DynaGraph: Lightweight Multi-Model Interaction Framework via Dynamic Topological Reconfiguration
Pith reviewed 2026-06-29 00:13 UTC · model grok-4.3
The pith
DynaGraph lets an 8B model match 72B-level reasoning on StrategyQA and MATH by reconfiguring its task graph on the fly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
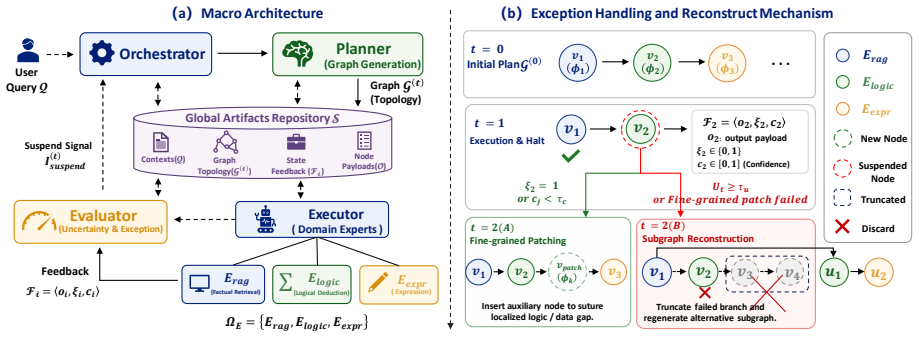
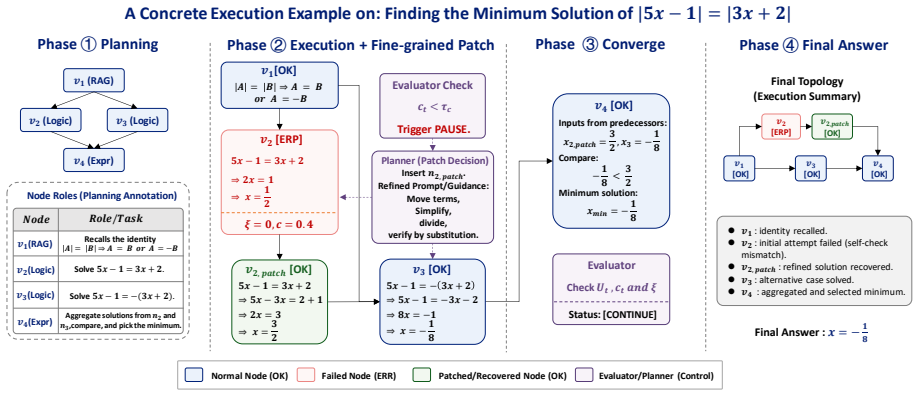
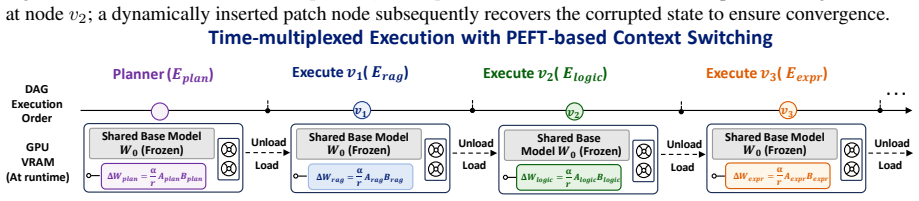
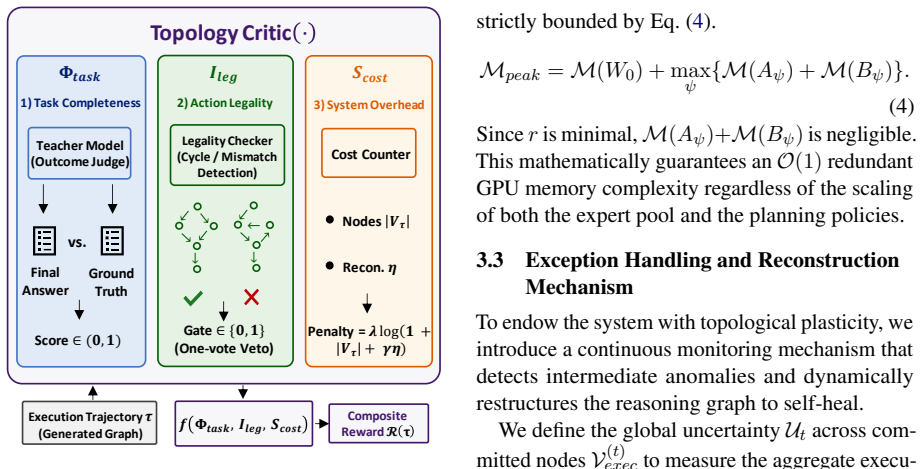
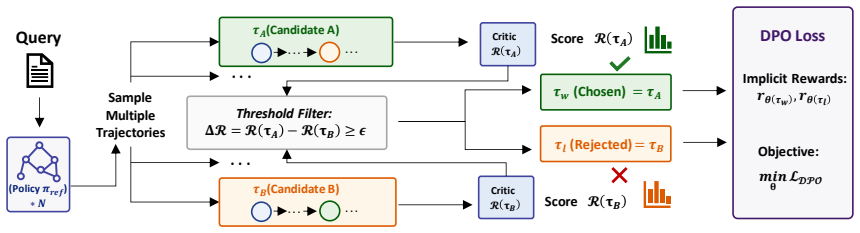
DynaGraph achieves near-parity with much larger monolithic models on reasoning benchmarks by multiplexing PEFT adapters over one base model and using an evaluator to drive hierarchical self-healing through fine-grained patching or subgraph reconstruction whenever execution confidence falls.
What carries the argument
Dynamic topological reconfiguration, in which an evaluator monitors execution confidence and switches between fine-grained patching for localized gaps and subgraph reconstruction for logical breaks.
If this is right
- An 8B model can reach performance levels previously associated with 72B models on math and strategy tasks.
- Multi-model systems can avoid both cascading errors from fixed graphs and memory growth from open-ended agents.
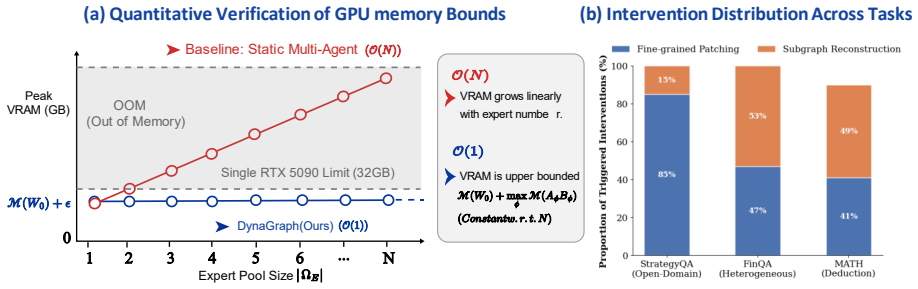
- Full training and inference for such frameworks fits on a single consumer GPU.
- Token use and latency drop by more than two-thirds relative to unconstrained dynamic routing.
Where Pith is reading between the lines
- The same evaluator-driven switch could be tested on code-generation or planning tasks where error types differ from the reported benchmarks.
- Combining the adapter multiplexing with quantization might allow even smaller base models while preserving the reported accuracy.
- The approach suggests a route to scale multi-agent reasoning without proportional increases in hardware.
Load-bearing premise
The evaluator can correctly spot confidence drops and pick the right fix without adding new errors or too much extra cost.
What would settle it
Run the system on a set of tasks where the evaluator repeatedly chooses patching when reconstruction is needed and measure whether accuracy collapses or latency spikes beyond the reported savings.
Figures
read the original abstract
Tackling complex reasoning tasks typically relies on massive monolithic LLMs, which suffer from severe computational redundancy. While task decomposition through structured pipelines or multi-agent collaborations offers an alternative, these approaches inevitably fall into a critical dilemma: predefined static topologies are highly vulnerable to cascading errors, whereas unconstrained dynamic agents suffer from trajectory divergence and unpredictable memory bloat. To address this, we present DynaGraph, a lightweight multi-model framework driven by dynamic topological reconfiguration. At the execution level, DynaGraph multiplexes time-division PEFT adapters over a shared base model, enabling both full system training and inference deployment on a single consumer-grade GPU. At the routing level, the Evaluator continuously monitors execution confidence to trigger hierarchical self-healing: Fine-grained Patching for localized data gaps and Subgraph Reconstruction for severe logical ruptures. Experiments on StrategyQA, MATH, and FinQA demonstrate our 8B model closely approximates the reasoning capabilities of a 72B monolithic model (e.g., 87.6% on StrategyQA, 82.7% on MATH). Furthermore, it reduces latency by up to 68.1% and token consumption by 68.6% compared to unconstrained dynamic architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DynaGraph, a lightweight multi-model framework for complex reasoning that employs dynamic topological reconfiguration to mitigate cascading errors in static pipelines and trajectory divergence in unconstrained multi-agent systems. It multiplexes time-division PEFT adapters over a shared base model to enable full training and inference on a single consumer GPU. At runtime, an Evaluator monitors execution confidence to trigger hierarchical self-healing via fine-grained patching for localized gaps or subgraph reconstruction for logical ruptures. Experiments on StrategyQA, MATH, and FinQA report that an 8B model achieves 87.6% and 82.7% accuracy respectively, closely approximating a 72B monolithic model, while reducing latency by up to 68.1% and token consumption by 68.6% versus unconstrained dynamic baselines.
Significance. If the empirical claims and the Evaluator mechanism hold under scrutiny, the work would be significant for showing how dynamic reconfiguration combined with PEFT multiplexing can close the capability gap between small and large models on reasoning benchmarks while delivering substantial efficiency gains. The single-GPU deployment aspect and explicit handling of self-healing distinguish it from prior static or fully dynamic multi-agent approaches. Reproducible code or parameter-free derivations are not mentioned.
major comments (2)
- [§4] §4 (Experiments) and the abstract: the central claims that the 8B model approximates 72B performance (87.6% StrategyQA, 82.7% MATH) and achieves 68.1%/68.6% reductions rest on the Evaluator correctly detecting confidence drops and choosing between patching and reconstruction without cascading errors or excessive overhead; no ablations, decision-accuracy metrics, error traces, or failure-mode analysis are supplied to validate this component.
- [§4.3] §4.3 (Baselines and comparisons): the latency and token reductions are reported only versus 'unconstrained dynamic architectures' with no description of those baselines' exact configurations, hyper-parameters, or statistical significance tests, making it impossible to assess whether the gains are attributable to the hierarchical self-healing or to other unstated differences.
minor comments (2)
- [§3.2] Abstract and §3.2: the term 'time-division PEFT adapters' is introduced without a precise definition or pseudocode for the multiplexing schedule, which would aid reproducibility.
- [Figure 2] Figure 2 (system overview): the diagram of subgraph reconstruction lacks labels for the confidence threshold or the decision boundary between patching and reconstruction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify important gaps in experimental validation and baseline documentation. We address each point below and will revise the manuscript to incorporate the requested analyses and details.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and the abstract: the central claims that the 8B model approximates 72B performance (87.6% StrategyQA, 82.7% MATH) and achieves 68.1%/68.6% reductions rest on the Evaluator correctly detecting confidence drops and choosing between patching and reconstruction without cascading errors or excessive overhead; no ablations, decision-accuracy metrics, error traces, or failure-mode analysis are supplied to validate this component.
Authors: We agree that the current manuscript does not provide ablations or failure-mode analysis for the Evaluator. In the revised version we will add a dedicated subsection under Experiments that reports (i) decision-accuracy metrics for confidence-drop detection, (ii) quantitative comparison of patching versus reconstruction choices, and (iii) representative error traces demonstrating prevention of cascading failures. These additions will directly support the central performance claims. revision: yes
-
Referee: [§4.3] §4.3 (Baselines and comparisons): the latency and token reductions are reported only versus 'unconstrained dynamic architectures' with no description of those baselines' exact configurations, hyper-parameters, or statistical significance tests, making it impossible to assess whether the gains are attributable to the hierarchical self-healing or to other unstated differences.
Authors: We concur that the baseline descriptions are insufficient. The revised §4.3 will specify the exact model sizes, adapter configurations, routing policies, and hyper-parameters of the unconstrained dynamic baselines. We will also add paired statistical significance tests (e.g., t-tests with p-values) for all reported latency and token reductions to clarify the contribution of hierarchical self-healing. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents DynaGraph as a framework for dynamic multi-model interaction with an Evaluator for self-healing, and reports empirical results on StrategyQA, MATH, and FinQA showing an 8B model approximating 72B performance plus latency reductions. No equations, fitted parameters, predictions, or self-citations are described that would make any claimed result equivalent to its inputs by construction. The central claims rest on experimental outcomes rather than any load-bearing derivation that reduces to a fit or self-reference. The framework description and performance numbers do not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Legal-bert: The muppets straight out of law school.Preprint, arXiv:2010.02559. Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan R Routledge, et al. 2021. Finqa: A dataset of numerical reasoning over financial data. InProceedings of the 2021 Con- ference on Empirical Methods i...
-
[2]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. Damai Dai, Chengqi Deng, Chenggang Zhao, R. X. Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y . Wu, Zhenda Xie, Y . K. Li, Panpan Huang, Fuli Luo, Chong Ruan, Zhifang Sui, and Wenfeng Liang. 2024. Deepseekmoe: Towards ultimate expert specialization in mixture-...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783. Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. 2021. Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies.Transactions of the Association for Computational Linguistics, 9:346– 361. Dan Hendrycks, Collin Burns, Saurav Kad...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
LoRA: Low-Rank Adaptation of Large Language Models
Measuring mathematical problem solving with the MATH dataset. InNeurIPS. Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven K. S. Yau, Zijian Lin, et al. 2024. Metagpt: Meta programming for a multi-agent col- laborative framework. InThe Twelfth International Conference on Learning Representati...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Bioinformatics, 36(4):1234–1240
Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4):1234–1240. Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Hein- rich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp t...
-
[6]
Qwen2 technical report.arXiv preprint arXiv:2407.10671. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayi- heng Liu, Fan Zhou, Fei Huang, et al. 2025. Qwen3 technical report.Preprint, arXiv:2505.09388. Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Ben- gio, William W Co...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Dynamo: Runtime switchable quantization for moe with cross-dataset adaptation.arXiv preprint arXiv:2503.21135. Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, and Ed Chi
-
[8]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Least-to-most prompting enables complex reasoning in large language models.Preprint, arXiv:2205.10625. Kunlun Zhu, Zijia Liu, et al. 2025. Where llm agents fail and how they can learn from failures.arXiv preprint arXiv:2509.25370. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.