PhAIL: A Real-Robot VLA Benchmark and Distributional Methodology
Pith reviewed 2026-06-29 06:43 UTC · model grok-4.3
The pith
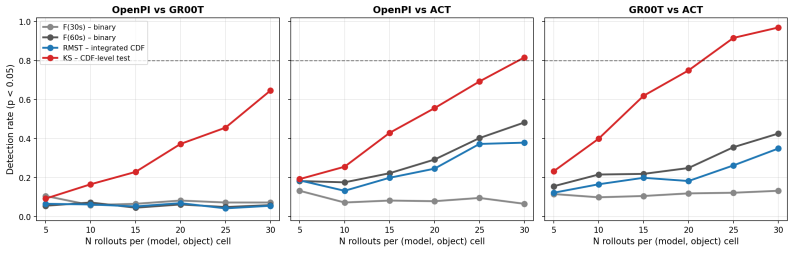
Time-to-success CDFs with KS testing resolve close VLA model differences at N=30 where binary success rates cannot.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
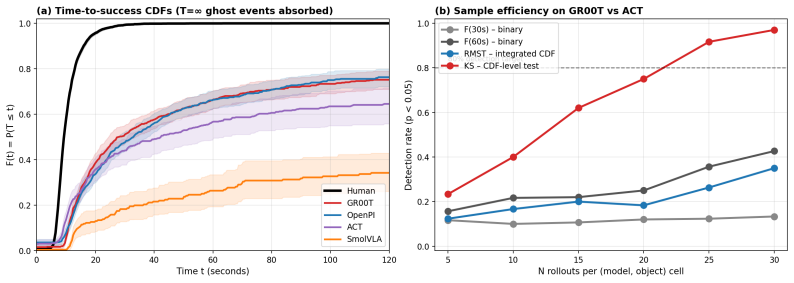
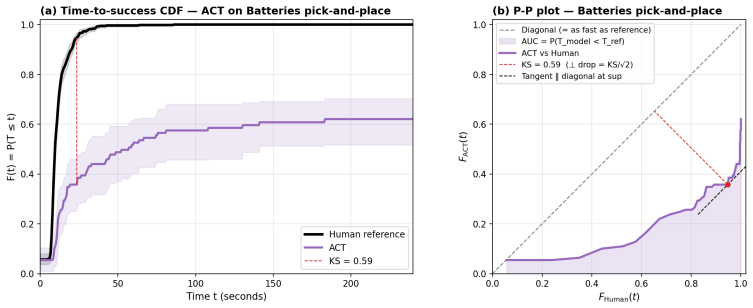
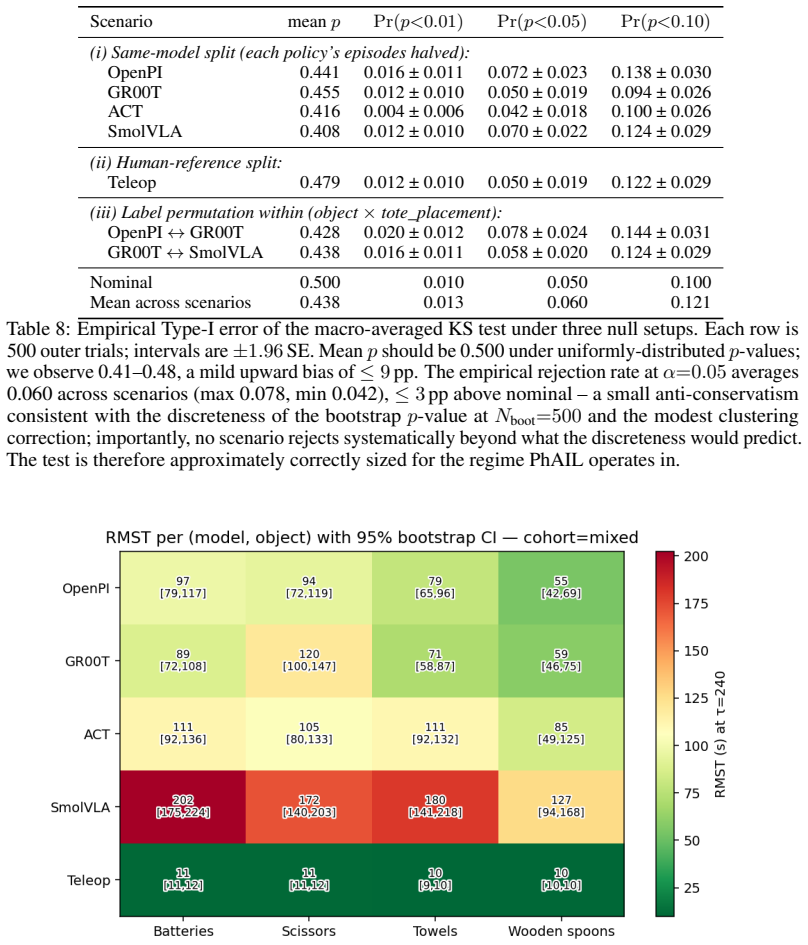
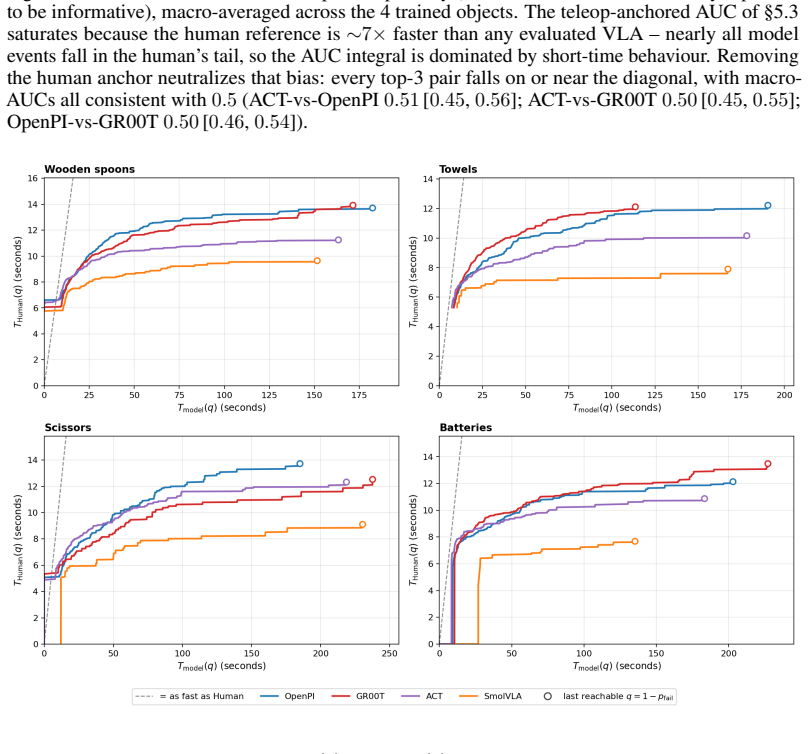
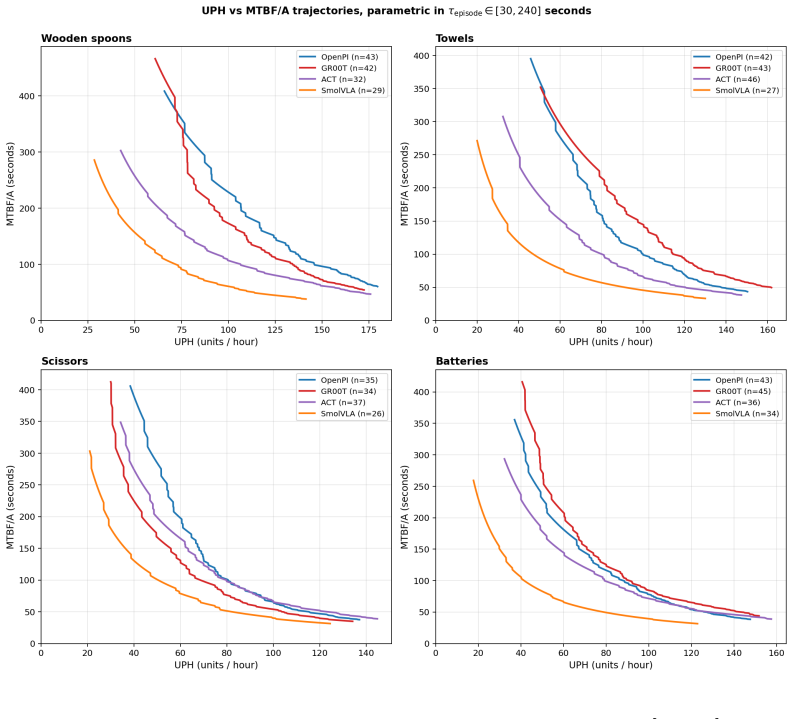
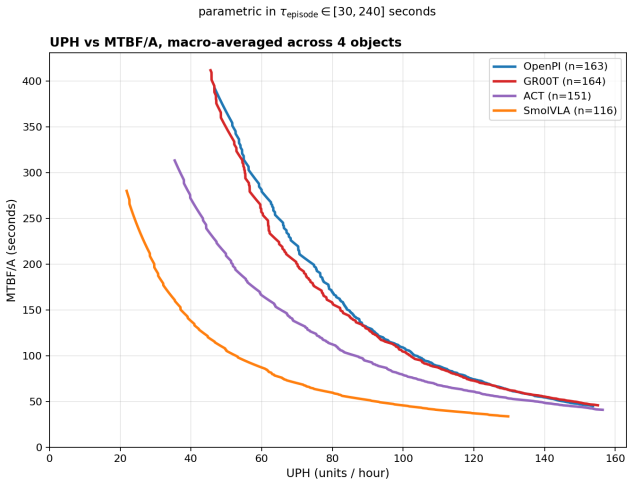
The macro-averaged Kolmogorov-Smirnov test applied to per-object time-to-success CDFs distinguishes two of the three closest VLA pairs (GR00T vs. ACT, OpenPI vs. ACT) at N≤30 rollouts per (model, object) cell, whereas binary success-rate thresholds at fixed timeout do not; the same data yield an RMST ratio showing the best evaluated VLA is approximately 7 times slower than human teleoperation on the same fixtures.
What carries the argument
The time-to-success cumulative distribution function evaluated first by Human-Relative Throughput (a dimensionless scalar with bootstrap intervals) and second by per-object then macro-averaged Kolmogorov-Smirnov significance testing.
If this is right
- VLA comparisons become statistically resolvable with cohorts no larger than 30 rollouts per condition.
- Model rankings can be reported with explicit confidence intervals rather than point estimates of success rate.
- Human teleoperation on identical fixtures supplies a stable, dimensionless reference scale for robot throughput.
- Per-object testing followed by macro-averaging prevents any single object from dominating the overall significance verdict.
Where Pith is reading between the lines
- Adoption would encourage reporting full rollout traces rather than thresholded aggregates, enabling later re-analysis with different cutoffs.
- The same CDF-plus-KS pipeline could be applied to other sequential robotics tasks where latency distributions matter more than binary completion.
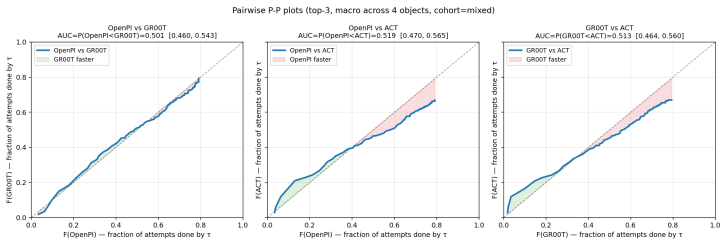
- The unresolved OpenPI-GR00T pair indicates that some model distinctions may require either larger N or a different test statistic even under the distributional approach.
Load-bearing premise
The cumulative distribution of time-to-success supplies a more discriminating and comparable evaluation primitive than binary success at a fixed timeout.
What would settle it
Re-evaluating the same four VLAs at N=30 with the identical fixtures and finding that the macro-averaged KS test no longer yields p-values below 0.05 for the pairs it currently separates would falsify the resolution advantage.
Figures
read the original abstract
Real-world evaluation of vision-language-action (VLA) policies still rests on binary success rate at a fixed timeout with $N \le 25$ rollouts per condition, almost always without confidence intervals or paired statistical comparison; these cohort sizes struggle to resolve close comparisons reliably. We introduce PhAIL (Physical AI Leaderboard, https://phail.ai), an open real-robot benchmark on a Franka FR3 (dataset, per-rollout artifacts, and end-to-end reference implementation) of a distributional evaluation methodology: the time-to-success cumulative distribution function (CDF) as the evaluation primitive, with two separated jobs. The first is scoring via Human-Relative Throughput (HRT), a dimensionless scalar with bootstrap confidence intervals, anchored to same-fixture human teleoperation. The second is a significance test (Kolmogorov-Smirnov, computed per-object and macro-averaged across objects). On four publicly-available VLAs, the macro-averaged KS test resolves two close comparisons (GR00T vs. ACT, OpenPI vs. ACT) at $N \le 30$ rollouts per (model, object) cell where binary-threshold metrics do not; the closest pair (OpenPI vs. GR00T) remains unresolved within our budget. The best evaluated VLA is $\sim 7\times$ slower per operation (RMST ratio) than the human reference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PhAIL, an open real-robot benchmark for vision-language-action (VLA) policies on a Franka FR3 arm. It critiques the standard practice of using binary success rates at fixed timeouts with small sample sizes (N ≤ 25) without statistical comparisons. The proposed methodology uses the time-to-success cumulative distribution function (CDF) as the evaluation primitive, introducing Human-Relative Throughput (HRT) as a dimensionless scalar metric with bootstrap confidence intervals anchored to human teleoperation performance, and employs per-object Kolmogorov-Smirnov (KS) tests that are macro-averaged across objects for significance testing. On four public VLAs, the macro-averaged KS test is shown to resolve two close model comparisons (GR00T vs. ACT and OpenPI vs. ACT) at N ≤ 30 rollouts per (model, object) cell, where binary-threshold metrics fail to do so, while the closest pair (OpenPI vs. GR00T) remains unresolved; additionally, the best VLA is reported to be approximately 7 times slower than the human reference in terms of RMST ratio.
Significance. If the results hold, this work provides a valuable contribution to real-robot VLA evaluation by offering a distributional approach that can distinguish model performances with modest rollout numbers where traditional metrics cannot. The open release of the benchmark, dataset, per-rollout artifacts, and end-to-end reference implementation is a notable strength, promoting reproducibility and allowing the community to build on the distributional methodology. The empirical demonstration that macro-averaged KS tests on time-to-success CDFs can resolve two pairwise comparisons at N ≤ 30 where binary success rates cannot is a concrete, falsifiable finding that advances benchmarking practices in robotics.
minor comments (3)
- The abstract references 'per (model, object) cell' and macro-averaging across objects but does not specify the number of objects or the exact task definitions used for the KS tests; adding this detail in the methods would strengthen verifiability of the reported resolutions.
- The RMST ratio used to quantify the ~7× slowdown relative to human teleoperation is mentioned without an explicit definition or reference to its computation; a brief equation or section reference would clarify this metric.
- Details on data collection protocols, success criteria, and any exclusion rules for rollouts are referenced as necessary for the KS and HRT computations but are not elaborated in the provided abstract; expanding these in the full methods section would address reproducibility concerns.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work, the accurate summary of the PhAIL benchmark and distributional methodology, and the recommendation for minor revision. We appreciate the recognition of the open release of the benchmark, dataset, and reference implementation, as well as the concrete empirical demonstration regarding macro-averaged KS tests.
Circularity Check
No significant circularity identified
full rationale
The paper introduces an empirical benchmark (PhAIL) and distributional methodology using the time-to-success CDF as primitive, with HRT anchored to external human teleoperation data and standard Kolmogorov-Smirnov tests applied per-object then macro-averaged. No load-bearing steps reduce by the paper's equations or self-citation to the paper's own inputs; the central claims consist of direct empirical comparisons on four public VLAs at N≤30, with no self-definitional metrics, fitted parameters renamed as predictions, or uniqueness theorems imported from prior author work. The methodology treats CDF/HRT/KS as alternative evaluation primitives rather than deriving them from the target results.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Kolmogorov-Smirnov test appropriately compares empirical CDFs of time-to-success across models and objects
invented entities (1)
-
Human-Relative Throughput (HRT)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Nonparametric Estimation from Incomplete Observations
Kaplan, E.L., Meier, P. Nonparametric Estimation from Incomplete Observations. Journal of the American Statistical Association, 53(282):457–481, 1958
1958
-
[2]
Evaluation of Survival Data and Two New Rank Order Statistics Arising in its Consideration
Mantel, N. Evaluation of Survival Data and Two New Rank Order Statistics Arising in its Consideration. Cancer Chemotherapy Reports, 50(3):163–170, 1966. 10
1966
-
[3]
Table for Estimating the Goodness of Fit of Empirical Distributions
Smirnov, N.V . Table for Estimating the Goodness of Fit of Empirical Distributions. Annals of Mathematical Statistics, 19(2):279–281, 1948
1948
-
[4]
An Introduction to the Bootstrap
Efron, B., Tibshirani, R.J. An Introduction to the Bootstrap. Chapman & Hall, 1993
1993
-
[5]
Testing Statistical Hypotheses, 3rd ed
Lehmann, E.L., Romano, J.P. Testing Statistical Hypotheses, 3rd ed. Springer, 2005
2005
-
[6]
Probable Inference, the Law of Succession, and Statistical Inference
Wilson, E.B. Probable Inference, the Law of Succession, and Statistical Inference. Journal of the American Statistical Association, 22(158):209–212, 1927
1927
-
[7]
Note on the Sampling Error of the Difference Between Correlated Proportions or Percentages
McNemar, Q. Note on the Sampling Error of the Difference Between Correlated Proportions or Percentages. Psychometrika, 12(2):153–157, 1947
1947
-
[8]
Sample Size for Testing Differences in Proportions for the Paired-Sample Design
Connor, R.J. Sample Size for Testing Differences in Proportions for the Paired-Sample Design. Biometrics, 43(1):207–211, 1987
1987
-
[9]
Visualization SDK for Multimodal Data.https://rerun.io, 2024
Rerun.io. Visualization SDK for Multimodal Data.https://rerun.io, 2024
2024
-
[10]
https://github.com/Positronic-Robotics/positronic, 2025
Positronic Robotics.positronic: Open-source framework for real-robot evaluation and operation. https://github.com/Positronic-Robotics/positronic, 2025
2025
-
[11]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Khazatsky et al. DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset. RSS, 2024
2024
-
[12]
RoboChallenge: Large-scale Real-robot Evaluation of Embodied Policies
Tang et al. RoboChallenge: Large-scale Real-robot Evaluation of Embodied Policies. arXiv:2510.17950, 2025
-
[13]
RoboArena: Distributed Real-World Evaluation of Generalist Robot Policies
Atreya et al. RoboArena: Distributed Real-World Evaluation of Generalist Robot Policies. arXiv:2506.18123, 2025
-
[14]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Nasiriany et al. RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots. arXiv, 2024
2024
-
[15]
CALVIN: A Benchmark for Language-Conditioned Policy Learning for Long- Horizon Robot Manipulation
Mees et al. CALVIN: A Benchmark for Language-Conditioned Policy Learning for Long- Horizon Robot Manipulation. IEEE RA-L, 2022
2022
-
[16]
ManiSkill3: GPU Parallelized Robotics Simulation and Benchmarking at Scale
Gu et al. ManiSkill3: GPU Parallelized Robotics Simulation and Benchmarking at Scale. arXiv:2410.00425, 2024
-
[17]
Evaluating Real-World Robot Manipulation Policies in Simulation
Li et al. Evaluating Real-World Robot Manipulation Policies in Simulation. arXiv, 2024
2024
-
[18]
Research Challenges and Progress in Robotic Grasping and Manipulation Competitions
Sun, Falco, Roa, Calli. Research Challenges and Progress in Robotic Grasping and Manipulation Competitions. IEEE Robotics and Automation Letters, 2022
2022
-
[19]
OCRTOC: A Cloud-Based Competition and Benchmark for Robotic Grasping and Manipulation
Liu et al. OCRTOC: A Cloud-Based Competition and Benchmark for Robotic Grasping and Manipulation. IEEE Robotics and Automation Letters, 2021
2021
-
[20]
NIST Assembly Task Boards: Performance Metrics and Test Methods for Robotic Assembly
Falco et al. NIST Assembly Task Boards: Performance Metrics and Test Methods for Robotic Assembly. NIST IR / IEEE, ongoing
-
[21]
A Robust Real Robot Baseline for the Real Robot Challenge
Bauer et al. A Robust Real Robot Baseline for the Real Robot Challenge. NeurIPS Datasets and Benchmarks, 2022
2022
-
[22]
Digital Robot Judge: Building a Task- centric Performance Database of Real-World Manipulation With Electronic Task Boards
So, Sarabakha, Wu, Culha, Abu-Dakka, Haddadin. Digital Robot Judge: Building a Task- centric Performance Database of Real-World Manipulation With Electronic Task Boards. IEEE Robotics & Automation Magazine, 2023
2023
-
[23]
Robot Learning as an Empirical Science: Best Practices for Policy Evaluation
Kress-Gazit, Hashimoto, Kuppuswamy, Shah, Horgan, Richardson, Feng, Burchfiel. Robot Learning as an Empirical Science: Best Practices for Policy Evaluation. arXiv:2409.09491, 2024
-
[24]
A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation
TRI LBM Team, Barreiros et al. A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation. arXiv:2507.05331, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Deep Reinforcement Learning at the Edge of the Statistical Precipice
Agarwal, Schwarzer, Castro, Courville, Bellemare. Deep Reinforcement Learning at the Edge of the Statistical Precipice. NeurIPS, 2021. 11
2021
-
[26]
Deep Reinforcement Learning That Matters
Henderson, Islam, Bachman, Pineau, Precup, Meger. Deep Reinforcement Learning That Matters. AAAI, 2018
2018
-
[27]
Is Your Imitation Learning Policy Better than Mine? Policy Comparison with Near-Optimal Stopping
Snyder et al. Is Your Imitation Learning Policy Better than Mine? Policy Comparison with Near-Optimal Stopping. arXiv:2503.10966, 2025
-
[28]
Human-level Control through Deep Reinforcement Learning
Mnih et al. Human-level Control through Deep Reinforcement Learning. Nature, 2015
2015
-
[29]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Black et al. ( π0.5): a Vision-Language-Action Model with Open-World Generalization. arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA et al. GR00T N1: An Open Foundation Model for Generalist Humanoid Robots. arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Zhao, Kumar, Levine, Finn. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware. RSS, 2023 (arXiv:2304.13705)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Shukor et al. SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics. arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
RT-1: Robotics Transformer for Real-World Control at Scale
Brohan et al. RT-1: Robotics Transformer for Real-World Control at Scale. RSS, 2023 (arXiv:2212.06817)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Brohan et al. RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. CoRL, 2023 (arXiv:2307.15818)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration. Open X-Embodiment: Robotic Learning Datasets and RT-X Models. ICRA, 2024 (arXiv:2310.08864)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim et al. OpenVLA: An Open-Source Vision-Language-Action Model. CoRL, 2024 (arXiv:2406.09246)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black et al. π0: A Vision-Language-Action Flow Model for General Robot Control. arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Black et al.π 0.6: a VLA That Learns from Experience. arXiv:2511.14759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation
Fu et al. Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation. CoRL, 2024 (arXiv:2401.02117)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Robotic Control via Embodied Chain-of-Thought Reasoning
Zawalski et al. Robotic Control via Embodied Chain-of-Thought Reasoning. CoRL, 2024 (arXiv:2407.08693). A Survey of Recent VLA Evaluation Practice Table 5 surveys 13 recent real-robot VLA papers from 2023–2025; the LBM examination [ 24] is included below the rule as the single recent counter-example. Modal per-condition N is 10–20; none of the 13 standard...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.