PEARL: Training Socratic Tutors with Pedagogically Aligned Reinforcement Learning
Pith reviewed 2026-06-29 08:30 UTC · model grok-4.3
The pith
PEARL trains Socratic tutoring agents via reinforcement learning with controllable student simulation, generative rewards, and stable multi-objective optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
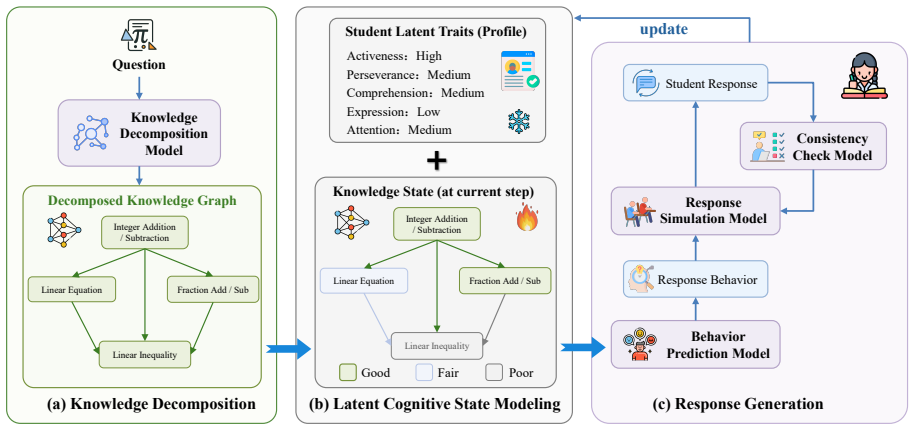
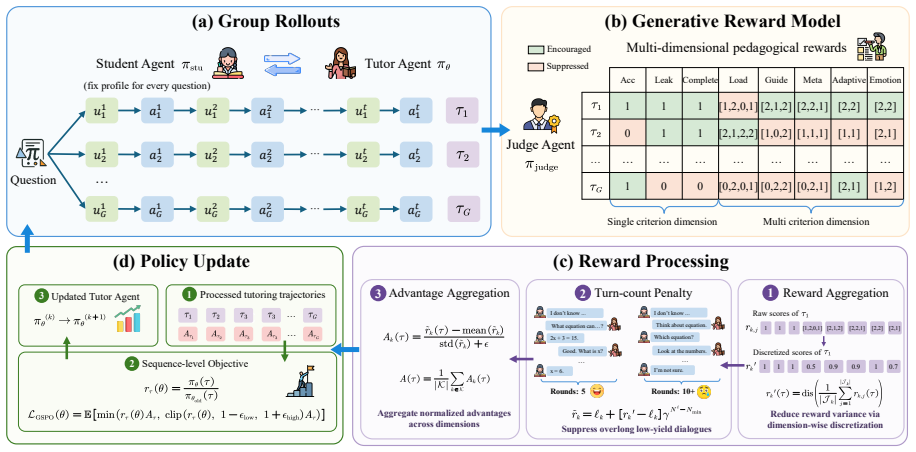
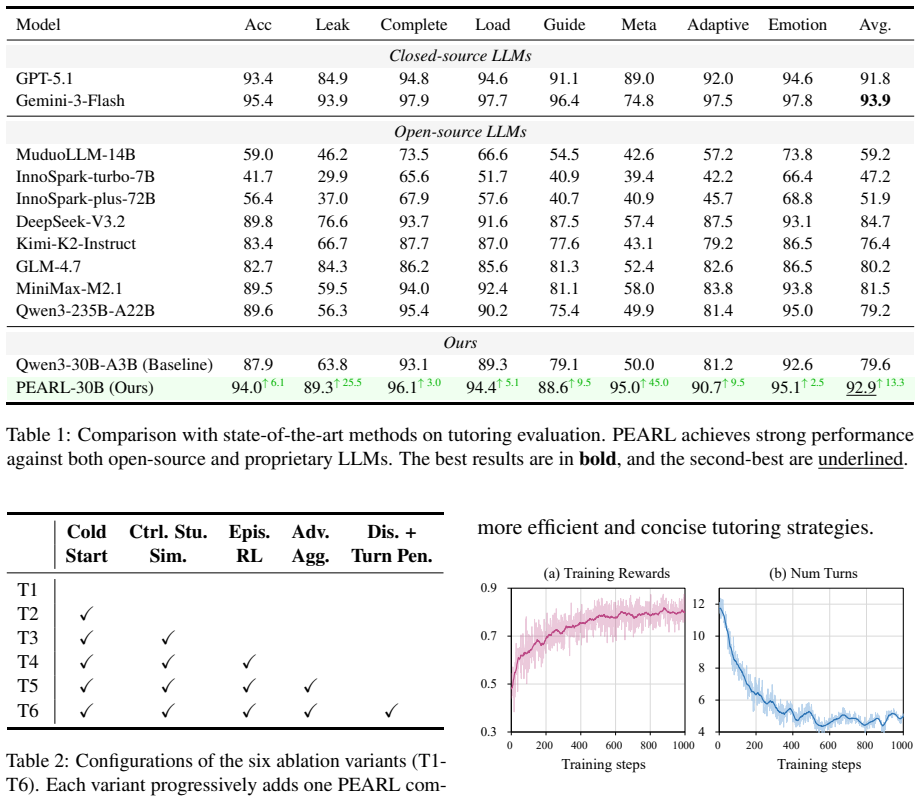
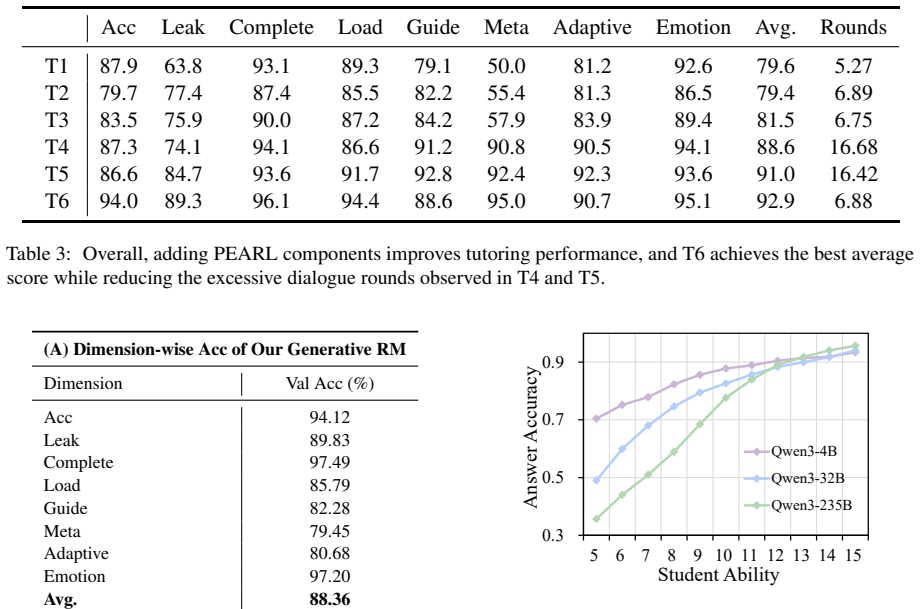
PEARL is a pedagogically aligned reinforcement learning framework consisting of a controllable student simulator that decouples latent cognitive states from response generation to model diverse abilities and misconceptions, a generative reward model that jointly evaluates pedagogical quality and objective correctness, and a stable multi-objective RL scheme that discretizes rewards within each dimension and aggregates normalized advantages across dimensions. Experiments show this produces tutoring agents that achieve the best performance among open-source models and remain competitive with leading proprietary LLMs despite using only a 30B policy model.
What carries the argument
The stable multi-objective RL scheme that discretizes rewards within each dimension and aggregates normalized advantages across dimensions to prevent high-variance objectives from dominating policy updates.
If this is right
- Open-source 30B models can reach performance levels comparable to much larger proprietary systems on multi-turn tutoring tasks.
- Socratic guidance can be optimized across multiple pedagogical objectives without one objective dominating the training signal.
- Decoupling cognitive states from response generation in simulators enables more diverse and controllable modeling of student errors.
- Generative reward models can supply joint signals for both factual accuracy and teaching strategy in policy optimization.
Where Pith is reading between the lines
- The separation of simulation and reward modeling could extend to training agents for other multi-turn tasks that require balanced objectives, such as negotiation or diagnostic dialogue.
- Deployments would benefit from periodic recalibration of the student simulator against fresh interaction logs to maintain alignment with evolving learner populations.
- The discretization step in the RL scheme might reduce sensitivity to reward scale differences, suggesting similar normalization tactics could stabilize other multi-objective RL applications in dialogue systems.
Load-bearing premise
The controllable student simulator must accurately capture real-world student abilities and misconceptions while the generative reward model must reliably measure pedagogical quality.
What would settle it
Direct comparison of PEARL-trained tutors against baselines in live sessions with human students, using metrics such as measured learning gains or independent human ratings of guidance quality, would falsify the claim if the trained agents show no advantage.
Figures



read the original abstract
Large Language Models (LLMs) have shown promise as educational tutors, yet effective tutoring requires more than solving problems: it must provide progressive Socratic guidance and balance multiple pedagogical objectives across multi-turn interactions. However, training such tutors remains challenging due to limited-fidelity and weakly controllable student simulation, under-specified pedagogical reward modeling, and unstable multi-objective optimization. To overcome these limitations, we propose PEARL, a pedagogically aligned reinforcement learning framework for training Socratic tutoring agents, consisting of three key components. First, we introduce a controllable student simulator that decouples latent cognitive states from response generation to model diverse abilities and misconceptions. Second, we develop a generative reward model that jointly evaluates pedagogical quality and objective correctness for policy optimization. Finally, we propose a stable multi-objective RL scheme that discretizes rewards within each dimension and aggregates normalized advantages across dimensions, preventing high-variance objectives from dominating updates. Experiments on multiple benchmarks show that PEARL achieves the best performance among open-source models and remains competitive with leading proprietary LLMs, despite using only a 30B policy model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PEARL, a pedagogically aligned RL framework for training Socratic tutoring LLMs. It introduces three components: (1) a controllable student simulator decoupling latent cognitive states from response generation, (2) a generative reward model jointly scoring pedagogical quality and correctness, and (3) a stable multi-objective RL scheme using per-dimension reward discretization and normalized advantage aggregation. The central claim is that the resulting 30B policy model achieves the best performance among open-source models and remains competitive with leading proprietary LLMs on multiple benchmarks.
Significance. If the simulator and reward model prove faithful to real tutoring dynamics, the work would meaningfully advance controllable training of multi-turn educational agents by providing a concrete recipe for balancing pedagogical objectives without high-variance collapse. The emphasis on a relatively compact 30B policy model reaching competitive results would also be a practical contribution if externally validated.
major comments (2)
- [Abstract] Abstract: The strongest claim (best open-source performance, competitive with proprietary LLMs) is load-bearing on the fidelity of the controllable student simulator and generative reward model, yet the manuscript supplies no external validation—e.g., correlation of simulated trajectories with real learner data or inter-rater agreement between the generative reward and human pedagogical experts. Without such checks, the stable multi-objective RL scheme may optimize simulator artifacts rather than actual tutoring quality.
- [Abstract] Abstract / Experiments: No experimental details, baselines, error bars, or statistical tests are described, so the benchmark superiority claim cannot be evaluated from the provided information; this directly undermines assessment of whether the three-component framework delivers the reported gains.
minor comments (2)
- Notation for the latent state decoupling and reward discretization should be introduced with explicit equations rather than prose descriptions to allow reproducibility.
- [Abstract] The abstract would benefit from naming the specific benchmarks and the exact open-source and proprietary comparators used.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of validating the simulator and reward model, as well as for noting the need for clearer experimental reporting. We agree these points strengthen the manuscript and will revise accordingly while maintaining the core contributions of the PEARL framework.
read point-by-point responses
-
Referee: [Abstract] Abstract: The strongest claim (best open-source performance, competitive with proprietary LLMs) is load-bearing on the fidelity of the controllable student simulator and generative reward model, yet the manuscript supplies no external validation—e.g., correlation of simulated trajectories with real learner data or inter-rater agreement between the generative reward and human pedagogical experts. Without such checks, the stable multi-objective RL scheme may optimize simulator artifacts rather than actual tutoring quality.
Authors: We acknowledge that external validation against real learner trajectories or human expert ratings would provide stronger support for the claims. The manuscript emphasizes the design of the controllable simulator (decoupling latent states) and generative reward model to address known limitations in prior work, with end-to-end gains demonstrated via benchmark performance. However, we agree this is a substantive gap. In revision we will add an explicit limitations subsection discussing the absence of direct correlation studies (due to privacy constraints on real student data) and include any internal consistency metrics already computed during development. We will also outline plans for future human validation studies. revision: partial
-
Referee: [Abstract] Abstract / Experiments: No experimental details, baselines, error bars, or statistical tests are described, so the benchmark superiority claim cannot be evaluated from the provided information; this directly undermines assessment of whether the three-component framework delivers the reported gains.
Authors: The full manuscript contains a complete Experiments section (Section 4) specifying the benchmarks, baselines (open-source and proprietary models), evaluation protocol, and results. Tables and figures include error bars from multiple random seeds and statistical significance tests. The abstract is a high-level summary and omits these details by convention. We will revise to improve clarity by adding a brief experimental overview paragraph in the introduction or abstract and ensuring all statistical reporting is highlighted in the Experiments section. revision: yes
Circularity Check
No circularity: new framework proposal validated empirically
full rationale
The paper introduces three new components (controllable student simulator decoupling latent states, generative reward model for pedagogical+correctness evaluation, and discretized multi-objective RL with normalized advantages) as a proposed solution to stated limitations in tutoring LLMs. Performance is assessed via experiments on benchmarks rather than any derivation, equation, or prediction that reduces to fitted inputs or self-citations by construction. No load-bearing step matches the enumerated circularity patterns; the abstract and description present an independent methodological contribution whose claims rest on external benchmark results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631. Giulia Bonino, Gabriele Sanmartino, Giovanni Gatti Pinheiro, Paolo Papotti, Raphaël Troncy, and Pietro Michiardi. 2024. Euler: Fine-tuning a large language model for socratic interactions.AIxEDU@ AI* IA, 3879. Qikai Chang, Zhenrong Zhang, Pengfei Hu, Jun Du, Jiefeng Ma, Yicheng Pan, Jianshu Zhang,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
InProceedings of the 2025 Con- ference on Empirical Methods in Natural Language Processing, pages 272–292
From problem-solving to teaching problem- solving: Aligning llms with pedagogy using rein- forcement learning. InProceedings of the 2025 Con- ference on Empirical Methods in Natural Language Processing, pages 272–292. Weibo Gao, Qi Liu, Linan Yue, Fangzhou Yao, Rui Lv, Zheng Zhang, Hao Wang, and Zhenya Huang
2025
-
[3]
InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 23923–23932
Agent4edu: Generating learner response data by generative agents for intelligent education systems. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 23923–23932. Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, and 1 others. 2024. A survey on llm-as...
2024
-
[4]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. 9 Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Ja- cob Steinhardt. 2021. Measuring mathematical prob- lem solving with the math dataset.arXiv preprint arXiv:2103.03874. Xiangen Hu, Sheng Xu, Richard Tong, and Art Graesser
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[5]
Mei Jiang, Haihai Shen, Zhuo Luo, Bingdong Li, Wen- jing Hong, Ke Tang, and Aimin Zhou
Generative ai in education: From foundational insights to the socratic playground for learning.arXiv preprint arXiv:2501.06682. Mei Jiang, Haihai Shen, Zhuo Luo, Bingdong Li, Wen- jing Hong, Ke Tang, and Aimin Zhou. 2025. Evo- lutionary reinforcement learning based ai tutor for socratic interdisciplinary instruction.arXiv preprint arXiv:2512.11930. Angéli...
-
[6]
Proximal Policy Optimization Algorithms
IEEE. David Rein, Betty Li Hou, Asa Cooper Stickland, Jack- son Petty, Richard Yuanzhe Pang, Julien Dirani, Ju- lian Michael, and Samuel R Bowman. 2024. Gpqa: A graduate-level google-proof q&a benchmark. In First conference on language modeling. Alexander Scarlatos, Naiming Liu, Jaewook Lee, Richard Baraniuk, and Andrew Lan. 2025. Train- ing llm-based tut...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Opportunities and challenges of llms in education: An nlp perspective.arXiv preprint arXiv:2507.22753. William Villegas-Ch, Diego Buenano-Fernandez, Alexandra Maldonado Navarro, and Aracely Mera- Navarrete. 2025. Adaptive intelligent tutoring sys- tems for stem education: analysis of the learning impact and effectiveness of personalized feedback: W. ville...
-
[8]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Ad- vances in Neural Information Processing Systems, 37:95266–95290. Shou’ang Wei, Xinyun Wang, Shuzhen Bi, Jian Chen, Ruijia Li, Bo Jiang, Xin Lin, Min Zhang, Yu Song, BingDong Li, and 1 others. 2025. Elmes: An au- tomated framework for evaluating large language models in...
-
[9]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, and 1 others. 2025. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476. Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, B...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Qiannan Zhu, ZeChen Li, Yang Zhang, Xuetao Ma, Wei- hao You, Mei Wang, Ting Zhang, Jinfeng Bai, Jian Li, 11 Hua Huang, and Mi Tian
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Qiannan Zhu, ZeChen Li, Yang Zhang, Xuetao Ma, Wei- hao You, Mei Wang, Ting Zhang, Jinfeng Bai, Jian Li, 11 Hua Huang, and Mi Tian. 2025. Muduollm: A high- performance llm for intelligent education solutions. https://huggingface.co/E...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.