VLAConf: Calibrated Task-Success Confidence for Vision-Language-Action Models
Pith reviewed 2026-06-29 06:52 UTC · model grok-4.3
The pith
VLAConf adds a lightweight head to frozen vision-language-action models to score task success in one forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
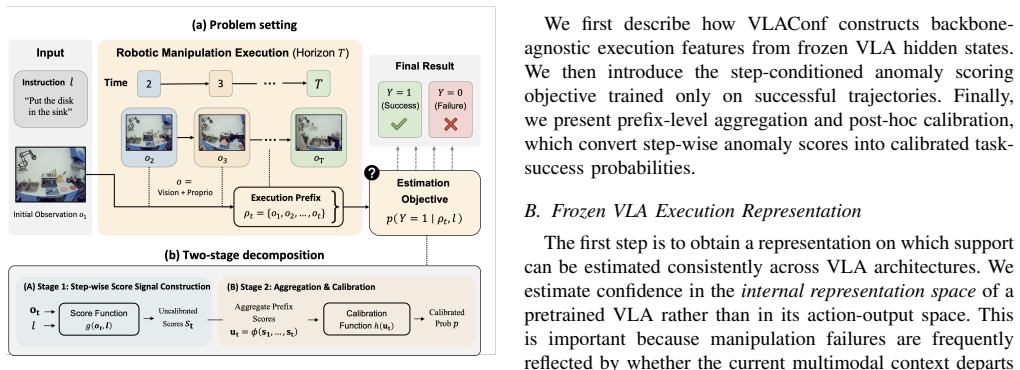
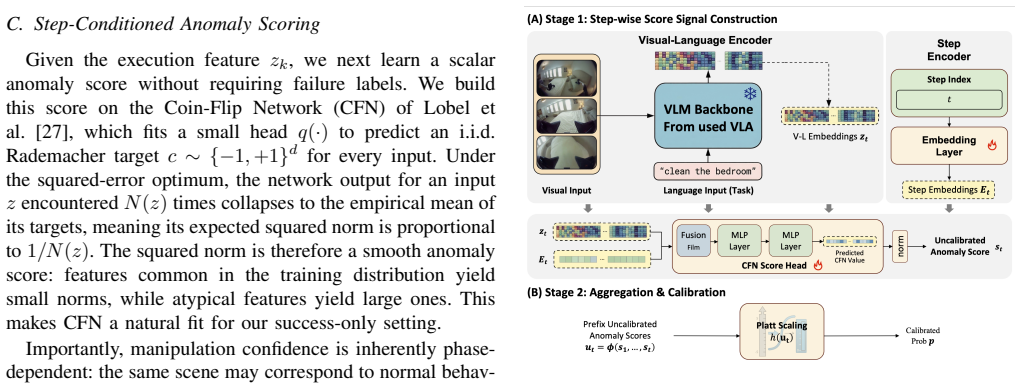
By passing the frozen internal representations of a pretrained VLA through a step-conditioned lightweight discriminative head, VLAConf produces calibrated task-success directly from a single forward pass, removing the need for repeated sampling and extending to continuous action spaces.
What carries the argument
A lightweight one-class discriminative head trained on frozen VLA internal representations that outputs step-wise anomaly scores conditioned on rollout phase.
If this is right
- Robots can obtain usable success estimates without ensembles or repeated sampling, enabling faster risk-aware planning.
- The method applies to both discrete and continuous action VLA architectures because it does not rely on token probabilities.
- Step-conditioned modeling along trajectories supplies phase-aware signals that improve calibration over unconditioned baselines.
- Post-hoc calibration of the produced scores becomes more effective because the raw anomaly scores already separate success and failure more cleanly.
Where Pith is reading between the lines
- If the same head can be trained once and reused across different VLA backbones without retraining, deployment cost for new robots drops further.
- The approach suggests that other internal-state signals (attention maps, value estimates) might also be turned into cheap anomaly detectors for failure anticipation.
- Real-world deployment would still require checking whether the head trained on simulation data transfers when the robot encounters new objects or lighting.
Load-bearing premise
The internal states already produced by a frozen pretrained VLA contain enough information to separate successful from unsuccessful task steps once a small additional head is trained on them.
What would settle it
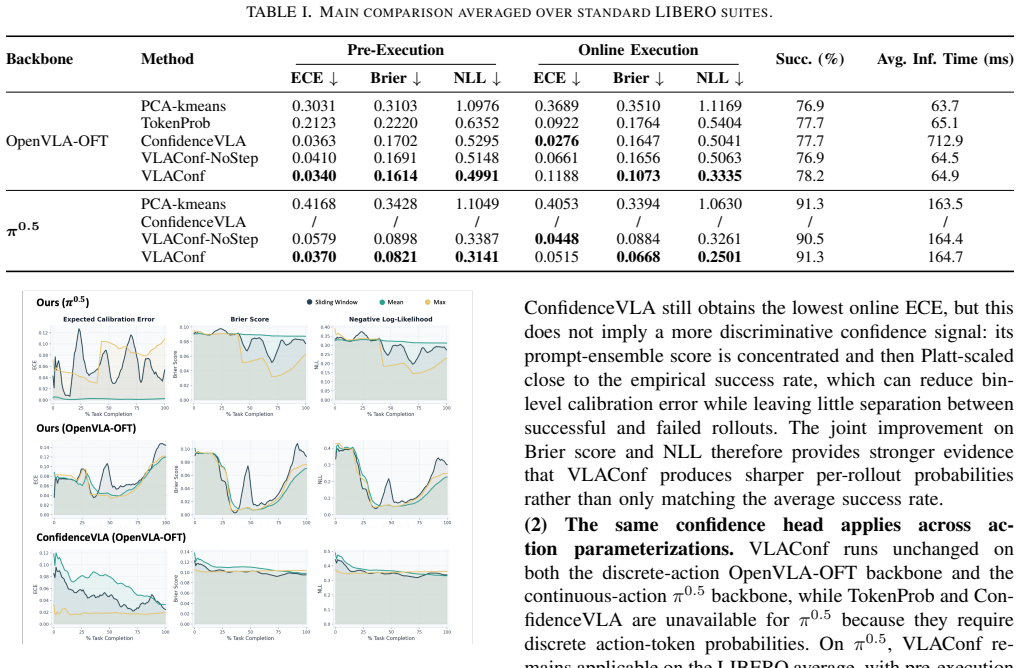
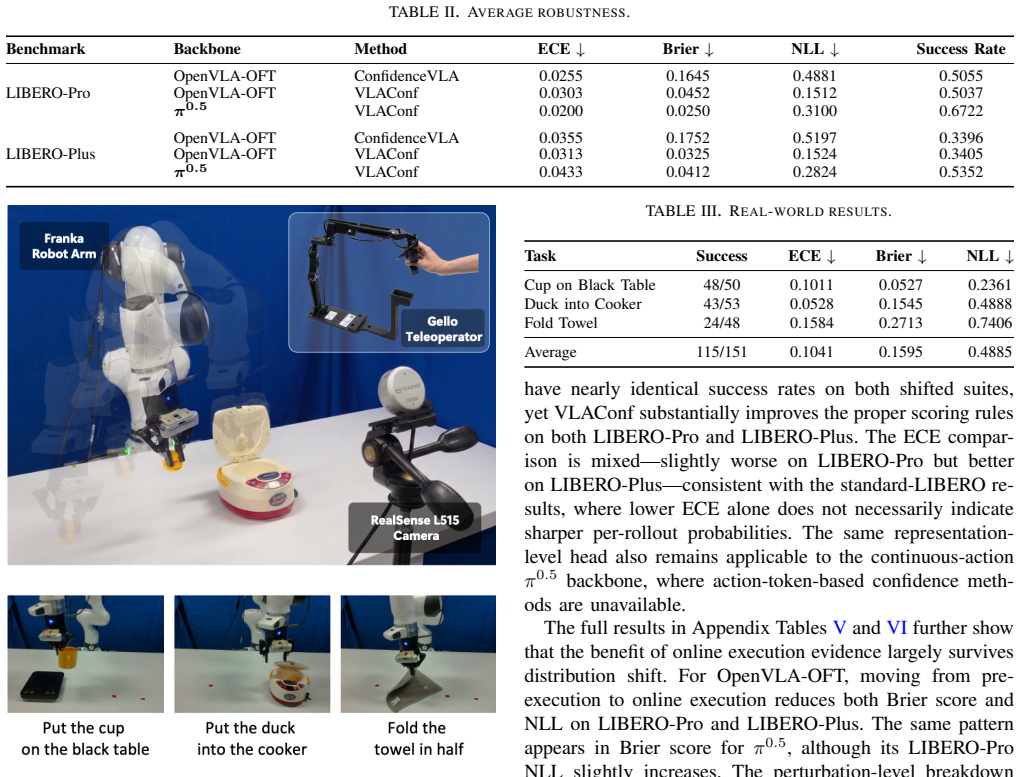
On the LIBERO benchmark, if the calibration metrics (such as expected calibration error) achieved by VLAConf do not exceed those of ensemble and token-probability baselines while also showing lower inference time, the central efficiency and quality claim does not hold.
Figures

read the original abstract
Confidence estimation for Vision-Language-Action (VLA) models is essential for robots to perform manipulation tasks in the open world, providing crucial signals for risk-sensitive decision-making and failure anticipation. Existing confidence estimation methods typically rely on ensemble-based paradigms or action-token probabilities to predict the likelihood of task success. However, they still encounter challenges in computational efficiency and cross-architecture generalizability. These methods usually require repeated sampling, leading to inference inefficiency, and are restricted to VLA models with discrete action outputs, making them difficult to apply to continuous action spaces. To address this issue, we propose VLAConf, a one-class discriminative confidence framework. By leveraging frozen pretrained VLA internal representations, VLAConf directly estimates step-wise anomaly scores in a single forward pass using a lightweight confidence head, thereby eliminating the overhead of exhaustive resampling. We additionally use step-conditioned modeling to encode rollout-phase information along the manipulation trajectory. Experiments on the LIBERO benchmark demonstrate that VLAConf significantly improves the quality of the confidence signal constructed for post-hoc calibration, outperforming existing baselines by a large margin in inference efficiency. The effectiveness of VLAConf is further validated in real-robot experiments. To access the source code and supplementary videos, visit https://sites.google.com/view/vlaconf.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VLAConf, a one-class discriminative confidence framework for Vision-Language-Action (VLA) models. It trains a lightweight head on frozen pretrained VLA internal representations to output step-wise anomaly scores in a single forward pass, incorporating step-conditioned modeling to capture rollout-phase information. The central claim is that this yields a higher-quality confidence signal for post-hoc calibration than existing ensemble or action-probability baselines, with large gains in inference efficiency on the LIBERO benchmark and validation in real-robot experiments; the method is positioned as applicable to continuous action spaces without repeated sampling.
Significance. If the empirical claims hold with proper quantitative support, VLAConf would provide an efficient, architecture-agnostic route to calibrated confidence for VLAs, removing the need for resampling and extending to continuous actions. This could directly benefit risk-aware robotic planning and failure anticipation in open-world manipulation.
major comments (2)
- [Abstract and §4] Abstract and §4 (results): the claim of 'significantly improves the quality of the confidence signal' and 'outperforming existing baselines by a large margin' is load-bearing for the contribution, yet the abstract and visible text supply no numerical values, baseline names, AUC/ECE deltas, statistical tests, or error bars on LIBERO; without these the central empirical claim cannot be evaluated.
- [§3] §3 (method) and skeptic concern: the framework rests on the assumption that frozen VLA activations already separate successful from unsuccessful executions sufficiently for a lightweight one-class head to produce usable anomaly scores. No ablation, t-SNE visualization, or linear-probe analysis is referenced showing that this separation exists prior to head training; if the representations primarily encode action prediction rather than outcome, the single-pass efficiency advantage collapses.
minor comments (2)
- [Abstract] The abstract states 'To access the source code...' but the manuscript should include a direct GitHub link or reproducibility statement in the main text rather than only a project page.
- [§3] Notation for the anomaly score and step-conditioned input should be defined once with consistent symbols (e.g., avoid switching between 'anomaly score' and 'confidence score' without explicit mapping).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript accordingly to strengthen the empirical presentation and supporting analysis.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (results): the claim of 'significantly improves the quality of the confidence signal' and 'outperforming existing baselines by a large margin' is load-bearing for the contribution, yet the abstract and visible text supply no numerical values, baseline names, AUC/ECE deltas, statistical tests, or error bars on LIBERO; without these the central empirical claim cannot be evaluated.
Authors: We agree that the abstract currently lacks specific numerical support for the central claim. Section 4 of the full manuscript contains the LIBERO results with comparisons against ensemble and action-probability baselines, including AUC/ECE metrics and efficiency measurements. To make the contribution immediately evaluable from the abstract, we will revise it to report the key deltas (e.g., AUC and ECE improvements), explicitly name the baselines, and reference the presence of error bars and statistical tests from the tables in §4. This change will be incorporated in the next version. revision: yes
-
Referee: [§3] §3 (method) and skeptic concern: the framework rests on the assumption that frozen VLA activations already separate successful from unsuccessful executions sufficiently for a lightweight one-class head to produce usable anomaly scores. No ablation, t-SNE visualization, or linear-probe analysis is referenced showing that this separation exists prior to head training; if the representations primarily encode action prediction rather than outcome, the single-pass efficiency advantage collapses.
Authors: The method does rely on the discriminative power of the frozen VLA representations. While the current submission does not include an explicit t-SNE visualization or linear-probe ablation, the strong empirical performance on both LIBERO and real-robot rollouts (reported in §4) provides indirect evidence that the representations contain outcome-relevant information. To directly address the concern, we will add a new ablation subsection (or appendix) that includes (i) a linear probe on the frozen features for success/failure classification and (ii) a t-SNE visualization of the representations conditioned on task outcome. This will confirm the separation prior to training the lightweight head. revision: yes
Circularity Check
No circularity: new head trained on frozen representations
full rationale
The paper introduces VLAConf as an independent construction: a lightweight one-class discriminative head trained on frozen VLA internal representations to output step-wise anomaly scores in one forward pass, with step-conditioned modeling. No equation or claim reduces the output to a fitted parameter defined by the target success signal, no self-citation chain justifies the core premise, and no ansatz or renaming is invoked. The method is presented as a novel post-hoc addition whose validity is checked empirically on LIBERO and real robots, remaining self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Frozen pretrained VLA internal representations contain sufficient information to distinguish task-success outcomes via anomaly scoring.
- domain assumption Step-conditioned modeling adds useful rollout-phase information for confidence estimation.
Reference graph
Works this paper leans on
-
[1]
pi 0: A vision-language-action flow model for general robot control,
K. B. et al., “pi 0: A vision-language-action flow model for general robot control,” 2024. [Online]. Available: https://arxiv.org/abs/2410. 24164
2024
-
[2]
pi 0.5: A vision-language-action model with open-world generalization,
——, “pi 0.5: A vision-language-action model with open-world generalization,” 2025. [Online]. Available: https://arxiv.org/abs/2504. 16054
2025
-
[3]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. K. et al., “Openvla: An open-source vision-language-action model,” 2025. [Online]. Available: https://arxiv.org/abs/2406.09246
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
B. Z. et al. (CoRL); Anthony Brohan et al. (arXiv preprint), “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” 2023. [Online]. Available: https://arxiv.org/abs/2307.15818
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Octo: An Open-Source Generalist Robot Policy
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu,et al., “Octo: An open-source generalist robot policy,”arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Linguistic calibration of long-form generations,
N. B. et al., “Linguistic calibration of long-form generations,” 2024. [Online]. Available: https://arxiv.org/abs/2404.00474
-
[7]
Teaching Models to Express Their Uncertainty in Words
O. E. Stephanie Lin, Jacob Hilton, “Teaching models to express their uncertainty in words,” 2022. [Online]. Available: https: //arxiv.org/abs/2205.14334
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
K. T. et al., “Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback,” 2023. [Online]. Available: https://arxiv.org/abs/2305.14975
-
[9]
Inside: Llms’ internal states retain the power of hallucination detection,
C. C. et al., “Inside: Llms’ internal states retain the power of hallucination detection,” 2024. [Online]. Available: https://arxiv.org/ abs/2402.03744
-
[10]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation,
S. F. Lorenz Kuhn, Yarin Gal, “Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation,” 2023
2023
-
[11]
Simple and scalable predictive uncertainty estimation using deep ensembles,
C. B. Balaji Lakshminarayanan, Alexander Pritzel, “Simple and scalable predictive uncertainty estimation using deep ensembles,”
-
[12]
Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles
[Online]. Available: https://arxiv.org/abs/1612.01474
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
INSIGHT: INference- time sequence introspection for generating help triggers in vision- language-action models,
U. B. Karli, Z. Shangguan, and T. Fitzgerald, “INSIGHT: INference- time sequence introspection for generating help triggers in vision- language-action models,” 2025
2025
-
[14]
Scaling verification can be more effective than scaling policy learning for vision-language-action alignment,
J. Kwok, X. Zhang, M. Xu, Y . Liu, A. Mirhoseini, C. Finn, and M. Pavone, “Scaling verification can be more effective than scaling policy learning for vision-language-action alignment,” 2026
2026
-
[15]
Confidence calibration in vision-language- action models,
T. P. Zollo and R. Zemel, “Confidence calibration in vision-language- action models,” 2025. [Online]. Available: https://arxiv.org/abs/2507. 17383
2025
-
[16]
A system-level view on out-of-distribution data in robotics,
R. S. et al., “A system-level view on out-of-distribution data in robotics,” 2022. [Online]. Available: https://arxiv.org/abs/2212.14020
-
[17]
C. X. et al., “Can we detect failures without failure data? uncertainty- aware runtime failure detection for imitation learning policies,” 2025. [Online]. Available: https://arxiv.org/abs/2503.08558
-
[18]
Failure prediction with statistical guarantees for vision-based robot control,
A. F. et al., “Failure prediction with statistical guarantees for vision-based robot control,” 2022. [Online]. Available: https: //arxiv.org/abs/2202.05894
-
[19]
Unpacking failure modes of generative policies: Runtime monitoring of consistency and progress,
C. A. et al., “Unpacking failure modes of generative policies: Runtime monitoring of consistency and progress,” 2024. [Online]. Available: https://arxiv.org/abs/2410.04640
-
[20]
Failure prediction at runtime for generative robot policies,
R. R ¨omer, A. Kobras, L. Worbis, and A. P. Schoellig, “Failure prediction at runtime for generative robot policies,” 2025
2025
-
[21]
RC-NF: Robot-conditioned normalizing flow for real-time anomaly detection in robotic manipulation,
S. Zhou, B. Zhu, J. Yang, X. Zhao, J. Chen, and Y .-G. Jiang, “RC-NF: Robot-conditioned normalizing flow for real-time anomaly detection in robotic manipulation,” 2026
2026
-
[22]
From demonstrations to safe deployment: Path-consistent safety filtering for diffusion policies,
R. R ¨omer, J. Balletshofer, J. Thumm, M. Pavone, A. P. Schoellig, and M. Althoff, “From demonstrations to safe deployment: Path-consistent safety filtering for diffusion policies,” 2025
2025
-
[23]
Real-time anomaly detection and reactive planning with large language models,
R. S. et al., “Real-time anomaly detection and reactive planning with large language models,” 2024. [Online]. Available: https: //arxiv.org/abs/2407.08735
-
[24]
Asking for help: Failure prediction in behavioral cloning through value approximation,
M. K. Cem Gokmen, Daniel Ho, “Asking for help: Failure prediction in behavioral cloning through value approximation,” 2023. [Online]. Available: https://arxiv.org/abs/2302.04334
-
[25]
T. A. et al., “Fighting failures with fire: Failure identification to reduce expert burden in intervention-based learning,” 2020. [Online]. Available: https://arxiv.org/abs/2007.00245
-
[26]
Aha: A vision-language-model for detecting and reasoning over failures in robotic manipulation,
J. D. et al., “Aha: A vision-language-model for detecting and reasoning over failures in robotic manipulation,” 2024. [Online]. Available: https://arxiv.org/abs/2410.00371
-
[27]
Safe: Multitask failure detection for vision-language- action models,
Q. Gu, Y . Ju, S. Sun, I. Gilitschenski, H. Nishimura, M. Itkina, and F. Shkurti, “Safe: Multitask failure detection for vision-language- action models,” 2025
2025
-
[28]
Flipping coins to estimate pseudocounts for exploration in reinforcement learning,
S. Lobel, A. Bagaria, and G. Konidaris, “Flipping coins to estimate pseudocounts for exploration in reinforcement learning,” inProceed- ings of the 40th International Conference on Machine Learning, ser. PMLR, 2023, pp. 22 594–22 613
2023
-
[29]
FiLM: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. de Vries, V . Dumoulin, and A. Courville, “FiLM: Visual reasoning with a general conditioning layer,” inProceedings of the 32nd AAAI Conference on Artificial Intelligence, 2018
2018
-
[30]
Probabilistic outputs for support vector machines and com- parisons to regularized likelihood methods,
J. Platt, “Probabilistic outputs for support vector machines and com- parisons to regularized likelihood methods,” 1999
1999
-
[31]
Libero: Benchmarking knowledge transfer for lifelong robot learn- ing,
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone, “Libero: Benchmarking knowledge transfer for lifelong robot learn- ing,”Advances in Neural Information Processing Systems, vol. 36, pp. 44 776–44 791, 2023
2023
-
[32]
LIBERO-PRO: Towards Robust and Fair Evaluation of Vision-Language-Action Models Beyond Memorization
X. Zhou, Y . Xu, G. Tie, Y . Chen, G. Zhang, D. Chu, P. Zhou, and L. Sun, “Libero-pro: Towards robust and fair evaluation of vision-language-action models beyond memorization,”arXiv preprint arXiv:2510.03827, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei,et al., “Libero-plus: In-depth robustness analysis of vision- language-action models,”arXiv preprint arXiv:2510.13626, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Multi-task interactive robot fleet learning with visual world models,
H. Liu, Y . Zhang, V . Betala, E. Zhang, J. Liu, C. Ding, and Y . Zhu, “Multi-task interactive robot fleet learning with visual world models,” inProceedings of the Conference on Robot Learning, 2024
2024
-
[35]
Exploration by random network distillation,
Y . Burda, H. Edwards, A. Storkey, and O. Klimov, “Exploration by random network distillation,” 2018
2018
-
[36]
Consistency flow matching: Defining straight flows with velocity consistency,
L. Yang, Z. Zhang, Z. Zhang, X. Liu, M. Xu, W. Zhang, C. Meng, S. Ermon, and B. Cui, “Consistency flow matching: Defining straight flows with velocity consistency,” 2024
2024
-
[37]
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finn,et al., “Cosmos policy: Fine-tuning video models for visuomotor control and planning,”arXiv preprint arXiv:2601.16163, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Causal World Modeling for Robot Control
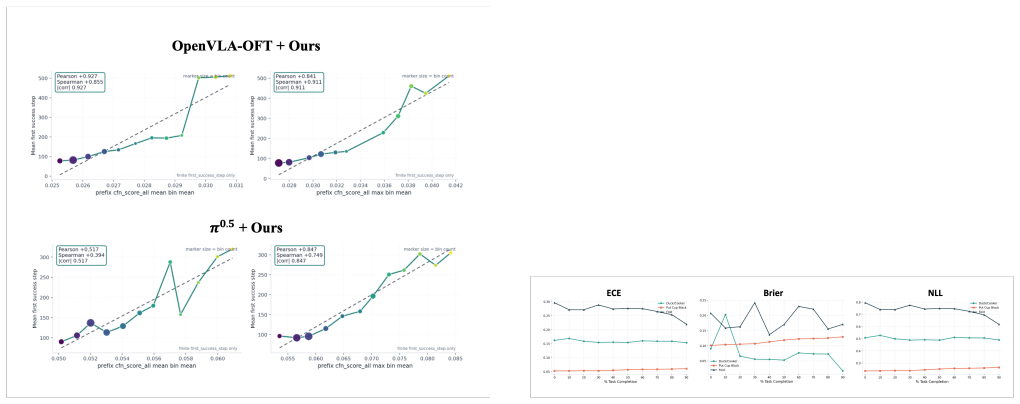
L. Li, Q. Zhang, Y . Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhu,et al., “Causal world modeling for robot control,” arXiv preprint arXiv:2601.21998, 2026. APPENDIXI ADDITIONALANALYSES This appendix provides supplementary analyses support- ing the main findings while keeping the main text focused. We first examine whether the raw anomaly s...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.