Why Larger Models Learn More: Effects of Capacity, Interference, and Rare-Task Retention
Pith reviewed 2026-06-29 08:37 UTC · model grok-4.3
The pith
Larger models learn rare tasks because they allocate enough capacity to common tasks that gradient updates on those tasks weaken and spare accumulating rare-task features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
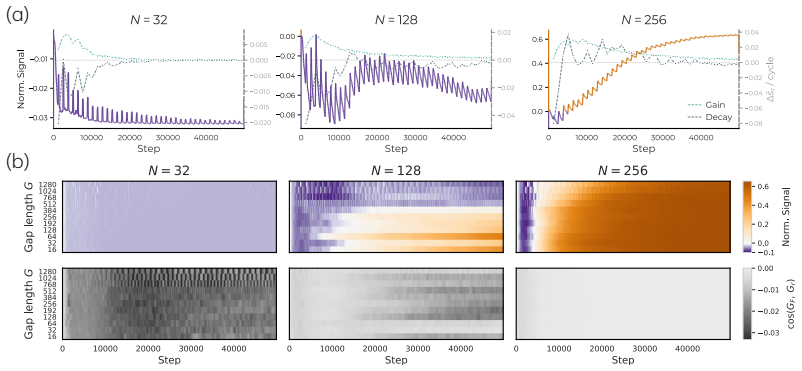
Larger models succeed on rare and complex tasks because they allocate enough neurons to high-frequency tasks that the gradient updates for those tasks weaken, leaving the slowly accumulating features of rare tasks intact; smaller models, lacking spare capacity, overwrite those features while optimizing for common tasks.
What carries the argument
The reduced interference mechanism arising from capacity allocation that weakens gradients on frequent tasks.
If this is right
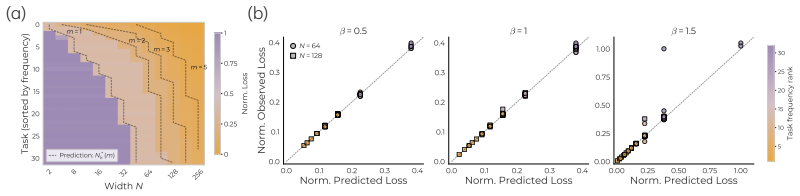
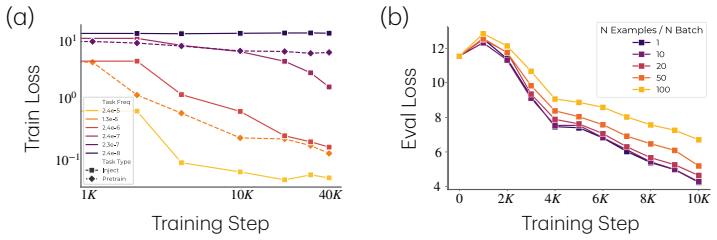
- Only models above a certain size learn infrequent and complex tasks in both the synthetic mixture and in OLMo pretraining.
- Larger models embed more task-specific features in their hidden representations.
- Gradient interference between tasks decreases measurably with scale.
- The data-centric competition for neurons explains why scaling improves performance on the tail of the task distribution.
Where Pith is reading between the lines
- Data-mixture design could deliberately boost the frequency of desired rare tasks when model capacity is limited.
- The same interference dynamic may appear when scaling other architectures or training objectives beyond language models.
- Practical decisions about model size should be informed by the frequency distribution of the tasks one ultimately wants to retain.
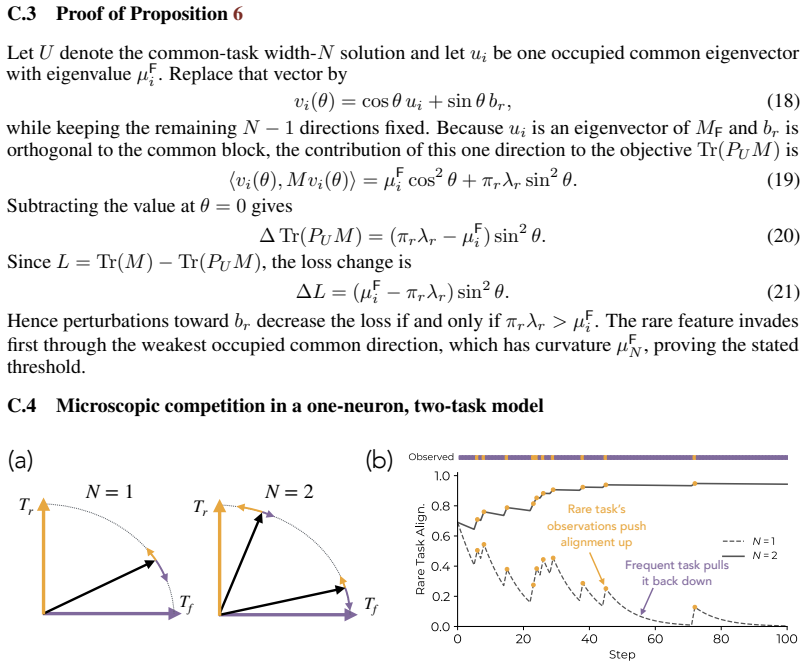
Load-bearing premise
The synthetic mixture of tasks with monotonic scaling curves reproduces the resource competition and interference dynamics that occur during real language-model pretraining on natural data.
What would settle it
A measurement showing that gradient interference on rare-task features remains equally strong in large and small models even after the large models have allocated extra capacity to common tasks would falsify the account.
Figures




read the original abstract
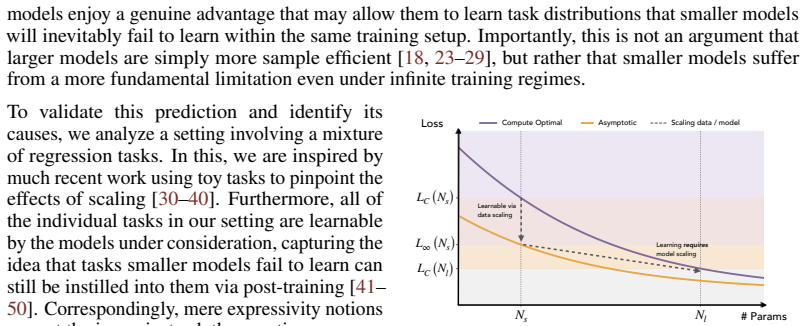
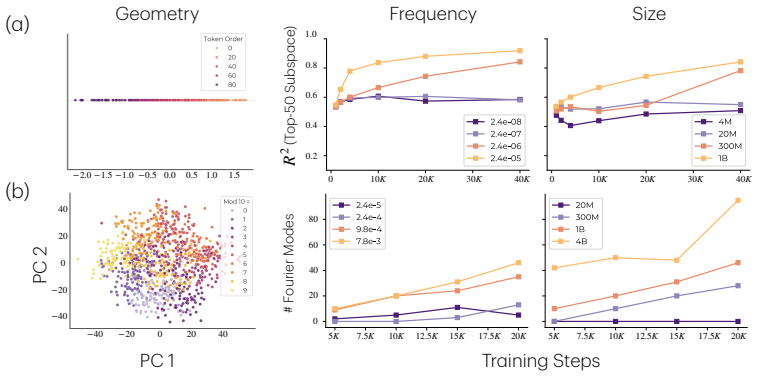
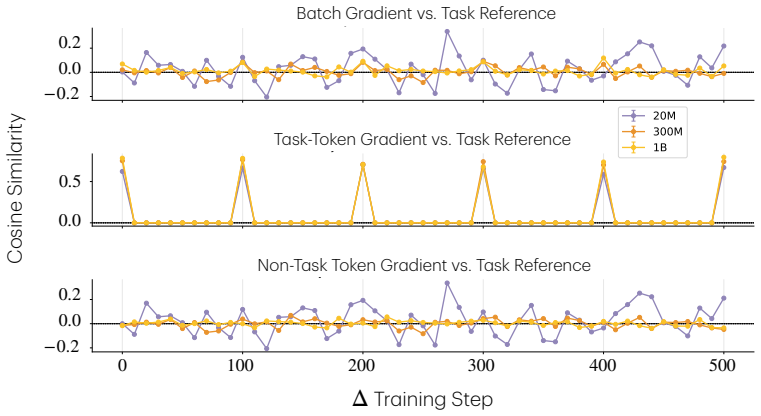
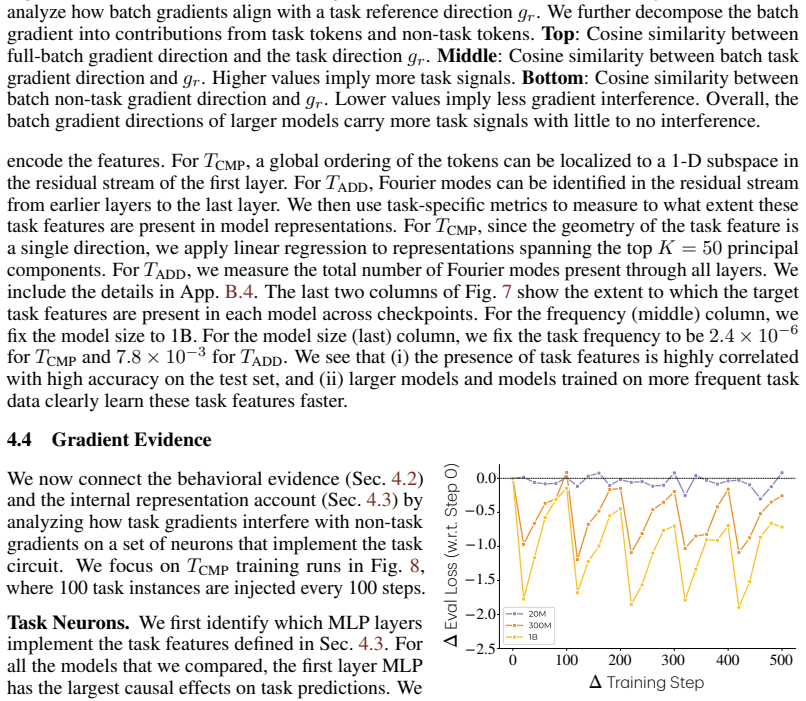
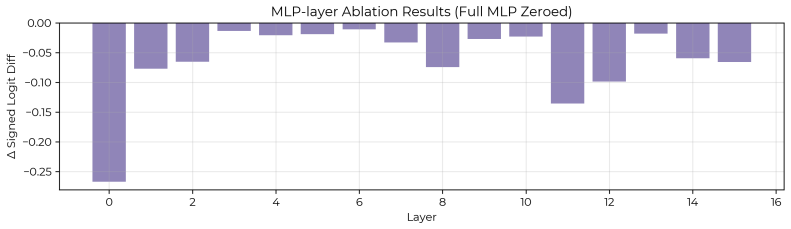
Larger models learn tasks smaller models do not. What drives this phenomenon? We develop a simple phenomenological argument that power-law scaling already suggests that a larger model will be able to learn a part of the data distribution that a smaller model fails to learn, even with infinite training data. To validate this claim and identify its causes, we study the effects of model scaling on a synthetic setup consisting of a mixture of tasks that show monotonic scaling curves. The results point to a data-induced competition over resources (neurons). Specifically, smaller models allocate their neurons to high frequency or low complexity tasks, and so they learn solutions that perform poorly on rare and complex tasks. Moreover, this happens even when solutions capable of expressing the desired task exist. We then assess how a larger model circumvents this data-centric bottleneck, finding that it traces to a reduced interference mechanism: larger models can allocate enough resources to common tasks that the gradient updates for those tasks become weak, which means that they do not overwrite rare-task features as they slowly accumulate. Finally, to further validate these claims, we pretrain OLMo models (4M to 4B parameters) on novel tasks of varying frequency and complexity. The results mirror those from our synthetic data experiments: only the larger OLMo models learn the infrequent and complex tasks, and these larger models embed more task features in their representations and show less gradient interference between tasks. Overall, we offer a data-centric account of why larger models learn tasks that smaller models fail to. This helps explain why larger models are better in practice, and it can inform practical questions concerning model sizing and training data mixtures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that larger models succeed on rare and complex tasks that smaller models fail to learn because they allocate sufficient capacity to common tasks, weakening the associated gradient updates and thereby reducing interference that would otherwise overwrite slowly accumulating rare-task features. This data-centric account is motivated by a phenomenological argument based on power-law scaling and is supported by synthetic experiments on task mixtures engineered to exhibit monotonic scaling curves, plus OLMo pretraining runs (4M to 4B parameters) that insert novel tasks of controlled frequency and complexity, where larger models are shown to embed more task features and exhibit less gradient interference.
Significance. If the reduced-interference mechanism holds, the work supplies a concrete explanation for why scaling improves performance on the tail of the data distribution and could inform practical choices about model size and data mixtures. Credit is due for the controlled synthetic setups that isolate resource competition and for the direct scaling experiments with OLMo models that provide reproducible evidence rather than relying solely on post-hoc analysis of existing checkpoints.
major comments (2)
- [Synthetic experiments section] Synthetic experiments section: the claim that the observed monotonic scaling and reduced interference explain larger-model behavior on natural data rests on the assumption that tasks can be treated as discrete, separable components whose resource competition is directly measurable; this is load-bearing for the central extrapolation because natural web-scale distributions entangle rare phenomena with common tokens, which may produce different gradient structures and neuron allocations.
- [OLMo pretraining experiments] OLMo pretraining experiments: inserting novel tasks of controlled frequency/complexity into the training mixture demonstrates the pattern but does not establish that the same reduced-interference dynamic governs the gradient updates arising from the statistically entangled rare events already present in the base corpus; this distinction is load-bearing for the claim that the mechanism accounts for scaling success in practice.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to clarify limitations.
read point-by-point responses
-
Referee: [Synthetic experiments section] Synthetic experiments section: the claim that the observed monotonic scaling and reduced interference explain larger-model behavior on natural data rests on the assumption that tasks can be treated as discrete, separable components whose resource competition is directly measurable; this is load-bearing for the central extrapolation because natural web-scale distributions entangle rare phenomena with common tokens, which may produce different gradient structures and neuron allocations.
Authors: The synthetic experiments are designed to isolate the interference mechanism by using discrete, controllable tasks, enabling direct measurement of capacity allocation, gradient magnitudes, and feature accumulation that would be difficult to disentangle in natural data. This controlled isolation is what allows us to identify the reduced-interference dynamic as a candidate explanation. The OLMo experiments then test the same pattern when tasks are inserted into a real corpus. We will add a dedicated limitations paragraph in the discussion section acknowledging that entanglement in natural distributions may alter gradient structures and that the synthetic results therefore provide mechanistic insight rather than a complete account of all scaling behaviors on web data. revision: partial
-
Referee: [OLMo pretraining experiments] OLMo pretraining experiments: inserting novel tasks of controlled frequency/complexity into the training mixture demonstrates the pattern but does not establish that the same reduced-interference dynamic governs the gradient updates arising from the statistically entangled rare events already present in the base corpus; this distinction is load-bearing for the claim that the mechanism accounts for scaling success in practice.
Authors: Inserting novel tasks provides the necessary experimental control to vary frequency and complexity independently while holding the base corpus fixed, allowing us to measure interference and feature embedding directly. This setup demonstrates that the mechanism operates even when tasks are added to a realistic mixture. We agree that it does not directly measure interference among already-entangled rare events native to the corpus. We will revise the abstract, introduction, and conclusion to qualify the claims as applying to controlled insertions and to note the open question of native rare-event dynamics as an important direction for future work. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper advances a phenomenological argument from existing power-law scaling observations, then validates the proposed reduced-interference mechanism through independent synthetic task-mixture experiments and new OLMo pretraining runs (4M–4B) that insert controlled novel tasks. These empirical setups are constructed and measured separately from any prior fitted quantities or self-citations; the central claims rest on the outcomes of these fresh experiments rather than reducing by construction to inputs via the paper's equations or load-bearing self-references. No steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Power-law scaling of model performance already implies larger models learn parts of the data distribution smaller models fail to learn even with infinite data
Forward citations
Cited by 1 Pith paper
-
Neuron Populations Exhibit Divergent Selectivity with Scale
Rosetta Neurons in language models up to 30B and vision models up to 5B parameters scale sublinearly with size while becoming more selective and monosemantic.
Reference graph
Works this paper leans on
-
[1]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card. arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
System Card: Claude Mythos Preview, 2026
Anthropic. System Card: Claude Mythos Preview, 2026. https://www-cdn.anthropic. com/08ab9158070959f88f296514c21b7facce6f52bc.pdf
2026
-
[3]
Gemini 3 Pro - Model Card, 2026
Google DeepMind. Gemini 3 Pro - Model Card, 2026. https://storage.googleapis. com/deepmind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf
2026
-
[4]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
DeepSeek-V4-Pro, 2026
DeepSeek-AI. DeepSeek-V4-Pro, 2026. https://huggingface.co/deepseek-ai/ DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
2026
-
[6]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Measuring AI ability to complete long software tasks
Thomas Kwa, Ben West, Joel Becker, Amy Deng, Katharyn Garcia, Max Hasin, Sami Jawhar, Megan Kinniment, Nate Rush, Sydney V on Arx, et al. Measuring AI ability to complete long software tasks. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[8]
FrontierMath: A Benchmark for Evaluating Advanced Mathematical Reasoning in AI
Elliot Glazer, Ege Erdil, Tamay Besiroglu, Diego Chicharro, Evan Chen, Alex Gunning, Caroline Falkman Olsson, Jean-Stanislas Denain, Anson Ho, Emily de Oliveira Santos, et al. Frontiermath: A benchmark for evaluating advanced mathematical reasoning in ai.arXiv preprint arXiv:2411.04872, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
ARC-AGI-3, 2026.https://arcprize.org/arc-agi/3
ARC Prize Foundation. ARC-AGI-3, 2026.https://arcprize.org/arc-agi/3
2026
-
[10]
Terminal-bench: Bench- marking agents on hard, realistic tasks in command line interfaces
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminal-bench: Bench- marking agents on hard, realistic tasks in command line interfaces. InThe Fourteenth Inter- national Conference on Learning Representations, 2026. URL https://openreview.net/ for...
2026
-
[11]
Responsible Scaling Policy, 2026
Anthropic. Responsible Scaling Policy, 2026. https://www.anthropic.com/ responsible-scaling-policy
2026
-
[12]
Our Approach to Frontier Risk, 2023
OpenAI. Our Approach to Frontier Risk, 2023. https://openai.com/global-affairs/ our-approach-to-frontier-risk/
2023
-
[13]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Predicting emergent abilities with infinite resolution evaluation
Shengding Hu, Xin Liu, Xu Han, Xinrong Zhang, Chaoqun He, Weilin Zhao, Yankai Lin, Ning Ding, Zebin Ou, Guoyang Zeng, Zhiyuan Liu, and Maosong Sun. Predicting emergent abilities with infinite resolution evaluation. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=lDbjooxLkD
2024
-
[15]
Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. Emergent abilities of large language models.Transactions on Machine Learning Research, 2022. ISSN 2835-8856. URL https://openr...
2022
-
[16]
137 emergent abilities of large language models, 2022
Jason Wei. 137 emergent abilities of large language models, 2022. https://www.jasonwei. net/blog/emergence. 11
2022
-
[17]
arXiv preprint arXiv:2307.15936 , year=
Sanjeev Arora and Anirudh Goyal. A theory for emergence of complex skills in language models.arXiv preprint arXiv:2307.15936, 2023
-
[18]
Understanding emergent abilities of language models from the loss perspective
Zhengxiao Du, Aohan Zeng, Yuxiao Dong, and Jie Tang. Understanding emergent abilities of language models from the loss perspective. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum? id=35DAviqMFo
2024
-
[19]
Larger language models do in-context learning differently
Jerry Wei, Jason Wei, Yi Tay, Dustin Tran, Albert Webson, Yifeng Lu, Xinyun Chen, Hanxiao Liu, Da Huang, Denny Zhou, et al. Larger language models do in-context learning differently. arXiv preprint arXiv:2303.03846, 2023
-
[20]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[21]
Deep Learning Scaling is Predictable, Empirically
Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically.arXiv preprint arXiv:1712.00409, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Rosenfeld, Amir Rosenfeld, Yonatan Belinkov, and Nir Shavit
Jonathan S. Rosenfeld, Amir Rosenfeld, Yonatan Belinkov, and Nir Shavit. A constructive prediction of the generalization error across scales. InInternational Conference on Learning Representations, 2020. URLhttps://openreview.net/forum?id=ryenvpEKDr
2020
-
[23]
Scaling Laws for Autoregressive Generative Modeling
Tom Henighan, Jared Kaplan, Mor Katz, Mark Chen, Christopher Hesse, Jacob Jackson, Hee- woo Jun, Tom B Brown, Prafulla Dhariwal, Scott Gray, et al. Scaling laws for autoregressive generative modeling.arXiv preprint arXiv:2010.14701, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[24]
Danny Hernandez, Jared Kaplan, Tom Henighan, and Sam McCandlish. Scaling laws for transfer.arXiv preprint arXiv:2102.01293, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[25]
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Jack W Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. Scaling language models: Methods, analysis & insights from training gopher.arXiv preprint arXiv:2112.11446, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[26]
Revisiting neural scaling laws in language and vision.Advances in Neural Information Processing Systems, 35:22300– 22312, 2022
Ibrahim M Alabdulmohsin, Behnam Neyshabur, and Xiaohua Zhai. Revisiting neural scaling laws in language and vision.Advances in Neural Information Processing Systems, 35:22300– 22312, 2022
2022
-
[27]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Training compute-optimal large language models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems,
-
[29]
URLhttps://openreview.net/forum?id=iBBcRUlOAPR
-
[30]
Reconciling kaplan and chinchilla scaling laws.Transactions on Machine Learning Research, 2024
Tim Pearce and Jinyeop Song. Reconciling kaplan and chinchilla scaling laws.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https://openreview.net/ forum?id=NLoaLyuUUF
2024
-
[31]
A dynamical model of neural scaling laws
Blake Bordelon, Alexander Atanasov, and Cengiz Pehlevan. A dynamical model of neural scaling laws. InForty-first International Conference on Machine Learning, 2024. URL https://openreview.net/forum?id=nbOY1OmtRc
2024
-
[32]
How feature learning can improve neural scaling laws
Blake Bordelon, Alexander Atanasov, and Cengiz Pehlevan. How feature learning can improve neural scaling laws. InThe Thirteenth International Conference on Learning Representations,
-
[33]
URLhttps://openreview.net/forum?id=dEypApI1MZ. 12
-
[34]
Explaining neural scaling laws.Proceedings of the National Academy of Sciences, 121(27):e2311878121, 2024
Yasaman Bahri, Ethan Dyer, Jared Kaplan, Jaehoon Lee, and Utkarsh Sharma. Explaining neural scaling laws.Proceedings of the National Academy of Sciences, 121(27):e2311878121, 2024
2024
-
[35]
Kakade, Peter L
Licong Lin, Jingfeng Wu, Sham M. Kakade, Peter L. Bartlett, and Jason Lee. Scaling laws in linear regression: Compute, parameters, and data. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 60556–60606. Curran Associates, Inc., 2024. doi: 10. 5...
2024
-
[36]
The quantization model of neural scaling
Eric Michaud, Ziming Liu, Uzay Girit, and Max Tegmark. The quantization model of neural scaling. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 28699–28722. Curran Associates, Inc., 2023. URL https://proceedings.neurips.cc/paper_files/paper/ 2023/file/5b6...
2023
-
[37]
A solvable model of neural scaling laws.arXiv preprint arXiv:2210.16859, 2022
Alexander Maloney, Daniel A Roberts, and James Sully. A solvable model of neural scaling laws.arXiv preprint arXiv:2210.16859, 2022
-
[38]
Dick, and Hidenori Tanaka
Ekdeep Singh Lubana, Kyogo Kawaguchi, Robert P. Dick, and Hidenori Tanaka. A percolation model of emergence: Analyzing transformers trained on a formal language. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=0pLCDJVVRD
2025
-
[39]
Learning curves theory for hierar- chically compositional data with power-law distributed features
Francesco Cagnetta, Hyunmo Kang, and Matthieu Wyart. Learning curves theory for hierar- chically compositional data with power-law distributed features. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id= Lw0kC75dY0
2025
-
[40]
Scaling laws and representation learning in simple hierarchical languages: Transformers vs
Francesco Cagnetta, Alessandro Favero, Antonio Sclocchi, and Matthieu Wyart. Scaling laws and representation learning in simple hierarchical languages: Transformers vs. convolutional architectures.arXiv preprint arXiv:2505.07070, 2025
-
[41]
Francesco Cagnetta, Allan Raventós, Surya Ganguli, and Matthieu Wyart. Deriving neural scaling laws from the statistics of natural language.arXiv preprint arXiv:2602.07488, 2026
-
[42]
Pareto frontiers in deep feature learning: Data, compute, width, and luck.Advances in Neural Information Processing Systems, 36:48021–48034, 2023
Benjamin Edelman, Surbhi Goel, Sham Kakade, Eran Malach, and Cyril Zhang. Pareto frontiers in deep feature learning: Data, compute, width, and luck.Advances in Neural Information Processing Systems, 36:48021–48034, 2023
2023
-
[43]
Tulu 3: Pushing frontiers in open language model post-training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James Validad Miranda, Alisa Liu, Nouha Dziri, Xinxi Lyu, et al. Tulu 3: Pushing frontiers in open language model post-training. InSecond Conference on Language Modeling, 2025. URLhttps://openreview.net/forum?id=i1uGbfHHpH
2025
-
[44]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforce- ment learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
OpenAI Claims DeepSeek Distilled US Models to Gain an Edge, 2026
Bloomberg. OpenAI Claims DeepSeek Distilled US Models to Gain an Edge, 2026. https://www.bloomberg.com/news/articles/2026-02-12/ openai-accuses-deepseek-of-distilling-us-models-to-gain-an-edge?
2026
-
[46]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Ren, Junxiao Song, Zhihong Shao, Wanjia Zhao, Haocheng Wang, Bo Liu, Liyue Zhang, Xuan Lu, Qiushi Du, , et al
Huajian Xin, Z.Z. Ren, Junxiao Song, Zhihong Shao, Wanjia Zhao, Haocheng Wang, Bo Liu, Liyue Zhang, Xuan Lu, Qiushi Du, , et al. Deepseek-prover-v1.5: Harnessing proof assistant feedback for reinforcement learning and monte-carlo tree search. InThe Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=...
2025
-
[48]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InThe Twelfth International Conference on Learning Representations,
-
[49]
URLhttps://openreview.net/forum?id=3zKtaqxLhW
-
[50]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Beyond verifiable rewards: Scaling reinforcement learning in language models to unverifiable data
Yunhao Tang, Sid Wang, Lovish Madaan, and Remi Munos. Beyond verifiable rewards: Scaling reinforcement learning in language models to unverifiable data. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview. net/forum?id=pc6M9h3T9m
2026
-
[52]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Cody Blakeney, Jessica Zosa Forde, Jonathan Frankle, Ziliang Zong, and Matthew L Leav- itt. Reduce, reuse, recycle: Improving training efficiency with distillation.arXiv preprint arXiv:2211.00683, 2022
-
[54]
Scaling collapse reveals universal dynamics in compute-optimally trained neural networks
Shikai Qiu, Lechao Xiao, Andrew Gordon Wilson, Jeffrey Pennington, and Atish Agarwala. Scaling collapse reveals universal dynamics in compute-optimally trained neural networks. InForty-second International Conference on Machine Learning, 2025. URL https:// openreview.net/forum?id=Fvq9ogLnLN
2025
-
[55]
4+3 phases of compute-optimal neural scaling laws.Advances in Neural Information Processing Systems, 37:16459–16537, 2024
Elliot Paquette, Courtney Paquette, Lechao Xiao, and Jeffrey Pennington. 4+3 phases of compute-optimal neural scaling laws.Advances in Neural Information Processing Systems, 37:16459–16537, 2024
2024
-
[56]
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, et al. 2 OLMo 2 Furious, 2024. URL https://arxiv.org/abs/2501.00656
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Yedi Zhang, Andrew M Saxe, and Peter E. Latham. Saddle-to-saddle dynamics explains a simplicity bias across neural network architectures. InThe Fourteenth International Con- ference on Learning Representations, 2026. URL https://openreview.net/forum?id= Vit5M0G5Gb
2026
-
[58]
Sgd learning on neural networks: leap complexity and saddle-to-saddle dynamics
Emmanuel Abbe, Enric Boix Adsera, and Theodor Misiakiewicz. Sgd learning on neural networks: leap complexity and saddle-to-saddle dynamics. InThe Thirty Sixth Annual Conference on Learning Theory, pages 2552–2623. PMLR, 2023
2023
-
[59]
Arthur Jacot, François Ged, Berfin ¸ Sim¸ sek, Clément Hongler, and Franck Gabriel. Saddle-to- saddle dynamics in deep linear networks: Small initialization training, symmetry, and sparsity. arXiv preprint arXiv:2106.15933, 2021
-
[60]
Alternating gradient flows: A theory of feature learning in two-layer neural networks
Daniel Kunin, Giovanni Luca Marchetti, Feng Chen, Dhruva Karkada, James B Simon, Michael R DeWeese, Surya Ganguli, and Nina Miolane. Alternating gradient flows: A theory of feature learning in two-layer neural networks. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum? id=t7LKc0MMW6
2026
-
[61]
Measuring forgetting of memorized training examples
Matthew Jagielski, Om Thakkar, Florian Tramer, Daphne Ippolito, Katherine Lee, Nicholas Carlini, Eric Wallace, Shuang Song, Abhradeep Guha Thakurta, Nicolas Papernot, and Chiyuan Zhang. Measuring forgetting of memorized training examples. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum? id=7bJizxLKrR
2023
-
[62]
The secret sharer: Evaluating and testing unintended memorization in neural networks
Nicholas Carlini, Chang Liu, Úlfar Erlingsson, Jernej Kos, and Dawn Song. The secret sharer: Evaluating and testing unintended memorization in neural networks. In28th USENIX Security Symposium (USENIX Security 19), pages 267–284, Santa Clara, CA, August 2019. USENIX 14 Association. ISBN 978-1-939133-06-9. URL https://www.usenix.org/conference/ usenixsecur...
2019
-
[63]
Demystifying verbatim memorization in large language models
Jing Huang, Diyi Yang, and Christopher Potts. Demystifying verbatim memorization in large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 10711–10732, 2024
2024
-
[64]
Gummadi, Willie Neiswanger, and Robin Jia
Johnny Wei, Ameya Godbole, Mohammad Aflah Khan, Ryan Yixiang Wang, Xiaoyuan Zhu, James Flemings, Nitya Kashyap, Krishna P. Gummadi, Willie Neiswanger, and Robin Jia. Hubble: a model suite to advance the study of LLM memorization. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=ZfdnZhOP0k
2026
-
[65]
Intrinsic task symmetry drives generalization in algorith- mic tasks, 2026
Hyeonbin Hwang and Yeachan Park. Intrinsic task symmetry drives generalization in algorith- mic tasks, 2026. URLhttps://arxiv.org/abs/2603.01968
-
[66]
Dolma: An Open Corpus of Three Trillion Tokens for Language Model Pretraining Research.arXiv preprint,
Luca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi Chandu, Jennifer Dumas, Yanai Elazar, et al. Dolma: An Open Corpus of Three Trillion Tokens for Language Model Pretraining Research.arXiv preprint,
-
[67]
URLhttps://huggingface.co/datasets/allenai/dolma
-
[68]
Extrinsic evaluation of cultural competence in large language models
Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, et al. OLMo: Accelerating the science of language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15789–15809, Bangkok, Thaila...
-
[69]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets.arXiv preprint arXiv:2201.02177, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[70]
Progress measures for grokking via mechanistic interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability. InThe Eleventh International Confer- ence on Learning Representations, sep 2022. URL https://openreview.net/forum?id= 9XFSbDPmdW
2022
-
[71]
Pre-trained large language models use fourier features to compute addition
Tianyi Zhou, Deqing Fu, Vatsal Sharan, and Robin Jia. Pre-trained large language models use fourier features to compute addition. InThe Thirty-eighth Annual Conference on Neu- ral Information Processing Systems, 2024. URL https://openreview.net/forum?id= i4MutM2TZb
2024
-
[72]
Arithmetic in the wild: Llama uses base-10 addition to reason about cyclic concepts,
Sheridan Feucht, Tal Haklay, Usha Bhalla, Daniel Wurgaft, Can Rager, Raphaël Sarfati, Jack Merullo, Thomas McGrath, Owen Lewis, Ekdeep Singh Lubana, Thomas Fel, and Atticus Geiger. Arithmetic in the wild: Llama uses base-10 addition to reason about cyclic concepts,
-
[73]
URLhttps://arxiv.org/abs/2605.01148
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
Finding alignments between interpretable causal variables and distributed neural representations
Atticus Geiger, Zhengxuan Wu, Christopher Potts, Thomas Icard, and Noah Goodman. Finding alignments between interpretable causal variables and distributed neural representations. In Francesco Locatello and Vanessa Didelez, editors,Proceedings of the Third Conference on Causal Learning and Reasoning, volume 236 ofProceedings of Machine Learning Research, p...
2024
-
[75]
Does learning require memorization? a short tale about a long tail
Vitaly Feldman. Does learning require memorization? a short tale about a long tail. In Proceedings of the 52nd annual ACM SIGACT symposium on theory of computing, pages 954–959, 2020
2020
-
[76]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020. 15
2020
-
[77]
Data selection for language models via importance resampling.Advances in Neural Information Processing Systems, 36:34201–34227, 2023
Sang Michael Xie, Shibani Santurkar, Tengyu Ma, and Percy S Liang. Data selection for language models via importance resampling.Advances in Neural Information Processing Systems, 36:34201–34227, 2023
2023
-
[78]
Doremi: Optimizing data mixtures speeds up language model pretraining.Advances in Neural Information Processing Systems, 36, 2024
Sang Michael Xie, Hieu Pham, Xuanyi Dong, Nan Du, Hanxiao Liu, Yifeng Lu, Percy S Liang, Quoc V Le, Tengyu Ma, and Adams Wei Yu. Doremi: Optimizing data mixtures speeds up language model pretraining.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[79]
Stanford University, 2024
Sang Michael Xie.Foundation Models from a Data-Distributional View. Stanford University, 2024
2024
-
[80]
A picture of the space of typical learnable tasks.arXiv preprint arXiv:2210.17011, 2022
Rahul Ramesh, Jialin Mao, Itay Griniasty, Rubing Yang, Han Kheng Teoh, Mark Transtrum, James P Sethna, and Pratik Chaudhari. A picture of the space of typical learnable tasks.arXiv preprint arXiv:2210.17011, 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.