OptSkills: Learning Generalizable Optimization Skills from Problem Archetypes via Cluster-Based Distillation
Pith reviewed 2026-06-29 07:04 UTC · model grok-4.3
The pith
OptSkills clusters optimization problems by archetypes and distills modeling trajectories into reusable skills to improve generalization across problem types.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
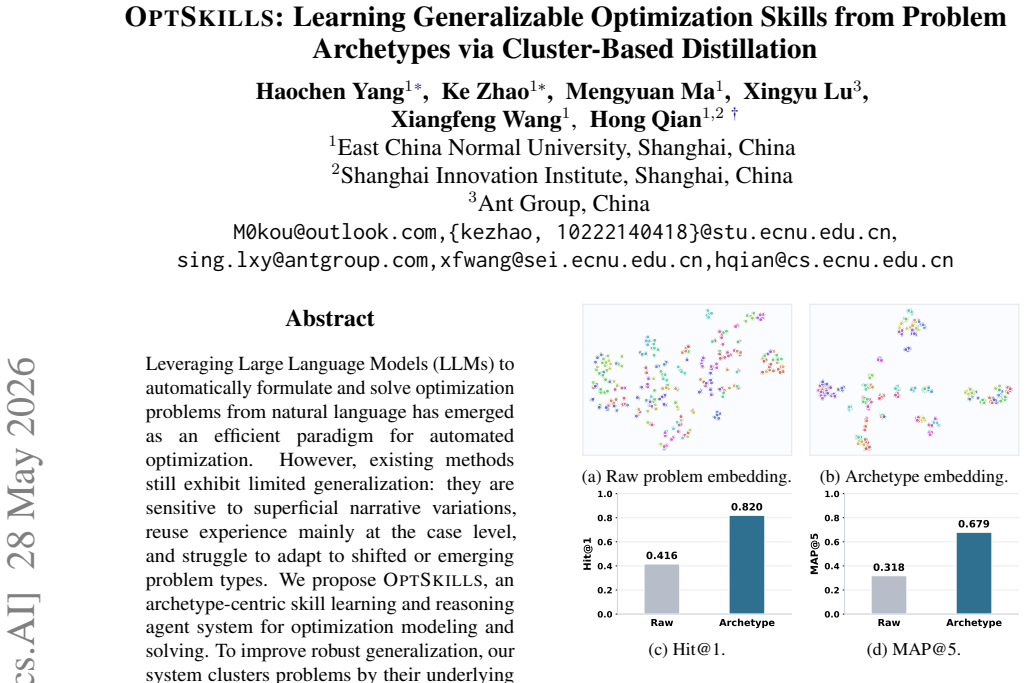
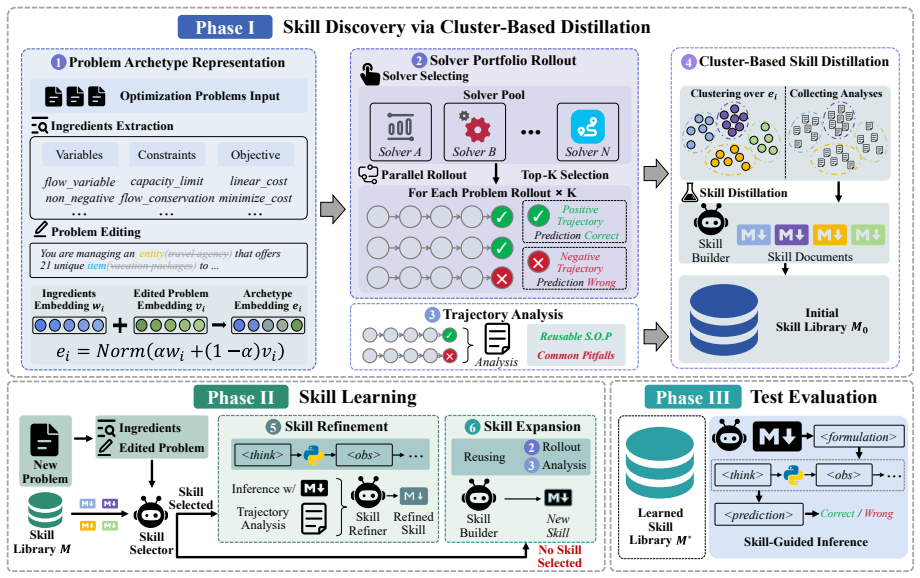
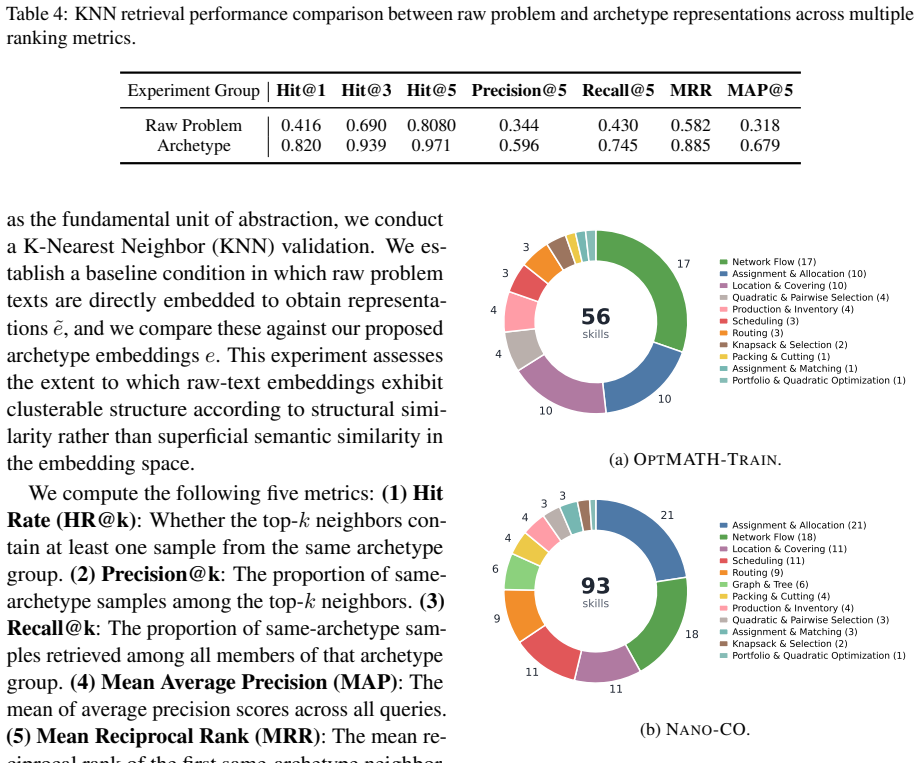
OptSkills is an archetype-centric skill learning and reasoning agent system. It clusters problems by underlying archetypes rather than surface narratives, explores diverse modeling paradigms and solver configurations within each cluster, distills successful trajectories into reusable workflow-level skills, and refines or expands the skill library for out-of-distribution cases. This produces state-of-the-art micro-averaged accuracy of 68.27 percent on datasets with diverse problem types, 26.91 percent on MIPLIB-NL (outperforming DeepSeek-V3.2-Thinking by 4.53 percent), and 72.79 percent on the OOD NLCO benchmark after skill learning on Nano-CO.
What carries the argument
Archetype-centric clustering of problems followed by cluster-based distillation of successful modeling and solver trajectories into reusable workflow-level skills.
If this is right
- Skills distilled from one cluster can be applied or refined when new problem instances appear inside or outside the original distribution.
- Exploration of multiple modeling paradigms and solver configurations inside each archetype cluster improves in-distribution accuracy.
- The skill library can be expanded incrementally without retraining the entire system when new trajectories are obtained.
- Performance on large-scale high-dimensional benchmarks such as MIPLIB-NL increases because archetype-level patterns reduce sensitivity to narrative variation.
Where Pith is reading between the lines
- The same clustering-plus-distillation pattern could be tested on other structured reasoning domains where surface descriptions vary but core structures recur.
- If archetype definitions are made explicit, the approach might allow systematic comparison of skill libraries across independent research groups.
- The reported gains on MIPLIB-NL suggest the method may be especially useful for problems whose mathematical structure is stable but whose natural-language presentations differ widely.
Load-bearing premise
Clustering problems by underlying archetypes rather than surface narratives produces groups whose modeling and solver trajectories can be distilled into skills that generalize to shifted or emerging problem types.
What would settle it
A controlled experiment in which archetype-based clustering is replaced by surface-narrative clustering or no clustering and the accuracy on the OOD NLCO benchmark after Nano-CO skill learning falls below 72.79 percent or matches the non-archetype baseline.
Figures





read the original abstract
Leveraging Large Language Models (LLMs) to automatically formulate and solve optimization problems from natural language has emerged as an efficient paradigm for automated optimization. However, existing methods still exhibit limited generalization: they are sensitive to superficial narrative variations, reuse experience mainly at the case level, and struggle to adapt to shifted or emerging problem types. We propose OptSkills, an archetype-centric skill learning and reasoning agent system for optimization modeling and solving. To improve robust generalization, our system clusters problems by their underlying archetypes rather than surface narratives. To improve in-distribution generalization, it explores diverse modeling paradigms and solver configurations within each cluster, then distills successful trajectories into reusable workflow-level skills. To improve out-of-distribution generalization, it refines existing skills or expands the skill library using newly obtained trajectories. Our system achieves a state-of-the-art micro-averaged accuracy of 68.27% on datasets encompassing diverse problem types and scenarios. In addition, on MIPLIB-NL, a highly challenging large-scale and high-dimensional benchmark, it achieves 26.91% accuracy, outperforming DeepSeek-V3.2-Thinking by 4.53%. After skill learning on Nano-CO, it reaches 72.79% on the OOD NLCO benchmark. Code and skills are available at https://github.com/fujiwaranoM0kou/OptSkills.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OptSkills, an archetype-centric LLM-based agent system for optimization modeling and solving. Problems are clustered by underlying archetypes (rather than surface narratives); within each cluster the system explores modeling paradigms and solver configurations, distills successful trajectories into reusable workflow-level skills, and refines or expands the skill library for OOD cases. It reports a micro-averaged accuracy of 68.27% on diverse datasets, 26.91% on MIPLIB-NL (outperforming DeepSeek-V3.2-Thinking by 4.53%), and 72.79% on the OOD NLCO benchmark after skill learning on Nano-CO. Code and skills are released publicly.
Significance. If the reported accuracies and the archetype-clustering-plus-distillation pipeline are shown to be robust, the work could advance LLM-driven optimization by shifting from case-level reuse to reusable, archetype-derived skills that improve both in-distribution and out-of-distribution generalization. The public release of code and skills is a clear strength that supports reproducibility and community follow-up.
major comments (2)
- [Abstract] Abstract: the manuscript supplies only an abstract containing accuracy figures and benchmark names but no experimental protocol, baseline details, dataset statistics, number of runs, error bars, or ablation results. Without these it is impossible to determine whether the reported numbers support the generalization claims.
- [Abstract] Abstract: the central design claim—that clustering by archetypes (rather than surface narratives) yields clusters whose internal modeling and solver trajectories can be distilled into generalizable skills—is stated as motivation but is unsupported by any description of archetype definition, clustering algorithm, or distillation mechanics, leaving the core technical contribution unevaluable.
minor comments (1)
- [Abstract] Abstract: the GitHub link for code and skills is a positive reproducibility signal but the abstract would benefit from a brief statement of the number of archetypes or size of the skill library to give readers context for the reported gains.
Simulated Author's Rebuttal
We thank the referee for the comments. The concerns focus on the abstract's brevity, which is a valid observation given space limits. The full manuscript provides the requested details in the body, but we agree the abstract should be expanded for standalone evaluability. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the manuscript supplies only an abstract containing accuracy figures and benchmark names but no experimental protocol, baseline details, dataset statistics, number of runs, error bars, or ablation results. Without these it is impossible to determine whether the reported numbers support the generalization claims.
Authors: We agree the abstract is too concise on these points. The full paper (Section 4) specifies the evaluation protocol (including prompt templates and solver interfaces), baselines (DeepSeek-V3.2-Thinking and others), dataset statistics (problem counts and types across MIPLIB-NL, NLCO, etc.), multiple runs, and ablation results on clustering and distillation. We will revise the abstract to add one sentence summarizing the protocol, number of runs, and key ablation findings. revision: yes
-
Referee: [Abstract] Abstract: the central design claim—that clustering by archetypes (rather than surface narratives) yields clusters whose internal modeling and solver trajectories can be distilled into generalizable skills—is stated as motivation but is unsupported by any description of archetype definition, clustering algorithm, or distillation mechanics, leaving the core technical contribution unevaluable.
Authors: We agree the abstract states the claim at a high level without mechanics. The manuscript body (Sections 3.1–3.3) defines archetypes via structural features (linearity, constraint types, objective form), uses embedding-based clustering (with the specific algorithm and hyperparameters), and details distillation (trajectory filtering, workflow extraction via LLM summarization, and skill library update rules). We will revise the abstract to briefly name these components (e.g., 'archetype clustering via embeddings followed by workflow skill distillation'). revision: yes
Circularity Check
No significant circularity; empirical claims on external benchmarks
full rationale
The paper describes an archetype-clustering and skill-distillation pipeline for optimization modeling, then reports concrete accuracy figures (68.27% micro-averaged, 26.91% on MIPLIB-NL, 72.79% on OOD NLCO) against named external benchmarks. No equations, fitted parameters, or derivation steps are supplied that would make any reported performance equivalent to its own inputs by construction. The central claims rest on measured outcomes rather than self-referential definitions or load-bearing self-citations. This is the normal case of an empirical systems paper whose results are falsifiable against independent test sets.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
EvoSkill: Automated Skill Discovery for Multi-Agent Systems
OptiMUS: Scalable optimization modeling with (MI)LP solvers and large language models. In Advances in Forty-first International Conference on Machine Learning, Vienna, Austria. Salaheddin Alzubi, Noah Provenzano, Jaydon Bingham, Weiyuan Chen, and Tu Vu. 2026. EvoSkill: Auto- mated skill discovery for multi-agent systems. arXiv preprint arXiv:2603.02766. Y...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
In Forty-third International Conference on Machine Learning
Constructing industrial-scale optimization modeling benchmark. In Forty-third International Conference on Machine Learning. Kuo Liang, Yuhang Lu, Jianming Mao, Shuyi Sun, Chunwei Yang, Congcong Zeng, Xiao Jin, Hanzhang Qin, Ruihao Zhu, and Chung-Piaw Teo. 2026. Large- scale optimization model auto-formulation: Harness- ing llm flexibility via structured w...
-
[3]
Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills
Trace2Skill: Distill trajectory-local lessons into transferable agent skills. arXiv preprint arXiv:2603.25158. OpenAI. 2026. Introducing gpt-5.4. Weichun Shi, Minghao Liu, Wanting Zhang, Langchen Shi, Fuqi Jia, Feifei Ma, and Jian Zhang
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
ConstraintLLM: A neuro-symbolic frame- work for industrial-level constraint programming. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 15999–16019, Suzhou, China. Association for Com- putational Linguistics. Yifan Shi, Jialong Shi, Jiayi Wang, Ye Fan, and Jiany- ong Sun. 2026. MIRROR: A multi-agent framew...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
MemSkill: Learning and evolving mem- ory skills for self-evolving agents. arXiv preprint arXiv:2602.02474. Huichi Zhou, Siyuan Guo, Anjie Liu, Zhongwei Yu, Ziqin Gong, Bowen Zhao, Zhixun Chen, Meng- long Zhang, Yihang Chen, Jinsong Li, Runyu Yang, Qiangbin Liu, Xinlei Yu, Jianmin Zhou, Na Wang, Chunyang Sun, and Jun Wang. 2026. Memento- Skills: Let agents...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Preserve directed pair set P = [(i,j) for i in N for j in N if i != j] maximize sum(benefit[(i,j)] * y[(i,j)] for (i,j) in P)
-
[7]
Verify against the same objective Selected nodes: [1, 2, 3]Total benefit: 127(1,2)=24, (2,1)=22(1,3)=17, (3,1)=21 (2,3)=18, (3,2)=25 Final answer: 127
-
[8]
63.5counts each unordered pair twice
Correct solution, then self-doubt Selected nodes: [1, 2, 3] Objective value: 127 The agent treats this as double-counting: Total benefit ... 63.5counts each unordered pair twice
-
[9]
The skill stabilizes the semantic choice P={(i,j):i!=j}
Optimizes a different problem benefit = {(0,1):16, ..., (3,4):17}# only define for i < jSelected nodes: [0, 2, 4] Objective value: 65 Final answer: 65 INSIGHT Skill effect. The skill stabilizes the semantic choice P={(i,j):i!=j}. The correct set [1,2,3] yields 24+22+17+21+18+25=127. Failure mode. The no-skill run finds 127 but changes the task to unordere...
-
[11]
RESULT: {{ objective_value}}
**Solving Stage**: Generate the solver- based Python code and wrapped in < solver_code> tags. - you may use the python-based modeling language as follows: ortools , pyomo. - you may use the solver as follows: gurobi, clp, glpk, ipopt, highs, cbc, scip, mindtpy. You need to select an appropriate solver based on the type of the problem (linear or nonlinear,...
-
[13]
keywords
minimally edit the problem text into a scenario-neutral version. Task A: Keyword extraction - Extract high-signal structural keywords and place them into: -`variable` -`constraint` -`objective` - The goal is not only mathematical correctness, but also discriminative power: the extracted keywords should help distinguish different canonical optimization cla...
-
[14]
extract scenario-agnostic optimization keywords into three slots
-
[15]
keywords
minimally edit the problem text into a scenario-neutral version. Task A: Keyword extraction - Extract high-signal structural keywords and place them into: -`variable` -`constraint` -`objective` - The goal is not only mathematical correctness, but also discriminative power: the extracted keywords should help distinguish different canonical optimization cla...
-
[16]
**Modeling Stage**: First output a valid formulation in JSON format wrapped in <formulation> tags
-
[17]
Ensure tool arguments are valid JSON
**Solving Stage**: Call the`run_code` tool to execute solver code. Ensure tool arguments are valid JSON
-
[18]
### Core Rules - At most one tool call per turn
**Final Stage**: Output the final numeric answer wrapped in <answer> tags. ### Core Rules - At most one tool call per turn. - Solver code must print`RESULT:<number >`. - Never assume tool success without checking feedback. - Select exactly one workflow from the skill (parallel alternatives, not sequential steps). - Before any tool call, output: < formulat...
-
[19]
Infer problem family from objective/ constraint keywords
-
[20]
Prefer robust and standard backends when uncertain
-
[21]
Keep diversity across frameworks/ backends when possible
-
[22]
selected
Do not invent solver IDs; choose only from catalog. Input: <problem_description> {problem_description} </problem_description> <keywords> {keywords} </keywords> <top_k> {top_k} </top_k> <solver_catalog_json> {solver_catalog} </solver_catalog_json> Return JSON only: {{ "selected": [ {{ "solver_id": "string", "reason": "short reason" }} ] }} H.5 Skill Prompt...
-
[23]
Distill lessons, do not narrate trajectory
-
[24]
Keep workflow alternatives parallel ( not sequential)
-
[25]
Use solver-aware modeling templates
-
[26]
Make result parsing and failure handling explicit
-
[27]
Prefer concise technical clarity over decorative prose
-
[28]
Suitable code usage can be placed in every step with explicit comments
-
[29]
sets": [],
Keep it general,Use placeholders instead of specific values. The skill should apply to similar problems, not just this one, not just this scenario. The Skill Name, Skill Description, Workflow Names, Step Names should all be generalized and not scenario-specific. Hard format contract: - Keep this section order exactly: frontmatter -> # Workflow 1 (...) -> ...
-
[30]
Preserve the outer document skeleton exactly: - keep the full YAML frontmatter, - keep both opening and closing`---`, - keep all existing YAML keys, - keep key order unchanged, - keep the top-level section structure and heading order unchanged unless explicitly impossible to maintain validity
-
[31]
Prefer local edits over full rewrites
Within existing sections, you may rewrite, compress, deduplicate, clarify, and generalize content. Prefer local edits over full rewrites
-
[32]
Remove only weak, vague, repetitive, or redundant wording
Preserve all useful existing workflows. Remove only weak, vague, repetitive, or redundant wording
-
[33]
You may clarify or tighten them if supported by the trajectory
Do not remove explicit execution checks, solver/status verification steps, or parseable output contracts. You may clarify or tighten them if supported by the trajectory
-
[34]
Exclude scenario-specific story details from the analysis, such as names, one-time events, or incidental numeric values, unless they represent a reusable operational threshold or rule
-
[35]
Convert hardcoded task-specific values into placeholders such as`[ TARGET]`,`[QUERY]`,`[TIME_LIMIT]`, `[CAPACITY]`, or similar appropriate abstractions
Replace overly specific examples with reusable patterns when possible. Convert hardcoded task-specific values into placeholders such as`[ TARGET]`,`[QUERY]`,`[TIME_LIMIT]`, `[CAPACITY]`, or similar appropriate abstractions
-
[36]
Preserve skill-discriminative information. Do not remove or blur details that define this SKILL's distinctive optimization structure, including when relevant: - problem class, - decision variable pattern, - objective type, - key constraint structure, - solver or modeling assumptions
-
[37]
Consolidate overlapping explanations into clearer single statements
Merge duplicate or near-duplicate content only when meaning is preserved. Consolidate overlapping explanations into clearer single statements
-
[38]
For`positive`labels: - strengthen successful SOPs supported by the analysis, - clarify reusable step order, - make successful checks, thresholds, or decision criteria more explicit, - do not add unsupported new methods or techniques
-
[39]
For`negative`labels: - prioritize prerequisite checks, early failure detection, recovery steps, and fallback guidance, - do not ban a method entirely unless the analysis clearly shows a general failure mode rather than a one-off execution issue, - do not overwrite or weaken proven successful workflows unless the analysis reveals a general flaw in them
-
[40]
Do not introduce new solver strategies, modeling tricks, tools, or procedures unless they are clearly supported by either the existing SKILL or the trajectory
-
[41]
Remove verbosity that does not improve execution quality
Keep the content concise, actionable, and reusable. Remove verbosity that does not improve execution quality
-
[42]
Maintain consistent formatting and scannability within the existing structure: - clear steps, - consistent bullet style, - concise wording, - no unnecessary prose expansion
-
[43]
Perform a consistency audit across prose, formulation templates, and code examples: - ensure sign conventions, index ordering, objective sense, constraint direction, and variable semantics are mutually consistent, - if a contradiction exists, prefer the smallest edit that restores internal consistency, - do not preserve contradictory formulations merely t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.