Towards Localized and Disentangled Knowledge Editing for Multimodal Large Language Models
Pith reviewed 2026-06-29 07:54 UTC · model grok-4.3
The pith
A framework localizes fact-specific layers in multimodal models and disentangles relevant inputs to make knowledge edits generalize without unintended changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
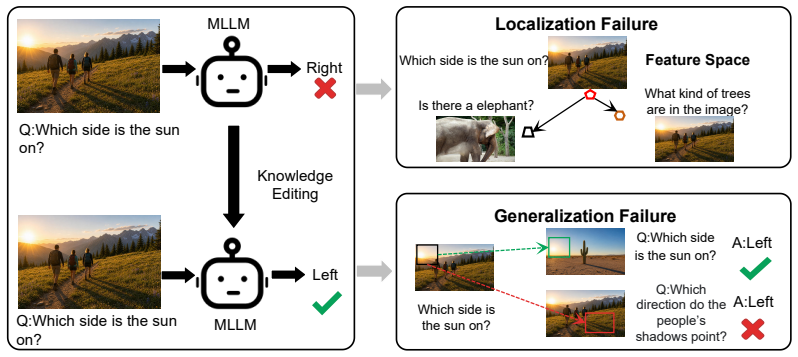
LDKE achieves precise and generalized editing by localizing fact-specific model layers and disentangling target-relevant inputs from irrelevant ones, with superior performance in propagating edits to related contexts while maintaining high locality.
What carries the argument
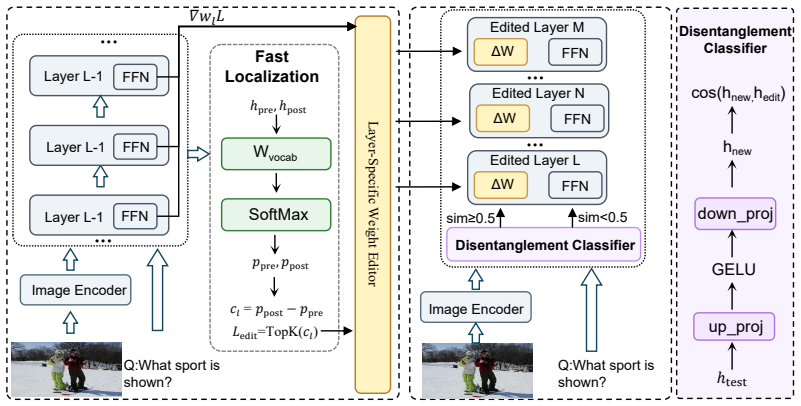
Fast Localization module that identifies critical layers for efficient updates, paired with a Disentanglement Classifier that routes inputs to preserve unrelated knowledge.
If this is right
- Edits propagate accurately to logically related queries while unrelated but visually or semantically linked information stays unchanged.
- The method applies across multiple benchmarks and different multimodal large language models without loss of locality.
- Updates become confined to fact-specific layers rather than affecting the entire model.
- Input routing prevents feature entanglement that previously caused unintended alterations.
Where Pith is reading between the lines
- The same localization-plus-disentanglement pattern might transfer to non-multimodal language models or vision-only systems facing similar editing issues.
- If the modules prove stable, they could reduce reliance on expensive full-model retraining for keeping deployed multimodal systems up to date.
- Combining the approach with parameter-efficient fine-tuning techniques could further lower the cost of repeated edits.
Load-bearing premise
The two failure modes of Causal Misalignment and Feature Entanglement are the main reasons existing methods fail at generalization and locality, and the new modules can fix them without creating fresh problems or trade-offs.
What would settle it
An experiment in which the Fast Localization module and Disentanglement Classifier produce no measurable gain in edit propagation or locality compared with baseline editing methods on the same benchmarks would falsify the central claim.
Figures
read the original abstract
Existing methods in Multimodal Knowledge Editing (MKE) have advanced the ability to correct outdated or inaccurate knowledge in Multimodal Large Language Models (MLLMs). However, they exhibit a critical limitation: while effectively modifying target factual pairs, they fail to generalize edits to logically related queries and often cause unintended alterations to unrelated but visually or semantically linked information. We identify and formalize two underlying failure modes causing this issue: Causal Misalignment, which confines edits to the specific sample, and Feature Entanglement, which causes unintended alterations to coupled but irrelevant information. To address these issues, we propose Localized and Disentangled Knowledge Editing (LDKE), a new framework that achieves precise and generalized editing by localizing fact-specific model layers and disentangling target-relevant inputs from irrelevant ones. Our approach introduces a Fast Localization module to identify and update critical layers efficiently, along with a Disentanglement Classifier that routes inputs appropriately to preserve unrelated knowledge. Extensive experiments across various benchmarks and MLLMs demonstrate that LDKE achieves superior performance in propagating edits to related contexts while maintaining high locality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies two failure modes in existing Multimodal Knowledge Editing (MKE) methods for MLLMs—Causal Misalignment (edits confined to specific samples) and Feature Entanglement (unintended changes to coupled irrelevant information)—and proposes Localized and Disentangled Knowledge Editing (LDKE). LDKE uses a Fast Localization module to identify and update critical layers and a Disentanglement Classifier to route target-relevant inputs, claiming this yields precise edits that generalize to related contexts while preserving high locality, as shown in experiments across benchmarks and MLLMs.
Significance. If the experimental claims hold with proper controls and baselines, LDKE could meaningfully advance knowledge editing for MLLMs by providing a more targeted mechanism that reduces side effects and improves generalization, which is valuable for applications requiring reliable factual updates in multimodal systems.
major comments (2)
- [Abstract] Abstract: The central claim of 'superior performance' and 'extensive experiments' demonstrating better edit propagation and locality is load-bearing, yet the text provides no quantitative results, baselines, error bars, or implementation details, preventing verification of whether the modules actually resolve the diagnosed failure modes without new trade-offs.
- [Introduction / Method] The assumption that Causal Misalignment and Feature Entanglement are the dominant causes (and that the proposed modules address them without side effects) is not isolated empirically; without ablation studies or controls showing these are primary over other factors, the motivation for the specific Fast Localization and Disentanglement Classifier design remains under-supported.
minor comments (2)
- [Method] Clarify the exact routing mechanism of the Disentanglement Classifier with pseudocode or an equation, as the high-level description leaves implementation ambiguous.
- [Experiments] Ensure all benchmarks and MLLMs used are explicitly listed with citation, and add a limitations section discussing potential computational overhead of the localization step.
Simulated Author's Rebuttal
We appreciate the referee's constructive feedback on our manuscript. We address each major comment below and outline the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'superior performance' and 'extensive experiments' demonstrating better edit propagation and locality is load-bearing, yet the text provides no quantitative results, baselines, error bars, or implementation details, preventing verification of whether the modules actually resolve the diagnosed failure modes without new trade-offs.
Authors: We agree that the abstract would benefit from including key quantitative results to support the claims. In the revised manuscript, we will update the abstract to highlight specific metrics from our experiments, such as improvements in edit generalization and locality compared to baselines. The full results with error bars, baselines, and implementation details are presented in the Experiments section. revision: yes
-
Referee: [Introduction / Method] The assumption that Causal Misalignment and Feature Entanglement are the dominant causes (and that the proposed modules address them without side effects) is not isolated empirically; without ablation studies or controls showing these are primary over other factors, the motivation for the specific Fast Localization and Disentanglement Classifier design remains under-supported.
Authors: The failure modes are identified through analysis of existing methods' behaviors on multimodal data, as detailed in the Introduction. To strengthen the empirical isolation of these factors, we will incorporate additional ablation studies in the revision that separately control for localization and disentanglement effects, showing their specific role in the observed issues and the design's effectiveness. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents a methodological framework (LDKE) consisting of a Fast Localization module and Disentanglement Classifier to address two diagnosed failure modes in existing MKE methods. No equations, closed-form derivations, parameter fits, or predictions are described that reduce to inputs by construction. Claims rest on experimental benchmarks rather than self-referential definitions or load-bearing self-citations. The derivation chain is self-contained as an engineering proposal without the circular patterns enumerated.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
Z. Yang, L. Li, J. Wang, K. Lin, E. Azarnasab, F. Ahmed, Z. Liu, C. Liu, M. Zeng, and L. Wang, “Mm-react: Prompting chatgpt for multimodal reasoning and action,”arXiv preprint arXiv:2303.11381, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Flamingo: a visual language model for few-shot learning,
J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y . Hasson, K. Lenc, A. Mensch, K. Millican, M. Reynoldset al., “Flamingo: a visual language model for few-shot learning,”Advances in neural information processing systems, vol. 35, pp. 23 716–23 736, 2022
2022
-
[3]
Llama: Open and efficient foundation language models,
H. T. Llama, “Llama: Open and efficient foundation language models,” 2023
2023
- [4]
-
[5]
Knowledge sanitization of large language models,
Y . Ishibashi and H. Shimodaira, “Knowledge sanitization of large language models,”arXiv preprint arXiv:2309.11852, 2023
-
[6]
Woodpecker: Hallucination correction for multimodal large language models,
S. Yin, C. Fu, S. Zhao, T. Xu, H. Wang, D. Sui, Y . Shen, K. Li, X. Sun, and E. Chen, “Woodpecker: Hallucination correction for multimodal large language models,”Science China Information Sciences, vol. 67, no. 12, p. 220105, 2024
2024
-
[7]
Knowledgeable or educated guess? revisiting language models as knowledge bases,
B. Cao, H. Lin, X. Han, L. Sun, L. Yan, M. Liao, T. Xue, and J. Xu, “Knowledgeable or educated guess? revisiting language models as knowledge bases,” inProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2021, pp. 1860–1874
2021
- [8]
-
[9]
Editing conceptual knowledge for large language models,
X. Wang, S. Mao, S. Deng, Y . Yao, Y . Shen, L. Liang, J. Gu, H. Chen, and N. Zhang, “Editing conceptual knowledge for large language models,” inFindings of the Association for Computa- tional Linguistics: EMNLP 2024, 2024, pp. 706–724
2024
-
[10]
Aging with grace: Lifelong model editing with discrete key-value adaptors,
T. Hartvigsen, S. Sankaranarayanan, H. Palangi, Y . Kim, and M. Ghassemi, “Aging with grace: Lifelong model editing with discrete key-value adaptors,”Advances in Neural Information Processing Systems, vol. 36, pp. 47 934–47 959, 2023
2023
-
[11]
Attribution analysis meets model edit- ing: Advancing knowledge correction in vision language models with visedit,
Q. Chen, T. Zhang, C. Wang, X. He, D. Wang, and T. Liu, “Attribution analysis meets model edit- ing: Advancing knowledge correction in vision language models with visedit,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 2, 2025, pp. 2168–2176
2025
-
[12]
Q. Li, Z. Ye, X. Feng, W. Zhong, W. Ma, and X. Feng, “Causal tracing of object representations in large vision language models: Mechanistic interpretability and hallucination mitigation,” arXiv preprint arXiv:2511.05923, 2025
-
[13]
Understanding information storage and transfer in multi-modal large language models,
S. Basu, M. Grayson, C. Morrison, B. Nushi, S. Feizi, and D. Massiceti, “Understanding information storage and transfer in multi-modal large language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 7400–7426, 2024
2024
-
[14]
Memory-based model editing at scale,
E. Mitchell, C. Lin, A. Bosselut, C. D. Manning, and C. Finn, “Memory-based model editing at scale,” inInternational Conference on Machine Learning. PMLR, 2022, pp. 15 817–15 831
2022
-
[15]
arXiv preprint arXiv:2301.09785 , year=
Z. Huang, Y . Shen, X. Zhang, J. Zhou, W. Rong, and Z. Xiong, “Transformer-patcher: One mistake worth one neuron,”arXiv preprint arXiv:2301.09785, 2023
-
[16]
Calibrating factual knowledge in pretrained language models,
Q. Dong, D. Dai, Y . Song, J. Xu, Z. Sui, and L. Li, “Calibrating factual knowledge in pretrained language models,” inFindings of the association for computational linguistics: EMNLP 2022, 2022, pp. 5937–5947
2022
-
[17]
Can we edit factual knowledge by in-context learning?
C. Zheng, L. Li, Q. Dong, Y . Fan, Z. Wu, J. Xu, and B. Chang, “Can we edit factual knowledge by in-context learning?” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 4862–4876. 10
2023
-
[18]
arXiv preprint arXiv:2110.11309 , year=
E. Mitchell, C. Lin, A. Bosselut, C. Finn, and C. D. Manning, “Fast model editing at scale,” arXiv preprint arXiv:2110.11309, 2021
-
[19]
Locating and editing factual associations in gpt,
K. Meng, D. Bau, A. Andonian, and Y . Belinkov, “Locating and editing factual associations in gpt,”Advances in neural information processing systems, vol. 35, pp. 17 359–17 372, 2022
2022
-
[20]
Mass-Editing Memory in a Transformer
K. Meng, A. S. Sharma, A. Andonian, Y . Belinkov, and D. Bau, “Mass-editing memory in a transformer,”arXiv preprint arXiv:2210.07229, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Visual-oriented fine-grained knowl- edge editing for multimodal large language models,
Z. Zeng, L. Gu, X. Yang, Z. Duan, Z. Shi, and M. Wang, “Visual-oriented fine-grained knowl- edge editing for multimodal large language models,” inProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, 2025, pp. 2491–2500
2025
-
[22]
Lifelong knowledge editing for vision language models with low-rank mixture-of-experts,
Q. Chen, C. Wang, D. Wang, T. Zhang, W. Li, and X. He, “Lifelong knowledge editing for vision language models with low-rank mixture-of-experts,” inProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), June 2025, pp. 9455–9466
2025
-
[23]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,” inInternational conference on machine learning. PMLR, 2023, pp. 19 730–19 742
2023
-
[24]
G. Team, A. Kamath, J. Ferret, S. Pathak, N. Vieillard, R. Merhej, S. Perrin, T. Matejovicova, A. Ramé, M. Rivière, L. Rouillard, T. Mesnard, G. Cideron, J. bastien Grillet al., “Gemma 3 technical report,”arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
W. Wang, Z. Gao, L. Gu, H. Pu, L. Cui, X. Wei, Z. Liu, L. Jing, S. Ye, J. Shaoet al., “Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency,”arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
arXiv preprint arXiv:2012.00363 , year=
C. Zhu, A. S. Rawat, M. Zaheer, S. Bhojanapalli, D. Li, F. Yu, and S. Kumar, “Modifying memories in transformer models,”arXiv preprint arXiv:2012.00363, 2020
-
[27]
Vlkeb: A large vision- language model knowledge editing benchmark,
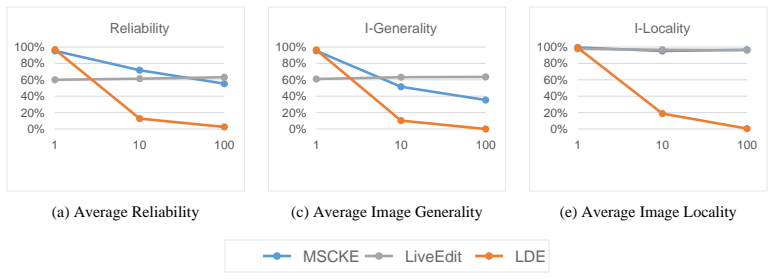
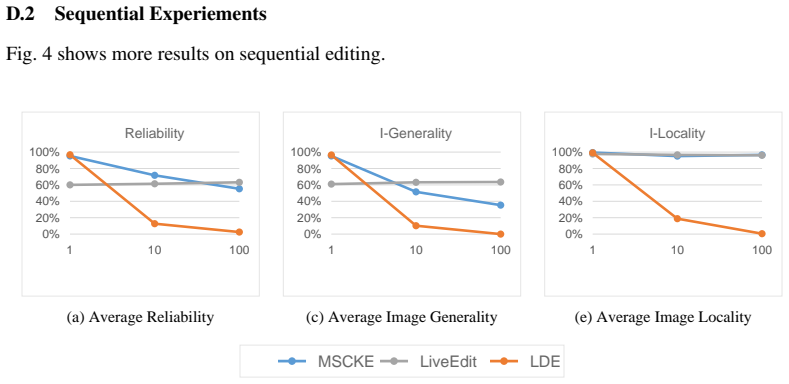
H. Huang, H. Zhong, T. Yu, Q. Liu, S. Wu, L. Wang, and T. Tan, “Vlkeb: A large vision- language model knowledge editing benchmark,”Advances in Neural Information Processing Systems, vol. 37, pp. 9257–9280, 2024. 11 A Limitations A primary limitation of LDKE lies in its suboptimal performance during sequential editing. This vulnerability stems from our ado...
2024
-
[28]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.