Teaching Language Models to Check Grounded Claim Factuality with Human Test-Taking Strategies
Pith reviewed 2026-06-29 07:32 UTC · model grok-4.3
The pith
Prompting language models with human test-taking strategies for true/false reading comprehension reduces token use over 80 percent while matching or beating costly factuality checkers on benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By formulating grounded claim factuality checking as a true/false reading comprehension task and prompting LLMs with explicit test-taking strategies, the method reduces token usage by over 80 percent compared to unguided open-ended reasoning, achieves competitive performance to more expensive alternatives across two factuality benchmarks, and sets a new state of the art on one. Small language models trained with supervised fine-tuning and a self-revision mechanism then replace the LLMs in the pipeline while performing on par with strong baselines, maintaining low inference costs, and generating supporting rationales.
What carries the argument
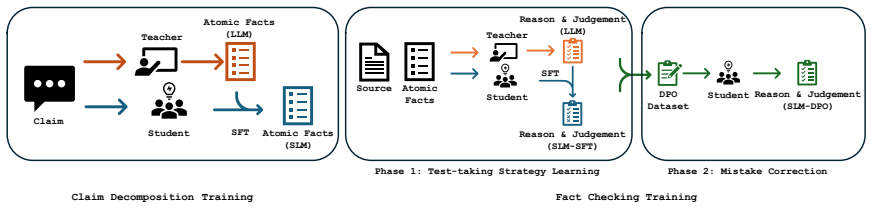
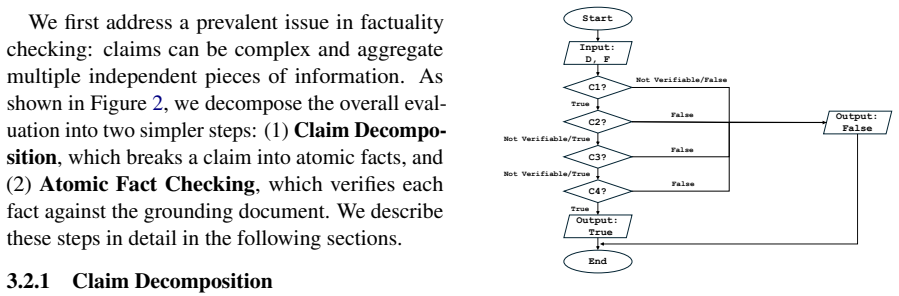
Explicit test-taking strategies supplied via prompting inside a true/false reading comprehension formulation of the factuality task, which steers the model through efficient, structured reasoning about whether evidence supports or contradicts the claim.
If this is right
- Factuality checking pipelines can run with over 80 percent lower token consumption than unguided LLM reasoning.
- Small language models become practical substitutes for larger models after supervised fine-tuning and self-revision on this task.
- The generated rationales add interpretability without increasing inference cost.
- No dataset-specific threshold tuning is required unlike entailment-classifier metrics.
Where Pith is reading between the lines
- The same strategy-prompting pattern could be tested on other structured reasoning tasks such as multi-step evidence aggregation.
- Combining the approach with retrieval modules might produce end-to-end verification systems that stay efficient at scale.
- Self-revision training on small models may allow further gains on out-of-distribution claims without collecting new labeled data.
Load-bearing premise
The selected human test-taking strategies transfer effectively to LLMs through prompting and the two benchmarks adequately represent real-world grounded claim verification needs without domain-specific tuning.
What would settle it
An experiment on a new set of claims drawn from a different domain where the strategy-prompted models use more tokens or score lower than unguided open-ended prompting or tuned entailment classifiers would falsify the efficiency and transfer claims.
Figures

read the original abstract
Grounded claim factuality checking is important for large language model (LLM) applications such as retrieval-augmented generation, as it helps users assess the correctness of generated outputs. Existing metrics using entailment classifiers require dataset-specific threshold tuning, while LLM-based approaches often use direct prompting, which underutilises the reasoning capabilities of LLMs. We address this by formulating grounded claim factuality checking as a true/false reading comprehension task and prompting LLMs with explicit test-taking strategies for efficient reasoning. Our method reduces token usage by over 80% compared to unguided open-ended reasoning, and achieves competitive performance to more expensive alternatives across two factuality benchmarks, setting a new state of the art on one. To further reduce inference cost, we train small language models (SLMs) to replace LLMs in the checking pipeline. Using supervised fine-tuning (SFT) and a self-revision mechanism, the SLMs learn to improve their factuality judgements. Experimental results show that the resulting SLMs perform on par with strong baselines, combining low inference costs with generating supporting rationales to support interpretability. Code and datasets will be released upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that framing grounded claim factuality checking as a true/false reading comprehension task and prompting LLMs with explicit human test-taking strategies enables efficient reasoning. It reports >80% token reduction vs. unguided open-ended reasoning, competitive performance to more expensive methods across two benchmarks (new SOTA on one), and that SLMs trained with SFT plus self-revision match strong baselines at low cost while producing supporting rationales. Code and datasets will be released.
Significance. If the efficiency gains and performance hold after isolating the contribution of the strategies, the work offers a practical route to lower-cost, interpretable factuality checking for RAG and similar applications. The planned code release is a clear strength that would support reproducibility.
major comments (2)
- [§5 (Experiments) and Table 2] §5 (Experiments) and Table 2: the 80%+ token reduction is shown only against an unguided open-ended baseline; without an ablation that applies the true/false output format without the test-taking strategies, it is unclear whether the savings are attributable to the strategies or simply to constraining the output format. This directly affects the central claim that the strategies enable efficient reasoning.
- [Abstract and §5.3] Abstract and §5.3: performance is described as competitive and SOTA on one benchmark, yet no statistical significance tests, error bars, or precise data-split details are reported, weakening the ability to evaluate whether the gains are robust.
minor comments (2)
- [§3 (Method)] §3 (Method): the mapping from human test-taking strategies to prompt templates would be clearer with one or two concrete prompt examples.
- [Figure 1] Figure 1: axis labels and legend text are small and hard to read at standard print size.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work framing grounded claim factuality checking with test-taking strategies. The comments help strengthen the presentation of efficiency gains and empirical robustness. We respond to each major comment below.
read point-by-point responses
-
Referee: [§5 (Experiments) and Table 2] the 80%+ token reduction is shown only against an unguided open-ended baseline; without an ablation that applies the true/false output format without the test-taking strategies, it is unclear whether the savings are attributable to the strategies or simply to constraining the output format. This directly affects the central claim that the strategies enable efficient reasoning.
Authors: We agree that an ablation isolating the true/false format from the full set of test-taking strategies would more precisely attribute the efficiency gains. Our current baseline uses unguided open-ended reasoning, and the strategies are intended to operate within the true/false task framing. We will add this ablation experiment to the revised manuscript to directly address the contribution of the strategies. revision: yes
-
Referee: [Abstract and §5.3] performance is described as competitive and SOTA on one benchmark, yet no statistical significance tests, error bars, or precise data-split details are reported, weakening the ability to evaluate whether the gains are robust.
Authors: We concur that reporting statistical significance, error bars, and explicit data-split details would improve evaluation of robustness. In the revision we will add these elements, including appropriate significance tests and standard deviations, along with precise descriptions of the train/validation/test splits used. revision: yes
Circularity Check
No significant circularity; claims rest on external benchmarks
full rationale
The paper presents its method as a prompting formulation (true/false reading comprehension with test-taking strategies) evaluated via direct comparisons on two external factuality benchmarks and token counts against an unguided baseline. No equations, fitted parameters renamed as predictions, self-citations used as load-bearing uniqueness theorems, or self-definitional reductions appear in the abstract or described claims. Performance and efficiency results are positioned as empirical outcomes rather than constructions internal to the derivation chain, making the work self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Towards question-answering as an automatic metric for evaluating the content quality of a sum- mary.Transactions of the Association for Computa- tional Linguistics, 9:774–789. Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, and 1 others. 2024. The llama 3 h...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
FactCG: Enhancing fact checkers with graph- based multi-hop data. InProceedings of the 2025 Conference of the Nations of the Americas Chap- ter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Pa- pers), pages 5002–5020, Albuquerque, New Mexico. Association for Computational Linguistics. Chin-Yew Lin. 2004. RO...
-
[3]
Liyan Tang, Tanya Goyal, Alex Fabbri, Philippe La- ban, Jiacheng Xu, Semih Yavuz, Wojciech Kryscin- ski, Justin Rousseau, and Greg Durrett
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. Liyan Tang, Tanya Goyal, Alex Fabbri, Philippe La- ban, Jiacheng Xu, Semih Yavuz, Wojciech Kryscin- ski, Justin Rousseau, and Greg Durrett. 2023. Un- derstanding factual errors in summarization: Errors, summariz...
2023
-
[4]
Yuxuan Ye, Edwin Simpson, and Raul Santos Rodriguez
Effects of reading strategy instruction in en- glish as a second language on students’ academic reading comprehension.Language Teaching Re- search, 27(6):1456–1479. Yuxuan Ye, Edwin Simpson, and Raul Santos Rodriguez
-
[5]
Weizhe Yuan, Graham Neubig, and Pengfei Liu
Using similarity to evaluate factual consistency in summaries.arXiv preprint arXiv:2409.15090. Yuheng Zha, Yichi Yang, Ruichen Li, and Zhiting Hu
-
[6]
BERTScore: Evaluating Text Generation with BERT
AlignScore: Evaluating factual consistency with a unified alignment function. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 11328–11348, Toronto, Canada. Association for Computational Linguistics. Muru Zhang, Ofir Press, William Merrill, Alisa Liu, and Noah A. Smith. 2024. How lan...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Final Answer: yes
have demonstrated the influence of dy- namic thresholding on these two metrics. We show the results with and without dynamic thresholds in Table 11 below. The dynamic threshold does not affect the overall conclu- sions in our paper. Metric ThresholdTuningFacTax-Benchmark LLM-AggreFact Baseline FactCG ✓ 71.0 77.2/times67.0 75.6 MiniCheck-DeBERTa✓ 66.1 74.1...
2020
-
[10]
Final Answer: yes
Look at the relationships between the object and the subject, is their relationship mentioned? If not, can the relationship be inferred from the article? If the relationship stands, can the previous information not mentioned be inferred from the article? Table 16: The prompt for fact checking. Only in ablation study,<claim>refers to a original claim. Othe...
2001
-
[11]
Does the claim explicitly mention both the subject and the object?
-
[12]
Final Answer: no
If both are mentioned, can the information connecting them be verified using the article? If some details are missing, carry those forward to the next step. If the information is verifiable but incorrect, stop and respond with “Final Answer: no.”
-
[13]
Final Answer: yes
Examine the relationship between the subject and the object. Is this relationship stated in the article? If not, can it reasonably be inferred? If the relationship is valid, determine whether any previously missing information can also be inferred from the article. Table 20: The fact-checking prompt paraphrased by ChatGPT. Read the article given below and...
-
[14]
Does the claim explicitly identify both the subject and the object?
-
[15]
If details are missing but not contradicted, proceed to the next step
If both entities are present, is the provided detail supported by the text? If the data is present but contradicts the source, mark as "no" and terminate. If details are missing but not contradicted, proceed to the next step
-
[16]
Final Answer: yes
Is the connection between the entities stated or clearly implied? If a relationship exists, determine if any previously missing details can be logically deduced from the source material. Table 21: The fact-checking prompt paraphrased by Gemini. F Qualitative Study Example Prompt Read the article given below and answer the questions. ARTICLE: The adapted a...
-
[17]
For the claim, are the object and the subject mentioned?
-
[18]
Final Answer: no
If the object and the subject are mentioned, is their related information verifiable according to the article? If there is information not mentioned, carry it into the next question. If verifiable but incorrect, stop here and answer "Final Answer: no"
-
[19]
- The Beatles album sleeve topped a list of the most valuable rare records
Look at the relationships between the object and the subject, is their relationship mentioned? If not, can the relationship be inferred from the article? If the relationship stands, can the previous information not mentioned be inferred from the article? Facts from the LLM - A Beatles album sleeve was designed by Sir Peter Blake. - The Beatles album sleev...
-
[20]
"Sir Peter Blake
Yes, both the object and the subject are mentioned. - The subject is ""Sir Peter Blake"". - The object is ""a Beatles album sleeve""
-
[21]
"Sir Peter Blake’s original Sgt Pepper collage was doctored
Yes, the related information is verifiable according to the article. - The article states: ""Sir Peter Blake’s original Sgt Pepper collage was doctored..."" - This confirms that Sir Peter Blake created the original artwork for the Sgt Pepper’s Lonely Hearts Club Band album, which is a Beatles album sleeve. - Therefore, the connection between Sir Peter Bla...
-
[22]
- The article explicitly states that Sir Peter Blake created the original artwork for the Sgt Pepper’s Lonely Hearts Club Band album
Yes, the relationship between the subject and the object is directly mentioned in the article. - The article explicitly states that Sir Peter Blake created the original artwork for the Sgt Pepper’s Lonely Hearts Club Band album. - This confirms the relationship: Sir Peter Blake designed the album sleeve. - No additional information needs to be inferred, a...
-
[23]
Yes, both the object (a Beatles album sleeve) and the subject (Sir Peter Blake) are mentioned in the article
-
[24]
"Sir Peter Blake’s original Sgt Pepper collage was doctored to replace the faces of The Beatles and other notable figures with those of executives from the band’s US label Capitol
Yes, the information is verifiable according to the article. The article states: ""Sir Peter Blake’s original Sgt Pepper collage was doctored to replace the faces of The Beatles and other notable figures with those of executives from the band’s US label Capitol."" This confirms that a Beatles album sleeve was designed by Sir Peter Blake
-
[25]
"The Speciality Steels division
The relationship between the object (a Beatles album sleeve) and the subject (Sir Peter Blake) is explicitly mentioned in the article — Sir Peter Blake designed the original Sgt Pepper collage, which was a Beatles album sleeve. This relationship is clearly stated and supported. Final Answer: yes Table 22: An example from the benchmark. The pinpointed info...
-
[26]
"based"" in Rotherham—only that it has a factory there. The word
The article states that the division has factories in Rotherham and Stocksbridge. Therefore, the presence of a factory in Rotherham is verifiable and mentioned. However, the article does not explicitly state that the division itself is ""based"" in Rotherham—only that it has a factory there. The word ""based"" could imply headquarters or primary operation...
-
[27]
is based in Rotherham,
The relationship between the Speciality Steels division and Rotherham is that the division has a factory in Rotherham. However, the claim says the division “is based in Rotherham,” which implies a primary or organizational base, not just a factory location. While it is possible to infer that Rotherham is a key location for the division, it cannot be defin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.