VikingMem: A Memory Base Management System for Stateful LLM-based Applications
Pith reviewed 2026-06-29 07:28 UTC · model grok-4.3
The pith
VikingMem introduces a Memory Base paradigm that selectively extracts, evolves, and abstracts memories to manage persistent state in LLM interactions, outperforming baselines by up to 30 percent in retrieval effectiveness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that defining a Memory Base around selective extraction of high-value memories from raw streams, inherent statefulness and evolution through progressive summarization correction and temporal weighting, and generalizable abstraction for transfer across applications, then implementing it via event-centric extraction and dynamic entity updates with temporal compression on a topic-wise timeline and time-weighted recall, enables effective persistent state management for stateful LLM applications.
What carries the argument
The Memory Base paradigm defined by selective extraction, inherent statefulness and evolution, and generalizable abstraction, realized through interconnected event and entity abstractions together with topic-wise timeline compression and time-weighted recall.
If this is right
- Memories are progressively summarized, corrected, and temporally weighted to prioritize recent interactions over older ones.
- High-level summary memories are produced while older content is compressed and faded using time-weighted recall.
- The approach transfers to downstream tasks including education, recommendation, and agent memory through its generalizable abstraction.
- Low latency is preserved for interactive applications alongside the reported gains in retrieval effectiveness.
Where Pith is reading between the lines
- The event-entity structure could support memory designs in multi-turn agent systems where state must persist across many turns.
- Similar temporal weighting might be applied to other context-management techniques to reduce token usage in long sessions.
- The abstraction layer suggests a path toward memory systems that avoid per-application prompt tuning.
Load-bearing premise
The three core principles of selective extraction, stateful evolution, and generalizable abstraction are sufficient to produce robust transferability across diverse downstream tasks without task-specific prompt engineering.
What would settle it
A controlled test on a new task such as medical consultation memory showing retrieval effectiveness no higher than baselines or a measurable rise in response latency would indicate the principles do not deliver the claimed general benefits.
Figures

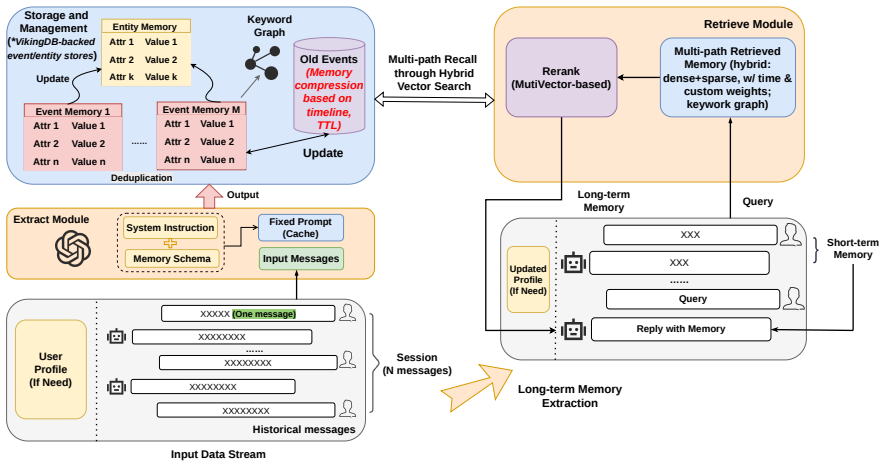
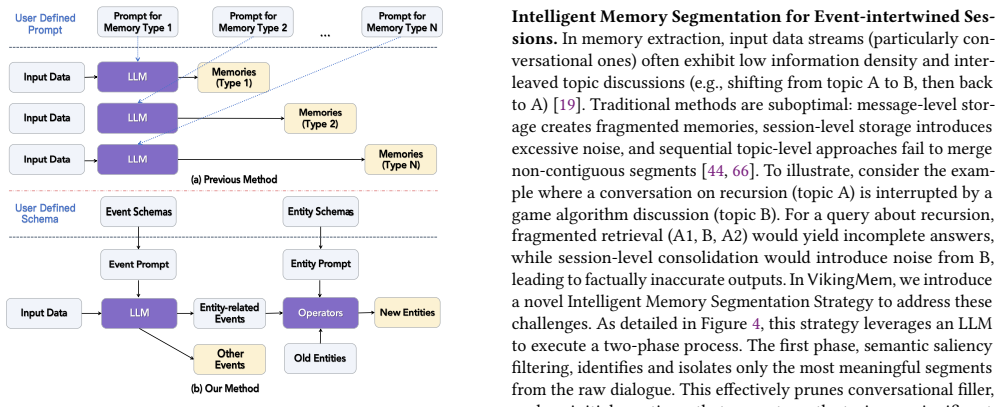

read the original abstract
Large Language Models have revolutionized interactive applications; however, their finite context windows pose a critical data management challenge for maintaining stateful, long-term interactions. Existing memory approaches often rely on simplistic extraction methods that lead to incomplete memories or use rigid, single-purpose memory extraction prompts tailored to a single use case, such as chatbots. Consequently, they lack generalizability and perform poorly across diverse downstream tasks. To bridge this gap, we introduce the Memory Base, a novel data management paradigm for managing the persistent state of long-term interactions. It is characterized by three core principles: selective extraction of high-value memories from raw information streams; inherent statefulness and evolution, where memory content is progressively summarized, corrected, and temporally weighted to prioritize recent interactions; and a generalizable abstraction paradigm designed for robust transferability across diverse applications, including education, recommendation, and agent memory. Building on this foundation, we present VikingMem, an end-to-end Memory Base Management System implemented on the VikingDB vector engine. VikingMem materializes this paradigm through interconnected event and entity abstractions. It features event-centric memory extraction to selectively handle complex information streams, while entities are dynamically updated by events to achieve stateful evolution. Using temporal compression via a topic-wise timeline and time-weighted recall, the system progressively produces high-level summary memories, prioritizes recent items, and compresses and fades older ones. Extensive evaluations on long-term memory benchmarks demonstrate that VikingMem outperformes baselines by up to 30% in memory retrieval effectiveness while maintaining the low latency essential for interactive applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Memory Base paradigm for managing persistent state in long-term LLM interactions, defined by three principles: selective extraction of high-value memories, inherent statefulness with progressive summarization/correction/temporal weighting, and generalizable abstraction for transfer across tasks. It presents VikingMem, an implementation on VikingDB using interconnected event-centric extraction and entity updates, with topic-wise timelines and time-weighted recall for compression. The central claim is that extensive evaluations on long-term memory benchmarks show up to 30% improvement in retrieval effectiveness over baselines while preserving low latency for interactive use.
Significance. If the 30% retrieval gain is reproducible with named benchmarks, baselines, and error bars, and if the three principles demonstrably transfer to the stated domains (education, recommendation, agent memory), the work could offer a practical data-management layer for stateful LLM applications. The implementation details on VikingDB and the event/entity abstraction are potentially useful engineering contributions, but the absence of cross-domain results limits the assessed impact to incremental improvements on existing long-term memory tasks.
major comments (2)
- [Abstract] Abstract: The claim that the three core principles 'enable robust transferability across diverse applications, including education, recommendation, and agent memory' is not supported by the reported evaluations, which are described only as occurring on 'long-term memory benchmarks.' No results, ablations, or transfer experiments are mentioned for the explicitly named target domains, so the 30% figure cannot substantiate the broader system claim.
- [Abstract] Abstract: The performance claim of 'up to 30% in memory retrieval effectiveness' provides no benchmark names, baseline descriptions, statistical details, or error bars. Without these, it is impossible to assess whether the data support the central effectiveness claim or to compare against prior work.
minor comments (1)
- [Abstract] Abstract: Typo 'outperformes' should be 'outperforms'.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that the claims regarding transferability and the performance metric require qualification to align precisely with the reported evaluations, which focus on long-term memory benchmarks. We will revise the abstract accordingly in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the three core principles 'enable robust transferability across diverse applications, including education, recommendation, and agent memory' is not supported by the reported evaluations, which are described only as occurring on 'long-term memory benchmarks.' No results, ablations, or transfer experiments are mentioned for the explicitly named target domains, so the 30% figure cannot substantiate the broader system claim.
Authors: We acknowledge that the evaluations are limited to long-term memory benchmarks and do not include explicit transfer experiments or results for the domains of education, recommendation, and agent memory. The abstract statement reflects the design intent of the Memory Base principles for generalizability, but we agree this is not empirically substantiated in the reported results. We will revise the abstract to state that the principles are designed to support transferability across applications, with empirical validation provided on long-term memory benchmarks relevant to these use cases. This change will be incorporated in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: The performance claim of 'up to 30% in memory retrieval effectiveness' provides no benchmark names, baseline descriptions, statistical details, or error bars. Without these, it is impossible to assess whether the data support the central effectiveness claim or to compare against prior work.
Authors: The 30% figure is derived from the detailed experimental results in the manuscript body, which specify the long-term memory benchmarks, baselines, and include statistical measures such as error bars. However, we agree the abstract lacks sufficient context for standalone assessment. We will revise the abstract to qualify the claim (e.g., 'up to 30% on long-term memory benchmarks, as detailed in Section 5') or reference the key evaluation setup where space permits, ensuring the central claim is traceable to the full results without altering the reported numbers. revision: yes
Circularity Check
No circularity; system design and empirical claims rest on external benchmarks without self-referential reduction
full rationale
The paper presents a new Memory Base paradigm defined by three explicit principles (selective extraction, statefulness/evolution, generalizable abstraction) and an implementation (VikingMem) whose performance is asserted via evaluations on long-term memory benchmarks. No equations, fitted parameters, predictions, or self-citations appear in the abstract or described content that would make any claim equivalent to its inputs by construction. The transferability assertion to education/recommendation/agent domains is an untested claim rather than a derived result, but this constitutes an evidence gap, not circularity. The derivation chain is self-contained as a descriptive systems contribution evaluated against external baselines.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Arkadeep Acharya, Brijraj Singh, and Naoyuki Onoe. 2023. Llm based generation of item-description for recommendation system. InProceedings of the 17th ACM conference on recommender systems. 1204–1207
2023
-
[2]
Federico Barbero, Andrea Banino, Steven Kapturowski, Dharshan Kumaran, João Madeira Araújo, Oleksandr Vitvitskyi, Razvan Pascanu, and Petar Veličković
-
[3]
Advances in Neural Information Processing Systems37 (2024), 98111–98142
Transformers need glasses! information over-squashing in language tasks. Advances in Neural Information Processing Systems37 (2024), 98111–98142
2024
-
[4]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
-
[5]
Davide Caffagni, Federico Cocchi, Nicholas Moratelli, Sara Sarto, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. 2024. Wiki-llava: Hierarchical retrieval- augmented generation for multimodal llms. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition. 1818–1826
2024
-
[6]
Ningyuan Chen. 2023. Enterprises Build Sustainable Innovation Loop: Take ByteDance Launching Lark as an Example. InDigitalization and Management Innovation. IOS Press, 126–132
2023
-
[7]
Sibei Chen, Ju Fan, Bin Wu, Nan Tang, Chao Deng, Pengyi Wang, Ye Li, Jian Tan, Feifei Li, Jingren Zhou, et al . 2025. Automatic database configuration debugging using retrieval-augmented language models.Proceedings of the ACM on Management of Data3, 1 (2025), 1–27
2025
-
[8]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Ya- dav. 2025. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [9]
-
[10]
Dong Deng, Guoliang Li, Jianhua Feng, and Wen-Syan Li. 2013. Top-k string similarity search with edit-distance constraints. In2013 IEEE 29th International Conference on Data Engineering (ICDE). IEEE, 925–936
2013
-
[11]
Weizhi Fei, Xueyan Niu, Pingyi Zhou, Lu Hou, Bo Bai, Lei Deng, and Wei Han
-
[12]
InFindings of the Association for Computational Linguistics ACL
Extending Context Window of Large Language Models via Semantic Compression. InFindings of the Association for Computational Linguistics ACL
-
[13]
Jiajie Fu, Junwen Chen, Mengzhao Wang, Aoxiang He, Maojia Sheng, Xiangyu Ke, Yifan Zhu, and Yunjun Gao. 2025. Evaluation Code for VikingMem. https: //github.com/BytedanceFu/VikingMem
2025
-
[14]
Jiajie Fu, Junwen Chen, Mengzhao Wang, Aoxiang He, Maojia Sheng, Xiangyu Ke, Yifan Zhu, and Yunjun Gao. 2025. Use cases for VikingMem. https://github. com/FuJiaJie123/VikingMem
2025
- [15]
- [16]
-
[17]
Jianyang Gao and Cheng Long. 2024. Rabitq: Quantizing high-dimensional vectors with a theoretical error bound for approximate nearest neighbor search. Proceedings of the ACM on Management of Data2, 3 (2024), 1–27
2024
-
[18]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. 2024. Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv:2312.10997 [cs.CL] https://arxiv.org/abs/2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Julie Gonneaud, Géraldine Rauchs, Mathilde Groussard, Brigitte Landeau, Flo- rence Mezenge, Vincent de La Sayette, Francis Eustache, and Béatrice Desgranges
-
[20]
How do we process event-based and time-based intentions in the brain? An fMRI study of prospective memory in healthy individuals.Human brain mapping35, 7 (2014), 3066–3082
2014
-
[21]
Gaurav Goswami. 2025. Dissecting the metrics: How different evaluation ap- proaches yield diverse results for conversational ai.Authorea Preprints(2025)
2025
-
[22]
Qinyu Han, Zhihao Yang, Hongfei Lin, and Tian Qin. 2024. Let topic flow: A uni- fied topic-guided segment-wise dialogue summarization framework.IEEE/ACM Transactions on Audio, Speech, and Language Processing32 (2024), 2021–2032
2024
-
[23]
Xiaoxin He, Yijun Tian, Yifei Sun, Nitesh Chawla, Thomas Laurent, Yann LeCun, Xavier Bresson, and Bryan Hooi. 2024. G-retriever: Retrieval-augmented gen- eration for textual graph understanding and question answering.Advances in Neural Information Processing Systems37 (2024), 132876–132907
2024
-
[24]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. 2025. A survey on hallucination in large language models: Principles, taxonomy, chal- lenges, and open questions.ACM Transactions on Information Systems43, 2 (2025), 1–55
2025
-
[25]
Yiqian Huang, Shiqi Zhang, and Xiaokui Xiao. 2025. KET-RAG: A Cost-Efficient Multi-Granular Indexing Framework for Graph-RAG. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Toronto ON, Canada)(KDD ’25). Association for Computing Machinery, 1003–1012
2025
-
[26]
Brennan Jones, Yan Xu, Qisheng Li, and Stefan Scherer. 2024. Designing a Proactive Context-Aware AI Chatbot for People’s Long-Term Goals. InExtended Abstracts of the CHI Conference on Human Factors in Computing Systems. 1–7
2024
-
[27]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick SH Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open-Domain Question Answering.. InEMNLP (1). 6769–6781
2020
-
[28]
Omar Khattab and Matei Zaharia. 2020. Colbert: Efficient and effective passage search via contextualized late interaction over bert. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 39–48
2020
-
[29]
Andrey Kuzmin, Mart Van Baalen, Yuwei Ren, Markus Nagel, Jorn Peters, and Ti- jmen Blankevoort. 2022. Fp8 quantization: The power of the exponent.Advances in Neural Information Processing Systems35 (2022), 14651–14662
2022
-
[30]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[31]
Hao Li, Chenghao Yang, An Zhang, Yang Deng, Xiang Wang, and Tat-Seng Chua
-
[32]
In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
Hello again! llm-powered personalized agent for long-term dialogue. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 5259–5276
2025
-
[33]
Xinze Li, Yushi Bai, Bowen Jin, Fengbin Zhu, Liangming Pan, and Yixin Cao
-
[34]
RAG: Strategies for Processing Long Documents in LLMs
Long Context vs. RAG: Strategies for Processing Long Documents in LLMs. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 4110–4113
-
[35]
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. 2024. Snapkv: Llm knows what you are looking for before generation.Advances in Neural Informa- tion Processing Systems37 (2024), 22947–22970
2024
- [36]
-
[37]
Patricia W Linville. 1987. Self-complexity as a cognitive buffer against stress- related illness and depression.Journal of personality and social psychology52, 4 (1987), 663
1987
- [38]
-
[39]
Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, Qifan Wang, Si Zhang, Ren Chen, Chris Leung, Jiajie Tang, and Jiebo Luo. 2024. Llm-rec: Personal- ized recommendation via prompting large language models. InFindings of the Association for Computational Linguistics: NAACL 2024. 583–612
2024
-
[40]
Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. 2023. Query rewriting in retrieval-augmented large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 5303–5315
2023
-
[41]
Yubo Ma, Jinsong Li, Yuhang Zang, Xiaobao Wu, Xiaoyi Dong, Pan Zhang, Yuhang Cao, Haodong Duan, Jiaqi Wang, Yixin Cao, and Aixin Sun. 2025. To- wards Storage-Efficient Visual Document Retrieval: An Empirical Study on Re- ducing Patch-Level Embeddings. InFindings of the Association for Computational Linguistics: ACL 2025. 19568–19580
2025
-
[42]
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. 2024. Evaluating Very Long-Term Conversational Memory of LLM Agents. InProceedings of the 62nd Annual Meeting of the Associ- ation for Computational Linguistics (Volume 1: Long Papers). 13851–13870
2024
-
[43]
Hazel Markus. 1977. Self-schemata and processing information about the self. Journal of personality and social psychology35, 2 (1977), 63. 13
1977
-
[44]
Memobase. 2025. Source code of Memobase. https://github.com/memodb- io/memobase
2025
-
[45]
Mite Mijalkov, Ludvig Storm, Blanca Zufiria-Gerbolés, Dániel Veréb, Zhilei Xu, Anna Canal-Garcia, Jiawei Sun, Yu-Wei Chang, Hang Zhao, Emiliano Gómez- Ruiz, et al. 2025. Computational memory capacity predicts aging and cognitive decline.Nature communications16, 1 (2025), 2748
2025
-
[46]
Openclaw. 2026. Openclaw AI. https://openclaw.ai/
2026
-
[47]
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G Patil, Ion Stoica, and Joseph E Gonzalez. 2023. MemGPT: Towards LLMs as Operating Systems.arXiv preprint arXiv:2310.08560(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [48]
-
[49]
Vicky Zhao, Lili Qiu, and Jianfeng Gao
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Xufang Luo, Hao Cheng, Dongsheng Li, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, and Jianfeng Gao. 2025. SeCom: On Memory Construction and Retrieval for Personalized Conversational Agents. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=xKDZAW0He3
2025
-
[50]
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. 2023. Yarn: Efficient context window extension of large language models.arXiv preprint arXiv:2309.00071(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. 2025. Zep: a temporal knowledge graph architecture for agent memory. arXiv preprint arXiv:2501.13956(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Machel Reid et al. 2024. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Henry L Roediger III and Jeffrey D Karpicke. 2006. Test-enhanced learning: Taking memory tests improves long-term retention.Psychological science17, 3 (2006), 249–255
2006
-
[54]
RooCodeInc. 2026. Roocode Source Code. Retrieved January 11, 2026 from https://github.com/RooCodeInc/Roo-Code
2026
-
[55]
Vitória S Santos and Carina F Dorneles. 2024. Unveiling the Segmentation Power of LLMs: Zero-Shot Invoice Item Description Analysis. InSimpósio Brasileiro de Banco de Dados (SBBD). SBC, 549–561
2024
- [56]
-
[57]
Yunxiao Shi, Xing Zi, Zijing Shi, Haimin Zhang, Qiang Wu, and Min Xu. 2024. En- hancing Retrieval and Managing Retrieval: A Four-Module Synergy for Improved Quality and Efficiency in RAG Systems. InECAI 2024. IOS Press, 2258–2265
2024
-
[58]
Aditi Singh, Abul Ehtesham, Saket Kumar, and Tala Talaei Khoei. 2025. Agen- tic retrieval-augmented generation: A survey on agentic rag.arXiv preprint arXiv:2501.09136(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Weihang Su, Yichen Tang, Qingyao Ai, Junxi Yan, Changyue Wang, Hongning Wang, Ziyi Ye, Yujia Zhou, and Yiqun Liu. 2025. Parametric retrieval augmented generation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1240–1250
2025
-
[60]
Jakub Swacha and Michał Gracel. 2025. Retrieval-Augmented Generation (RAG) Chatbots for Education: A Survey of Applications.Applied Sciences15, 8 (2025), 4234
2025
-
[61]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
VikingMem. 2025. VikingMem User Guide. https://docs.byteplus.com/en/docs/ VikingDB/Integrating_LLM_with_Memory
2025
- [63]
-
[64]
Yu Wang and Xi Chen. 2025. MIRIX: Multi-Agent Memory System for LLM-Based Agents.arXiv preprint arXiv:2507.07957(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. 2024. Agent workflow memory.arXiv preprint arXiv:2409.07429(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reason- ing in large language models.Advances in neural information processing systems 35 (2022), 24824–24837
2022
- [67]
-
[68]
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. 2024. Longmemeval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[69]
Weiqi Wu, Shen Huang, Yong Jiang, Pengjun Xie, Fei Huang, and Hai Zhao
-
[70]
InFindings of the Association for Computational Linguistics: NAACL 2025
Unfolding the Headline: Iterative Self-Questioning for News Retrieval and Timeline Summarization. InFindings of the Association for Computational Linguistics: NAACL 2025. 4385–4398
2025
-
[71]
Yunzhong Xiao, Yangmin Li, Hewei Wang, Yunlong Tang, and Zora Zhiruo Wang
- [72]
-
[73]
Linhao Ye, Zhikai Lei, Jianghao Yin, Qin Chen, Jie Zhou, and Liang He
-
[74]
InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval
Boosting conversational question answering with fine-grained retrieval- augmentation and self-check. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2301–2305
- [75]
- [76]
-
[77]
Xin Zhang, Yanzhao Zhang, Dingkun Long, Wen Xie, Ziqi Dai, Jialong Tang, Huan Lin, Baosong Yang, Pengjun Xie, Fei Huang, et al. 2024. mGTE: Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track. 1393–1412
2024
-
[78]
Siyun Zhao, Yuqing Yang, Zilong Wang, Zhiyuan He, Luna K Qiu, and Lili Qiu
- [79]
-
[80]
Wei Zhou, Yuyang Gao, Xuanhe Zhou, and Guoliang Li. 2025. Cracking SQL Barriers: An LLM-based Dialect Translation System.Proceedings of the ACM on Management of Data3, 3 (2025), 1–26. 14
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.