CODEFUSE-DEBENCH: An Empirical Study on Readability, Recompilability, and Functionality
Pith reviewed 2026-06-29 06:52 UTC · model grok-4.3
The pith
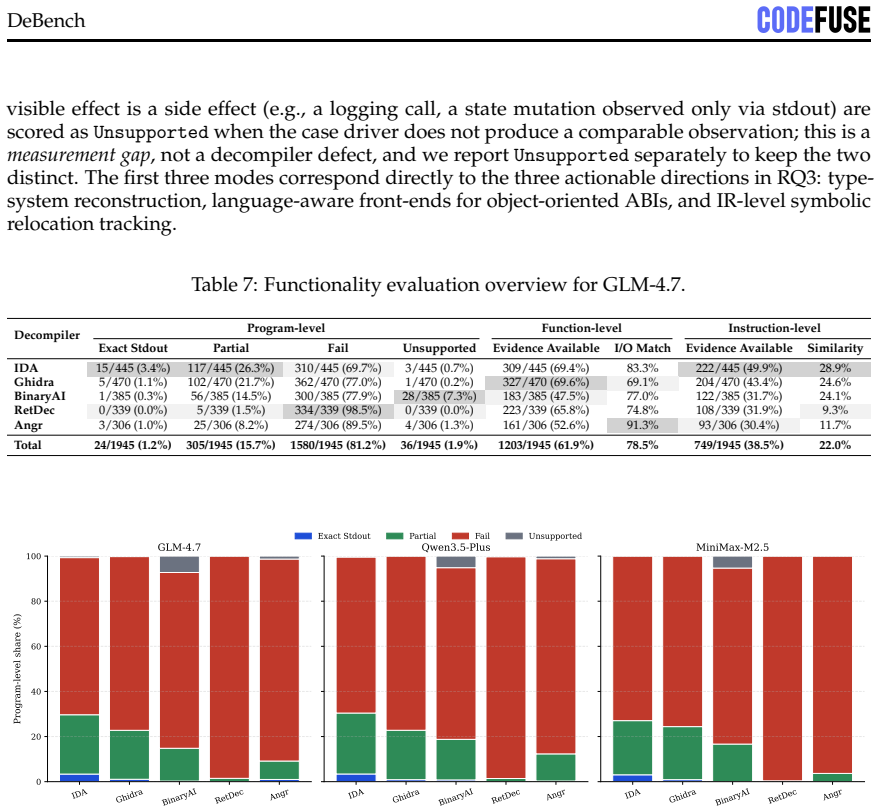
The best decompiler-LLM pair reaches 22.3% behavioral overlap but only 1.2% exact stdout match on test binaries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
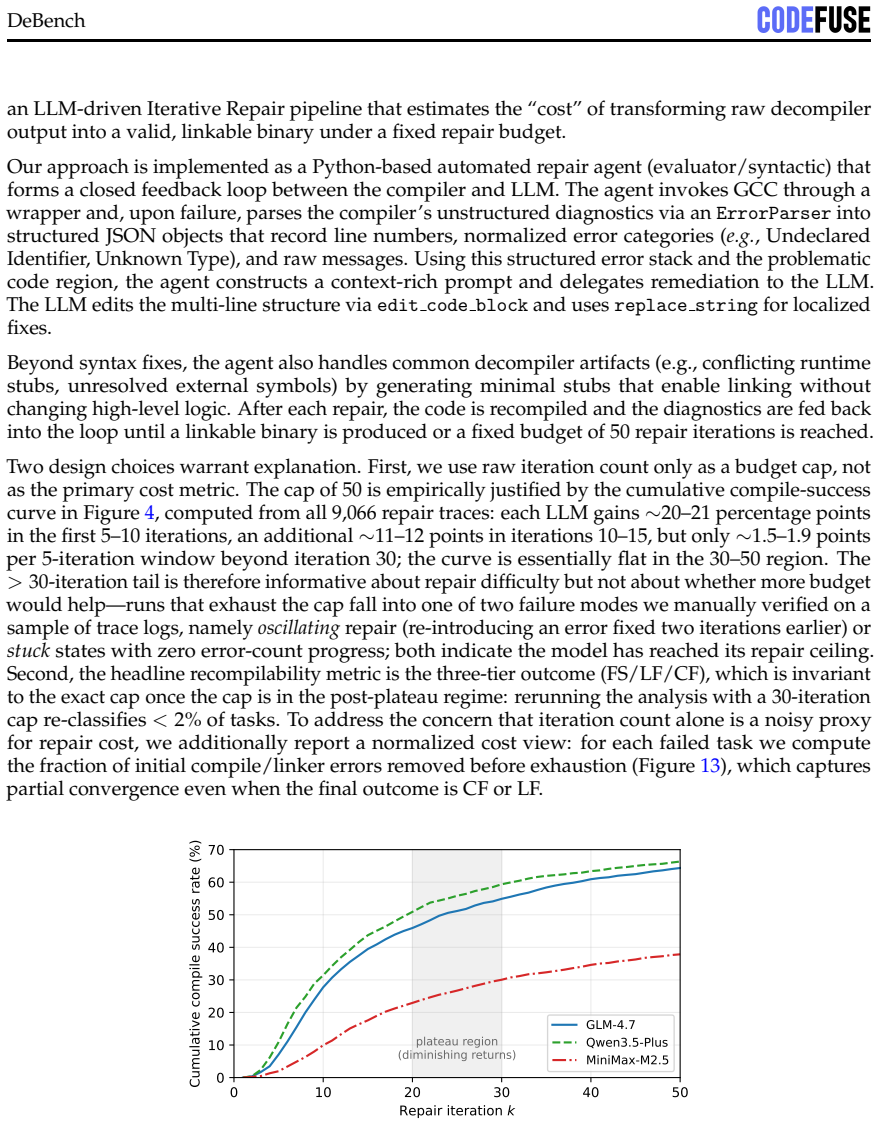
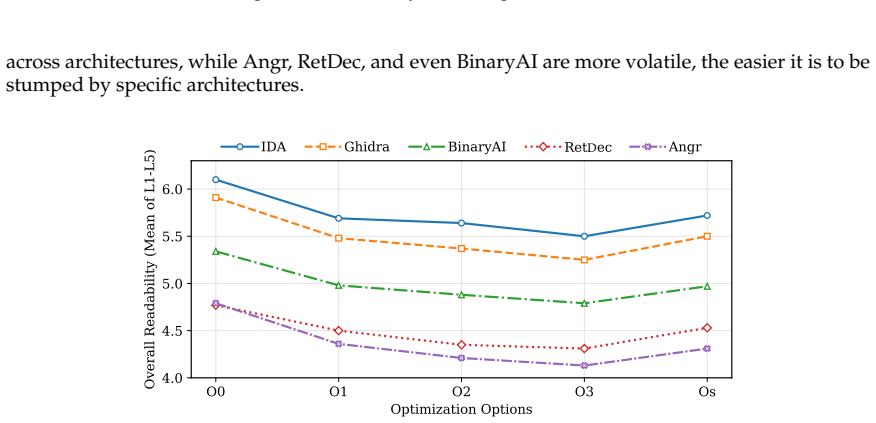
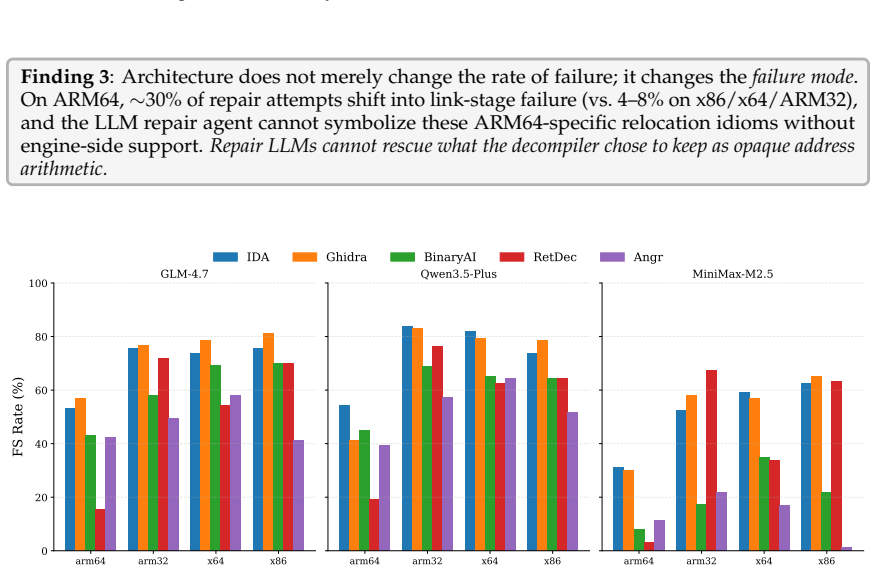
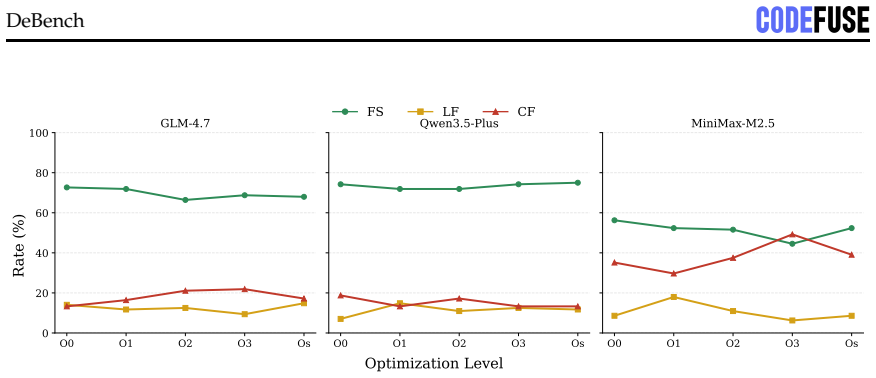
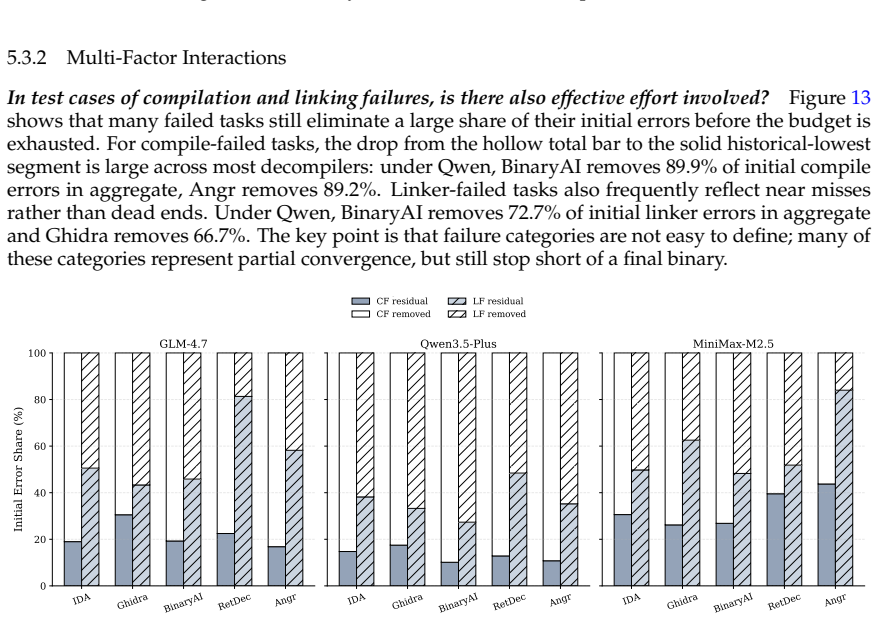
DEBENCH shows that the reusability cliff is steep, with the best decompiler-LLM pair reaching 22.3% Exact+Partial program-level behavioral overlap but only 1.2% exact stdout match, nearly 50 points below recompilability. Settings that maximize readability do not maximize functionality, as -O3 yields the lowest readability but highest functionality while Clang produces 2.6 times higher functionality than GCC despite lower readability. Cross-decompiler functional variation reaches 20 times the scale of cross-LLM variation, and repair failures split into syntactic noise, type-system collapse in about 19% of cases, and irreversible upstream losses from ARM64 relocation idioms and C++ ABI feature
What carries the argument
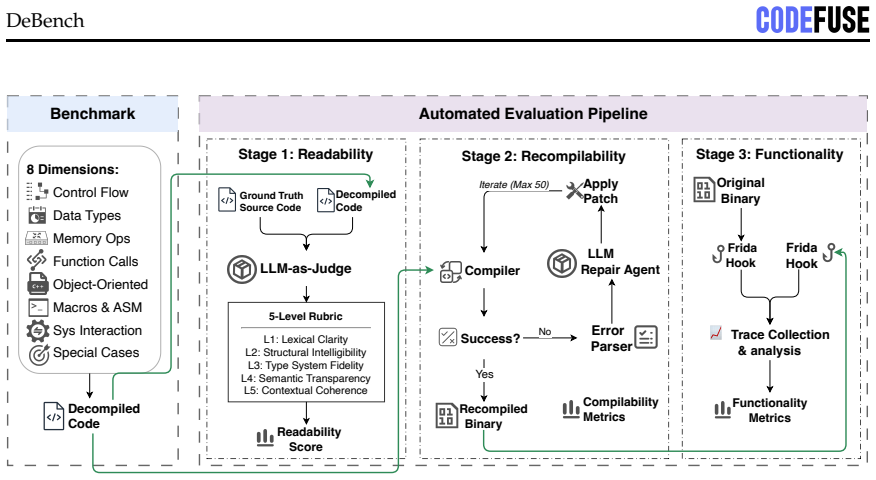
DEBENCH, an automated framework that evaluates five decompilers and three repair LLMs across readability via LLM-as-judge plus 18-subdimension URAF scoring, recompilability via fixed 50-iteration compile-and-repair, and functionality via Frida differential tracing at program, function, and instruction levels on 240 atomic test functions.
If this is right
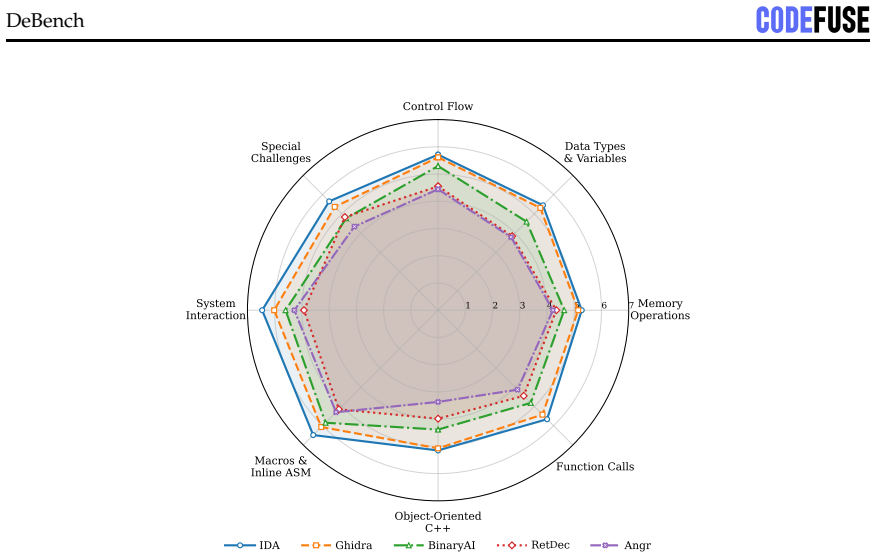
- Decompiler engines drive functional outcomes far more than repair LLMs, since cross-decompiler variation is 20x while cross-LLM variation is only 1.6x.
- Optimization level and compiler choice create direct trade-offs, with -O3 delivering highest functionality at the cost of lowest readability and Clang outperforming GCC by 2.6x on functionality.
- Roughly 19% of repair errors come from type-system collapse, pointing to a recurring limit in current repair pipelines.
- Certain upstream losses from ARM64 relocation idioms and C++ ABI features cannot be recovered by repair models.
Where Pith is reading between the lines
- Decompiler development should target type inference and architecture-specific idioms before further scaling of repair models.
- The three-dimension evaluation could be applied to larger codebases to test whether the reusability cliff widens or narrows with program size.
- Teams recovering binaries for reuse may achieve better results by trying multiple decompilers rather than a single engine plus LLM repair.
Load-bearing premise
The 240 atomic test functions compiled into 640 binaries sufficiently represent the range of real-world decompilation challenges for measuring practical reusability.
What would settle it
Running the same five decompilers and three LLMs on a separate corpus of larger real-world open-source binaries and measuring whether the 22.3% to 1.2% gap and 20x decompiler variation persist or shift substantially.
Figures


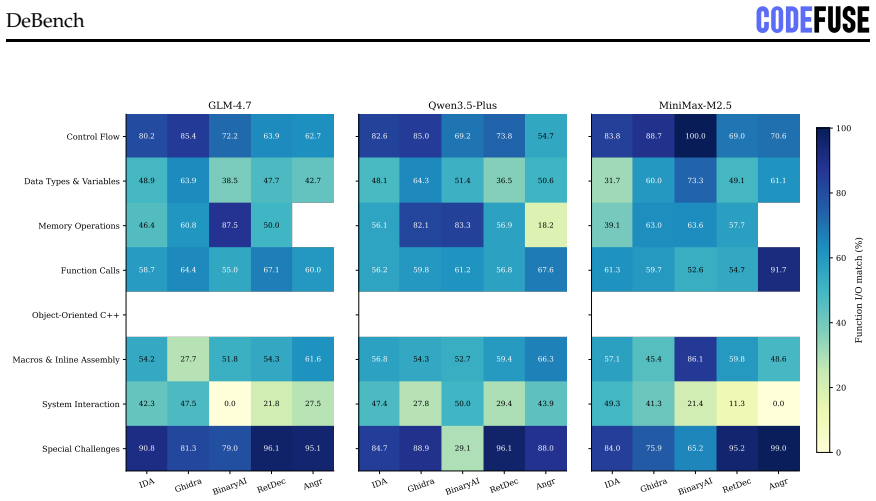
read the original abstract
Binary decompilation aims to recover binaries into high-level source code, but existing evaluations mainly rely on syntactic similarity or single-axis readability metrics, which fail to capture practical reusability. We propose a reusability-driven evaluation paradigm that measures decompiler quality along three orthogonal dimensions: readability, recompilability, and functionality. We present DEBENCH, the first automated framework for multidimensional decompilation evaluation. DEBENCH contains 240 atomic test functions, organized into 8 source files and compiled into 640 binaries. It combines LLM-as-judge readability scoring with URAF (18 sub-dimensions), iterative compile-and-repair under a fixed 50-iteration budget, and Frida-based differential dynamic tracing at the program, function, and instruction levels. We evaluate five mainstream decompilers and three repair LLMs. Our study reveals four findings. First, the reusability cliff is steep: the best decompiler-LLM pair reaches 22.3% Exact+Partial program-level behavioral overlap but only 1.2% exact stdout match, nearly 50 points below recompilability. Second, settings that maximize readability do not maximize functionality: -O3 yields the lowest readability but the highest functionality, and Clang gives lower readability than GCC but 2.6x higher functionality. Third, cross-decompiler variation at the functional level is 20x, far larger than the 1.6x cross-LLM variation, showing that progress depends more on decompiler engines than larger repair models. Fourth, failures fall into three categories: syntactic noise, type-system collapse (about 19% of repair errors), and irreversible upstream losses such as ARM64 relocation idioms and C++ ABI features.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DEBENCH, the first automated framework for multidimensional decompilation evaluation, using 240 atomic test functions compiled into 640 binaries. It measures decompiler quality (five decompilers, three repair LLMs) along readability (LLM-as-judge with URAF 18-subdimension scoring), recompilability (iterative compile-and-repair, 50-iteration budget), and functionality (Frida-based differential dynamic tracing at program/function/instruction levels). The study reports four findings: a steep reusability cliff (best pair at 22.3% Exact+Partial program-level behavioral overlap but 1.2% exact stdout match), settings maximizing readability do not maximize functionality (-O3 lowest readability but highest functionality; Clang 2.6x higher functionality than GCC), 20x cross-decompiler vs 1.6x cross-LLM functional variation, and three failure categories (syntactic noise, ~19% type-system collapse, irreversible upstream losses like ARM64 relocations and C++ ABI).
Significance. If the empirical results hold, the work establishes a reusability-driven evaluation paradigm that addresses limitations of prior syntactic or single-axis metrics, with concrete numbers from 640 binaries and an automated framework combining LLM judging, compile-repair, and dynamic tracing. Strengths include the orthogonal dimensions, explicit failure categorization, and the finding that decompiler engines matter more than repair-model scale. This provides a reproducible basis for prioritizing decompiler improvements over larger LLMs.
major comments (1)
- [DEBENCH description and findings] DEBENCH framework (abstract and evaluation setup): The central reusability-cliff claim (22.3% behavioral overlap vs. 1.2% stdout match) and the four findings rest on 240 atomic test functions. These lack inter-procedural data flow, complex heap layouts, and ABI interactions that dominate real binaries; the paper's own identification of irreversible upstream losses (ARM64 relocations, C++ ABI) indicates the test set may under-sample exactly those dominant failure modes, risking that the measured gap shrinks or reverses on larger programs.
minor comments (2)
- [Results] Results section: clarify the precise definition and computation of 'Exact+Partial program-level behavioral overlap' and how it differs from exact stdout match, including any thresholds or aggregation rules across the three tracing levels.
- [Methods] Methods: provide explicit data-exclusion rules, error bars or confidence intervals on the reported percentages, and the full list of the 8 source files or 240 functions to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of DEBENCH's contributions and for the detailed comment on the evaluation setup. We respond point by point below.
read point-by-point responses
-
Referee: The central reusability-cliff claim (22.3% behavioral overlap vs. 1.2% stdout match) and the four findings rest on 240 atomic test functions. These lack inter-procedural data flow, complex heap layouts, and ABI interactions that dominate real binaries; the paper's own identification of irreversible upstream losses (ARM64 relocations, C++ ABI) indicates the test set may under-sample exactly those dominant failure modes, risking that the measured gap shrinks or reverses on larger programs.
Authors: The 240 atomic test functions were deliberately chosen to isolate decompilation effects across the three orthogonal dimensions (readability, recompilability, functionality) while eliminating confounding variables such as inter-procedural data flow or complex heap layouts. This controlled design enables the precise attribution of the 20x cross-decompiler versus 1.6x cross-LLM variation and the identification of the three failure categories, including the irreversible upstream losses (ARM64 relocations, C++ ABI) already highlighted in the manuscript. The reusability-cliff numbers and four findings are explicitly scoped to this reproducible test suite of 640 binaries; the paper does not claim they generalize to arbitrary real-world binaries. Extending DEBENCH to larger programs with richer ABI and data-flow interactions is a natural next step, but the current atomic baseline remains valuable for guiding targeted improvements to decompiler engines. revision: no
Circularity Check
No circularity: pure empirical measurement study
full rationale
The paper constructs DEBENCH from 240 atomic test functions compiled to 640 binaries and reports direct execution outcomes (readability scores via LLM-as-judge and URAF, recompilation success under 50-iteration repair, and Frida-based behavioral overlap percentages). No equations, fitted parameters, predictions, or derivations exist; the four findings are raw measurement results. No self-citations are load-bearing for any claim, and the evaluation pipeline is externally falsifiable on the stated test suite without reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 240 atomic test functions and their compilation into 640 binaries capture the key challenges of practical decompilation.
invented entities (2)
-
DEBENCH framework
no independent evidence
-
URAF readability scoring system
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jordi Armengol-Estap´e, Jackson Woodruff, Alexander Brauckmann, Jos´e Wesley de Souza Magalh˜aes, and Michael F. P . O’Boyle. Exebench: an ml-scale dataset of executable c functions. InProceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming, MAPS 2022, pp. 50–59, New York, NY, USA,
2022
-
[2]
Association for Computing Machinery. ISBN 9781450392730. doi: 10.1145/3520312.3534867. URLhttps://doi.org/10.1145/3520312.3534867. Avast. Retdec.https://github.com/avast/retdec/,
-
[3]
David Brumley, JongHyup Lee, Edward J Schwartz, and Maverick Woo
Accessed 2026-1-1. David Brumley, JongHyup Lee, Edward J Schwartz, and Maverick Woo. Native x86 decompilation using {Semantics-Preserving} structural analysis and iterative {Control-Flow} structuring. In 22nd USENIX Security Symposium (USENIX Security 13), pp. 353–368,
2026
-
[4]
Evaluating the effectiveness of decompilers
Ying Cao, Runze Zhang, Ruigang Liang, and Kai Chen. Evaluating the effectiveness of decompilers. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2024, pp. 491–502, New York, NY, USA,
2024
-
[5]
Association for Computing Machinery. ISBN 9798400706127. doi: 10.1145/3650212.3652144. URL https://doi.org/10.1145/3650212.3652
-
[6]
Cliff Fan. Arm adr/adrp demos. https://duetorun.com/blog/20230609/arm-adr-demo,
-
[7]
Han Gao, Shaoyin Cheng, Yinxing Xue, and Weiming Zhang
Accessed 2026-1-1. Han Gao, Shaoyin Cheng, Yinxing Xue, and Weiming Zhang. A lightweight framework for function name reassignment based on large-scale stripped binaries. InProceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis, pp. 607–619,
2026
-
[8]
Decompilebench: A comprehensive benchmark for evaluating decompilers in real-world scenarios
Zeyu Gao, Yuxin Cui, Hao Wang, Siliang Qin, Yuanda Wang, Zhang Bolun, and Chao Zhang. Decompilebench: A comprehensive benchmark for evaluating decompilers in real-world scenarios. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 23250–23267,
2025
-
[9]
Jingxuan He, Pesho Ivanov, Petar Tsankov, Veselin Raychev, and Martin Vechev
URLhttps://arxiv.org/abs/2503.06643. Jingxuan He, Pesho Ivanov, Petar Tsankov, Veselin Raychev, and Martin Vechev. Debin: Predicting debug information in stripped binaries. InProceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, pp. 1667–1680,
-
[10]
Peiwei Hu, Ruigang Liang, and Kai Chen
Accessed 2025-1-1. Peiwei Hu, Ruigang Liang, and Kai Chen. Degpt: Optimizing decompiler output with llm. In Proceedings 2024 Network and Distributed System Security Symposium, volume 267622140,
2025
-
[11]
Symlm: Predicting function names in stripped binaries via context-sensitive execution-aware code embeddings
Xin Jin, Kexin Pei, Jun Yeon Won, and Zhiqiang Lin. Symlm: Predicting function names in stripped binaries via context-sensitive execution-aware code embeddings. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, pp. 1631–1645,
2022
-
[12]
Dire: A neural approach to decompiled identifier naming
Jeremy Lacomis, Pengcheng Yin, Edward Schwartz, Miltiadis Allamanis, Claire Le Goues, Graham Neubig, and Bogdan Vasilescu. Dire: A neural approach to decompiled identifier naming. In 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE), pp. 628–639. IEEE,
2019
-
[13]
Finding vulnerabilities in internal-binary of firmware with clues
Puzhuo Liu, Dongliang Fang, Chuan Qin, Kai Cheng, Shichao Lv, Hongsong Zhu, and Limin Sun. Finding vulnerabilities in internal-binary of firmware with clues. InICC 2022-IEEE International Conference on Communications, pp. 5397–5402. IEEE,
2022
-
[14]
Jiaqian Peng, Puzhuo Liu, Yicheng Zeng, Kai Cheng, Yongji Liu, Yun Yang, and Hongsong Zhu
Accessed 2026-1-1. Jiaqian Peng, Puzhuo Liu, Yicheng Zeng, Kai Cheng, Yongji Liu, Yun Yang, and Hongsong Zhu. Bridge: High-Order Taint Vulnerabilities Detection in Linux-based IoT Firmware . In2026 IEEE Symposium on Security and Privacy (SP), pp. 2659–2678, Los Alamitos, CA, USA, May
2026
-
[15]
doi: 10.1109/SP63933.2026.00001
IEEE Computer Society. doi: 10.1109/SP63933.2026.00001. URL https://doi.ieeecomputersociety. org/10.1109/SP63933.2026.00001. Ole Andr´e Ravn˚as. Frida: A world-class dynamic instrumentation toolkit. https://frida.re/ ,
-
[16]
Benchmarking binary type inference techniques in decompilers
Vedant Soni, Audrey Dutcher, Tiffany Bao, and Ruoyu Wang. Benchmarking binary type inference techniques in decompilers. InProceedings of the 2025 Workshop on Software Understanding and Reverse Engineering, SURE ’25, pp. 48–60, New York, NY, USA,
2025
-
[17]
Association for Computing Machinery. ISBN 9798400719103. doi: 10.1145/3733822.3764675. URL https://doi.org/10.114 5/3733822.3764675. 30 DeBench Akihiro Suda and Lima contributors. Lima: Linux virtual machines.https://lima-vm.io/,
-
[18]
Llm4decompile: Decompiling binary code with large language models
Hanzhuo Tan, Qi Luo, Jing Li, and Yuqun Zhang. Llm4decompile: Decompiling binary code with large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 3473–3487,
2024
-
[19]
URLhttps://arxiv.org/abs/2505.12668. Tencent Security. BinaryAI: Binary code analysis with artificial intelligence. https://www.binary ai.net/,
-
[20]
Resym: Harness- ing llms to recover variable and data structure symbols from stripped binaries
Danning Xie, Zhuo Zhang, Nan Jiang, Xiangzhe Xu, Lin Tan, and Xiangyu Zhang. Resym: Harness- ing llms to recover variable and data structure symbols from stripped binaries. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pp. 4554–4568,
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.