Recovering Policy-Induced Errors: Benchmarking and Trajectory Synthesis for Robust GUI Agents
Pith reviewed 2026-06-29 08:15 UTC · model grok-4.3
The pith
GUI agents recover from their own errors after training on 800k synthesized trajectories, reaching 47.4 percent success on OSWorld.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
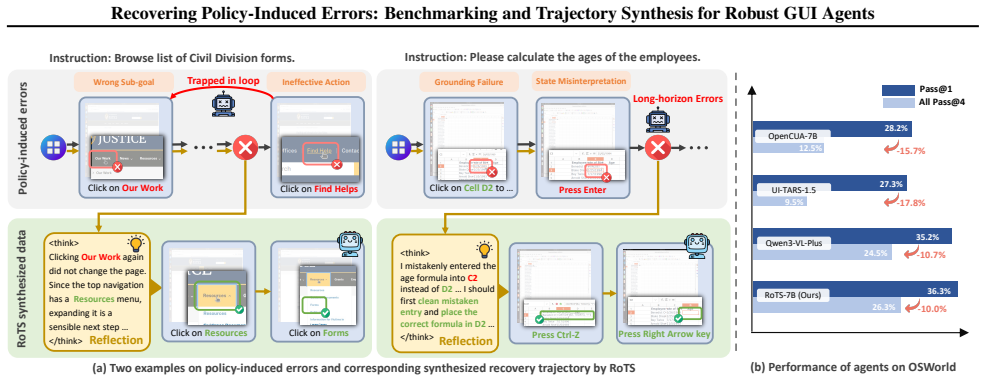
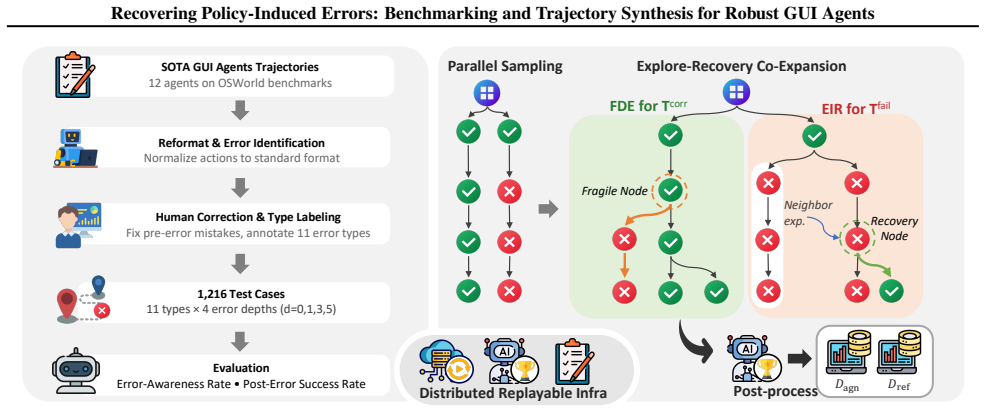
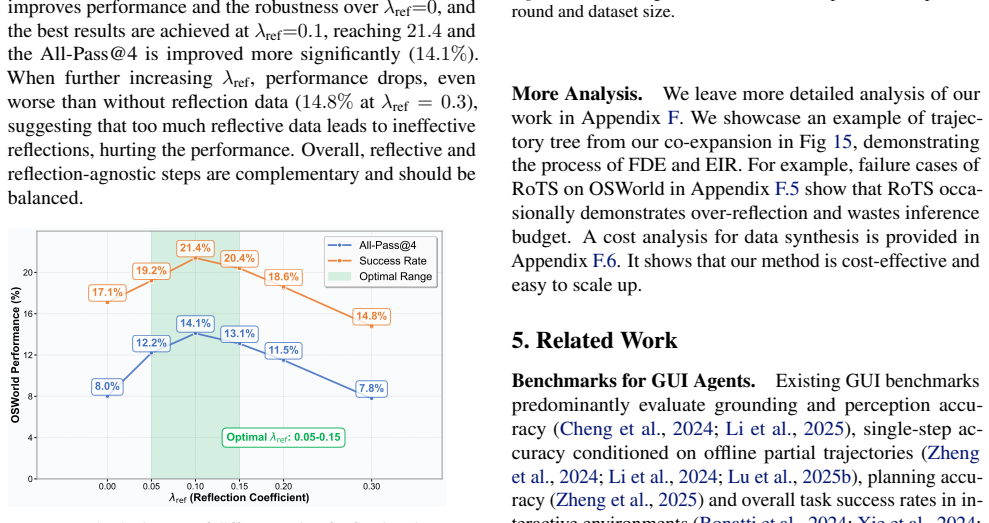
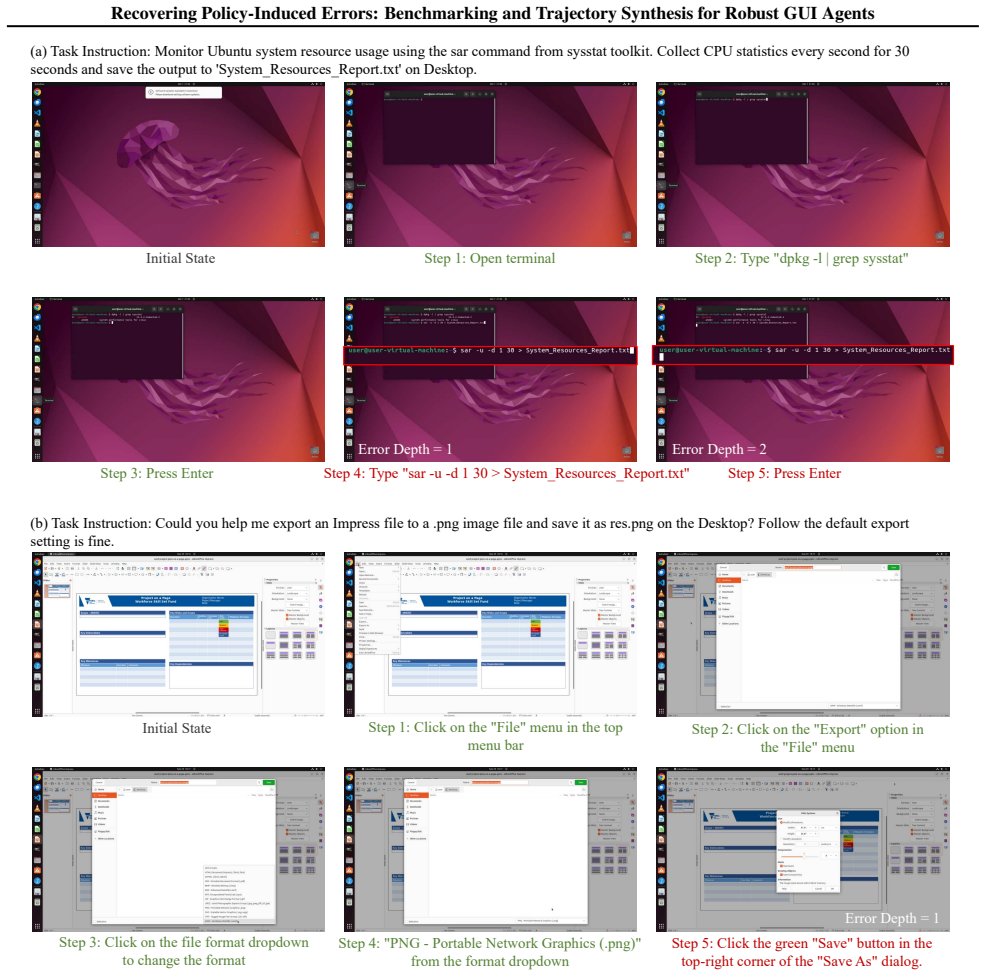
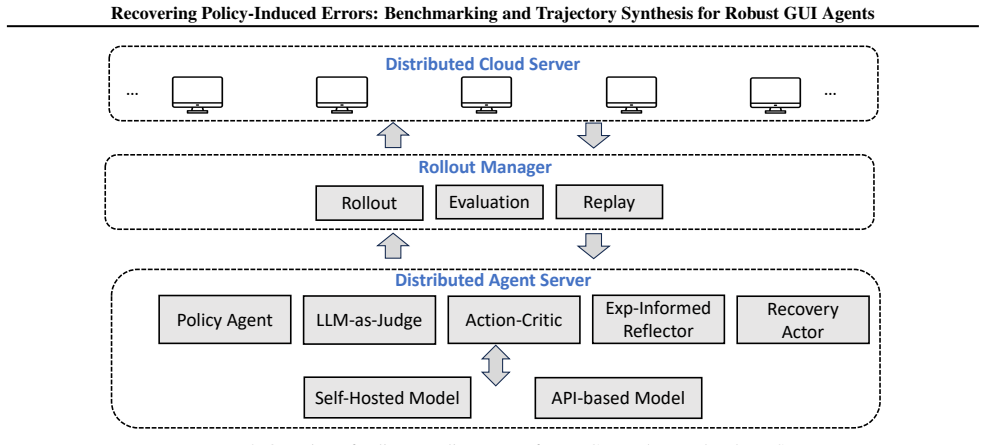
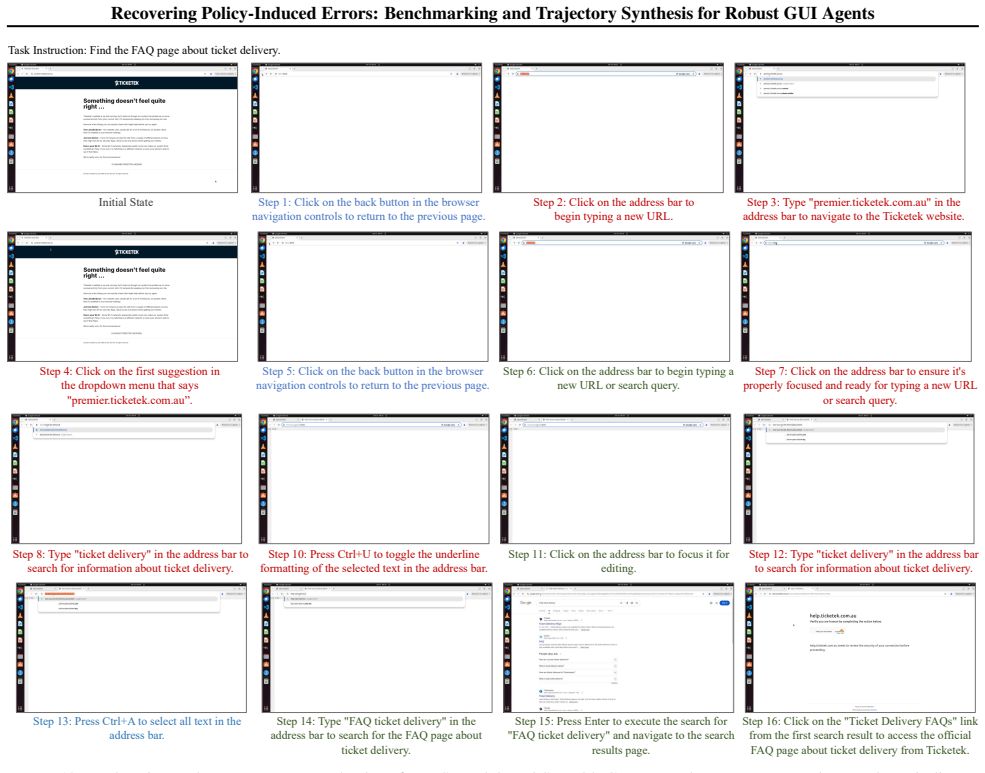
The paper claims that its Robustness-driven Trajectory Synthesis (RoTS) framework, using a tree-based pipeline to discover error modes and create corresponding recovery steps, produces 800k high-quality trajectories. Fine-tuning models on this data results in RoTS-7B and RoTS-32B that outperform prior approaches on GUI-RobustEval and achieve 47.4 percent success rate with 33.8 percent All-Pass@4 on OSWorld, indicating that better error recovery enhances long-horizon performance.
What carries the argument
The RoTS tree-based pipeline that proactively discovers diverse error modes and synthesizes recovery steps.
If this is right
- Both RoTS-7B and RoTS-32B show significant gains on GUI-RobustEval and traditional GUI benchmarks.
- RoTS-32B reaches state-of-the-art on OSWorld with 47.4 percent success rate.
- Improved long-horizon error recovery ability contributes to both robustness and overall performance.
- GUI-RobustEval provides a systematic way to measure error recovery across a broad spectrum of error modes.
Where Pith is reading between the lines
- Similar synthesis pipelines might help build robust agents in other interactive environments like web browsing or robotics.
- If the generated trajectories cover the main error modes, this could reduce reliance on expensive human demonstrations for training.
- Extending the tree pipeline to more complex multi-step errors could further improve performance on very long tasks.
Load-bearing premise
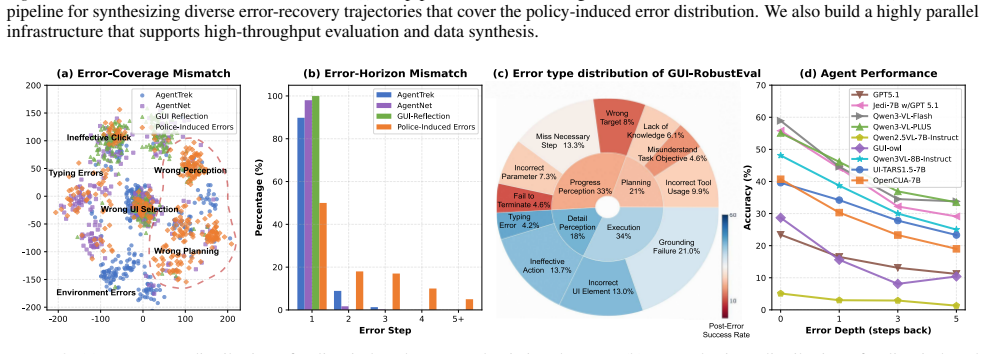
The distribution of error modes in the tree-generated trajectories matches the errors that actual GUI agent policies encounter in real deployment.
What would settle it
A test showing that RoTS-trained agents fail to recover from error types that occur in real user interactions but are absent from the synthesized dataset would falsify the claim that the method produces generally robust agents.
Figures












read the original abstract
While GUI agents have advanced rapidly, they often lack the robustness to recover from their own errors, hindering real-world deployment. To bridge this gap at both the evaluation and data levels, we introduce GUI-RobustEval and propose Robustness-driven Trajectory Synthesis. GUI-RobustEval contains $1,216$ executable test cases that systematically measure error recovery capabilities across a broad and realistic spectrum of error modes. At the data level, RoTS is a scalable synthesis framework that creates $800k$ high-quality data via a tree-based pipeline that proactively discovers diverse error modes and synthesizes corresponding recovery steps. Our two models, RoTS-7B and RoTS-32B, fine-tuned on our dataset, both demonstrate significant gains on GUI-RobustEval and traditional GUI benchmarks. Notably, RoTS-32B achieves state-of-the-art performance on OSWorld, with a $47.4\%$ success rate and a $33.8\%$ All-Pass@4 score, suggesting that improved long-horizon error recovery ability contributes to both robustness and overall performance. Our code is available at https://github.com/AlibabaResearch/RoTS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GUI-RobustEval, a benchmark of 1,216 executable test cases that systematically covers a spectrum of error modes for GUI agents, and RoTS, a tree-based trajectory synthesis pipeline that generates 800k recovery trajectories. Two models (RoTS-7B and RoTS-32B) are fine-tuned on the resulting data and evaluated on both the new benchmark and existing GUI agent suites; the abstract reports that RoTS-32B reaches 47.4% success and 33.8% All-Pass@4 on OSWorld, attributing the gains to improved long-horizon error recovery.
Significance. If the central attribution holds, the work supplies both a targeted evaluation protocol and a scalable data-generation method that could materially advance robustness in deployed GUI agents. The public release of code at the cited GitHub repository is a concrete reproducibility asset.
major comments (2)
- [Abstract] Abstract: the claim that the reported OSWorld gains 'suggest that improved long-horizon error recovery ability contributes to both robustness and overall performance' is load-bearing, yet the manuscript provides no quantitative comparison (KL divergence, category overlap, or rollout statistics) between the error-mode distribution of the 800k tree-synthesized trajectories and the actual failures observed when baseline policies are rolled out on the same environments.
- [GUI-RobustEval] GUI-RobustEval construction: the selection criteria and sampling procedure for the 1,216 test cases, including how the 'broad and realistic spectrum of error modes' was defined and validated against real deployment traces, are not described; without this, it is impossible to determine whether the benchmark isolates the recovery capability that the synthesis method is intended to improve.
minor comments (1)
- [Abstract] The abstract states performance numbers and data scale but defers all methodological detail; a short methods paragraph or pointer to the relevant section would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the manuscript without overstating our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the reported OSWorld gains 'suggest that improved long-horizon error recovery ability contributes to both robustness and overall performance' is load-bearing, yet the manuscript provides no quantitative comparison (KL divergence, category overlap, or rollout statistics) between the error-mode distribution of the 800k tree-synthesized trajectories and the actual failures observed when baseline policies are rolled out on the same environments.
Authors: We agree the attribution would be stronger with a direct quantitative comparison of error-mode distributions. The current manuscript relies on performance gains on GUI-RobustEval (which targets recovery) and OSWorld to support the suggestion. In revision we will add category-overlap statistics and rollout failure analysis between the synthesized trajectories and baseline OSWorld rollouts; if the comparison is not feasible with existing logs we will qualify the abstract claim accordingly. revision: yes
-
Referee: [GUI-RobustEval] GUI-RobustEval construction: the selection criteria and sampling procedure for the 1,216 test cases, including how the 'broad and realistic spectrum of error modes' was defined and validated against real deployment traces, are not described; without this, it is impossible to determine whether the benchmark isolates the recovery capability that the synthesis method is intended to improve.
Authors: Section 3.1 describes the error-mode taxonomy and how the 1,216 cases were constructed to cover them, but the sampling procedure and any validation against external deployment traces are not stated with sufficient detail. We will expand Section 3.1 with explicit selection criteria, sampling method, and validation steps against real traces. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical pipeline for trajectory synthesis via a tree-based method and evaluates resulting models on external benchmarks (GUI-RobustEval and OSWorld). No equations, fitted parameters, or self-citations are present that reduce any reported performance gain or attribution to a definitional equivalence or input by construction. The central claims rest on observed success rates from fine-tuning and external testing rather than any self-referential loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions of supervised fine-tuning and benchmark validity in machine learning for agents.
Reference graph
Works this paper leans on
-
[1]
doi: 10.18653/v1/2025.acl-long.369. URL https: //aclanthology.org/2025.acl-long.369/. Hurst, A., Lerer, A., Goucher, A. P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al. GPT-4o system card.arXiv preprint arXiv:2410.21276, 2024. Li, K., Meng, Z., Lin, H., Luo, Z., Tian, Y ., Ma, J., Huang, Z., and Chua, T.-S...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025.acl-long.369 2025
-
[2]
It must be an explicit judgment of error / non-compliance with the task goal
It states that a prior action/decision/step was wrong relative to the instruction (i.e., it was incorrect, off-track, failed to meet requirements, or was a bad choice). It must be an explicit judgment of error / non-compliance with the task goal
-
[3]
therefore I need to change to
It includes an intention to correct / an improvement strategy (e.g., “therefore I need to change to. . . ”, “roll back. . . ”, “reselect. . . ”, etc.). If the thought only contains any of the following, it must be judged asNO reflection(has reflection=false): • “The previous step succeeded / completed / now I will do the next step” (success assessment) • ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.