Efficient, Validation-Free Intrinsic Quality Estimation for Large-Scale Face Recognition Datasets
Pith reviewed 2026-06-29 08:32 UTC · model grok-4.3
The pith
Intrinsic Quality metric estimates face recognition dataset potential without validation or full training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
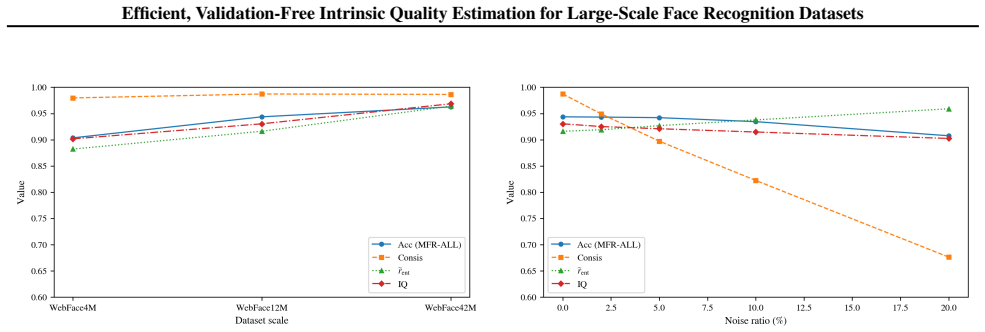
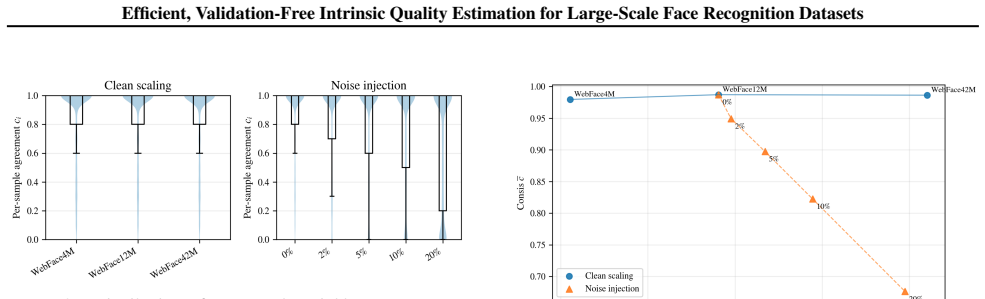
The central claim is that IQ, formed by integrating Neighbor-Consistency Score quantifying local identity label agreement via nearest neighbors and Global Representation Subspace Complexity via Effective Rank capturing embedding geometry and diversity, can predict downstream performance and enable rapid evaluation on lightweight proxies or subsets for clean, noisy, and mixed datasets.
What carries the argument
Intrinsic Quality (IQ) score that merges Neighbor-Consistency Score and Effective Rank to assess dataset quality.
Load-bearing premise
The Neighbor-Consistency Score and Effective Rank together reliably predict downstream face recognition model performance across clean, noisy, and mixed datasets.
What would settle it
Observing that datasets with high IQ scores produce lower performing models than those with low IQ scores after full training would falsify the central claim.
Figures
read the original abstract
We propose Intrinsic Quality (IQ), a validation-free metric designed to estimate the inherent potential of face recognition (FR) datasets to produce high-performance models without the need for full-scale training. IQ integrates two components: (i) a Neighbor-Consistency Score that quantifies local identity label agreement via nearest neighbors, and (ii) Global Representation Subspace Complexity (Effective Rank, ER), which captures the underlying embedding geometry and dataset diversity. IQ allows for rapid evaluation using lightweight proxy models or data subsets, facilitating dataset diagnosis and curation prior to resource-intensive full-scale training. We describe an experimental protocol tailored to clean, noisy, and mixed-quality FR datasets, and outline evaluation methodologies to validate IQ's predictive power for downstream performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Intrinsic Quality (IQ), a validation-free metric to estimate the potential of face recognition (FR) datasets to yield high-performance models without full-scale training. IQ integrates a Neighbor-Consistency Score (local identity label agreement via nearest neighbors) and Global Representation Subspace Complexity via Effective Rank (ER) of the embedding geometry and diversity. It supports rapid evaluation with lightweight proxy models or data subsets for dataset diagnosis and curation. The manuscript describes an experimental protocol for clean, noisy, and mixed-quality FR datasets and outlines evaluation methodologies to validate IQ's predictive power for downstream performance.
Significance. If the claimed predictive correlation holds, the metric would be significant for efficient, low-cost dataset curation in large-scale face recognition, reducing reliance on full training runs to assess data quality and enabling better handling of noisy or mixed datasets.
major comments (2)
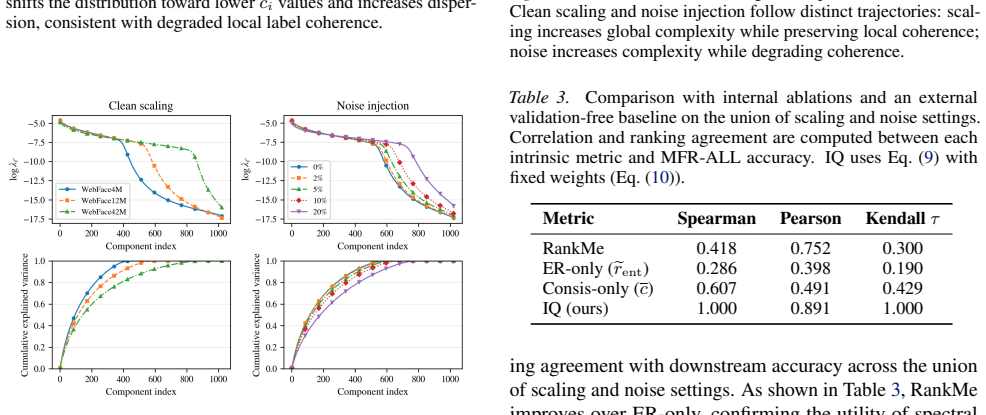
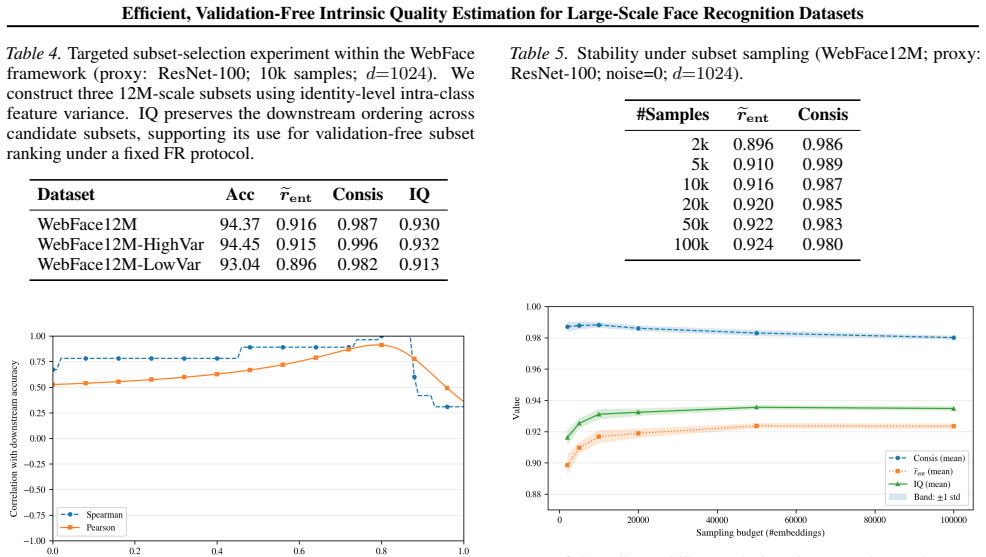
- [Abstract / Evaluation methodologies] Abstract and evaluation methodologies section: The manuscript describes the IQ components and outlines evaluation methodologies to validate predictive power but reports no empirical results, correlation coefficients, ablation studies, or head-to-head comparisons showing that Neighbor-Consistency Score + Effective Rank correlates with downstream FR verification accuracy on clean, noisy, or mixed datasets. This is load-bearing for the central claim.
- [Neighbor-Consistency Score] Neighbor-Consistency Score description: No details are provided on the choice of k for nearest neighbors, the distance metric in embedding space, or handling of label noise, which are necessary to assess whether the score reliably quantifies local agreement as claimed.
minor comments (1)
- [Abstract] The abstract refers to 'lightweight proxy models' without specifying their architecture or training regime relative to the full model.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment below and will revise the paper to strengthen the empirical validation and implementation details.
read point-by-point responses
-
Referee: [Abstract / Evaluation methodologies] Abstract and evaluation methodologies section: The manuscript describes the IQ components and outlines evaluation methodologies to validate predictive power but reports no empirical results, correlation coefficients, ablation studies, or head-to-head comparisons showing that Neighbor-Consistency Score + Effective Rank correlates with downstream FR verification accuracy on clean, noisy, or mixed datasets. This is load-bearing for the central claim.
Authors: The current manuscript emphasizes the definition of the IQ metric and the experimental protocol for clean/noisy/mixed datasets, without including numerical results. We agree this is a gap for the central claim. In revision, we will add empirical results including correlation coefficients, ablation studies on the two components, and head-to-head comparisons of IQ against downstream verification accuracy. revision: yes
-
Referee: [Neighbor-Consistency Score] Neighbor-Consistency Score description: No details are provided on the choice of k for nearest neighbors, the distance metric in embedding space, or handling of label noise, which are necessary to assess whether the score reliably quantifies local agreement as claimed.
Authors: We will expand the Neighbor-Consistency Score section in the revised manuscript to specify the value of k, the distance metric (cosine similarity in embedding space), and the method for handling label noise during neighbor agreement computation. revision: yes
Circularity Check
No derivation chain or self-referential steps; metric proposal is self-contained
full rationale
The paper proposes IQ as a composite metric (Neighbor-Consistency Score via k-NN label agreement plus Effective Rank of embedding subspace) and describes an experimental protocol plus evaluation outline to test its correlation with downstream FR performance. No equations, fitted parameters renamed as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text. The central claim is a definition of a new diagnostic tool plus a validation plan, not a reduction of any result to its own inputs by construction. This is the normal non-circular case for a metrics paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M., and Zisserman, A
Cao, Q., Shen, L., Xie, W., Parkhi, O. M., and Zisserman, A. Vggface2: A dataset for recognising faces across pose and age. In2018 13th IEEE international conference on automatic face & gesture recognition (FG 2018), pp. 67–74. IEEE,
2018
-
[2]
X-factor: Quality is a dataset-intrinsic property.arXiv preprint arXiv:2505.22813,
Couch, J., Li, M., Arnaout, R., and Arnaout, R. X-factor: Quality is a dataset-intrinsic property.arXiv preprint arXiv:2505.22813,
-
[3]
arXiv preprint arXiv:2408.14358 (2024)
Di Salvo, F., Doerrich, S., Rieger, I., and Ledig, C. An em- bedding is worth a thousand noisy labels.arXiv preprint arXiv:2408.14358,
-
[4]
Deep Residual Learning for Image Recognition
URL https:// arxiv.org/abs/1512.03385. Huang, B., Wang, Z., Wang, G., Jiang, K., He, Z., Zou, H., and Zou, Q. Masked face recognition datasets and validation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, pp. 1487–1491, October
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
A community detec- tion approach to cleaning extremely large face database
Jin, C., Jin, R., Chen, K., and Dou, Y . A community detec- tion approach to cleaning extremely large face database. Computational intelligence and neuroscience, 2018(1): 4512473,
2018
-
[6]
Using representation expressiveness and learnability to evaluate self-supervised learning methods
Lu, Y ., Liu, Z., Baratin, A., Laroche, R., Courville, A., and Sordoni, A. Using representation expressiveness and learnability to evaluate self-supervised learning methods. arXiv preprint arXiv:2206.01251,
-
[7]
G., Athalye, A., and Mueller, J
Northcutt, C., Jiang, L., and Chuang, I. Confident learn- ing: Estimating uncertainty in dataset labels.Journal of Artificial Intelligence Research, 70:1373–1411, 2021a. Northcutt, C. G., Athalye, A., and Mueller, J. Pervasive la- bel errors in test sets destabilize machine learning bench- marks.arXiv preprint arXiv:2103.14749, 2021b. Papernot, N. and McD...
-
[8]
Swayamdipta, S., Schwartz, R., Lourie, N., Wang, Y ., Ha- jishirzi, H., Smith, N. A., and Choi, Y . Dataset cartog- raphy: Mapping and diagnosing datasets with training dynamics.arXiv preprint arXiv:2009.10795,
-
[9]
Unsupervised embedding quality evaluation
Tsitsulin, A., Munkhoeva, M., and Perozzi, B. Unsupervised embedding quality evaluation. InTopological, Algebraic and Geometric Learning Workshops 2023, pp. 169–188. PMLR,
2023
-
[10]
PaCo-FR: Patch-Pixel Aligned End-to-End Codebook Learning for Facial Representation Pre-training
Xie, Y ., Chen, Z., Xiao, Z., Zhao, Y ., An, X., Yang, K., Ran, Z., Guo, J., Feng, Z., and Deng, J. Paco-fr: Patch-pixel aligned end-to-end codebook learning for facial repre- sentation pre-training.arXiv preprint arXiv:2508.09691,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
arXiv preprint arXiv:2305.17326 , year=
Zhang, Y ., Tan, Z., Yang, J., Huang, W., and Yuan, Y . Matrix information theory for self-supervised learning.arXiv preprint arXiv:2305.17326,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.