Saji Mathews and Meiyappan Nagappan. 2024. Test-driven development and llm-based code generation. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 1583–1594
2024
- [40]
-
[41]
Fangwen Mu, Lin Shi, Song Wang, Zhuohao Yu, Binquan Zhang, ChenXue Wang, Shichao Liu, and Qing Wang. 2024. Clarifygpt: A framework for enhancing llm-based code generation via requirements clarification.Proceedings of the ACM on Software Engineering1, FSE (2024), 2332–2354
2024
-
[42]
Daye Nam, Andrew Macvean, Vincent Hellendoorn, Bogdan Vasilescu, and Brad Myers. 2024. Using an llm to help with code understanding. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–13
2024
-
[43]
Abi Noda, Margaret-Anne Storey, Nicole Forsgren, and Michaela Greiler. 2023. DevEX: What actually drives productiv- ity?Commun. ACM66, 11 (2023), 44–49
2023
-
[44]
OpenAI. 2025. GPT-5. https://openai.com/. Large language model released by OpenAI, used for advanced code understanding and personalized software engineering tasks
2025
-
[45]
Sebastian Proksch, Sven Amann, and Sarah Nadi. 2018. Enriched event streams: a general dataset for empirical studies on in-IDE activities of software developers. InProceedings of the 15th International Conference on Mining Software Repositories. 62–65
2018
-
[46]
Asif Rahman, Veljko Cvetkovic, Kathleen Reece, Aidan Walters, Yasir Hassan, Aneesh Tummeti, Bryan Torres, Denise Cooney, Margaret Ellis, and Dimitrios S Nikolopoulos. 2025. Marco: A multi-agent system for optimizing hpc code generation using large language models.arXiv preprint arXiv:2505.03906(2025). Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE020...
-
[47]
Krishna Ronanki. 2025. Facilitating Trustworthy Human-Agent Collaboration in LLM-based Multi-Agent System oriented Software Engineering. InProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering. 1333–1337
2025
-
[48]
Zoltán Ságodi, Gábor Antal, Bence Bogenfürst, Martin Isztin, Péter Hegedűs, and Rudolf Ferenc. 2024. Reality check: Assessing GPT-4 in fixing real-world software vulnerabilities. InProceedings of the 28th International Conference on Evaluation and Assessment in Software Engineering. 252–261
2024
-
[49]
Alexander Scarlatos, Ryan S. Baker, and Andrew Lan. 2025. Exploring Knowledge Tracing in Tutor-Student Dialogues using LLMs. InProceedings of the 15th International Learning Analytics and Knowledge Conference (LAK 2025). ACM, 249–259. doi:10.1145/3706468.3706501
-
[50]
Matthias Schmidmaier, Zhiwei Han, Thomas Weber, Yuanting Liu, and Heinrich Hußmann. 2019. Real-time personal- ization in adaptive IDEs. InAdjunct Publication of the 27th Conference on User Modeling, Adaptation and Personalization. 81–86
2019
-
[51]
Martin Schröer and Rainer Koschke. 2021. Recording, Visualising and Understanding Developer Programming Behaviour. In2021 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). 561–566. doi:10.1109/SANER50967.2021.00066
-
[52]
Agnia Sergeyuk, Yaroslav Golubev, Timofey Bryksin, and Iftekhar Ahmed. 2025. Using AI-based coding assistants in practice: State of affairs, perceptions, and ways forward.Information and Software Technology178 (2025), 107610
2025
-
[53]
Kensen Shi, Deniz Altınbüken, Saswat Anand, Mihai Christodorescu, Katja Grünwedel, Alexa Koenings, Sai Naidu, Anurag Pathak, Marc Rasi, Fredde Ribeiro, et al. 2025. Natural language outlines for code: Literate programming in the llm era. InProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering. 150–161
2025
-
[54]
Phil Steinhorst, Andrew Petersen, and Jan Vahrenhold. 2020. Introductory Programming Self-Efficacy Scale (IPSES). https://csedresearch.org/wp-content/uploads/Instruments/Computing/PDF/IntroductoryProgrammingSelf- EfficacyScale.pdf Accessed: 2025-09-10
2020
-
[55]
Trae Team. 2025. Trae (v2.3.0). https://trae.com/. Version 2.3.0; AI-native IDE based on a VS Code fork, using workspace chat as industrial-grade reference for evaluating personalization
2025
- [56]
-
[57]
Junjie Wang, Yuchao Huang, Chunyang Chen, Zhe Liu, Song Wang, and Qing Wang. 2024. Software testing with large language models: Survey, landscape, and vision.IEEE Transactions on Software Engineering50, 4 (2024), 911–936
2024
- [58]
-
[59]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al . 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[60]
Di Wu, Fangwen Mu, Lin Shi, Zhaoqiang Guo, Kui Liu, Weiguang Zhuang, Yuqi Zhong, and Li Zhang. 2024. ismell: Assembling llms with expert toolsets for code smell detection and refactoring. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 1345–1357
2024
-
[61]
Guanqun Yang. 2025. Advancing Intelligent Software Development and Trustworthy Models Through the Synergy of Software Engineering and LLMs. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 29313–29314
2025
-
[62]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems37 (2024), 50528–50652
2024
-
[63]
Gonzalez, and Ion Stoica
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. InThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track. https://openreview...
2023
-
[64]
Clement, Neel Sundaresan, and Michele Tufano
Andrei Zlotchevski, Dawn Drain, Alexey Svyatkovskiy, Colin B. Clement, Neel Sundaresan, and Michele Tufano. 2022. Exploring and evaluating personalized models for code generation. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE ’22). ACM, 1500–1508. doi:10.1145...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.