CB-SLICE: Concept-Based Interpretable Error Slice Discovery
Pith reviewed 2026-06-29 08:22 UTC · model grok-4.3
The pith
CB-SLICE discovers error slices by grouping concept mispredictions in bottleneck models, outperforming prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
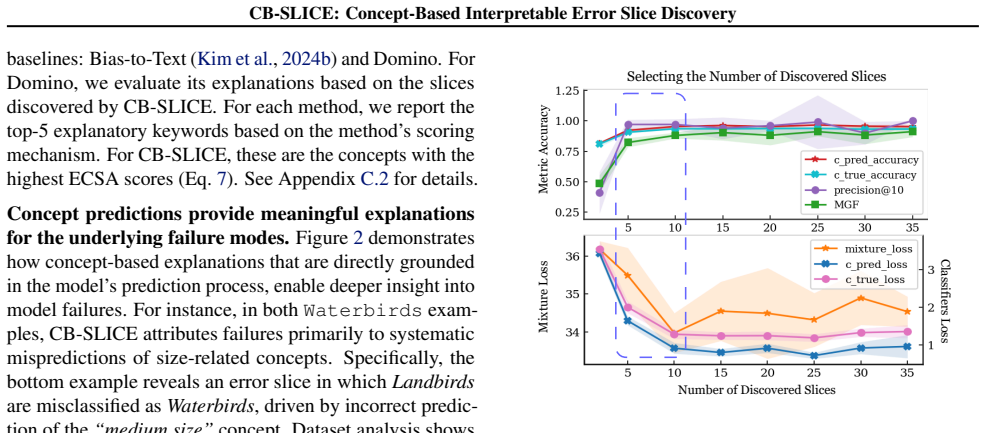
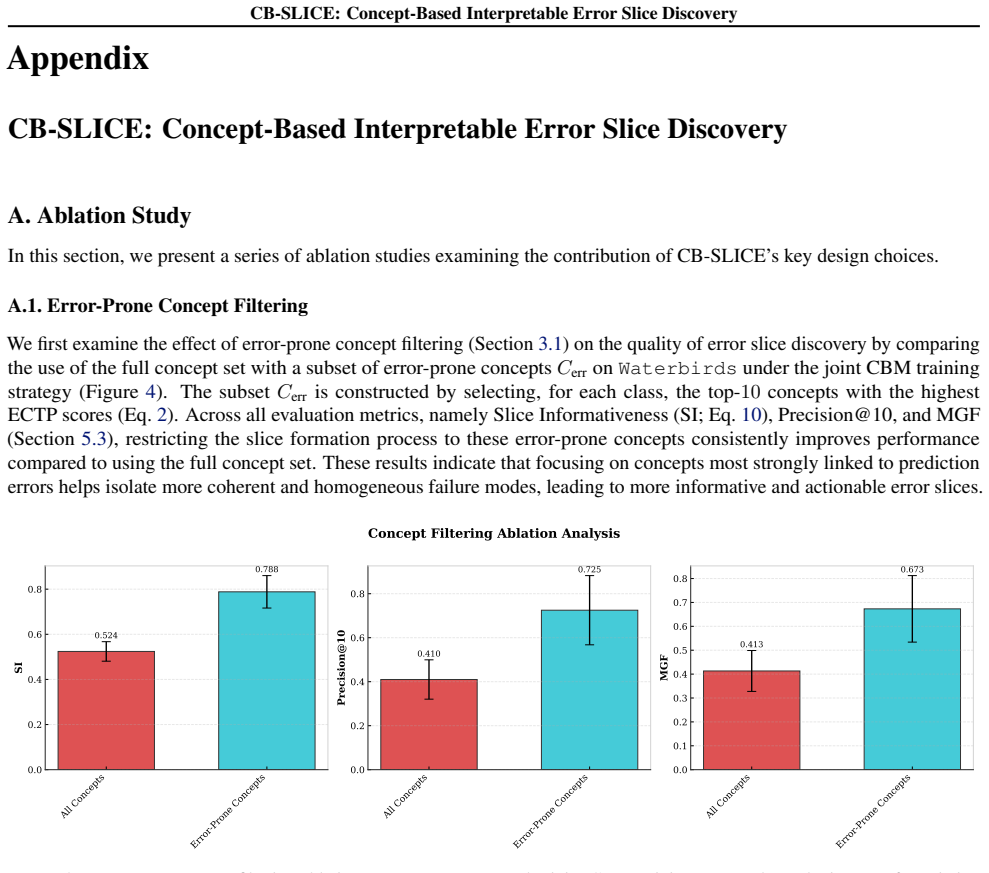
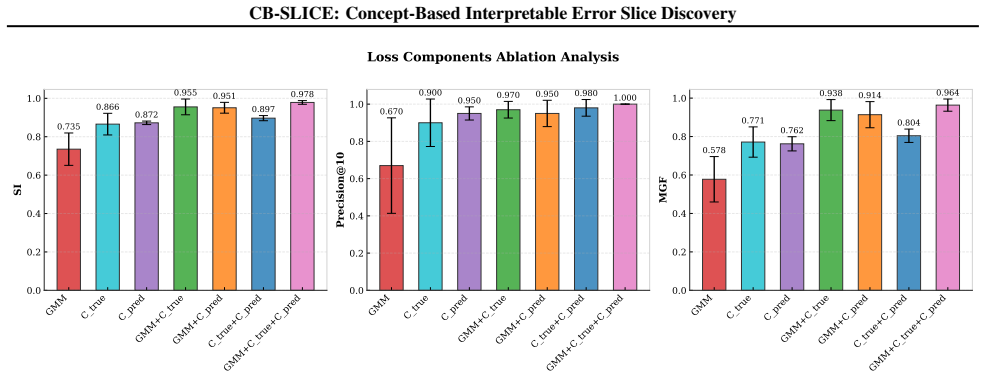
CB-SLICE groups samples with shared concept prediction failures and identifies the keyword concepts most responsible for each slice's failure mode, yielding richer and more faithful explanations of model errors than state-of-the-art slice discovery methods.
What carries the argument
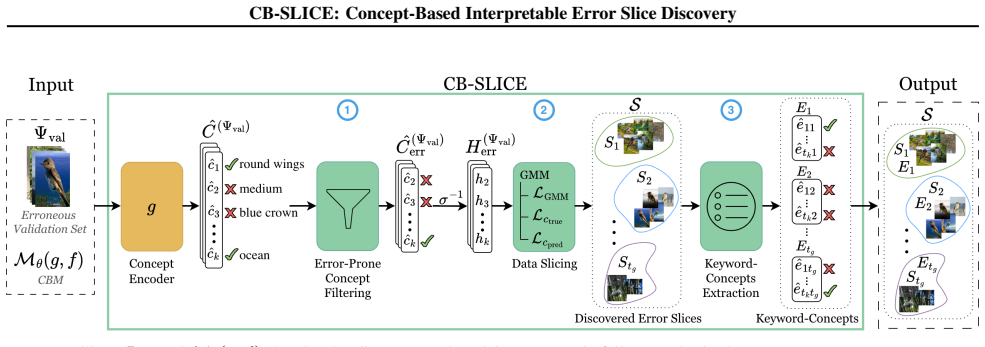
Grouping samples by shared concept mispredictions in Concept Bottleneck Models to link error slices directly to the source of inference failures.
Load-bearing premise
Downstream task failures in CBMs commonly arise from concept mispredictions.
What would settle it
Finding a dataset where CB-SLICE does not identify known biases that other SDMs successfully detect, or where its concept-based explanations do not align with observed model behavior.
Figures


read the original abstract
Despite strong average-case performance, deep learning models often exhibit systematic errors on specific population groups, known as error slices. Identifying these groups and the root causes of their failures is critical for model debugging and bias mitigation. However, existing error Slice Discovery Methods (SDMs) typically generate explanations disconnected from the model's inference process, thus only approximating the underlying error source and may be inaccurate. We address this limitation by leveraging Concept Bottleneck Models (CBMs), whose predictions are directly dependent on human-understandable semantic concepts. Since downstream task failures in CBMs commonly arise from concept mispredictions, concept representations provide a strong candidate for error slice identification, offering fine-grained explanations directly linked to the error source. Building on this insight, we introduce CB-SLICE, a concept-based SDM that groups samples with shared concept prediction failures and identifies the keyword concepts most responsible for each slice's failure mode. Across multiple benchmarks, we show that CB-SLICE outperforms state-of-the-art methods in uncovering well-known biases while providing richer and more faithful explanations of model errors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CB-SLICE, a concept-based error slice discovery method for Concept Bottleneck Models (CBMs). It groups samples by shared concept prediction failures and identifies responsible keyword concepts, claiming this yields slices directly linked to error sources. Across multiple benchmarks, CB-SLICE is asserted to outperform state-of-the-art SDMs in uncovering known biases while providing richer and more faithful explanations than methods whose outputs are disconnected from the model's inference process.
Significance. If the empirical claims hold after verification of the core premise and experimental details, the work would supply a direct mechanistic link between error slices and CBM concept errors, improving the faithfulness of debugging tools for interpretable models that already expose concept activations.
major comments (2)
- [Abstract] Abstract: the central premise that 'downstream task failures in CBMs commonly arise from concept mispredictions' is stated without qualification, citation, or supporting analysis. This assumption is load-bearing; if a non-negligible fraction of task errors occur on correctly predicted concepts (i.e., in the concept-to-task mapping), then slices identified by concept failures would not be 'directly linked to the error source' and the reported gains in bias uncovering and faithfulness would not follow.
- [Abstract] Abstract: the claim of outperformance 'across multiple benchmarks' is made without any mention of datasets, baselines (e.g., existing SDMs), metrics, statistical significance, or experimental protocol. Because the abstract supplies no verification steps, it is impossible to assess whether the data support the superiority assertions.
minor comments (1)
- [Abstract] The acronym 'CB-SLICE' is introduced in the title but never expanded in the provided abstract text.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will incorporate revisions to strengthen the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central premise that 'downstream task failures in CBMs commonly arise from concept mispredictions' is stated without qualification, citation, or supporting analysis. This assumption is load-bearing; if a non-negligible fraction of task errors occur on correctly predicted concepts (i.e., in the concept-to-task mapping), then slices identified by concept failures would not be 'directly linked to the error source' and the reported gains in bias uncovering and faithfulness would not follow.
Authors: We agree the premise is presented without explicit qualification or citation in the abstract and is central to the claims. While the full manuscript motivates this based on the CBM architecture (task prediction is a direct function of concept activations), we will revise the abstract to qualify the statement (e.g., 'frequently arise') and add a supporting reference to prior CBM literature showing strong correlation between concept and task accuracy. This addresses the load-bearing concern without altering the core method. revision: yes
-
Referee: [Abstract] Abstract: the claim of outperformance 'across multiple benchmarks' is made without any mention of datasets, baselines (e.g., existing SDMs), metrics, statistical significance, or experimental protocol. Because the abstract supplies no verification steps, it is impossible to assess whether the data support the superiority assertions.
Authors: We acknowledge that the abstract is concise and omits concrete details on datasets, baselines, metrics, and protocol, which limits immediate verifiability. To improve transparency while respecting length constraints, we will revise the abstract to briefly specify the benchmarks (e.g., CelebA, Waterbirds), key SDM baselines, and primary metrics (bias uncovering rate, explanation faithfulness). Full experimental protocol, statistical tests, and results remain in Sections 4 and 5. revision: yes
Circularity Check
No circularity; method rests on external CBM premise without self-referential reduction
full rationale
The paper's core insight—that CBM task failures commonly arise from concept mispredictions—is stated as a premise drawn from the structure of CBMs rather than derived from the paper's own equations, fits, or self-citations. CB-SLICE is then defined as grouping by shared concept prediction failures, with empirical claims of outperformance evaluated on external benchmarks. No step reduces a prediction to a fitted input by construction, invokes a self-citation uniqueness theorem, or renames a known result; the derivation chain remains independent of the target outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Downstream task failures in CBMs commonly arise from concept mispredictions
Reference graph
Works this paper leans on
-
[1]
Post- hoc explanations fail to achieve their purpose in adversar- ial contexts
Bordt, S., Finck, M., Raidl, E., and V on Luxburg, U. Post- hoc explanations fail to achieve their purpose in adversar- ial contexts. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, pp. 891– 905,
2022
-
[2]
R., and Leyton-Brown, K
d’Eon, G., d’Eon, J., Wright, J. R., and Leyton-Brown, K. The spotlight: A general method for discovering systematic errors in deep learning models. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, pp. 1962–1981,
2022
-
[3]
Enouen, E. et al. Debugging concept bottleneck models through removal and retraining. InNeurIPS 2025 Work- shop on Regulatable ML,
2025
-
[4]
Constructing concept-based models to mitigate spurious correlations with minimal human effort
Kim, J., Wang, Z., and Qiu, Q. Constructing concept-based models to mitigate spurious correlations with minimal human effort. InEuropean Conference on Computer Vision, pp. 137–153. Springer, 2024a. Kim, M. P., Ghorbani, A., and Zou, J. Multiaccuracy: Black- box post-processing for fairness in classification. InPro- ceedings of the 2019 AAAI/ACM Conference...
2019
-
[5]
Promises and pitfalls of black-box concept learning models.arXiv preprint arXiv:2106.13314,
Mahinpei, A., Clark, J., Lage, I., Doshi-Velez, F., and Pan, W. Promises and pitfalls of black-box concept learning models.arXiv preprint arXiv:2106.13314,
- [6]
-
[7]
and Hirschberg, J
Rosenberg, A. and Hirschberg, J. V-measure: A conditional entropy-based external cluster evaluation measure. In Proceedings of the 2007 joint conference on empirical methods in natural language processing and computa- tional natural language learning (EMNLP-CoNLL), pp. 410–420,
2007
-
[8]
Sagawa, S., Koh, P. W., Hashimoto, T. B., and Liang, P. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case gener- alization.arXiv preprint arXiv:1911.08731,
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[9]
doi: 10.3390/electronics14142785
ISSN 2079-9292. doi: 10.3390/electronics14142785. URL https://www. mdpi.com/2079-9292/14/14/2785. Publisher: Multidisciplinary Digital Publishing Institute. Wah, C., Branson, S., Welinder, P., Perona, P., and Belongie, S. The caltech-ucsd birds-200-2011 dataset.Technical Report CNS-TR-2011-001, California Institute of Tech- nology,
-
[10]
Error slice discovery via manifold compactness.arXiv preprint arXiv:2501.19032,
Yu, H., Liu, J., Zou, H., Xu, R., He, Y ., Zhang, X., and Cui, P. Error slice discovery via manifold compactness.arXiv preprint arXiv:2501.19032,
-
[11]
Post-hoc con- cept bottleneck models
Yuksekgonul, M., Wang, M., and Zou, J. Post-hoc con- cept bottleneck models. InICLR 2022 Workshop on PAIR2Struct: Privacy, Accountability, Interpretability, Robustness, Reasoning on Structured Data,
2022
-
[12]
is a binary bird classification dataset (Landbirdsvs.Waterbirds) composed of RGB images created by overlaying bird crops from the Caltech-UCSD Birds-200-2011 (CUB) dataset (Wah et al.,
2011
-
[13]
bamboo forest
onto background images from the Places dataset (Zhou et al., 2017). Backgrounds are drawn from four scene categories:bamboo forest,forest,lake, andocean. This construction yields four subgroups:Landbirds-on-land,Landbirds-on-water,Waterbirds- on-land, andWaterbirds-on-water. In the training set,Landbirds-on-landandWaterbirds-on-waterare overrepresented re...
2017
-
[14]
For concept annotations, we adopt the Label-free pipeline of Oikarinen et al
For image preprocessing, we follow the same procedure as for CelebA. For concept annotations, we adopt the Label-free pipeline of Oikarinen et al. (2023), using the concept bank from Enouen et al. (2025) and a zero-shot CLIP classifier (Radford et al.,
2023
-
[15]
Table 3.Waterbirds dataset splits. DATASPLITLANDBIRDWATERBIRDTOTAL LANDWATERLANDWATER # TRAININGSAMPLES3,498 184 56 1,057 4,795 # VALIDATIONSAMPLES2,722 155 44 775 3,696 # TOTAL6,559 1,932 8,491 Table 4.CelebA dataset splits. DATASPLITFEMALEMALETOTAL BLONDENON-BLONDEBLONDENON-BLONDE # TRAININGSAMPLES22,880 71,629 1,387 66,874 162,770 # VALIDATIONSAMPLES2,...
2000
-
[16]
We train the GMM module for 200 epochs using SGD with an initial learning rate of 0.1, decayed by a factor of2every30epochs, and a batch size of8. C.2. Baselines Quantitative Baselines.We compare CB-SLICE against four state-of-the-art SDMs: Domino (Eyuboglu et al., 2022), GEORGE (Sohoni et al., 2020), HiBug2 (Chen et al., 2025), and Spotlight (d’Eon et al...
2022
-
[17]
Qualitative Baselines.For the qualitative assessment of slice explanations, we compare CB-SLICE with Bias-to-Text (Kim et al., 2024b) and Domino
For HiBug2, the number of slices is determined automatically by its enumeration algorithm. Qualitative Baselines.For the qualitative assessment of slice explanations, we compare CB-SLICE with Bias-to-Text (Kim et al., 2024b) and Domino. Bias-to-Textfirst produces image-level descriptions via ClipCap (Mokady et al., 2021), then applies the YAKE keyword ext...
2021
-
[18]
backbone as the concept encoder g, for all tasks except MNIST-Sum. For MNIST-Sum, we adopt a lightweight backbone consisting of two convolutional layers with 32 and 64 channels, respectively, each followed by a ReLU activation, and a fully connected (FC) layer with ReLU. For the label predictor f, we use a single FC layer across all tasks. In practice, f ...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.