Unsupervised Semantic Segmentation Facilitates Model Understanding
Pith reviewed 2026-06-29 08:34 UTC · model grok-4.3
The pith
A visualization protocol using unsupervised semantic segmentation reveals consistent positional biases and scaling behaviors in self-supervised vision transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Applying unsupervised semantic segmentation to the representations of various self-supervised vision transformers and visualizing the outputs conveys model behaviors that emerge consistently, including distinct positional biases and scaling behaviors, without any optimization for segmentation performance.
What carries the argument
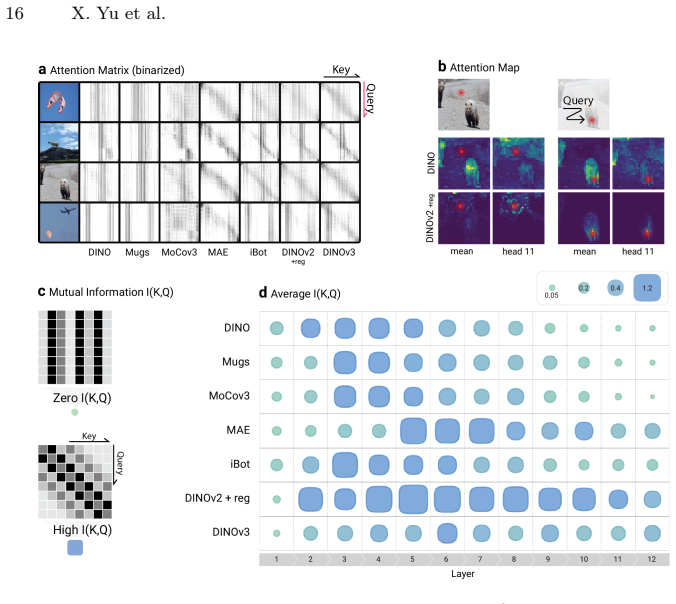
The visualization protocol that renders unsupervised semantic segmentation results from model representations to expose biases and differences across layers.
If this is right
- Insights into distinct positional biases between contrastive and masked image modeling approaches become directly observable.
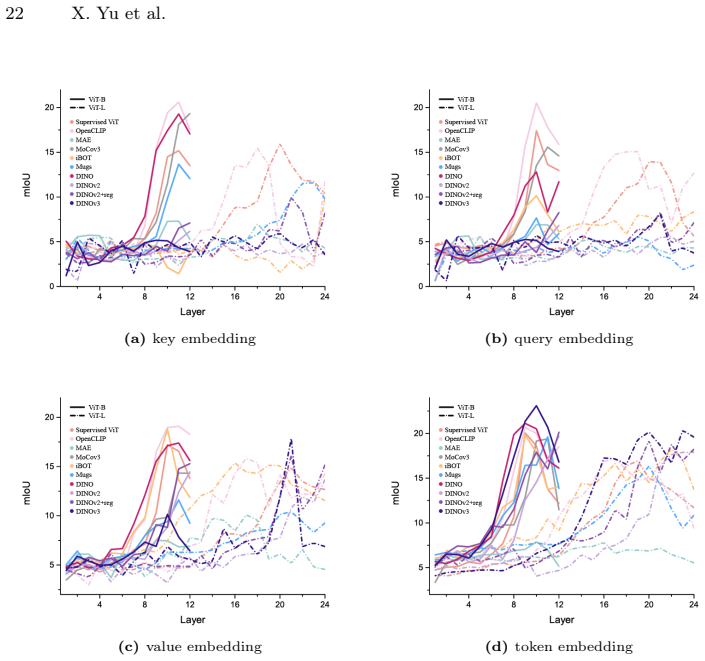
- Strong boundary artifacts appear specifically in DINOv3-Large model tokens.
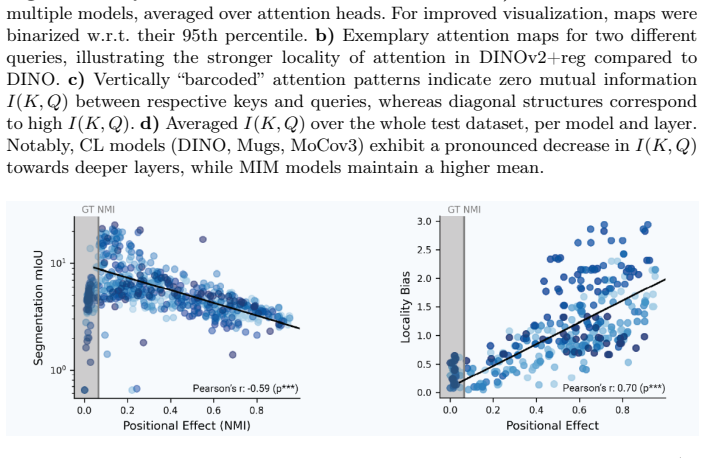
- Positional effects can be visually separated from the related locality bias.
- Previous analyses of self-attention and captured information gain an intuitive visual complement.
Where Pith is reading between the lines
- The protocol could serve as a quick diagnostic when evaluating newly trained SSL models for unintended biases.
- It may extend to comparing representations from supervised versus self-supervised training on the same architecture.
- Visual patterns identified this way could guide targeted interventions to reduce specific artifacts during pretraining.
Load-bearing premise
That unsupervised semantic segmentation results, even when not optimized for segmentation accuracy, reliably surface consistent model behaviors that can be visually distinguished across images and training paradigms.
What would settle it
Running the protocol on the same set of models and images but obtaining visualizations with no repeatable differences between models or layers.
Figures
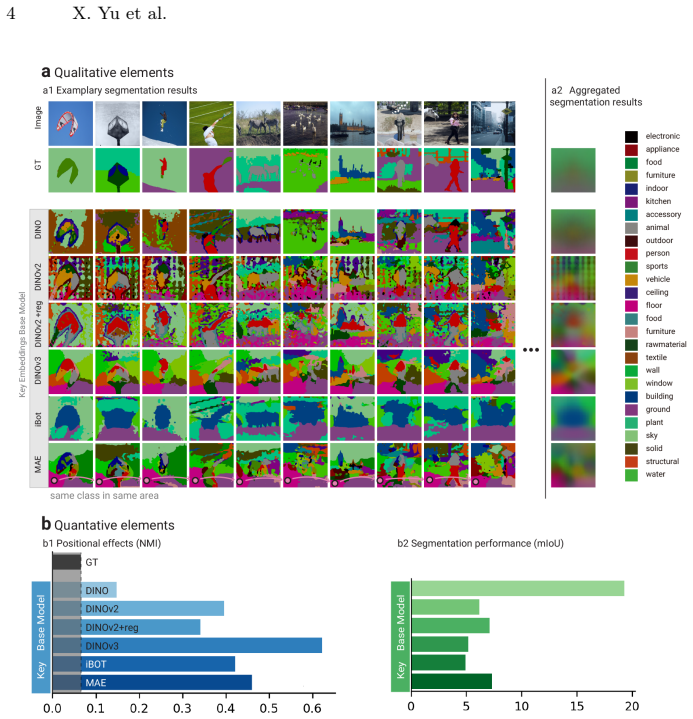

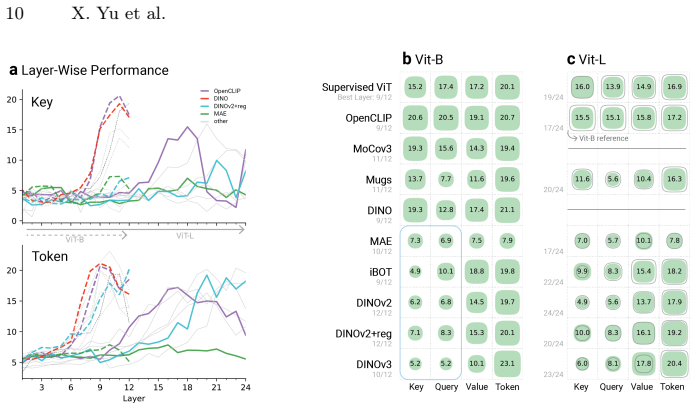
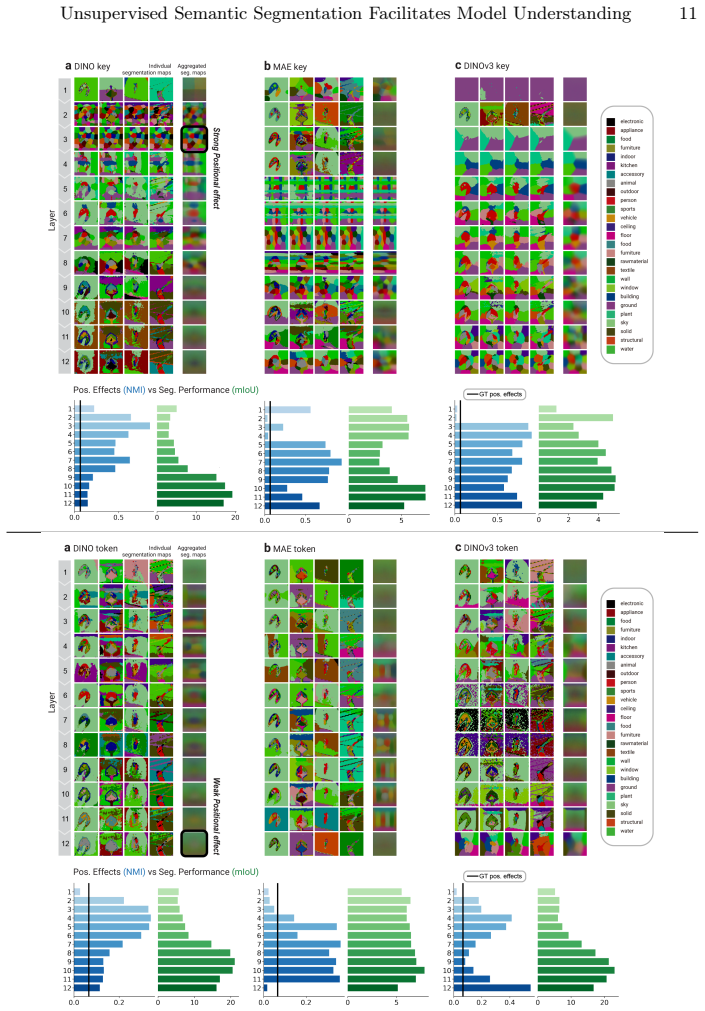
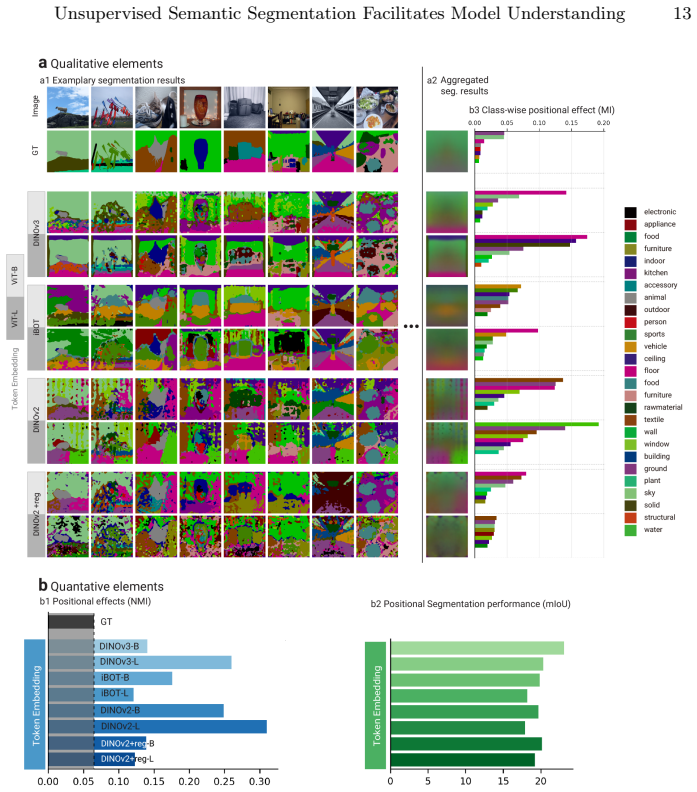






read the original abstract
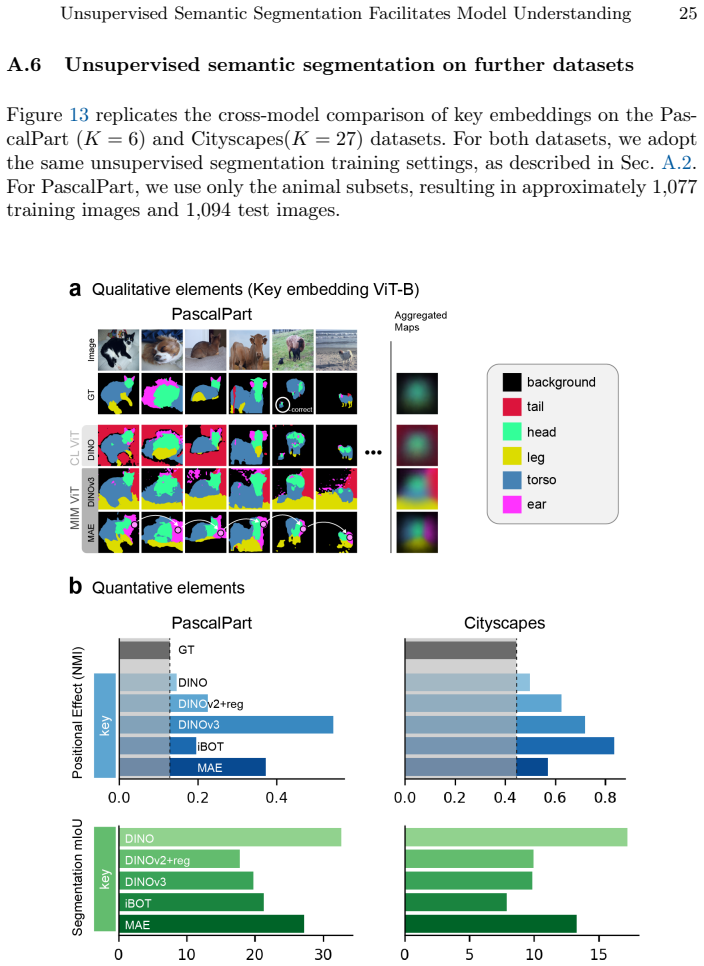
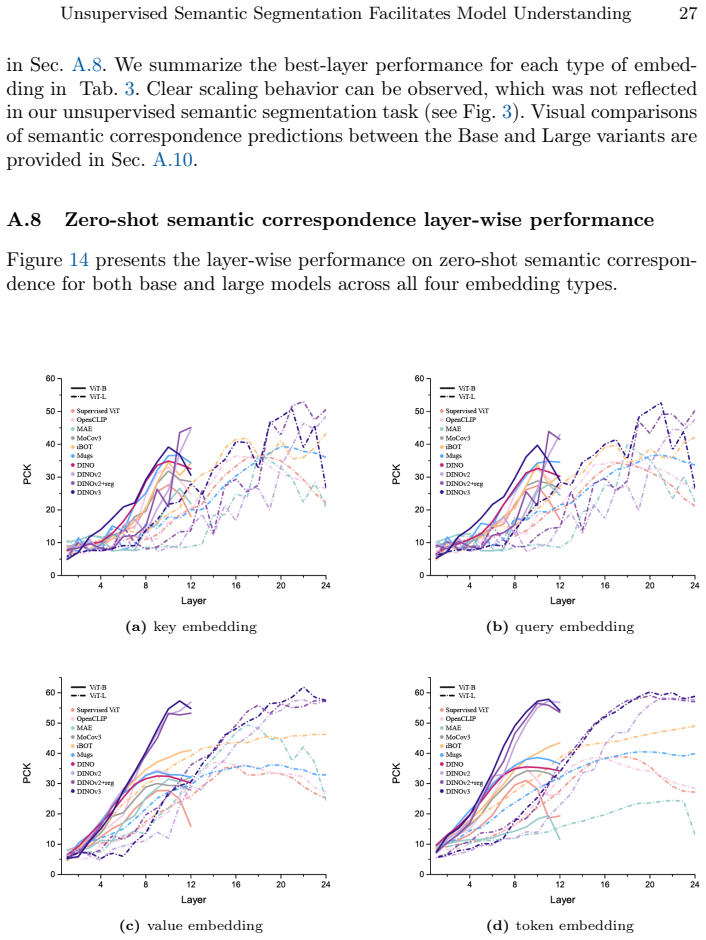
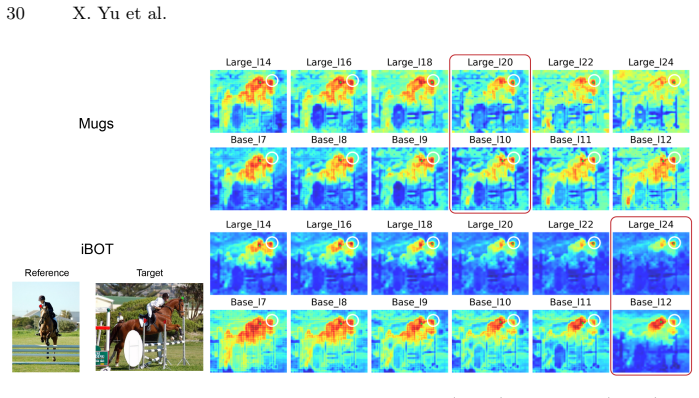
Self-supervised learning (SSL) has produced a diverse landscape of vision transformers (ViTs) whose pretrained representations support a wide range of downstream tasks. Towards a better understanding of these models, a body of work has assessed the mechanics of their self-attention as well as the types of information captured across their representations, revealing, for example, stark differences between models trained with contrastive learning (CL) and masked image modeling (MIM). However, these advances in model understanding have not yet fully permeated the broader community, where insights specific to CL models are sometimes generalized to MIM models. To make model understanding straightforward and intuitive for a broad audience, we propose a simple and easily interpretable visualization protocol. Our protocol is based on visualizing unsupervised semantic segmentation results, yet our goal is not to maximize segmentation performance. Instead, it allows us to convey model behaviors that consistently emerge across images. Benchmarking a diverse set of SSL models across layers and representations, we obtain novel insights into distinct positional biases and scaling behaviors, including strong boundary artifacts in DINOv3-Large model tokens. These insights complement and help communicate a range of previous findings. Our protocol further enables a clear visual distinction between positional effects and the closely related but distinct locality bias, which has been studied much more extensively in the literature. The protocol is publicly available on GitHub and we believe it will catalyze further model understanding for a broad community.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a simple visualization protocol based on unsupervised semantic segmentation outputs from self-supervised vision transformers. The goal is not to achieve high segmentation accuracy but to provide an intuitive way to convey consistent model behaviors (e.g., positional biases, scaling behaviors, and boundary artifacts such as those observed in DINOv3-Large) across images and training paradigms. The work benchmarks multiple SSL models (CL and MIM) across layers and representations, distinguishes positional effects from locality bias, and releases the protocol publicly on GitHub to aid broader model understanding.
Significance. If the visualizations reliably and consistently surface distinguishable behaviors that align with and communicate prior findings on CL vs. MIM differences, the protocol could serve as an accessible tool for the community. The explicit public code release strengthens reproducibility and potential adoption.
major comments (2)
- [Abstract] Abstract: the central claim that the protocol yields 'novel insights' into positional biases, scaling behaviors, and boundary artifacts rests on qualitative observations, yet the provided text contains no quantitative metrics, consistency measures across images, dataset details, or error analysis to substantiate that the surfaced behaviors are reliable and not visualization artifacts.
- The assumption that unsupervised segmentation results (even when unoptimized for accuracy) reliably surface consistent, visually distinguishable model behaviors across training paradigms is load-bearing for the protocol's utility; without explicit validation (e.g., inter-image agreement statistics or comparison to known attention patterns), it remains unclear whether the method generalizes beyond selected examples.
minor comments (1)
- The distinction between positional effects and locality bias is stated as a contribution; the manuscript should include a dedicated paragraph or figure explicitly contrasting the two with references to prior locality-bias literature.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Our protocol is intentionally qualitative and visualization-focused to make model behaviors accessible, rather than a quantitative benchmark. We address the concerns point-by-point below with targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the protocol yields 'novel insights' into positional biases, scaling behaviors, and boundary artifacts rests on qualitative observations, yet the provided text contains no quantitative metrics, consistency measures across images, dataset details, or error analysis to substantiate that the surfaced behaviors are reliable and not visualization artifacts.
Authors: We agree the abstract should better contextualize the qualitative nature of the work. The protocol's purpose is to surface visually consistent behaviors across images for intuitive understanding, complementing (not replacing) quantitative studies in the literature. We will revise the abstract and add a dedicated paragraph in Section 3 to specify the evaluation images (sampled from ImageNet validation), note that consistency is demonstrated via repeated patterns across diverse examples in the figures and supplement, and explicitly state that no quantitative segmentation metrics or error analysis are claimed. This preserves the contribution's focus on accessibility while addressing the request for transparency. revision: partial
-
Referee: The assumption that unsupervised segmentation results (even when unoptimized for accuracy) reliably surface consistent, visually distinguishable model behaviors across training paradigms is load-bearing for the protocol's utility; without explicit validation (e.g., inter-image agreement statistics or comparison to known attention patterns), it remains unclear whether the method generalizes beyond selected examples.
Authors: The manuscript already benchmarks multiple SSL models (CL and MIM) across layers and shows behaviors that align with established differences (e.g., locality in CL vs. global in MIM). We will expand the discussion section to include explicit references to prior attention-map analyses that corroborate the observed positional biases and boundary artifacts, and add a short paragraph on generalization by noting that the released code enables verification on arbitrary images. We maintain that inter-image agreement statistics fall outside the protocol's scope, as it is not positioned as a validated segmentation method but as a visualization aid; adding such metrics would require a separate quantitative study. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper proposes a visualization protocol using unsupervised semantic segmentation outputs to convey consistent model behaviors in SSL ViTs, explicitly stating the goal is not segmentation accuracy. No equations, fitted parameters, predictions, or derivation chains appear in the abstract or description. Benchmarking across layers for positional biases and boundary artifacts is presented as an independent qualitative method with public code release. No self-citation load-bearing steps, self-definitional elements, or reductions of claims to inputs by construction are identifiable, rendering the protocol self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2112.058142(3), 4 (2021)
Amir, S., Gandelsman, Y., Bagon, S., Dekel, T.: Deep vit features as dense visual descriptors. arXiv preprint arXiv:2112.058142(3), 4 (2021)
-
[2]
Balestriero, R., LeCun, Y.: Lejepa: Provable and scalable self-supervised learning without the heuristics (2025),https://arxiv.org/abs/2511.08544
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Perception Encoder: The best visual embeddings are not at the output of the network
Bolya, D., Huang, P.Y., Sun, P., Cho, J.H., Madotto, A., Wei, C., Ma, T., Zhi, J., Rajasegaran, J., Rasheed, H., et al.: Perception encoder: The best visual em- beddings are not at the output of the network. arXiv preprint arXiv:2504.13181 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
In:ProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition
Caesar, H., Uijlings, J., Ferrari, V.: Coco-stuff: Thing and stuff classes in context. In:ProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition. pp. 1209–1218 (2018) 18 X. Yu et al
2018
-
[5]
In: Proceedings of the IEEE/CVF international conference on computer vision
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9650–9660 (2021)
2021
-
[6]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Chen, X., Mottaghi, R., Liu, X., Fidler, S., Urtasun, R., Yuille, A.: Detect what you can: Detecting and representing objects using holistic models and body parts. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1971–1978 (2014)
1971
-
[7]
In: Proceedings of the IEEE/CVF international conference on com- puter vision
Chen, X., Xie, S., He, K.: An empirical study of training self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on com- puter vision. pp. 9640–9649 (2021)
2021
-
[8]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3213–3223 (2016)
2016
-
[9]
Vision Transformers Need Registers
Darcet, T., Oquab, M., Mairal, J., Bojanowski, P.: Vision transformers need reg- isters. arXiv preprint arXiv:2309.16588 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Dehghani, M., Djolonga, J., Mustafa, B., Padlewski, P., Heek, J., Gilmer, J., Steiner, A., Caron, M., Geirhos, R., Alabdulmohsin, I., Jenatton, R., Beyer, L., Tschannen, M., Arnab, A., Wang, X., Riquelme, C., Minderer, M., Puigcerver, J., Evci, U., Kumar, M., van Steenkiste, S., Elsayed, G.F., Mahendran, A., Yu, F., Oliver, A., Huot, F., Bastings, J., Col...
- [11]
-
[12]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[13]
arXiv preprint arXiv:2404.16818 (2024)
Hahn, O., Araslanov, N., Schaub-Meyer, S., Roth, S.: Boosting unsuper- vised semantic segmentation with principal mask proposals. arXiv preprint arXiv:2404.16818 (2024)
-
[14]
arXiv preprint arXiv:2203.08414 (2022)
Hamilton, M., Zhang, Z., Hariharan, B., Snavely, N., Freeman, W.T.: Unsuper- vised semantic segmentation by distilling feature correspondences. arXiv preprint arXiv:2203.08414 (2022)
-
[15]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16000–16009 (2022)
2022
-
[16]
Ilharco, G., Wortsman, M., Wightman, R., Gordon, C., Carlini, N., Taori, R., Dave, A., Shankar, V., Namkoong, H., Miller, J., et al.: Openclip (2021)
2021
- [17]
-
[18]
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer:Hierarchicalvisiontransformerusingshiftedwindows.In:Proceedings of the IEEE/CVF international conference on computer vision. pp. 10012–10022 (2021)
2021
-
[19]
In: Proc
McQueen, J.B.: Some methods of classification and analysis of multivariate ob- servations. In: Proc. of 5th Berkeley Symposium on Math. Stat. and Prob. pp. 281–297 (1967) Unsupervised Semantic Segmentation Facilitates Model Understanding 19
1967
-
[20]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [21]
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Seong, H.S., Moon, W., Lee, S., Heo, J.P.: Leveraging hidden positives for unsu- pervised semantic segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19540–19549 (2023)
2023
-
[23]
The Bell System Tech- nical Journal27, 379–423 (1948),http://plan9.bell- labs.com/cm/ms/what/ shannonday/shannon1948.pdf
Shannon, C.E.: A mathematical theory of communication. The Bell System Tech- nical Journal27, 379–423 (1948),http://plan9.bell- labs.com/cm/ms/what/ shannonday/shannon1948.pdf
1948
-
[24]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Neurocomputing568, 127063 (2024)
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y.: Roformer: Enhanced trans- former with rotary position embedding. Neurocomputing568, 127063 (2024)
2024
- [26]
-
[27]
In: Proceedings of the IEEE/CVF international conference on computer vision
Wang, W., Xie, E., Li, X., Fan, D.P., Song, K., Liang, D., Lu, T., Luo, P., Shao, L.: Pyramid vision transformer: A versatile backbone for dense prediction with- out convolutions. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 568–578 (2021)
2021
-
[28]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, X., Girdhar, R., Yu, S.X., Misra, I.: Cut and learn for unsupervised object detection and instance segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3124–3134 (2023)
2023
-
[29]
IEEE transactions on pattern analysis and machine intelligence45(12), 15790–15801 (2023)
Wang, Y., Shen, X., Yuan, Y., Du, Y., Li, M., Hu, S.X., Crowley, J.L., Vaufreydaz, D.: Tokencut: Segmenting objects in images and videos with self-supervised trans- former and normalized cut. IEEE transactions on pattern analysis and machine intelligence45(12), 15790–15801 (2023)
2023
-
[30]
arXiv preprint arXiv:2502.10385 (2025)
Wu, Z., Zhang, J., Pai, D., Wang, X., Singh, C., Yang, J., Gao, J., Ma, Y.: Simpli- fying dino via coding rate regularization. arXiv preprint arXiv:2502.10385 (2025)
-
[31]
Xie, Z., Geng, Z., Hu, J., Zhang, Z., Hu, H., Cao, Y.: Revealing the dark secrets of masked image modeling. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 14475–14485 (2023).https://doi.org/10. 1109/CVPR52729.2023.01391
-
[32]
In: European Conference on Computer Vision
Yang, J., Luo, K.Z., Li, J., Deng, C., Guibas, L., Krishnan, D., Weinberger, K.Q., Tian, Y., Wang, Y.: Denoising vision transformers. In: European Conference on Computer Vision. pp. 453–469. Springer (2024)
2024
-
[33]
iBOT: Image BERT Pre-Training with Online Tokenizer
Zhou, J., Wei, C., Wang, H., Shen, W., Xie, C., Yuille, A., Kong, T.: ibot: Image bert pre-training with online tokenizer. arXiv preprint arXiv:2111.07832 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[34]
arXiv preprint arXiv:2203.14415 (2022)
Zhou, P., Zhou, Y., Si, C., Yu, W., Ng, T.K., Yan, S.: Mugs: A multi-granular self-supervised learning framework. arXiv preprint arXiv:2203.14415 (2022)
-
[35]
Zhou, T., Xia, W., Zhang, F., Chang, B., Wang, W., Yuan, Y., Konukoglu, E., Cremers,D.:Imagesegmentationinfoundationmodelera:Asurvey.arXivpreprint arXiv:2408.12957 (2024) 20 X. Yu et al. A Supplement A.1 Properties of models included in the benchmark SSL framework Size Dataset Pos. Emb. Category Supervised ViT [12] B,L ImageNet-21K Learned abs Supervised ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.