RTP-LLM: High-Performance Alibaba LLM Inference Engine
Pith reviewed 2026-06-28 23:50 UTC · model grok-4.3
The pith
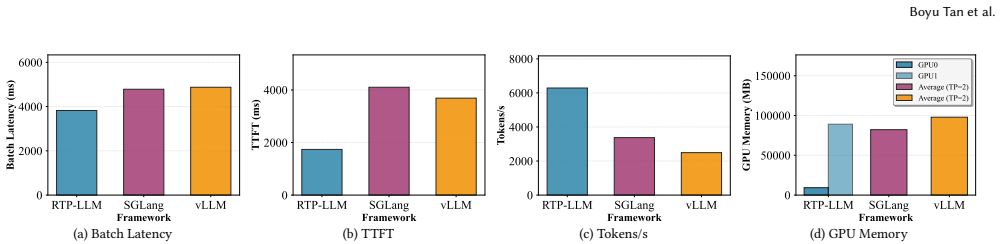
RTP-LLM uses prefill-decode disaggregation and hierarchical KV cache management to deliver 4.7x-6.3x faster model loading and 35-37% lower TTFT latency than vLLM and SGLang.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
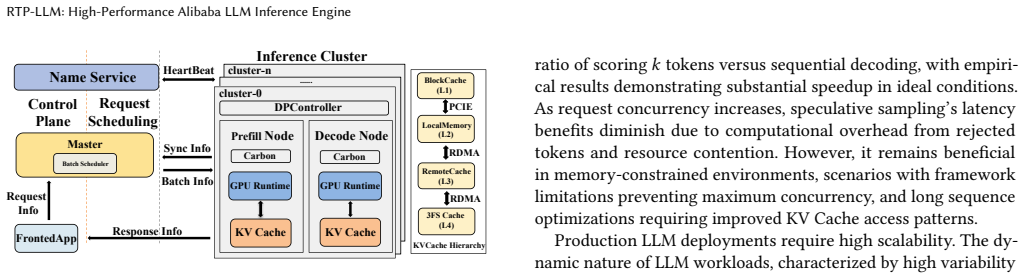
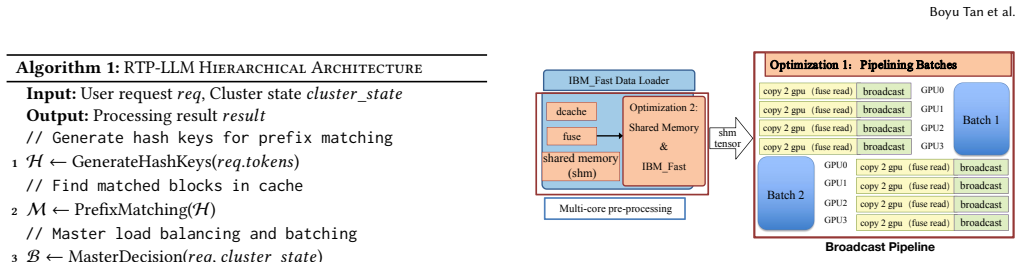
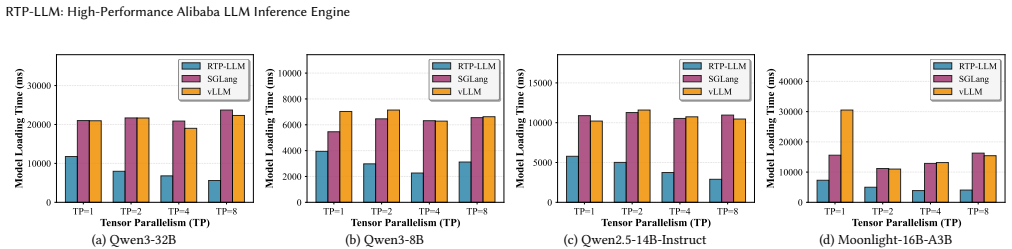
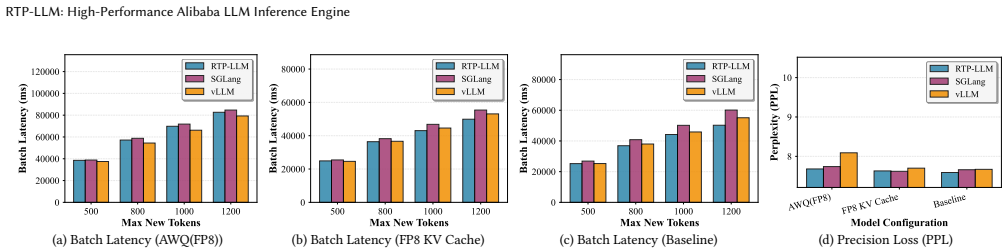
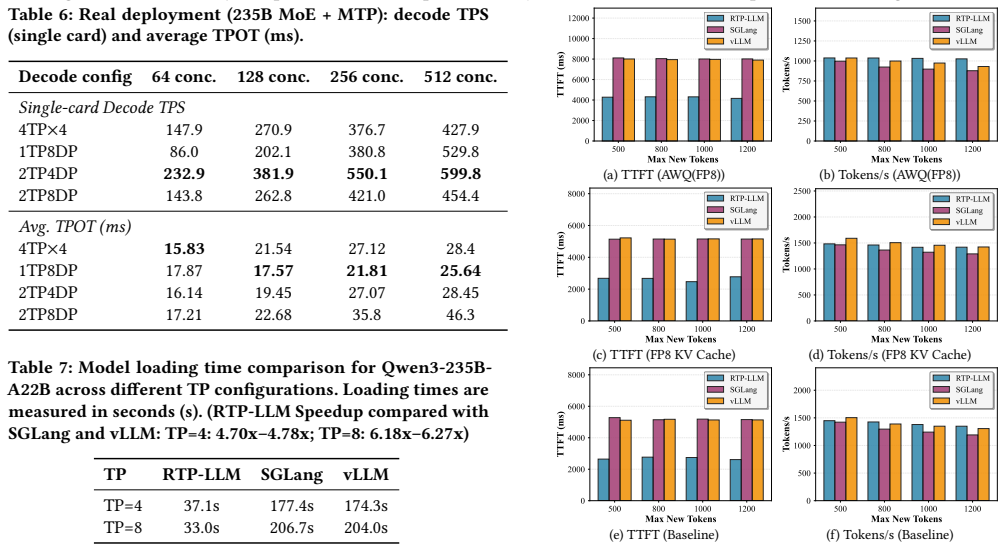
RTP-LLM addresses fundamental bottlenecks through integrated design: file-order-driven I/O and parallel I/O-communication overlapping for model loading; a Prefill-Decode Disaggregation architecture that decouples compute-intensive prefill from memory-bound decode phases, combined with hierarchical multi-tiered KV cache management for efficient cache reuse; modular speculative decoding supporting multiple algorithms; adaptive KV cache quantization; and decoupled multimodal processing with multi-level parallelism. Evaluations against vLLM and SGLang show 4.7x-6.3x model loading speedup, 35-37% TTFT P95 latency reduction with 215% cache reuse improvement, 1.12x-2.48x and 1.86x-2.52x throughput
What carries the argument
The Prefill-Decode Disaggregation architecture paired with hierarchical multi-tiered KV cache management, which separates prefill and decode phases while enabling efficient cache reuse across tiers.
If this is right
- Model loading becomes 4.7x-6.3x faster via file-order-driven I/O and overlapping.
- Production traffic scheduling achieves 35-37% TTFT P95 reduction alongside 215% cache reuse improvement.
- Speculative decoding delivers 1.12x-2.48x throughput improvement.
- Multimodal inference reaches 1.86x-2.52x throughput gains.
- Quantized inference reduces batch latency 35-40% and improves TTFT by 1.9x-3.0x.
Where Pith is reading between the lines
- The disaggregation technique could extend to other phases where compute and memory demands mismatch in distributed AI systems.
- Open release of the engine may encourage similar I/O and cache layering patterns in other serving frameworks.
- Further gains might appear if the multi-level parallelism is tuned against specific interconnect topologies not detailed in the evaluations.
- The hierarchical cache approach suggests potential benefits for energy efficiency in data-center LLM fleets if reuse rates hold under varied traffic.
Load-bearing premise
The production workloads and benchmark setups used for evaluation are representative of typical industrial traffic and the measured gains arise primarily from the described architectural choices rather than unstated hardware configurations or tuning.
What would settle it
An experiment that runs the same benchmarks and production traces on identical hardware with vLLM and SGLang producing equal or better results in loading time, TTFT, throughput, and cache reuse would falsify the performance claims.
Figures
read the original abstract
Large Language Models (LLMs) have revolutionized AI applications, but deploying them at scale presents significant challenges. We present RTP-LLM, a high-performance inference engine for industrial-scale LLM deployment, successfully deployed across Alibaba Group serving over 100 million users. RTP-LLM addresses fundamental bottlenecks through integrated design. It optimizes model loading via file-order-driven I/O and parallel I/O-communication overlapping. The Prefill-Decode Disaggregation architecture decouples compute-intensive prefill from memory-bound decode phases, combined with hierarchical multi-tiered KV cache management enabling efficient cache reuse. In addition, RTP-LLM incorporates modular speculative decoding supporting multiple algorithms, adaptive KV cache quantization, and decoupled multimodal processing, with support for multi-level parallelism. Comprehensive evaluations across diverse model architectures (8B-235B parameters) have been conducted, where both controlled benchmarks and real production workloads are used. The results demonstrate RTP-LLM's superior performance against vLLM and SGLang: 4.7x-6.3x model loading speedup, 35-37% TTFT P95 latency reduction with 215% cache reuse improvement in production traffic scheduling, 1.12x-2.48x and 1.86x-2.52x throughput improvements in speculative decoding and multimodal inference, respectively, and 35-40% batch latency reduction with 1.9x-3.0x TTFT improvement in quantized inference. RTP-LLM's production-proven architecture and open-source availability make it a comprehensive solution for industrial LLM deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents RTP-LLM, an industrial LLM inference engine deployed at Alibaba serving over 100 million users. It describes optimizations including file-order-driven I/O with parallel overlapping, Prefill-Decode Disaggregation, hierarchical multi-tiered KV cache for reuse, modular speculative decoding, adaptive KV cache quantization, and decoupled multimodal processing. Evaluations on 8B-235B models against vLLM and SGLang report 4.7x-6.3x model loading speedup, 35-37% TTFT P95 reduction with 215% cache reuse improvement in production, 1.12x-2.48x and 1.86x-2.52x throughput gains in speculative and multimodal cases, and 35-40% batch latency reduction with 1.9x-3.0x TTFT improvement in quantized inference.
Significance. If the performance deltas can be isolated to the described architectural choices under controlled conditions, the work would offer a practically significant contribution to production LLM serving systems by demonstrating scalable disaggregation and cache management techniques in real traffic. The open-source release and multi-level parallelism support add value for the community.
major comments (3)
- [Evaluation] Evaluation section: The reported speedups (4.7x-6.3x loading, 35-37% TTFT P95 reduction, etc.) are presented without explicit confirmation that vLLM and SGLang baselines used identical cluster hardware, interconnects, CUDA versions, or equivalent per-system tuning. This prevents isolating gains to Prefill-Decode Disaggregation and hierarchical KV cache as claimed in the abstract.
- [Abstract] Abstract and Evaluation: All quantitative claims (e.g., 215% cache reuse improvement, 1.12x-2.48x throughput) are given as point estimates without error bars, workload characterization details, or statistical analysis, making it impossible to assess variability or reproducibility of the production traffic results.
- [Evaluation] Evaluation section: No description of how production workloads were selected or whether they are representative; the 35-37% TTFT reduction and cache reuse claims rest on the unverified assumption that measured gains arise primarily from the listed features rather than unstated configuration differences.
minor comments (1)
- [Abstract] The abstract states results across 'diverse model architectures (8B-235B parameters)' but provides no table or section listing the exact models, batch sizes, or sequence lengths used in each comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation methodology and reproducibility aspects. We address each major comment below and will revise the manuscript to improve clarity on experimental setups and workload details where feasible.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The reported speedups (4.7x-6.3x loading, 35-37% TTFT P95 reduction, etc.) are presented without explicit confirmation that vLLM and SGLang baselines used identical cluster hardware, interconnects, CUDA versions, or equivalent per-system tuning. This prevents isolating gains to Prefill-Decode Disaggregation and hierarchical KV cache as claimed in the abstract.
Authors: We acknowledge that the current manuscript does not explicitly detail the hardware equivalence for baselines. All reported comparisons were performed on the same production-grade cluster with identical hardware, interconnects (e.g., NVLink and InfiniBand), CUDA versions, and driver configurations; baseline systems received equivalent tuning efforts to the best of our ability. In the revised version, we will add a dedicated 'Experimental Setup' subsection in the Evaluation section that explicitly confirms these controls and describes how gains are isolated to the architectural features. revision: yes
-
Referee: [Abstract] Abstract and Evaluation: All quantitative claims (e.g., 215% cache reuse improvement, 1.12x-2.48x throughput) are given as point estimates without error bars, workload characterization details, or statistical analysis, making it impossible to assess variability or reproducibility of the production traffic results.
Authors: We agree that the absence of error bars and statistical details limits assessment of variability. Production metrics reflect aggregated observations over multi-day periods of live traffic rather than repeated controlled trials, which inherently limits the applicability of traditional error bars. In the revision, we will add a note on measurement methodology, include any available variability ranges for key metrics, and clarify that point estimates represent observed typical improvements under the described conditions. revision: partial
-
Referee: [Evaluation] Evaluation section: No description of how production workloads were selected or whether they are representative; the 35-37% TTFT reduction and cache reuse claims rest on the unverified assumption that measured gains arise primarily from the listed features rather than unstated configuration differences.
Authors: Production workloads were drawn from actual Alibaba user traffic spanning multiple model sizes and request patterns to ensure representativeness of real deployment scenarios. Configuration differences between systems were minimized by using the same cluster and equivalent tuning. In the revised manuscript, we will expand the Evaluation section with a high-level workload characterization (e.g., request rate distributions and model mix) while respecting confidentiality constraints, and reaffirm that comparisons control for non-architectural factors. revision: yes
Circularity Check
No circularity: purely empirical benchmark results
full rationale
The paper is a systems description of an LLM inference engine. All performance claims (speedups, latency reductions, throughput gains) are presented as direct empirical measurements from controlled benchmarks and production traffic, with no mathematical derivations, first-principles predictions, fitted parameters renamed as outputs, or load-bearing self-citations of uniqueness theorems. No equations or ansatzes are invoked that could reduce to inputs by construction. This matches the expected non-finding for engineering papers whose central claims rest on external falsifiable measurements rather than internal derivation chains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [2]
-
[3]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Taming {Throughput-Latency} tradeoff in {LLM} inference with {Sarathi-Serve}. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 117–134
2024
-
[4]
Alibaba. 2025. Source code of RTP-LLM. https://github.com/alibaba/rtp-llm
2025
-
[5]
Aone. 2025. Aone Copilot. Visual Studio Code Extension. https://marketplace. visualstudio.com/items?itemName=Aone.aone-copilot Accessed: 2025-11-15
2025
-
[6]
Hicham Badri and Appu Shaji. 2023. Half-Quadratic Quantization of Large Machine Learning Models. https://mobiusml.github.io/hqq_blog/
2023
-
[7]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report.arXiv preprint arXiv:2309.16609(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond.arXiv preprint arXiv:2308.12966(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
-
[11]
NVIDIA Corporation. 2025. NVIDIA Collective Communications Library (NCCL) User Guide. Online Documentation. https://docs.nvidia.com/deeplearning/nccl/ user-guide/docs/overview.html Accessed: 2025-11-15
2025
-
[12]
Tri Dao. 2023. Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. Flashat- tention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems35 (2022), 16344–16359
2022
-
[15]
Yangshen Deng, Zhengxin You, Long Xiang, Qilong Li, Peiqi Yuan, Zhaoyang Hong, Yitao Zheng, Wanting Li, Runzhong Li, Haotian Liu, et al. 2025. AlayaDB: The Data Foundation for Efficient and Effective Long-context LLM Inference. In Companion of the 2025 International Conference on Management of Data. 364–377
2025
-
[16]
Alexey Dosovitskiy. 2020. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[17]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv e-prints(2024), arXiv–2407
2024
-
[18]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. 2022. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Shihong Gao, Xin Zhang, Yanyan Shen, and Lei Chen. 2025. Apt-Serve: Adap- tive Request Scheduling on Hybrid Cache for Scalable LLM Inference Serving. Proceedings of the ACM on Management of Data3, 3 (2025), 1–28
2025
-
[20]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Kostas Hatalis, Despina Christou, Joshua Myers, Steven Jones, Keith Lambert, Adam Amos-Binks, Zohreh Dannenhauer, and Dustin Dannenhauer. 2023. Mem- ory matters: The need to improve long-term memory in llm-agents. InProceedings of the AAAI Symposium Series, Vol. 2. 277–280
2023
-
[22]
Yongjun He, Yao Lu, and Gustavo Alonso. 2024. Deferred continuous batching in resource-efficient large language model serving. InProceedings of the 4th Workshop on Machine Learning and Systems. 98–106
2024
- [23]
-
[24]
GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering
Drew A. Hudson and Christopher D. Manning. 2019. GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering. arXiv:1902.09506 [cs.CL] https://arxiv.org/abs/1902.09506
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[25]
Hugging Face Inc. 2024. Text Generation Inference (TGI): High -Performance Inference Engine for Large Language Models. https://huggingface.co/text- generation-inference
2024
-
[26]
Chao Jin, Zili Zhang, Xuanlin Jiang, Fangyue Liu, Shufan Liu, Xuanzhe Liu, and Xin Jin. 2024. Ragcache: Efficient knowledge caching for retrieval-augmented generation.ACM Transactions on Computer Systems(2024)
2024
-
[27]
Saehan Jo and Immanuel Trummer. 2025. SpareLLM: Automatically Selecting Task-Specific Minimum-Cost Large Language Models under Equivalence Con- straint.Proceedings of the ACM on Management of Data3, 3 (2025), 1–26
2025
-
[28]
Uday Kamath, Kevin Keenan, Garrett Somers, and Sarah Sorenson. 2024. LLMs in Production. InLarge Language Models: A Deep Dive: Bridging Theory and Practice. Springer, 315–373
2024
- [29]
-
[30]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAtten- tion. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles
2023
-
[31]
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. 2024. {InfiniGen}: Efficient generative inference of large language models with dynamic {KV} cache management. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 155–172
2024
-
[32]
Baolin Li, Yankai Jiang, Vijay Gadepally, and Devesh Tiwari. 2024. Llm infer- ence serving: Survey of recent advances and opportunities. In2024 IEEE High Performance Extreme Computing Conference (HPEC). IEEE, 1–8
2024
-
[33]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. 2024. Eagle: Speculative sampling requires rethinking feature uncertainty.arXiv preprint arXiv:2401.15077(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. 2024. Awq: Activation-aware weight quantization for on-device llm compression and accel- eration.Proceedings of machine learning and systems6 (2024), 87–100
2024
-
[35]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Guangda Liu, Chengwei Li, Jieru Zhao, Chenqi Zhang, and Minyi Guo. 2025. Clus- terkv: Manipulating llm kv cache in semantic space for recallable compression. In2025 62nd ACM/IEEE Design Automation Conference (DAC). IEEE, 1–7
2025
-
[37]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
2023
-
[38]
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, Yanru Chen, Huabin Zheng, Yibo Liu, Shaowei Liu, Bohong Yin, Weiran He, Han Zhu, Yuzhi Wang, Jianzhou Wang, Mengnan Dong, Zheng Zhang, Yongsheng Kang, Hao Zhang, Xinran Xu, Yutao Zhang, Yuxin Wu, Xinyu Zhou, and Zhilin Yang. 2025. Muon ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Mikasenghaas and Hugging Face Dataset Authors. 2024. Wikitext-2 Dataset Mir- ror. Hugging Face Dataset Card. https://hf-mirror.com/datasets/mikasenghaas/ wikitext-2 Accessed: 2024-11
2024
-
[40]
NVIDIA. 2023. TensorRT LLM. https://github.com/NVIDIA/TensorRT-LLM
2023
-
[41]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 118–132
2024
-
[42]
Satya Naga Mallika Pothukuchi. 2025. LLMOps: A Comprehensive Guide to Deploying Large Language Models in Production.IJSAT-International Journal on Science and Technology16, 1 (2025)
2025
-
[43]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. 2025. Mooncake: Trading more storage for less computation—a {KVCache-centric} architecture for serving {LLM} chatbot. In23rd USENIX Conference on File and Storage Technologies (FAST 25). 155–170
2025
-
[44]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog1, 8 (2019), 9
2019
-
[45]
Gursimran Singh, Xinglu Wang, Yifan Hu, Timothy Yu, Linzi Xing, Wei Jiang, Zhefeng Wang, Xiaolong Bai, Yi Li, Ying Xiong, Yong Zhang, and Zhenan Fan
-
[46]
arXiv:2501.05460 [cs.DC] https://arxiv.org/abs/2501.05460
Efficiently Serving Large Multimodal Models Using EPD Disaggregation. arXiv:2501.05460 [cs.DC] https://arxiv.org/abs/2501.05460
- [47]
-
[48]
Qwen Team. 2024. Qwen2.5: A Party of Foundation Models. https://qwenlm. github.io/blog/qwen2.5/
2024
-
[49]
Qwen Team. 2025. Qwen2.5-VL. https://qwenlm.github.io/blog/qwen2.5-vl/
2025
-
[50]
Qwen Team. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https: //arxiv.org/abs/2505.09388 Boyu Tan et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[52]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. 2024. Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution.arXiv preprint arXiv:2409.12191(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Yiding Wang, Kai Chen, Haisheng Tan, and Kun Guo. 2023. Tabi: An efficient multi-level inference system for large language models. InProceedings of the Eighteenth European Conference on Computer Systems. 233–248
2023
-
[54]
Yuxin Wang, Yuhan Chen, Zeyu Li, Xueze Kang, Yuchu Fang, Yeju Zhou, Yang Zheng, Zhenheng Tang, Xin He, Rui Guo, et al . 2025. Burstgpt: A real-world workload dataset to optimize llm serving systems. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 5831–5841
2025
- [55]
-
[56]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Cheng- peng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei Li, Mingfen...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Yuqing Yang, Lei Jiao, and Yuedong Xu. 2024. A queueing theoretic perspective on low-latency llm inference with variable token length. In2024 22nd Interna- tional Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks (WiOpt). IEEE, 273–280
2024
- [58]
- [59]
-
[60]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung- Gon Chun. 2022. Orca: A distributed serving system for {Transformer-Based} generative models. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). 521–538
2022
-
[61]
Chen Zhang, Kuntai Du, Shu Liu, Woosuk Kwon, Xiangxi Mo, Yufeng Wang, Xiaoxuan Liu, Kaichao You, Zhuohan Li, Mingsheng Long, et al. 2025. JENGA: Ef- fective memory management for serving LLM with heterogeneity. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles. 446–461
2025
-
[62]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. 2023. H2o: Heavy-hitter oracle for efficient generative inference of large language models. Advances in Neural Information Processing Systems36 (2023), 34661–34710
2023
-
[63]
Chenggang Zhao, Shangyan Zhou, Liyue Zhang, Chengqi Deng, Zhean Xu, Yuxuan Liu, Kuai Yu, Jiashi Li, and Liang Zhao. 2025. DeepEP: an efficient expert-parallel communication library. https://github.com/deepseek-ai/DeepEP
2025
-
[64]
Pinxue Zhao, Hailin Zhang, Fangcheng Fu, Xiaonan Nie, Qibin Liu, Fang Yang, Yuanbo Peng, Dian Jiao, Shuaipeng Li, Jinbao Xue, et al . 2025. MEMO: Fine- grained Tensor Management For Ultra-long Context LLM Training.Proceedings of the ACM on Management of Data3, 1 (2025), 1–28
2025
-
[65]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Livia Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. 2024. Sglang: Efficient execution of structured language model programs. Advances in neural information processing systems37 (2024), 62557–62583
2024
-
[66]
Zhen Zheng, Xin Ji, Taosong Fang, Fanghao Zhou, Chuanjie Liu, and Gang Peng
-
[67]
Batchllm: Optimizing large batched llm inference with global prefix sharing and throughput-oriented token batching.arXiv preprint arXiv:2412.03594(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[68]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. 2024. {DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 193–210
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.