LoRA-Key: User-Centric LoRA Watermarking for Text-to-Image Diffusion Models
Pith reviewed 2026-06-29 06:37 UTC · model grok-4.3
The pith
A reusable Watermark LoRA carries a secret message that attaches to any target LoRA by linear addition, enabling ownership checks without retraining each module.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
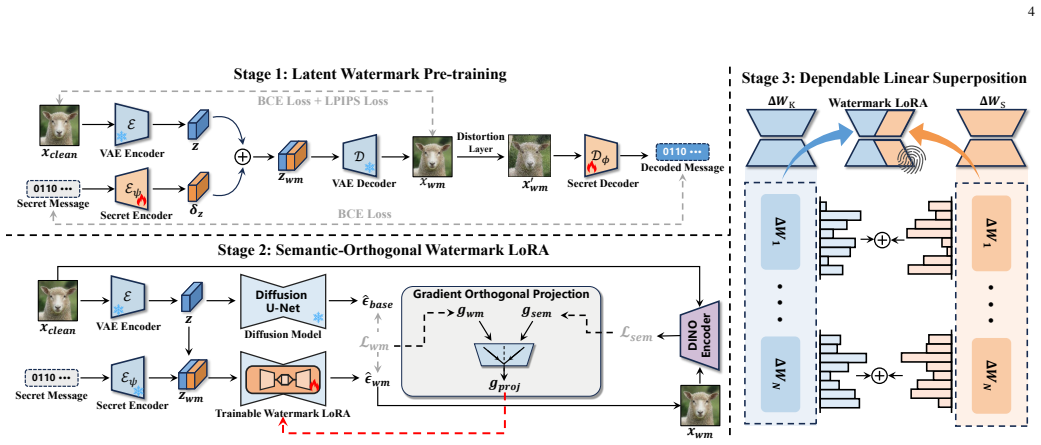
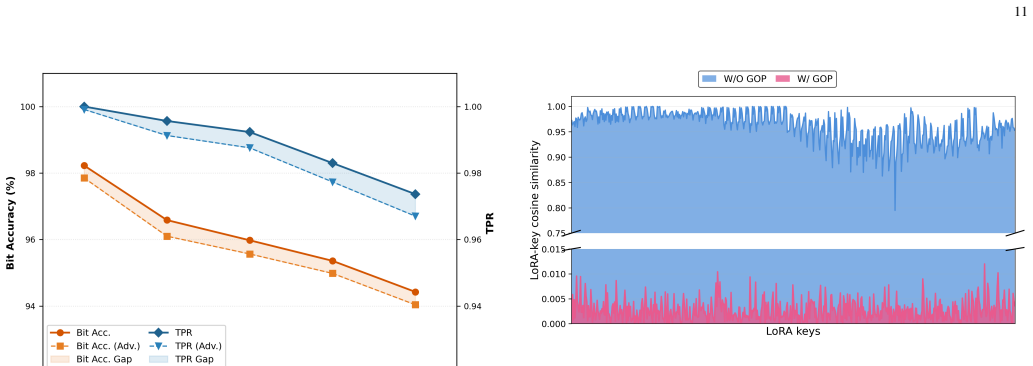
LoRA-Key encapsulates a recoverable secret message into a standalone user-specific Watermark LoRA, which can be attached to different target LoRAs through training-free linear superposition without per-LoRA retraining or structural modification. Training first sets a latent watermark prior in the frozen VAE latent space, then optimizes the Watermark LoRA using message-conditioned supervision and semantic consistency constraints. Gradient Orthogonal Projection suppresses updates that conflict with semantic directions.
What carries the argument
The Watermark LoRA optimized in the frozen VAE latent space with message-conditioned supervision and Gradient Orthogonal Projection to limit interference.
If this is right
- Ownership verification works on images from any composed LoRA without additional training steps.
- Generation quality and style fidelity remain preserved after the linear addition.
- The method supports multi-LoRA composition while keeping robust message recovery.
- Verification holds under image-level distortions and downstream fine-tuning of the combined modules.
Where Pith is reading between the lines
- A single Watermark LoRA could serve as a reusable key across an entire user's collection of target LoRAs.
- LoRA sharing platforms could require or support this form of attachment for automated ownership checks.
- The same linear-superposition pattern might apply to other low-rank adapters outside text-to-image diffusion.
Load-bearing premise
The hidden message placed in the VAE latent space stays detectable after the Watermark LoRA is added to an arbitrary unrelated target LoRA.
What would settle it
Generate images from a Watermark LoRA linearly added to a target LoRA never encountered in training and check whether the secret message can still be recovered at high accuracy.
Figures


read the original abstract
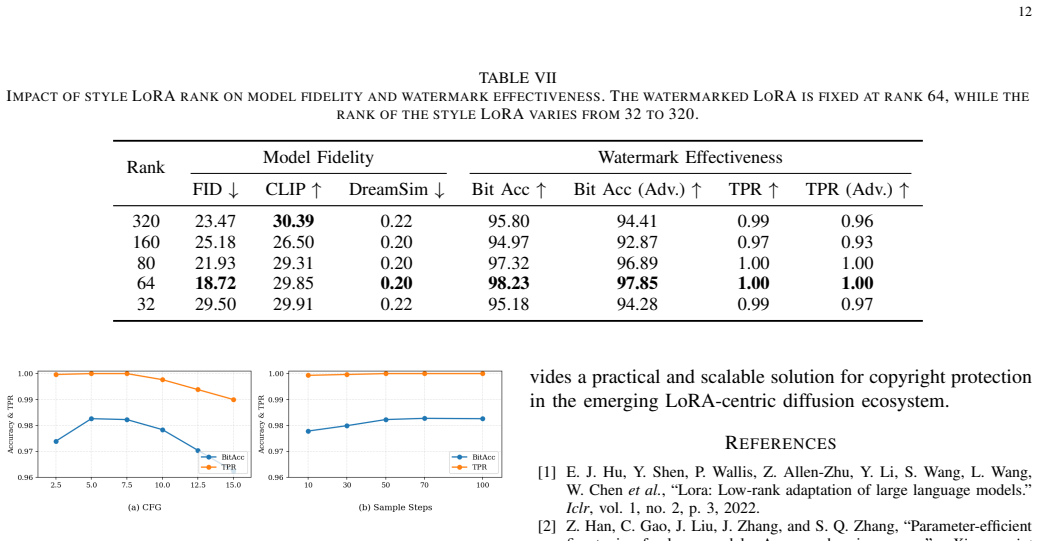
Low-Rank Adaptation (LoRA) has become a widely used mechanism for customizing text-to-image diffusion models, enabling lightweight modules that are shared, reused, and commercialized as independent assets. This LoRA-centric ecosystem shifts copyright protection from foundation models to distributed LoRA modules, which are easy to copy, redistribute, or reuse without authorization. Existing watermarking methods either protect the base diffusion model or require watermark-aware retraining for each target LoRA, limiting their practicality in open community settings. To address this limitation, we propose LoRA-Key, a user-centric LoRA watermarking framework that treats copyright protection as a reusable ownership key. LoRA-Key encapsulates a recoverable secret message into a standalone user-specific Watermark LoRA, which can be attached to different target LoRAs through training-free linear superposition without per-LoRA retraining or structural modification. To train such a reusable key, we first establish a latent watermark prior in the frozen VAE latent space for robust message embedding and recovery, and then optimize the Watermark LoRA with message-conditioned watermark supervision and semantic consistency constraints. We further introduce Gradient Orthogonal Projection (GOP) to suppress watermark updates that conflict with semantic-preserving directions, reducing interference with generation fidelity and downstream style adaptation. Extensive experiments show that LoRA-Key provides lightweight plug-and-play copyright protection while preserving generation quality and style fidelity, and maintains robust ownership verification under image-level distortions, downstream fine-tuning, and multi-LoRA composition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LoRA-Key, a framework that embeds a recoverable secret message into a standalone user-specific Watermark LoRA. This Watermark LoRA is trained once using a latent watermark prior in frozen VAE space plus message-conditioned supervision and Gradient Orthogonal Projection (GOP); it can then be attached to arbitrary target LoRAs via training-free linear weight superposition for ownership verification without per-LoRA retraining or structural changes. The abstract asserts that the method preserves generation quality, resists image distortions and downstream fine-tuning, and supports multi-LoRA composition.
Significance. If the core robustness claim holds, the work supplies a reusable, plug-and-play ownership mechanism tailored to the LoRA-centric ecosystem of diffusion models, addressing a practical gap left by methods that require watermark-aware retraining of each target module. The training-free superposition and GOP regularization are potentially useful design choices for minimizing interference.
major comments (2)
- [Abstract / Method] Abstract and method description: the central claim that message recovery remains reliable after training-free linear superposition with arbitrary unseen target LoRAs rests on the unverified assumption that the VAE latent watermark prior stays within its learned support after the combined weight update. The optimization constrains the Watermark LoRA only in isolation; no term in the loss or GOP explicitly regularizes against the distribution shift induced by an arbitrary target LoRA in weight space. This is load-bearing for the 'plug-and-play' property and requires either a supporting analysis or targeted experiments measuring recovery rates across diverse target LoRAs.
- [Abstract] Abstract: the statement of 'extensive experiments' demonstrating robustness under distortions, fine-tuning, and multi-LoRA composition is not accompanied by quantitative tables, ablation results, or dataset/metric details in the provided description. Without these, the empirical support for the robustness and fidelity claims cannot be evaluated.
minor comments (2)
- [Method] Clarify the precise definition and implementation of the latent watermark prior (e.g., how the message is encoded into VAE latents and the exact recovery procedure).
- [Method] Specify the rank and initialization of the Watermark LoRA relative to typical target LoRAs to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below with clarifications and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method description: the central claim that message recovery remains reliable after training-free linear superposition with arbitrary unseen target LoRAs rests on the unverified assumption that the VAE latent watermark prior stays within its learned support after the combined weight update. The optimization constrains the Watermark LoRA only in isolation; no term in the loss or GOP explicitly regularizes against the distribution shift induced by an arbitrary target LoRA in weight space. This is load-bearing for the 'plug-and-play' property and requires either a supporting analysis or targeted experiments measuring recovery rates across diverse target LoRAs.
Authors: We agree that the Watermark LoRA optimization occurs in isolation and that no explicit term in the loss or GOP directly constrains behavior under arbitrary target LoRA superposition. The latent watermark prior is learned in frozen VAE space to provide a stable embedding, and GOP is intended to limit semantic interference, but these do not explicitly address distribution shift from unseen targets. To address this, we will add targeted experiments in the revision measuring recovery rates across a diverse set of unseen target LoRAs. revision: yes
-
Referee: [Abstract] Abstract: the statement of 'extensive experiments' demonstrating robustness under distortions, fine-tuning, and multi-LoRA composition is not accompanied by quantitative tables, ablation results, or dataset/metric details in the provided description. Without these, the empirical support for the robustness and fidelity claims cannot be evaluated.
Authors: The full manuscript includes Section 4 with quantitative tables, ablation studies, and full details on datasets, metrics, and results for robustness under distortions, fine-tuning, and multi-LoRA composition. The abstract provides a high-level summary of these findings; the supporting evidence appears in the experiments section of the complete paper. revision: no
Circularity Check
No circularity: derivation relies on independent training procedure and empirical robustness checks
full rationale
The paper introduces a new Watermark LoRA trained via message-conditioned supervision plus GOP on a frozen VAE latent prior, then claims training-free superposition works for arbitrary target LoRAs. No equation, parameter, or claim reduces the recovered message or robustness metric to a quantity defined by the method's own fitted values. No self-citation chains or uniqueness theorems are invoked to force the result. The central assumption (robustness after superposition) is presented as an empirical claim to be validated by experiments, not derived by construction from the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A latent watermark prior can be established in the frozen VAE latent space that supports robust message embedding and recovery after superposition.
invented entities (1)
-
Watermark LoRA
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” Iclr, vol. 1, no. 2, p. 3, 2022
2022
-
[2]
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Z. Han, C. Gao, J. Liu, J. Zhang, and S. Q. Zhang, “Parameter-efficient fine-tuning for large models: A comprehensive survey,”arXiv preprint arXiv:2403.14608, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Not all layers are created equal: Adaptive lora ranks for personalized image generation,
D. Shenaj, F. Errica, and A. Carta, “Not all layers are created equal: Adaptive lora ranks for personalized image generation,”arXiv preprint arXiv:2603.21884, 2026
-
[4]
Intlora: Integral low-rank adaptation of quantized diffusion models,
H. Guo, Y . Li, T. Dai, S.-T. Xia, and L. Benini, “Intlora: Integral low-rank adaptation of quantized diffusion models,”arXiv preprint arXiv:2410.21759, 2024
-
[5]
Dreambooth: Fine tuning text-to-image diffusion models for subject- driven generation,
N. Ruiz, Y . Li, V . Jampani, Y . Pritch, M. Rubinstein, and K. Aberman, “Dreambooth: Fine tuning text-to-image diffusion models for subject- driven generation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 22 500–22 510
2023
-
[6]
Multi- concept customization of text-to-image diffusion,
N. Kumari, B. Zhang, R. Zhang, E. Shechtman, and J.-Y . Zhu, “Multi- concept customization of text-to-image diffusion,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 1931–1941
2023
-
[7]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
R. Gal, Y . Alaluf, Y . Atzmon, O. Patashnik, A. H. Bermano, G. Chechik, and D. Cohen-Or, “An image is worth one word: Person- alizing text-to-image generation using textual inversion,”arXiv preprint arXiv:2208.01618, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
X. Wu, S. Huang, and F. Wei, “Mixture of lora experts,”arXiv preprint arXiv:2404.13628, 2024
-
[9]
Civitai: Open model sharing platform for generative ai,
Civitai, “Civitai: Open model sharing platform for generative ai,” https: //civitai.com, 2024, accessed: 2026-04-16
2024
-
[10]
Hugging Face, “Lora,” https://huggingface.co/docs/diffusers/training/ lora, 2024, accessed: 2026-04-28
2024
-
[11]
Transformers: State- of-the-art natural language processing,
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowiczet al., “Transformers: State- of-the-art natural language processing,”Proceedings of EMNLP: System Demonstrations, 2020
2020
-
[12]
Rethinking data protection in the (generative) artificial intelligence era,
Y . Li, S. Shao, Y . He, J. Guo, T. Zhang, Z. Qin, P.-Y . Chen, M. Backes, P. Torr, D. Taoet al., “Rethinking data protection in the (generative) artificial intelligence era,”arXiv preprint arXiv:2507.03034, 2025
-
[13]
PromptCOS: Towards Content-only System Prompt Copyright Auditing for LLMs
Y . Yang, Y . Li, H. Yao, E. Huang, S. Shao, Y . Wang, Z. Wang, D. Tao, and Z. Qin, “Promptcos: Towards content-only system prompt copyright auditing for llms,”arXiv preprint arXiv:2509.03117, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
A. Blattmann, T. Dockhorn, S. Kulal, D. Mendelevitch, M. Kilian, D. Lorenz, Y . Levi, Z. English, V . V oleti, A. Lettset al., “Stable video diffusion: Scaling latent video diffusion models to large datasets,”arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Tree-ring watermarks: Fingerprints for diffusion images that are invisible and robust,
Y . Wen, J. Kirchenbauer, J. Geiping, and T. Goldstein, “Tree-ring watermarks: Fingerprints for diffusion images that are invisible and robust,”arXiv preprint arXiv:2305.20030, 2023
-
[16]
Aqualora: Toward white-box protection for customized stable diffusion models via watermark lora,
W. Feng, W. Zhou, J. He, J. Zhang, T. Wei, G. Li, T. Zhang, W. Zhang, and N. Yu, “Aqualora: Toward white-box protection for customized stable diffusion models via watermark lora,”arXiv preprint arXiv:2405.11135, 2024
-
[17]
Sleepermark: Towards robust watermark against fine-tuning text-to- image diffusion models,
Z. Wang, J. Guo, J. Zhu, Y . Li, H. Huang, M. Chen, and Z. Tu, “Sleepermark: Towards robust watermark against fine-tuning text-to- image diffusion models,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 8213–8224. 13
2025
-
[18]
Authenlora: Entangling stylization with imperceptible watermarks for copyright-secure lora adapters,
F. Shi, L. Li, K. Chen, G. Feng, and X. Zhang, “Authenlora: Entangling stylization with imperceptible watermarks for copyright-secure lora adapters,”arXiv preprint arXiv:2511.21216, 2025
-
[19]
Towards robust model watermark via reducing parametric vulnerability,
G. Gan, Y . Li, D. Wu, and S.-T. Xia, “Towards robust model watermark via reducing parametric vulnerability,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4751–4761
2023
-
[20]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[21]
Lorahub: Efficient cross-task generalization via dynamic lora composition,
C. Huang, Q. Liu, B. Y . Lin, T. Pang, C. Du, and M. Lin, “Lorahub: Efficient cross-task generalization via dynamic lora composition,”arXiv preprint arXiv:2307.13269, 2023
-
[22]
Mix-of-show: Decentralized low-rank adap- tation for multi-concept customization of diffusion models,
Y . Gu, X. Wang, J. Z. Wu, Y . Shi, Y . Chen, Z. Fan, W. Xiao, R. Zhao, S. Chang, W. Wuet al., “Mix-of-show: Decentralized low-rank adap- tation for multi-concept customization of diffusion models,”Advances in Neural Information Processing Systems, vol. 36, pp. 15 890–15 902, 2023
2023
-
[23]
Editing Models with Task Arithmetic
G. Ilharco, M. T. Ribeiro, M. Wortsman, S. Gururangan, L. Schmidt, H. Hajishirzi, and A. Farhadi, “Editing models with task arithmetic,” arXiv preprint arXiv:2212.04089, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Ties- merging: Resolving interference when merging models,
P. Yadav, D. Tam, L. Choshen, C. A. Raffel, and M. Bansal, “Ties- merging: Resolving interference when merging models,”Advances in neural information processing systems, vol. 36, pp. 7093–7115, 2023
2023
-
[25]
Ziplora: Any subject in any style by effectively merging loras,
V . Shah, N. Ruiz, F. Cole, E. Lu, S. Lazebnik, Y . Li, and V . Jampani, “Ziplora: Any subject in any style by effectively merging loras,” in European Conference on Computer Vision. Springer, 2024, pp. 422– 438
2024
-
[26]
Lora. rar: Learning to merge loras via hypernetworks for subject-style condi- tioned image generation,
D. Shenaj, O. Bohdal, M. Ozay, P. Zanuttigh, and U. Michieli, “Lora. rar: Learning to merge loras via hypernetworks for subject-style condi- tioned image generation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 16 132–16 142
2025
-
[27]
Reading between the lines: Towards reliable black-box llm fingerprinting via zeroth-order gradient estimation,
S. Shao, Y . Li, H. Yao, Y . Chen, Y . Yang, and Z. Qin, “Reading between the lines: Towards reliable black-box llm fingerprinting via zeroth-order gradient estimation,” inProceedings of the ACM Web Conference 2026, 2026, pp. 2637–2648
2026
-
[28]
S. Shao, Y . Li, H. Yao, Y . He, Z. Qin, and K. Ren, “Explanation as a wa- termark: Towards harmless and multi-bit model ownership verification via watermarking feature attribution,”arXiv preprint arXiv:2405.04825, 2024
-
[29]
Move: Effective and harmless ownership verification via embedded external features,
Y . Li, L. Zhu, X. Jia, Y . Bai, Y . Jiang, S.-T. Xia, X. Cao, and K. Ren, “Move: Effective and harmless ownership verification via embedded external features,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[30]
Wavelet transform based watermark for digital images,
X.-G. Xia, C. G. Boncelet, and G. R. Arce, “Wavelet transform based watermark for digital images,”Optics Express, vol. 3, no. 12, pp. 497– 511, 1998
1998
-
[31]
Hidden: Hiding data with deep networks,
J. Zhu, R. Kaplan, J. Johnson, and L. Fei-Fei, “Hidden: Hiding data with deep networks,” inProceedings of the European conference on computer vision (ECCV), 2018, pp. 657–672
2018
-
[32]
I. Cox, M. Miller, J. Bloom, J. Fridrich, and T. Kalker,Digital water- marking and steganography. Morgan kaufmann, 2007
2007
-
[33]
Stegastamp: Invisible hyperlinks in physical photographs,
M. Tancik, B. Mildenhall, and R. Ng, “Stegastamp: Invisible hyperlinks in physical photographs,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2117–2126
2020
-
[34]
Robust invisible video watermarking with attention,
K. A. Zhang, L. Xu, A. Cuesta-Infante, and K. Veeramachaneni, “Robust invisible video watermarking with attention,”arXiv preprint arXiv:1909.01285, 2019
-
[35]
The stable signature: Rooting watermarks in latent diffusion models,
P. Fernandez, G. Couairon, H. J ´egou, M. Douze, and T. Furon, “The stable signature: Rooting watermarks in latent diffusion models,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 22 466–22 477
2023
-
[36]
Y . Wang, H. Xu, Z. Wang, J. Du, Z. Li, Y . Li, Q. Wang, and K. Ren, “Pt-mark: Invisible watermarking for text-to-image diffusion models via semantic-aware pivotal tuning,”arXiv preprint arXiv:2504.10853, 2025
-
[37]
Gaussian shading: Provable performance-lossless image watermarking for diffu- sion models,
Z. Yang, K. Zeng, K. Chen, H. Fang, W. Zhang, and N. Yu, “Gaussian shading: Provable performance-lossless image watermarking for diffu- sion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 12 162–12 171
2024
-
[38]
Robin: Robust and invisible water- marks for diffusion models with adversarial optimization,
H. Huang, Y . Wu, and Q. Wang, “Robin: Robust and invisible water- marks for diffusion models with adversarial optimization,”Advances in Neural Information Processing Systems, vol. 37, pp. 3937–3963, 2024
2024
-
[39]
A recipe for watermarking diffusion models,
Y . Zhao, T. Pang, C. Du, X. Yang, N.-M. Cheung, and M. Lin, “A recipe for watermarking diffusion models,”arXiv preprint arXiv:2303.10137, 2023
-
[40]
Attack-resilient image watermarking using stable diffusion,
L. Zhang, X. Liu, A. Martin, C. Bearfield, Y . Brun, and H. Guan, “Attack-resilient image watermarking using stable diffusion,”Advances in Neural Information Processing Systems, vol. 37, pp. 38 480–38 507, 2024
2024
-
[41]
Loraguard: An effective black-box watermarking approach for loras,
P. Lv, Y . Xiahou, C. Li, M. Sun, S. Zhang, K. Chen, and Y . Zhang, “Loraguard: An effective black-box watermarking approach for loras,” arXiv preprint arXiv:2501.15478, 2025
-
[42]
Seal: Entangled white-box watermarks on low-rank adaptation,
G. Oh, S. Kim, W. Cho, S. Lee, J. Chung, D. Song, and Y . Yu, “Seal: Entangled white-box watermarks on low-rank adaptation,”arXiv preprint arXiv:2501.09284, 2025
-
[43]
D. Lin, Y . Li, B. Tondi, K. Lin, B. Li, and M. Barni, “An efficient wa- termarking method for latent diffusion models via low-rank adaptation and dynamic loss weighting,”arXiv preprint arXiv:2410.20202, 2024
-
[44]
When LoRA Betrays: Backdooring Text-to-Image Models by Masquerading as Benign Adapters
L. Lyu, J. Xu, J. Ding, and Q. Deng, “When lora betrays: Backdoor- ing text-to-image models by masquerading as benign adapters,”arXiv preprint arXiv:2602.21977, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Styledrop: Text-to-image generation in any style,
K. Sohn, N. Ruiz, K. Lee, D. C. Chin, I. Blok, H. Chang, J. Barber, L. Jiang, G. Entis, Y . Liet al., “Styledrop: Text-to-image generation in any style,”arXiv preprint arXiv:2306.00983, 2023
-
[46]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[47]
Clipscore: A reference-free evaluation metric for image captioning,
J. Hessel, A. Holtzman, M. Forbes, R. Le Bras, and Y . Choi, “Clipscore: A reference-free evaluation metric for image captioning,” inProceedings of the 2021 conference on empirical methods in natural language processing, 2021, pp. 7514–7528
2021
-
[48]
DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data
S. Fu, N. Tamir, S. Sundaram, L. Chai, R. Zhang, T. Dekel, and P. Isola, “Dreamsim: Learning new dimensions of human visual similarity using synthetic data,”arXiv preprint arXiv:2306.09344, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inComputer vision–ECCV 2014: 13th European conference, zurich, Switzerland, September 6-12, 2014, proceedings, part v 13. Springer, 2014, pp. 740–755
2014
-
[50]
Diffusiondb: A large-scale prompt gallery dataset for text-to- image generative models,
Z. J. Wang, E. Montoya, D. Munechika, H. Yang, B. Hoover, and D. H. Chau, “Diffusiondb: A large-scale prompt gallery dataset for text-to- image generative models,”arXiv preprint arXiv:2210.14896, 2022
-
[51]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023. Yaopeng Wangreceived the MS degree in computer technology from Fuzhou University, China, in 2022. He is currently working toward ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
His research interests include AI security, the Internet of Things, network security, and privacy protection
He is currently a Professor at the School of Cyber Science and Technology, College of Computer Science and Technology, Zhejiang University. His research interests include AI security, the Internet of Things, network security, and privacy protection. 14 Huiyu Xureceived the B.E. degree in Information Security from Nankai University, China, in 2021. He is c...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.