Towards Human-Like Interactive Speech Recognition With Agentic Correction and Semantic Evaluation
Pith reviewed 2026-06-29 07:28 UTC · model grok-4.3
The pith
An agentic closed-loop ASR system uses multi-turn semantic correction to reduce meaning errors beyond what single-pass or token metrics achieve.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
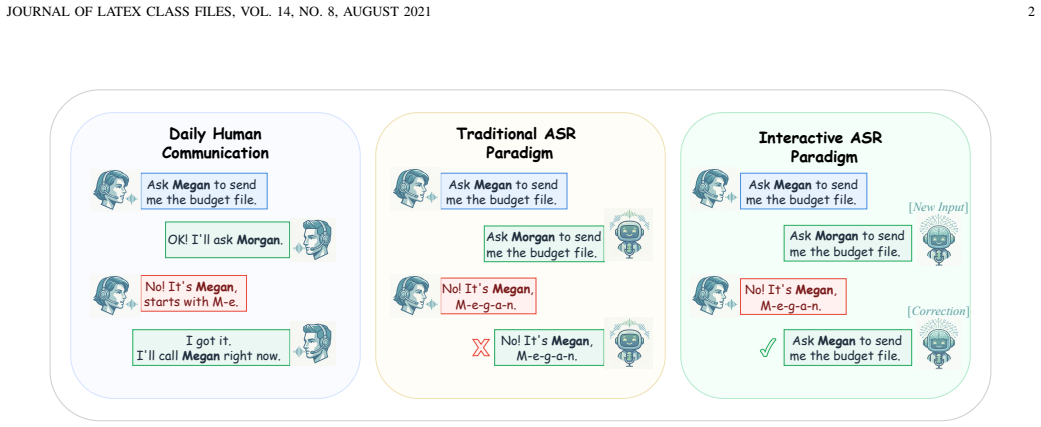
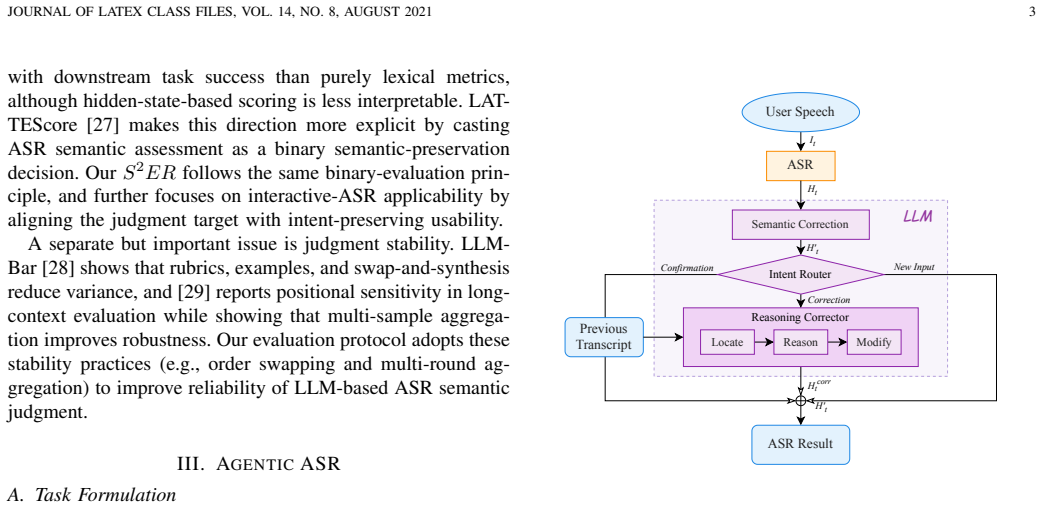
Formulating speech recognition as a multi-turn refinement task and equipping it with a closed-loop Agentic ASR framework that combines a single-pass front-end with semantic correction, intent routing, and reasoning-based editing produces consistent reductions in semantic errors; these gains are substantially larger when measured by the new LLM-based Sentence-level Semantic Error Rate than by conventional token-level metrics, and the semantic judge aligns with human judgments.
What carries the argument
Agentic ASR, a closed-loop framework that adds semantic correction, intent routing, and reasoning-based editing to a single-pass ASR front-end.
If this is right
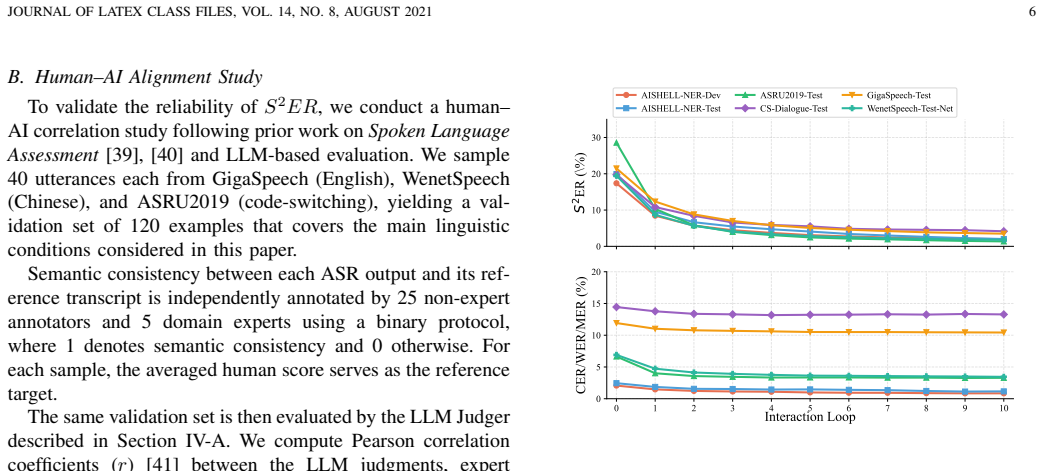
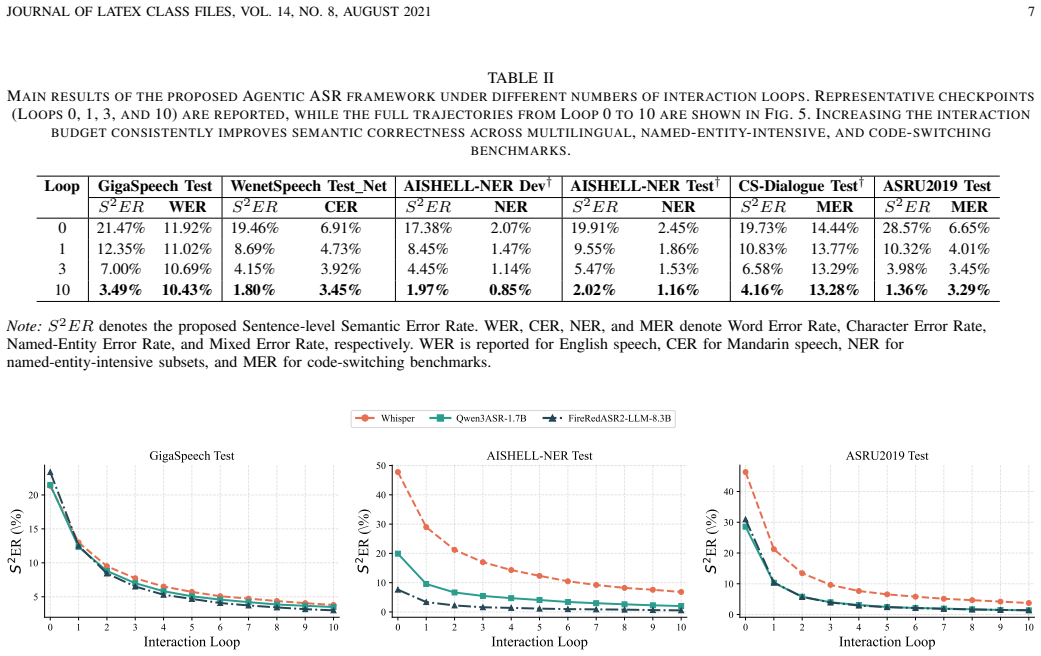
- Iterative interaction reduces semantic errors on multilingual, named-entity-intensive, and code-switching benchmarks.
- Improvements appear larger under S²ER than under token-level metrics such as WER or CER.
- Ablation studies confirm that each component of the agentic loop contributes to the observed error reduction.
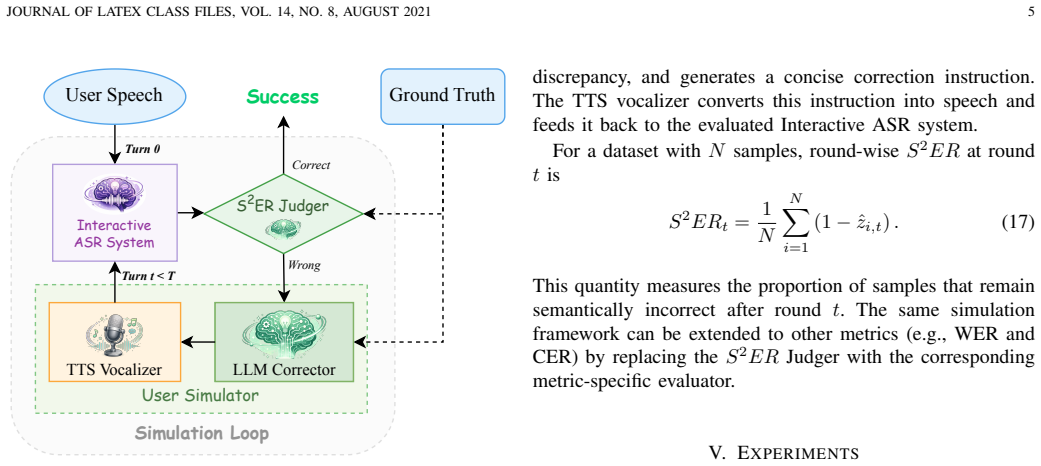
- The Interactive Simulation System enables reproducible benchmarking without repeated human annotation.
Where Pith is reading between the lines
- The same correction loop could be attached to other front-end recognizers such as handwriting or video captioning systems.
- Tighter coupling between the semantic judge and downstream LLM agents might allow the system to request clarification only on intent-critical errors.
- The simulation environment could be used to train lightweight correction policies that run without calling a full LLM at inference time.
Load-bearing premise
An LLM can judge whether two sentences convey the same intended meaning without introducing systematic bias or hallucination.
What would settle it
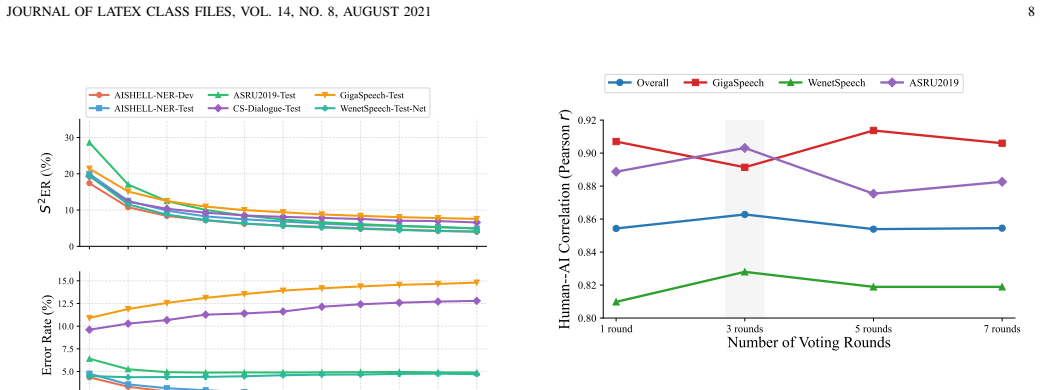
A controlled study in which human listeners rate pairs of transcripts for semantic fidelity and the rankings produced by S²ER disagree with the human rankings on a statistically significant fraction of cases.
Figures

read the original abstract
Automatic speech recognition (ASR) is a core component of human--computer interaction and an increasingly important front-end for LLM-based assistants and agents. However, most current ASR systems still follow a single-pass paradigm, which is poorly aligned with human communication, where misunderstandings are resolved through iterative clarification and refinement. This mismatch makes it difficult to correct meaning-critical errors once they occur. Meanwhile, token-level metrics such as WER or CER cannot adequately reflect such a problem. To address these limitations, we formulate \emph{Interactive ASR} as a multi-turn refinement task and propose \textbf{Agentic ASR}, a closed-loop framework that combines a single-pass ASR front-end with semantic correction, intent routing, and reasoning-based editing. We further introduce the \textbf{Sentence-level Semantic Error Rate} ($S^2ER$), an LLM-based semantic evaluation metric, together with an \textbf{Interactive Simulation System} for scalable and reproducible benchmarking. Experiments on multilingual, named-entity-intensive, and code-switching benchmarks show that iterative interaction consistently reduces semantic errors, with much larger gains in $S^2ER$ than in conventional token-level metrics. Human--AI alignment and ablation studies further validate the reliability of the semantic judge and the robustness of the proposed framework. The code is available at: https://interactiveasr.github.io/ and the live demo is available at https://i-asr.sjtuxlance.com/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce an Agentic ASR framework for interactive, multi-turn speech recognition that uses LLM-based semantic correction, intent routing, and reasoning-based editing to correct meaning-critical errors. It proposes the S²ER metric, an LLM-based sentence-level semantic error rate, and an Interactive Simulation System for benchmarking. Experiments on multilingual, named-entity-intensive, and code-switching benchmarks show that iterative interaction reduces semantic errors, with larger gains in S²ER than in WER or CER. Human-AI alignment and ablation studies are provided to validate the approach, and code is made available.
Significance. If the results hold, this approach could significantly advance ASR systems towards more human-like interactive paradigms, improving semantic accuracy in downstream LLM applications. The open-sourcing of code and the live demo are positive for reproducibility and further research. The introduction of a semantic metric addresses a known limitation of token-level metrics.
major comments (2)
- [S²ER Metric and Human-AI Alignment Studies] S²ER definition: the metric is defined via an LLM judge for semantic fidelity, yet the correction stage also relies on LLM semantic correction, intent routing, and reasoning-based editing. The manuscript must explicitly report whether the same model family and prompt style are used for both, along with judge-correction divergence rates and the precise setup of the human-AI alignment study (including model identity). This directly affects whether the larger S²ER gains reflect genuine semantic recovery or shared inductive bias.
- [Experiments] Experimental results: the abstract states 'consistent reductions' and 'much larger gains in S²ER' but supplies no numerical values, error bars, confidence intervals, or statistical tests. The full paper must include these quantities (with per-benchmark breakdowns) for the central claim that iterative interaction yields substantially larger semantic improvements than token-level metrics to be verifiable.
minor comments (2)
- Provide the exact prompts and model versions used for the LLM judge and correction agent in an appendix to support reproducibility.
- Clarify how the Interactive Simulation System generates multi-turn interactions and whether it introduces any distributional shift relative to real user corrections.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications and commitments to revisions that strengthen the presentation without altering the core contributions.
read point-by-point responses
-
Referee: [S²ER Metric and Human-AI Alignment Studies] S²ER definition: the metric is defined via an LLM judge for semantic fidelity, yet the correction stage also relies on LLM semantic correction, intent routing, and reasoning-based editing. The manuscript must explicitly report whether the same model family and prompt style are used for both, along with judge-correction divergence rates and the precise setup of the human-AI alignment study (including model identity). This directly affects whether the larger S²ER gains reflect genuine semantic recovery or shared inductive bias.
Authors: We agree that explicit reporting on model usage for the S²ER judge versus the correction components is necessary for transparency. The revised manuscript will add a dedicated subsection detailing the exact model families, prompt styles, and configurations employed in each stage. We will also report judge-correction divergence rates computed on a held-out validation set and expand the description of the human-AI alignment study to include all relevant setup details and model identities. These additions will enable readers to evaluate potential inductive bias concerns directly. revision: yes
-
Referee: [Experiments] Experimental results: the abstract states 'consistent reductions' and 'much larger gains in S²ER' but supplies no numerical values, error bars, confidence intervals, or statistical tests. The full paper must include these quantities (with per-benchmark breakdowns) for the central claim that iterative interaction yields substantially larger semantic improvements than token-level metrics to be verifiable.
Authors: The full manuscript already presents numerical results and per-benchmark breakdowns in the experiments section. To further improve verifiability as requested, the revised version will augment the results with error bars, confidence intervals, and statistical tests (such as paired significance tests) across all benchmarks. This will directly support the claim of larger semantic gains relative to token-level metrics. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines S²ER as an LLM-based metric and reports experimental reductions in it versus token-level metrics, with explicit mention of separate human-AI alignment and ablation studies to validate the judge. No equations, self-citations, or derivations reduce the central claims to fitted inputs, self-definitions, or author-prior ansatzes by construction. The framework's use of LLMs for both correction and evaluation is acknowledged but does not create a load-bearing circular step under the enumerated patterns, as the validation steps are presented as external checks. The derivation remains self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM can serve as a reliable proxy for human semantic judgment in error evaluation
invented entities (2)
-
Agentic ASR closed-loop framework
no independent evidence
-
S²ER metric
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Automatic recognition of spoken digits,
K. H. Davis, R. Biddulph, and S. Balashek, “Automatic recognition of spoken digits,”The Journal of the Acoustical Society of America, vol. 24, no. 6, pp. 637–642, 11 1952
1952
-
[2]
Slm: Bridge the thin gap between speech and text foundation models,
M. Wang, W. Han, I. Shafran, Z. Wu, C.-C. Chiu, Y . Cao, N. Chen, Y . Zhang, H. Soltau, P. K. Rubensteinet al., “Slm: Bridge the thin gap between speech and text foundation models,” in2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2023, pp. 1–8
2023
-
[3]
X. Shi, X. Wang, Z. Guo, Y . Wang, P. Zhang, X. Zhang, Z. Guo, H. Hao, Y . Xi, B. Yanget al., “Qwen3-asr technical report,”arXiv preprint arXiv:2601.21337, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Listen, attend and spell: A neural network for large vocabulary conversational speech recognition,
W. Chan, N. Jaitly, Q. Le, and O. Vinyals, “Listen, attend and spell: A neural network for large vocabulary conversational speech recognition,” in2016 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2016, pp. 4960–4964
2016
-
[5]
Robust speech recognition via large-scale weak supervi- sion,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervi- sion,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518
2023
-
[6]
Grounding in communication,
H. H. Clark and S. E. Brennan, “Grounding in communication,” in Perspectives on Socially Shared Cognition, L. B. Resnick, J. M. Levine, and S. D. Teasley, Eds. Washington, DC: American Psychological Association, 1991, pp. 127–149
1991
-
[7]
The preference for self- correction in the organization of repair in conversation,
E. A. Schegloff, G. Jefferson, and H. Sacks, “The preference for self- correction in the organization of repair in conversation,”Language, vol. 53, no. 2, pp. 361–382, 1977
1977
-
[8]
How to evaluate asr output for named entity recognition?
M. Jannet, O. Galibert, M. Adda-Decker, and S. Rosset, “How to evaluate asr output for named entity recognition?” inProc. Interspeech 2015, 09 2015, pp. 1289–1293
2015
-
[9]
Is word error rate a good indicator for spoken language understanding accuracy,
Y .-y. Wang, “Is word error rate a good indicator for spoken language understanding accuracy,” in2003 IEEE Workshop on Automatic Speech Recognition and Understanding (IEEE Cat. No.03EX721), 2003
2003
-
[10]
Jelinek,Statistical methods for speech recognition
F. Jelinek,Statistical methods for speech recognition. MIT Press, 1997
1997
-
[11]
Semantic-wer: A unified metric for the evaluation of asr transcript for end usability,
S. Roy, “Semantic-wer: A unified metric for the evaluation of asr transcript for end usability,”arXiv preprint arXiv:2106.02016, 2021
-
[12]
S. Kim, A. Arora, D. Le, C.-F. Yeh, C. Fuegen, O. Kalinli, and M. L. Seltzer, “Semantic distance: A new metric for asr perfor- mance analysis towards spoken language understanding,”arXiv preprint arXiv:2104.02138, 2021
-
[13]
Automatic estimation of word significance oriented for speech-based information retrieval,
T. Shichiri, H. Nanjo, and T. Yoshimi, “Automatic estimation of word significance oriented for speech-based information retrieval,” inProceed- ings of the Third International Joint Conference on Natural Language Processing: Volume-I, 2008
2008
-
[14]
Heval: A new hybrid evaluation metric for automatic speech recognition tasks,
Z. Sasindran, H. Yelchuri, T. V . Prabhakar, and S. Rao, “Heval: A new hybrid evaluation metric for automatic speech recognition tasks,” in 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2023, pp. 1–7
2023
-
[15]
BERTScore: Evaluating Text Generation with BERT
T. Zhang, V . Kishore, F. Wu, K. Q. Weinberger, and Y . Artzi, “Bertscore: Evaluating text generation with bert,”arXiv preprint arXiv:1904.09675, 2020
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[16]
Laser: An llm-based asr scoring and evaluation rubric,
A. Parulekar and P. Jyothi, “Laser: An llm-based asr scoring and evaluation rubric,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 24 773–24 782
2025
-
[17]
S. Pulikodan, S. K, P. K. Ghosh, V . Sanka, and N. Desai, “An approach to measuring the performance of automatic speech recognition (asr) models in the context of large language model (llm) powered applications,” arXiv preprint arXiv:2507.16456, 2025
-
[18]
Multimodal error correction for speech user interfaces,
B. Suhm, B. Myers, and A. Waibel, “Multimodal error correction for speech user interfaces,”ACM transactions on computer-human interaction (TOCHI), vol. 8, no. 1, pp. 60–98, 2001
2001
-
[19]
V oice typing: a new speech interaction model for dictation on touchscreen devices,
A. Kumar, T. Paek, and B. Lee, “V oice typing: a new speech interaction model for dictation on touchscreen devices,” inProceedings of the 30th ACM SIGCHI Conference on Human Factors in Computing Systems. ACM, 2012, pp. 2277–2286
2012
-
[20]
Ef- ficient speech transcription through respeaking
M. Sperber, G. Neubig, C. F ¨ugen, S. Nakamura, and A. Waibel, “Ef- ficient speech transcription through respeaking.” inInterspeech, 2013, pp. 1087–1091
2013
-
[21]
L. Zhou, Y . Ding, M. Chen, H. Zhang, R. Prabhavalkar, D. Guliani, G. Motta, and R. Mathews, “The gift of feedback: Improving asr model quality by learning from user corrections through federated learning,” arXiv preprint arXiv:2310.00141, 2023
-
[22]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” inThe eleventh international conference on learning representations, 2022
2022
-
[23]
Large language models are state-of-the- art evaluators of translation quality,
T. Kocmi and C. Federmann, “Large language models are state-of-the- art evaluators of translation quality,”arXiv preprint arXiv:2302.14520, 2023
-
[24]
Judging llm-as-a-judge with mt-bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xinget al., “Judging llm-as-a-judge with mt-bench and chatbot arena,”Advances in neural information processing systems, vol. 36, pp. 46 595–46 623, 2023
2023
-
[25]
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Y . Liu, D. Iter, Y . Xu, S. Wang, R. Xu, and C. Zhu, “G-eval: Nlg evaluation using gpt-4 with better human alignment,”arXiv preprint arXiv:2303.16634, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Evaluating speech recognition perfor- mance towards large language model based voice assistants,
Z. Liu, S. Kim, and O. Kalinli, “Evaluating speech recognition perfor- mance towards large language model based voice assistants,” inProc. Interspeech 2024, 2024
2024
-
[27]
Large language models as a proxy for human evaluation in assessing the comprehensibility of disordered speech transcription,
K. Tomanek, J. Tobin, S. Venugopalan, R. Cave, K. Seaver, J. R. Green, and R. Heywood, “Large language models as a proxy for human evaluation in assessing the comprehensibility of disordered speech transcription,” inICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 10 846– 10 850
2024
-
[28]
Evaluat- ing large language models at evaluating instruction following,
Z. Zeng, J. Yu, T. Gao, Y . Meng, T. Goyal, and D. Chen, “Evaluat- ing large language models at evaluating instruction following,”arXiv preprint arXiv:2310.07641, 2024
-
[29]
L. Shi, C. Ma, W. Liang, X. Diao, W. Ma, and S. V osoughi, “Judging the judges: A systematic study of position bias in llm-as-a-judge,”arXiv preprint arXiv:2406.07791, 2025
-
[30]
Aishell- ner: Named entity recognition from chinese speech,
B. Chen, G. Xu, X. Wang, P. Xie, M. Zhang, and F. Huang, “Aishell- ner: Named entity recognition from chinese speech,”arXiv preprint arXiv:2202.08533, 2022
-
[31]
Code-switching in end-to-end automatic speech recognition: A system- atic literature review,
M. T. Agro, A. Kulkarni, K. Kadaoui, Z. Talat, and H. Aldarmaki, “Code-switching in end-to-end automatic speech recognition: A system- atic literature review,”arXiv preprint arXiv:2507.07741, 2025
-
[32]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
W. Deng, S. Zhou, J. Shu, J. Wang, and L. Wang, “Indextts: An industrial-level controllable and efficient zero-shot text-to-speech sys- tem,”arXiv preprint arXiv:2502.05512, 2025
-
[34]
Gigaspeech: An evolving, multi- domain asr corpus with 10,000 hours of transcribed audio,
G. Chen, S. Chai, G. Wang, J. Du, W.-Q. Zhang, C. Weng, D. Su, D. Povey, J. Trmal, J. Zhanget al., “Gigaspeech: An evolving, multi- domain asr corpus with 10,000 hours of transcribed audio,”arXiv preprint arXiv:2106.06909, 2021
-
[35]
Wenetspeech: A 10000+ hours multi-domain mandarin corpus for speech recognition,
B. Zhang, H. Lv, P. Guo, Q. Shao, C. Yang, L. Xie, X. Xu, H. Bu, X. Chen, C. Zenget al., “Wenetspeech: A 10000+ hours multi-domain mandarin corpus for speech recognition,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6182–6186
2022
-
[36]
AISHELL-1: An Open-Source Mandarin Speech Corpus and A Speech Recognition Baseline
H. Bu, J. Du, X. Na, B. Wu, and H. Zheng, “Aishell-1: An open- source mandarin speech corpus and a speech recognition baseline,”arXiv preprint arXiv:1709.05522, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[37]
X. Shi, Q. Feng, and L. Xie, “The asru 2019 mandarin-english code- switching speech recognition challenge: Open datasets, tracks, methods and results,”arXiv preprint arXiv:2007.05916, 2020. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 10
-
[38]
J. Zhou, Y . Guo, S. Zhao, H. Sun, H. Wang, J. He, A. Kong, S. Wang, X. Yang, Y . Wang, Y . Lin, and Y . Qin, “Cs-dialogue: A 104-hour dataset of spontaneous mandarin-english code-switching dialogues for speech recognition,”arXiv preprint arXiv:2502.18913, 2025
-
[39]
Zechner and K
K. Zechner and K. Evanini, Eds.,Automated Speaking Assessment: Using Language Technologies to Score Spontaneous Speech, 1st ed. Routledge, 2019
2019
-
[40]
Automated speech scoring system under the lens: Evaluating and interpreting models,
A. Biswaset al., “Automated speech scoring system under the lens: Evaluating and interpreting models,”arXiv preprint arXiv:2111.15156, 2021
-
[41]
Vii. note on regression and inheritance in the case of two parents,
K. Pearson, “Vii. note on regression and inheritance in the case of two parents,”Proceedings of the Royal Society of London, vol. 58, no. 347- 352, pp. 240–242, 12 1895
-
[42]
K.-T. Xu, F.-L. Xie, X. Tang, and Y . Hu, “Fireredasr: Open-source industrial-grade mandarin speech recognition models from encoder- decoder to llm integration,”arXiv preprint arXiv:2501.14350, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.