Latent Terms: Dense Retrievers Contain Trivially Extractable BM25-ready Zipfian Vocabularies
Pith reviewed 2026-06-29 05:44 UTC · model grok-4.3
The pith
Dense retrievers contain sparse vocabularies that sparse autoencoders extract and make directly usable with standard BM25.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
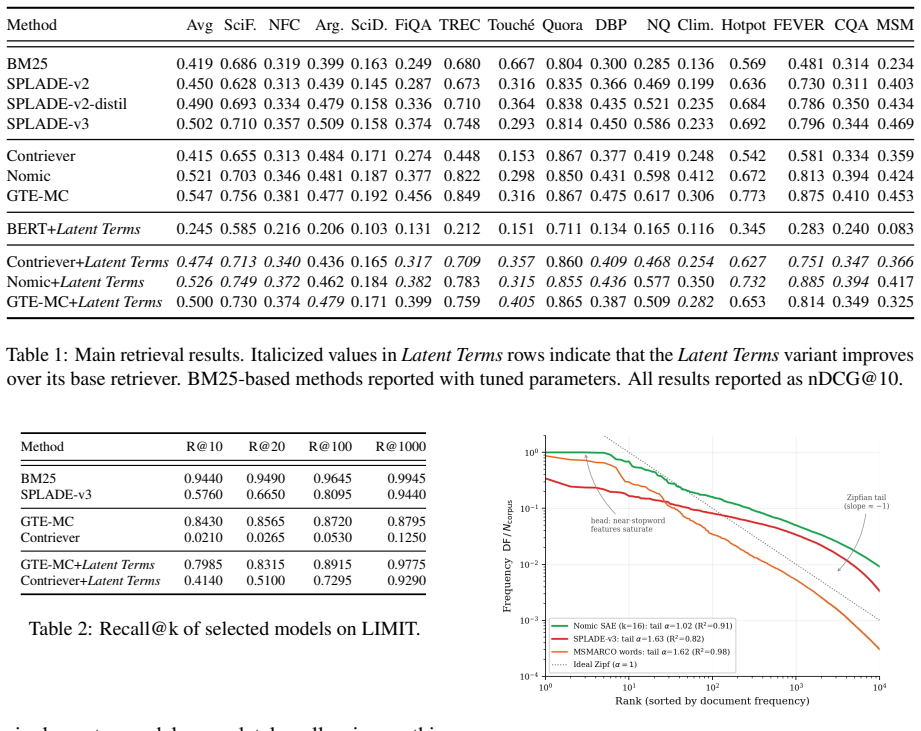
Models trained for dense retrieval learn representations that sparse autoencoders can decompose into retrieval-ready sparse features; when the autoencoders run on frozen retrievers with no retrieval adjustments, the extracted latents form a vocabulary whose collection statistics are approximately Zipfian and therefore directly compatible with unmodified BM25 scoring.
What carries the argument
Latent Terms: the sparse features recovered by sparse autoencoders from dense retriever activations, which exhibit Zipfian statistics and serve as a ready vocabulary for BM25.
If this is right
- Sparse retrieval becomes available from any dense retriever with zero sparse supervision or expansion training.
- The same procedure works on both single-vector and multi-vector dense models.
- Retrieval effectiveness on the LIMIT task exceeds the base dense model's single-vector scores.
- Performance matches or exceeds comparable SPLADE variants trained with explicit sparse objectives.
Where Pith is reading between the lines
- Hybrid retrieval systems could be constructed by extracting the sparse component from an existing dense model rather than training a separate sparse encoder.
- The Zipfian alignment may indicate that dense training implicitly captures term-frequency regularities that classical IR methods exploit explicitly.
- The approach could be tested on collections with different term distributions to check whether the extracted vocabularies remain BM25-compatible outside the original training domain.
Load-bearing premise
The autoencoder latents recovered from frozen dense retrievers are term-like enough and have collection statistics aligned enough to the corpus that they work in standard BM25 without post-processing or learned weights.
What would settle it
Apply the extracted latent terms to BM25 on a held-out collection such as MS MARCO and observe that effectiveness falls substantially below the original dense retriever's single-vector scores.
Figures

read the original abstract
We propose Latent Terms, a method revealing that models trained for dense retrieval, whether single- or multi-vector, learn representations that can trivially be decomposed into retrieval-ready sparse features. When trained on frozen retrievers, Sparse Autoencoders without any retrieval-specific adjustments extract a latent vocabulary with approximately Zipfian collection statistics, directly suitable for classical sparse retrieval scoring via BM25. This approach enables sparse retrieval while requiring no learned expansion objective or sparse retrieval supervision whatsoever, and can be readily applied to any dense retriever. Latent Terms is able to match or outperform single-vector scoring methods from its own base model as well as comparable SPLADE variants. In addition, it substantially outperforms its base model on LIMIT, a task specifically designed to highlight the failures of single-vector retrieval. Overall, our results highlight that neural retrievers contain more expressive and indexable structure than their default scoring functions expose, but that other methods can nonetheless be leveraged.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Sparse Autoencoders trained on frozen dense retrievers (single- or multi-vector) extract latent vocabularies exhibiting approximately Zipfian collection statistics. These latents are asserted to be directly suitable for unmodified BM25 scoring without retrieval-specific adjustments, learned expansion, or sparse supervision. The resulting sparse retriever matches or outperforms the base model's single-vector scoring and comparable SPLADE variants, while substantially outperforming the base model on the LIMIT benchmark designed to expose single-vector failures.
Significance. If the central empirical claims hold, the work is significant because it shows that dense retrievers internally encode sparse, term-like features with classical collection statistics that can be recovered via SAEs and used for sparse retrieval. This provides a training-free bridge between dense and sparse paradigms and demonstrates that existing dense models contain more indexable structure than their default scoring functions expose. The reported LIMIT gains are noteworthy as they target a documented weakness of dense methods.
major comments (1)
- [Abstract] Abstract: the claim that the SAE latents are 'directly suitable for classical sparse retrieval scoring via BM25' with 'no retrieval-specific adjustments' and 'without any retrieval-specific adjustments' is load-bearing but unsupported by an explicit mapping. Standard BM25 (Robertson-Sparck Jones) requires integer document term frequencies tf(d,t); SAE outputs are continuous real-valued activations. The manuscript provides no formula showing how raw activations are used as tf without thresholding, scaling, or selection, making it impossible to verify that the procedure is unmodified.
Simulated Author's Rebuttal
We thank the referee for their thorough review and for highlighting the need for greater clarity on the BM25 mapping. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the SAE latents are 'directly suitable for classical sparse retrieval scoring via BM25' with 'no retrieval-specific adjustments' and 'without any retrieval-specific adjustments' is load-bearing but unsupported by an explicit mapping. Standard BM25 (Robertson-Sparck Jones) requires integer document term frequencies tf(d,t); SAE outputs are continuous real-valued activations. The manuscript provides no formula showing how raw activations are used as tf without thresholding, scaling, or selection, making it impossible to verify that the procedure is unmodified.
Authors: We agree that an explicit mapping is required to substantiate the claim of using unmodified BM25. The current manuscript does not include a formula detailing the conversion from continuous SAE activations to tf values. In the revised version we will add this in the Methods section, specifying the exact procedure (including any thresholding or rounding to integer frequencies) so that readers can verify the inputs to the standard BM25 implementation. This addition will not alter the core claim that no retrieval-specific training or learned adjustments are involved. revision: yes
Circularity Check
No circularity: empirical extraction procedure with independent results
full rationale
The paper describes training SAEs on frozen dense retrievers and observing that the resulting latents exhibit Zipfian statistics and can be used for BM25-style scoring. No equations, derivations, or fitted parameters are presented that reduce the reported performance or the 'term-like' property to quantities defined inside the same experiment. No self-citations are invoked as load-bearing uniqueness theorems, and the method is framed as an extraction rather than a predictive model whose outputs are forced by construction. The central claims rest on empirical measurements against external baselines, which are falsifiable outside the fitted values.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Visual words meet bm25: Sparse auto-encoder visual word scoring for image retrieval.Preprint, arXiv:2603.05781. Ben He and Iadh Ounis. 2005. Term frequency normali- sation tuning for bm25 and dfr models. InAdvances in Information Retrieval, pages 200–214, Berlin, Hei- delberg. Springer Berlin Heidelberg. Tz-Huan Hsu, Jheng-Hong Yang, and Jimmy Lin. 2026. ...
-
[2]
Document expansion by query prediction.arXiv preprint arXiv:1904.08375,
MS MARCO: A human generated machine reading comprehension dataset.choice, 2640:660. Rodrigo Nogueira, Wei Yang, Jimmy Lin, and Kyunghyun Cho. 2019. Document expansion by query prediction.arXiv preprint arXiv:1904.08375. Zach Nussbaum, John Xavier Morris, Andriy Mul- yar, and Brandon Duderstadt. 2025. Nomic embed: Training a reproducible long context text ...
-
[3]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 26468–26485, Suzhou, China
Decoding dense embeddings: Sparse autoen- coders for interpreting and discretizing dense re- trieval. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 26468–26485, Suzhou, China. Association for Computational Linguistics. Guilherme Penedo, Hynek Kydlíˇcek, Loubna Ben Al- lal, Anton Lozhkov, Margaret Mitchell,...
2025
-
[4]
Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders
An alternative to flops regularization to ef- fectively productionize splade-doc. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’25, page 2789–2793, New York, NY , USA. Association for Computing Machinery. Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand...
work page internal anchor Pith review Pith/arXiv arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.