MEMENTO: Leveraging Web as a Learning Signal for Low-Data Domains
Pith reviewed 2026-06-29 07:26 UTC · model grok-4.3
The pith
MEMENTO shows agents can acquire reusable research strategies and domain expertise directly from web interaction trajectories without any model training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
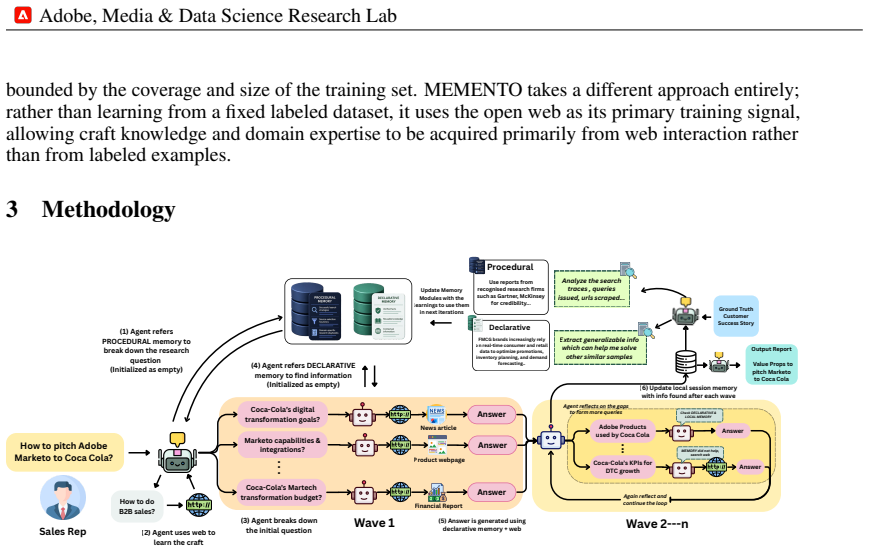
MEMENTO enables agents to learn reusable research strategies and domain expertise from trajectories of web interaction without additional model training. It does so by running iterative web exploration inside each session via an Adaptive Exploration Tree that decomposes tasks into evolving questions and reflects on intermediate findings, while accumulating experience across sessions through dual-channel memory that separates declarative knowledge from procedural knowledge. Evaluated on sales automation and legal research, the system produces consistent gains over ReAct baselines.
What carries the argument
Adaptive Exploration Tree (AET) paired with dual-channel memory, where the tree decomposes tasks and reflects on findings while the memory separates facts from search strategies.
If this is right
- Agents acquire both domain facts and reusable search strategies from web trajectories alone.
- No extra model training or labeled data is required to improve on low-data professional tasks.
- The web functions as a scalable, ongoing source of task-specific expertise.
- Performance lifts appear in both sales automation (+25.6%) and legal research (+36.5%).
Where Pith is reading between the lines
- The same structure might let agents build expertise in other web-rich domains such as medical literature search or financial analysis.
- Separating procedural memory from factual memory could reduce the need for repeated prompting across related tasks.
- Testing whether the learned strategies transfer to new models or to non-web environments would clarify the scope of the approach.
Load-bearing premise
The performance gains are produced by the adaptive exploration tree and dual-channel memory rather than by differences in prompting, implementation details, or baseline configuration.
What would settle it
An ablation that removes either the adaptive exploration tree or the dual-channel memory from MEMENTO and measures whether the reported gains over ReAct disappear on the same sales and legal tasks.
Figures
read the original abstract
Real-world tasks often lack large labeled datasets, motivating extensive work on learning in low-data regimes. However, existing approaches such as few-shot prompting, instruction tuning, and synthetic data generation, continue to treat labeled or pseudo-labeled data as the primary learning signal. In contrast, human practitioners acquire expertise through repeated, self-directed interaction with the open web, progressively refining both domain knowledge and search strategies. We propose MEMENTO, a framework that treats the web as a learning signal rather than a stateless retrieval interface. MEMENTO operates at two levels: within each session, it conducts iterative web exploration via an Adaptive Exploration Tree (AET) that decomposes tasks into evolving questions and reflects on intermediate findings; across sessions, it accumulates experience through dual-channel memory, separating declarative knowledge (facts) from procedural knowledge (search strategies). This design enables agents to learn reusable research strategies and domain expertise from trajectories of web interaction without additional model training. We evaluate MEMENTO on two low-data professional domains: sales automation and legal research. Our empirical results show consistent improvements in performance over ReAct based baselines (+25.6% on sales automation and 36.5% on legal research), demonstrating that the web can serve as a scalable learning source for acquiring task-specific expertise in data-scarce settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that MEMENTO enables agents to learn reusable research strategies and domain expertise from trajectories of web interaction without additional model training. It operates via an Adaptive Exploration Tree (AET) for iterative task decomposition and reflection within sessions, and dual-channel memory separating declarative facts from procedural search strategies across sessions. Empirical results on sales automation and legal research domains report consistent gains over ReAct baselines of +25.6% and +36.5%, respectively, positioning the open web as a scalable learning signal for low-data professional tasks.
Significance. If the reported gains can be isolated to the AET and dual-channel memory, the work would offer a meaningful contribution to training-free agent adaptation in data-scarce domains by demonstrating how web trajectories can substitute for labeled data in acquiring both knowledge and strategies.
major comments (1)
- [Abstract] Abstract: The central claim of +25.6% and +36.5% gains over ReAct is presented without any description of the experimental protocol, baseline equivalence (identical LLM, prompt templates, tool interfaces, iteration budgets, or reflection steps), statistical tests, number of trials, or ablation studies. This prevents verification that the improvements are attributable to the Adaptive Exploration Tree and dual-channel memory rather than configuration differences.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for clearer experimental context in the abstract. We address this point directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of +25.6% and +36.5% gains over ReAct is presented without any description of the experimental protocol, baseline equivalence (identical LLM, prompt templates, tool interfaces, iteration budgets, or reflection steps), statistical tests, number of trials, or ablation studies. This prevents verification that the improvements are attributable to the Adaptive Exploration Tree and dual-channel memory rather than configuration differences.
Authors: We agree the abstract as written is too terse to support standalone verification of the gains. The full manuscript details the experimental protocol in the Experimental Setup section, including use of the identical LLM backbone for MEMENTO and ReAct, matched prompt templates and tool interfaces, equivalent iteration budgets, and reflection mechanisms. Ablation studies isolating AET and dual-channel memory are reported in Section 5.3, with results averaged over multiple trials and statistical significance noted. To address the concern, we will revise the abstract to include a single sentence summarizing the matched baseline conditions and refer readers to the experimental section for full protocol details. revision: yes
Circularity Check
No significant circularity; empirical framework with external learning signal
full rationale
The paper describes an agent framework (MEMENTO) that uses web interactions as an external learning signal for low-data domains, with performance evaluated via comparisons to ReAct baselines. No equations, fitted parameters, or mathematical derivations appear in the provided text. The central claims rest on iterative exploration and memory mechanisms applied to open-web trajectories, without any self-definitional reductions, fitted-input predictions, or load-bearing self-citations. The design is self-contained against external benchmarks (web content and baseline runs), satisfying the default expectation of no circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Web interaction trajectories contain sufficient reusable signal to improve agent performance on professional tasks without model fine-tuning
invented entities (2)
-
Adaptive Exploration Tree (AET)
no independent evidence
-
dual-channel memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, et al. Gepa: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Mohammad Alali, Shaayan Syed, Mohammed Alsayed, Smit Patel, and Hemanth Bodala. Justice: A benchmark dataset for supreme court’s judgment prediction.arXiv preprint arXiv:2112.03414,
-
[3]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
1901
-
[4]
ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning
Mingyang Chen, Linzhuang Sun, Tianpeng Li, Haoze Sun, Yijie Zhou, Chenzheng Zhu, Haofen Wang, Jeff Z Pan, Wen Zhang, Huajun Chen, et al. Learning to reason with search for llms via reinforcement learning.arXiv preprint arXiv:2503.19470,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
A survey on in-context learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, et al. A survey on in-context learning. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 1107–1128,
2024
-
[6]
Accessed: 2026-04-23. Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, et al. Textbooks are all you need.arXiv preprint arXiv:2306.11644,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
A survey on recent approaches for natural language processing in low-resource scenarios
Michael A Hedderich, Lukas Lange, Heike Adel, Jannik Strötgen, and Dietrich Klakow. A survey on recent approaches for natural language processing in low-resource scenarios. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2545–2568,
2021
-
[8]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Se-search: Self-evolving search agent via memory and dense reward.arXiv preprint arXiv:2603.03293,
Jian Li, Yizhang Jin, Dongqi Liu, Hang Ding, Jiafu Wu, Dongsheng Chen, Yunhang Shen, Yulei Qin, Ying Tai, Chengjie Wang, et al. Se-search: Self-evolving search agent via memory and dense reward.arXiv preprint arXiv:2603.03293,
-
[10]
WebGPT: Browser-assisted question-answering with human feedback
10 Adobe, Media & Data Science Research Lab Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. Webgpt: Browser-assisted question-answering with human feedback.arXiv preprint arXiv:2112.09332,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Introducing deep research
OpenAI. Introducing deep research. https://openai.com/index/ introducing-deep-research/, 2025a. Accessed: 2026-04-23. OpenAI. Openai gpt-5 mini. https://platform.openai.com/docs/models/gpt-5, 2025b. Accessed: 2026-05-07. Krista Opsahl-Ong, Michael J Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab. Optimizing instructio...
2026
-
[12]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu
Accessed: 2026-04-23. Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67,
2026
-
[13]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. R1-searcher: Incentivizing the search capability in llms via reinforcement learning. arXiv preprint arXiv:2503.05592,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Finetuned Language Models Are Zero-Shot Learners
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners.arXiv preprint arXiv:2109.01652,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Webagent-r1: Training web agents via end-to-end multi-turn reinforcement learning
Zhepei Wei, Wenlin Yao, Yao Liu, Weizhi Zhang, Qin Lu, Liang Qiu, Changlong Yu, Puyang Xu, Chao Zhang, Bing Yin, et al. Webagent-r1: Training web agents via end-to-end multi-turn reinforcement learning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 7920–7939,
2025
-
[16]
Accessed: 2026-04-23. Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Jinhe Bi, Kristian Kersting, Jeff Z Pan, et al. Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning.arXiv preprint arXiv:2508.19828,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
11 Adobe, Media & Data Science Research Lab An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Training one 60-sample run with Qwen takes approximately6 hours; inference over the 120-sample test set takes approximately8 hoursper configuration. The GPT-5- mini variants exhibit comparable wall times despite offloading inference to Azure (training: ∼6 h, test: ∼7 h), as end-to-end latency is dominated by API round-trips under concurrent load rather th...
-
[20]
Declarative memory con- tributes only +0.0007 in isolation, within the range of run-to-run noise
13 Adobe, Media & Data Science Research Lab Procedural memory accounts for the majority of the gain.Of the +0.0265 total improvement, procedural memory alone delivers +0.0225 — roughly 85% of the lift. Declarative memory con- tributes only +0.0007 in isolation, within the range of run-to-run noise. The implication is clear: for this task,howthe agent sear...
2004
-
[21]
The two channels are weakly complementary.If the effects were strictly independent, the combined lift would be approximately 0.0225 + 0.0007 = 0.0232 . The full system achieves +0.0265, a small super-additive effect of ≈0.003 . This is consistent with the interpretation that declarative facts become usefulconditional ongood procedural strategy: once the a...
-
[22]
[2021]; our filtering pipeline for the legal task is described in detail
and the JUSTICE benchmark is publicly available Alali et al. [2021]; our filtering pipeline for the legal task is described in detail. All prompts and memory store formats are described at a level sufficient to reimplement the system. Guidelines: • The answer [N/A] means that the paper does not include experiments. • If the paper includes experiments, a [...
2021
-
[23]
and JUSTICE Alali et al. [2021]). The only novel artifacts produced by training are the procedural and declarative memory stores, which are stored as human-readable natural-language text and are therefore directly inspectable and auditable rather than opaque weight updates. Domain-specific risks of misuse, including manipulative sales targeting, legal mis...
2021
-
[24]
and JUSTICE Alali et al. [2021]. The Qwen-2.5-235B-Instruct model is open-weight and used under its Apache 2.0 license. GPT-5-mini is accessed through Azure OpenAI under its commercial API terms of service. Specific license versions for the datasets will be included in the final camera-ready appendix. Guidelines: • The answer [N/A] means that the paper do...
2021
-
[25]
[2021]), no new human annotations were collected, and all evaluation is performed by an automated LLM-as-judge
and JUSTICE Alali et al. [2021]), no new human annotations were collected, and all evaluation is performed by an automated LLM-as-judge. IRB approval (or equivalent) is therefore not applicable. Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects. • Depending on the country in which research ...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.