MIRAGE: Adaptive Multimodal Gating for Whole-Brain fMRI Encoding
Pith reviewed 2026-06-29 09:12 UTC · model grok-4.3
The pith
Natively multimodal features with adaptive layer-wise gating outperform post-hoc fusion of separate unimodal features for predicting whole-brain fMRI responses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
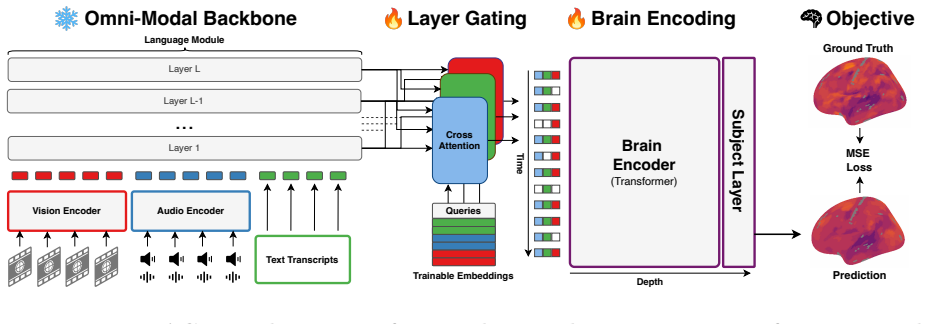
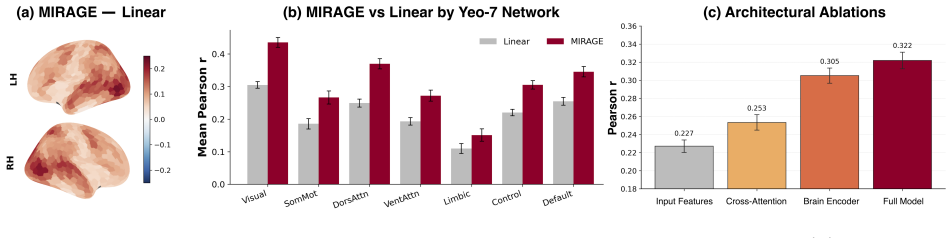
MIRAGE shows that representations taken from an omni-modal foundation model, when combined via adaptive gating across layers and passed through a transformer encoder with subject-specific linear readouts, yield higher whole-brain fMRI prediction accuracy than either unimodal models or post-hoc aggregation of their outputs, while the gating weights themselves reveal distinct modality contributions that align with known cortical topography.
What carries the argument
Adaptive multimodal gating that learns to weight and select layer-wise features from a single omni-modal backbone before they enter the brain encoder.
If this is right
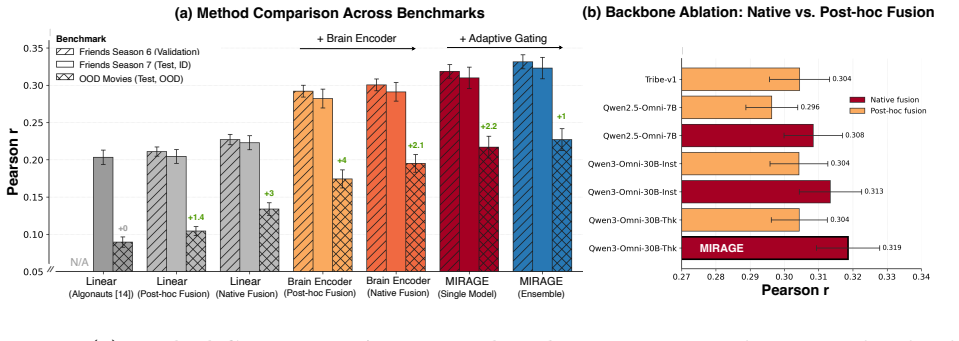
- Natively multimodal backbones produce better encoding performance than unimodal or post-hoc multimodal baselines across multiple architectures and datasets.
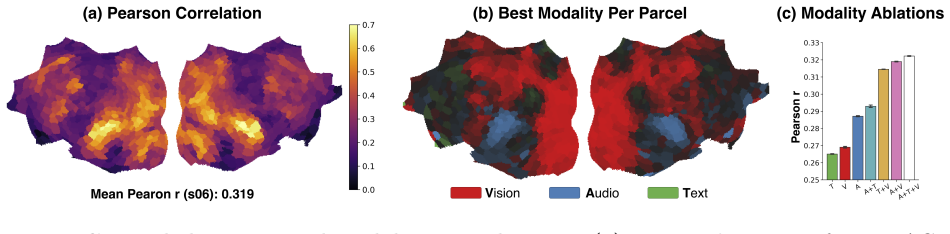
- The learned attention weights directly indicate the relative contribution of each modality at every layer of the backbone.
- Each modality's gated features map onto distinct spatial patterns across cortical parcels.
- The overall pipeline remains interpretable because the gating profile can be inspected without additional analysis tools.
Where Pith is reading between the lines
- The same gating idea could be tested on non-audiovisual naturalistic stimuli to check whether the advantage persists when one modality is missing.
- If the gating weights turn out to be stable across subjects, they might serve as a compact signature of how an individual integrates senses.
- Applying the identical native-multimodal-plus-gating recipe to other imaging modalities such as MEG could test whether the benefit is specific to fMRI hemodynamics.
Load-bearing premise
The layer-wise features produced by current omni-modal foundation models already contain the right information for the brain's responses, so that a simple learned gate can extract it without needing to be retrained or regularized specifically for each new fMRI dataset.
What would settle it
A controlled re-run on the same audiovisual fMRI datasets in which post-hoc concatenation or averaging of features from three separate unimodal models reaches the same or higher prediction accuracy as the native multimodal gated version.
Figures

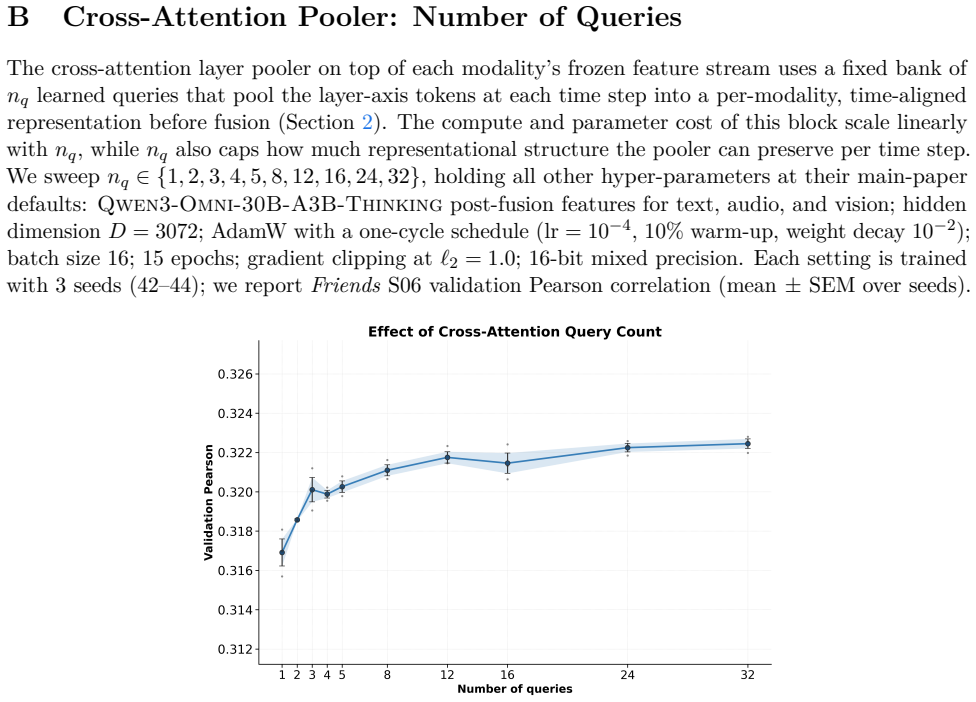
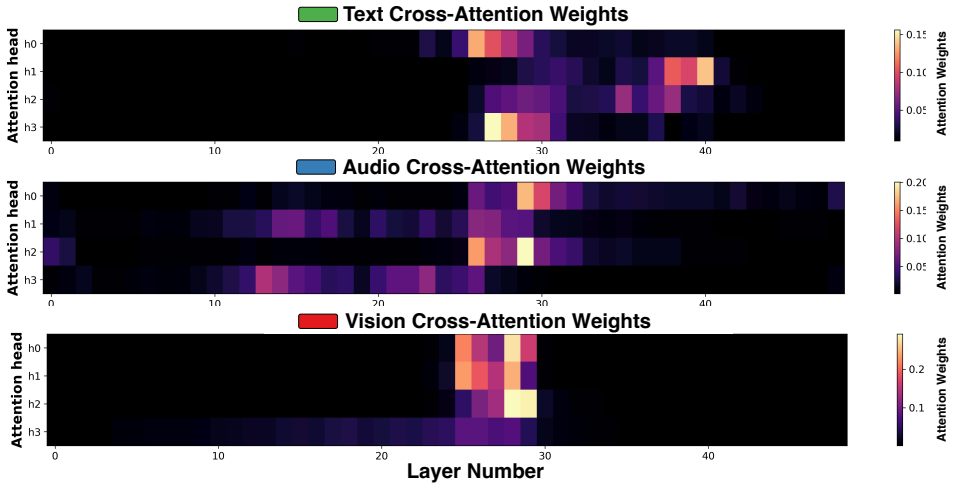
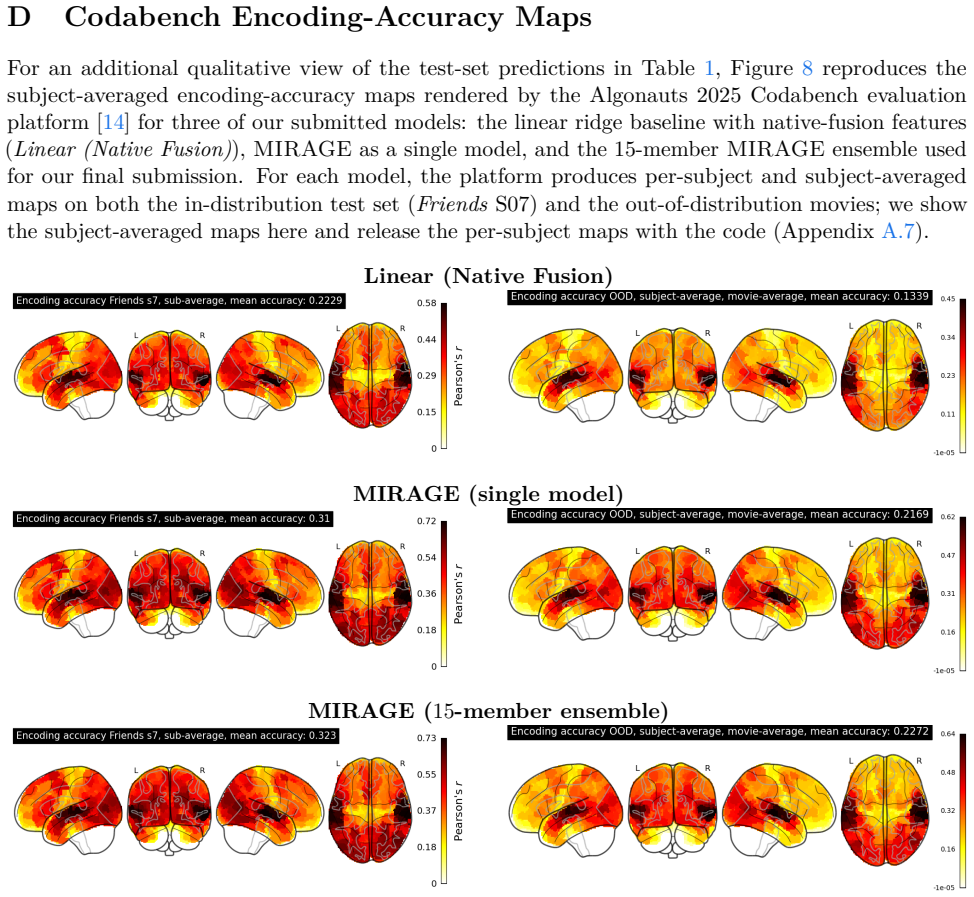
read the original abstract
Recent progress in task-optimized neural networks has established encoding models as a powerful tool for predicting brain responses to naturalistic stimuli, yet most existing approaches rely on unimodal representations. The emergence of omni-modal foundation models and rich multimodal neural datasets enables encoding models that jointly integrate visual, auditory, and linguistic information across subjects. We introduce MIRAGE, a brain encoding framework for predicting whole-brain fMRI responses to naturalistic audiovisual stimuli. MIRAGE achieves state-of-the-art performance via a native multimodal backbone and adaptive feature gating across layers. These representations are then combined with a transformer-based brain encoder and a subject-specific linear head over the cortical parcels. Controlled comparisons show that natively multimodal features consistently outperform post-hoc aggregation of independent unimodal features, across architectural levels and backbones. Beyond predictive accuracy, the learned attention weights are directly inspectable to interpret the modality-specific gating profile over the backbone, and each modality traces a distinct anatomical pattern across cortex. Together, these results propose adaptive layer-wise aggregation of natively multimodal features as a generalizable, interpretable, and accurate approach for whole-brain encoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MIRAGE, a brain encoding framework for predicting whole-brain fMRI responses to naturalistic audiovisual stimuli. It uses omni-modal foundation models with adaptive layer-wise feature gating, combined with a transformer-based brain encoder and subject-specific linear heads over cortical parcels. The central claims are state-of-the-art performance via native multimodal backbones and that natively multimodal features consistently outperform post-hoc aggregation of independent unimodal features across architectural levels and backbones; the learned gating weights are presented as interpretable for modality-specific profiles with distinct anatomical patterns across cortex.
Significance. If the central claims hold after addressing validation gaps, the work would advance multimodal fMRI encoding by demonstrating benefits of integrated representations from omni-modal models over unimodal aggregation, while adding interpretability through inspectable attention weights. The approach addresses a gap in handling audiovisual naturalistic stimuli jointly across subjects. No machine-checked proofs or parameter-free derivations are present, but the emphasis on controlled comparisons and anatomical tracing is a potential strength if the controls are robust.
major comments (2)
- [Abstract and Results] Abstract and Results section: The controlled comparisons claiming consistent outperformance of natively multimodal features over post-hoc unimodal aggregation do not describe ablations with frozen or non-adaptive gating. Without such controls, the performance lift cannot be isolated from potential overfitting of the end-to-end optimized gating parameters to subject- or stimulus-specific modality preferences on the fMRI training splits.
- [Methods] Methods section: No details are provided on held-out dataset testing (beyond standard splits), explicit regularization of the gating parameters, or cross-dataset generalization, which are necessary to secure the assumption that the adaptive gating reflects intrinsic multimodal feature quality rather than dataset-specific tuning.
minor comments (2)
- [Abstract] Abstract: The assertion of 'state-of-the-art performance' is made without any quantitative metrics, error bars, dataset sizes, or validation procedures, which reduces clarity even if the full text supplies them.
- [Abstract] Abstract: The final sentence uses 'propose ... as a generalizable, interpretable, and accurate approach'; rephrasing to reflect the empirical claims more directly would improve precision.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below. Where the concerns identify gaps in the current controls and documentation, we agree that revisions are warranted and will incorporate the suggested ablations and clarifications.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results section: The controlled comparisons claiming consistent outperformance of natively multimodal features over post-hoc unimodal aggregation do not describe ablations with frozen or non-adaptive gating. Without such controls, the performance lift cannot be isolated from potential overfitting of the end-to-end optimized gating parameters to subject- or stimulus-specific modality preferences on the fMRI training splits.
Authors: The referee correctly identifies that our reported comparisons do not include explicit frozen-gating or non-adaptive baselines. While the existing results already show consistent gains across multiple independent backbones and architectural depths (which would be unlikely under pure overfitting to a single training split), we agree that frozen-gating ablations are needed to isolate the contribution of the adaptive mechanism. We will add these controls in the revised Results section, training identical models with gating weights fixed to uniform or unimodal-only values. revision: yes
-
Referee: [Methods] Methods section: No details are provided on held-out dataset testing (beyond standard splits), explicit regularization of the gating parameters, or cross-dataset generalization, which are necessary to secure the assumption that the adaptive gating reflects intrinsic multimodal feature quality rather than dataset-specific tuning.
Authors: We will expand the Methods section to document (i) the precise regularization applied to the gating parameters (L2 penalty and early stopping on a validation split), (ii) the exact held-out subject and stimulus partitions used beyond the standard train/val/test division, and (iii) a limitations paragraph acknowledging the absence of cross-dataset evaluation. Because the current experiments remain within a single large naturalistic dataset, we cannot claim cross-dataset generalization; we will therefore qualify the interpretability claims accordingly rather than overstate them. revision: partial
Circularity Check
No circularity: empirical comparisons presented without reduction to fitted inputs or self-citations
full rationale
The provided abstract and manuscript description contain no equations, no explicit derivation chain, and no self-citations that serve as load-bearing premises for the central claim. The reported superiority of natively multimodal features with adaptive gating is framed as an outcome of controlled empirical comparisons rather than a quantity defined by construction from the gating parameters or prior author work. No step matches any enumerated circularity pattern; the framework is therefore treated as self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yamins, Ha Hong, Charles F
Daniel L. Yamins, Ha Hong, Charles F. Cadieu, Ethan A. Solomon, Darren Seibert, and James J. DiCarlo. Performance-optimized hierarchical models predict neural responses in higher visual cortex.Proceedings of the National Academy of Sciences, 111(23):8619–8624, 2014. doi: 10.1073/ pnas.1403112111
2014
-
[2]
Daniel L K Yamins and James J DiCarlo. Using goal-driven deep learning models to understand sensory cortex.Nature Neuroscience, 19(3):356–365, February 2016. ISSN 1546-1726. doi: 10.1038/nn.4244. URLhttp://dx.doi.org/10.1038/nn.4244
-
[3]
Majaj, Rishi Rajalingham, Elias B
Martin Schrimpf, Jonas Kubilius, Ha Hong, Najib J. Majaj, Rishi Rajalingham, Elias B. Issa, Kohitij Kar, Pouya Bashivan, Jonathan Prescott-Roy, Franziska Geiger, Kailyn Schmidt, Daniel L. K. Yamins, and James J. DiCarlo. Brain-score: Which artificial neural network for object recognition is most brain-like?bioRxiv preprint, 2018. URL https://www.biorxiv.o...
-
[4]
Hosseini, Nancy Kanwisher, Joshua B
Martin Schrimpf, Idan Asher Blank, Greta Tuckute, Carina Kauf, Eghbal A. Hosseini, Nancy Kanwisher, Joshua B. Tenenbaum, and Evelina Fedorenko. The neural architecture of language: Integrative modeling converges on predictive processing.Proceedings of the National Academy of Sciences (PNAS), 118(45), November 2021. ISSN 0027-8424. doi: 10.1073/pnas.210564...
-
[5]
Blake A. Richards, Timothy P. Lillicrap, Philippe Beaudoin, Yoshua Bengio, Rafal Bogacz, Amelia Christensen, Claudia Clopath, Rui Ponte Costa, Archy de Berker, Surya Ganguli, Colleen J. Gillon, Danijar Hafner, Adam Kepecs, Nikolaus Kriegeskorte, Peter Latham, Grace W. Lindsay, Kenneth D. Miller, Richard Naud, Christopher C. Pack, Panayiota Poirazi, Pieter...
-
[6]
Colin Conwell, Jacob S. Prince, Kendrick N. Kay, George A. Alvarez, and Talia Konkle. A large-scale examination of inductive biases shaping high-level visual representation in brains and machines.Nature Communications, 15(1), October 2024. ISSN 2041-1723. doi: 10.1038/s41467-0 24-53147-y. URLhttp://dx.doi.org/10.1038/s41467-024-53147-y
-
[7]
Scaling laws for task-optimized models of the primate visual ventral stream
Abdulkadir Gokce and Martin Schrimpf. Scaling laws for task-optimized models of the primate visual ventral stream. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=WxY61MmHYo
2025
-
[8]
Many-two-one: Diverse representations across visual pathways emerge from a single objective
Yingtian Tang, Abdulkadir Gokce, Khaled Jedoui Al-Karkari, Daniel Yamins, and Martin Schrimpf. Many-two-one: Diverse representations across visual pathways emerge from a single objective. bioRxiv, 2025. doi: 10.1101/2025.07.22.664908. URLhttps://www.biorxiv.org/content/earl y/2025/07/26/2025.07.22.664908
-
[9]
TRIBE: TRImodal brain encoder for whole-brain fMRI response prediction
Stéphane d’Ascoli, Jérémy Rapin, Yohann Benchetrit, Hubert Banville, and Jean-Remi King. TRIBE: TRImodal brain encoder for whole-brain fMRI response prediction. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/f orum?id=biegtqdqmg
2026
-
[10]
From language to cognition: How LLMs outgrow the human language network
Badr AlKhamissi, Greta Tuckute, Yingtian Tang, Taha Osama A Binhuraib, Antoine Bosselut, and Martin Schrimpf. From language to cognition: How LLMs outgrow the human language network. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Process...
2025
-
[11]
GhislainSt-Yves, EmilyJ.Allen, YihanWu, KendrickKay, andThomasNaselaris. Brain-optimized deep neural network models of human visual areas learn non-hierarchical representations.Nature Communications, 14(1), June 2023. ISSN 2041-1723. doi: 10.1038/s41467-023-38674-4. URL http://dx.doi.org/10.1038/s41467-023-38674-4
-
[12]
Transformer brain encoders explain human high-level visual responses
Hossein Adeli, Minni Sun, and Nikolaus Kriegeskorte. Transformer brain encoders explain human high-level visual responses. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=Tt3XLyuDrE
2025
-
[13]
Boyle, Basile Pinsard, Amal Boukhdhir, Sylvie Belleville, Simona Brambatti, Jeni Chen, Julien Cohen-Adad, and Andre Cyr
Julie A. Boyle, Basile Pinsard, Amal Boukhdhir, Sylvie Belleville, Simona Brambatti, Jeni Chen, Julien Cohen-Adad, and Andre Cyr. The courtois project on neuronal modelling – 2020 data release. https://www.cneuromod.ca , June 2020. Poster 1939 presented at the 2020 Annual Meeting of the Organization for Human Brain Mapping (OHBM), held virtually
2020
-
[14]
Alessandro T. Gifford, Domenic Bersch, Marie St-Laurent, Basile Pinsard, Julie Boyle, Lune Bellec, Aude Oliva, Gemma Roig, and Radoslaw M. Cichy. The algonauts project 2025 challenge: How the human brain makes sense of multimodal movies, 2025. URLhttps://arxiv.org/abs/ 2501.00504
-
[15]
Vibe: Video-input brain encoder for fmri response modeling, 2025
Daniel Carlström Schad, Shrey Dixit, Janis Keck, Viktor Studenyak, Aleksandr Shpilevoi, and Andrej Bicanski. Vibe: Video-input brain encoder for fmri response modeling, 2025. URL https://arxiv.org/abs/2507.17958
-
[16]
Multimodal recurrent ensembles for predicting brain responses to naturalistic movies (algonauts 2025), 2025
Semih Eren, Deniz Kucukahmetler, and Nico Scherf. Multimodal recurrent ensembles for predicting brain responses to naturalistic movies (algonauts 2025), 2025. URLhttps://arxiv.org/abs/25 07.17897
2025
-
[17]
AaronGrattafiori, AbhimanyuDubey, AbhinavJauhri, AbhinavPandey, AbhishekKadian, Ahmad Al-Dahle, et al. The llama 3 herd of models, 2024. URLhttps://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Yu-An Chung, Yu Zhang, Wei Han, Chung-Cheng Chiu, James Qin, Ruoming Pang, and Yonghui Wu. w2v-bert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training. In2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), page 244–250. IEEE, December 2021. doi: 10.1109/asru51503.2021.9688253. URL htt...
-
[19]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mahmoud Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Mojtaba Komeili, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, Sergio Arnaud, Abha Gejji, Ada Martin, Francois Robert Hogan, Daniel Dugas, Piotr Bojanowski, Vasil Khalidov, Patrick Labatut, Francisco Massa, Marc Szafraniec, Kapil Krishnakumar, Yong Li, X...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-omni technical report, 2025. URLhttps://arxiv.org/abs/2503.20215
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, Yuanjun Lv, Yongqi Wang, Dake Guo, He Wang, Linhan Ma, Pei Zhang, Xinyu Zhang, Hongkun Hao, Zishan Guo, Baosong Yang, Bin Zhang, Ziyang Ma, Xipin Wei, Shuai Bai, Keqin Chen, Xuejing Liu, Peng Wang, Mingkun Yang, Dayiheng Liu, Xingzhang Ren, Bo ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URLhttp...
2017
-
[23]
A foundation model of vision, audition, and language for in-silico neuroscience, 2026
Stéphane d’Ascoli, Jérémy Rapin, Yohann Benchetrit, Teon Brookes, Katelyn Begany, Joséphine Raugel, Hubert Banville, and Jean-Rémi King. A foundation model of vision, audition, and language for in-silico neuroscience, 2026. URLhttps://ai.meta.com/research/publications/ a-foundation-model-of-vision-audition-and-language-for-in-silico-neuroscience/
2026
- [24]
-
[25]
Alexander G. Huth, Wendy A. de Heer, Thomas L. Griffiths, Frédéric E. Theunissen, and Jack L. Gallant. Natural speech reveals the semantic maps that tile human cerebral cortex. Nature, 532(7600):453–458, April 2016. ISSN 1476-4687. doi: 10.1038/nature17637. URL http://dx.doi.org/10.1038/nature17637
-
[26]
Evelina Fedorenko, Anna A. Ivanova, and Tamar I. Regev. The language network as a natural kind within the broader landscape of the human brain.Nature Reviews Neuroscience, 25(5): 289–312, April 2024. ISSN 1471-0048. doi: 10.1038/s41583-024-00802-4. URLhttp://dx.doi.o rg/10.1038/s41583-024-00802-4
-
[27]
B. T. Thomas Yeo, Fenna M. Krienen, Jorge Sepulcre, Mert R. Sabuncu, Danial Lashkari, Marisa Hollinshead, Joshua L. Roffman, Jordan W. Smoller, Lilla Zöllei, Jonathan R. Polimeni, Bruce Fischl, Hesheng Liu, and Randy L. Buckner. The organization of the human cerebral cortex estimated by intrinsic functional connectivity.Journal of Neurophysiology, 106(3):...
-
[28]
ISSN 1522-1598. doi: 10.1152/jn.00338.2011. URLhttp://dx.doi.org/10.1152/jn.00 338.2011
-
[29]
Layer by layer: Uncovering hidden representations in language models
Oscar Skean, Md Rifat Arefin, Dan Zhao, Niket Nikul Patel, Jalal Naghiyev, Yann LeCun, and Ravid Shwartz-Ziv. Layer by layer: Uncovering hidden representations in language models. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.n et/forum?id=WGXb7UdvTX
2025
-
[30]
Deep Supervised, but Not Unsupervised, Models May Explain IT Cortical Representation.PLoS Computational Biology, 10(11), November
Seyed Mahdi Khaligh-Razavi and Nikolaus Kriegeskorte. Deep Supervised, but Not Unsupervised, Models May Explain IT Cortical Representation.PLoS Computational Biology, 10(11), November
-
[31]
doi: 10.1371/journal.pcbi.1003915
ISSN 15537358. doi: 10.1371/journal.pcbi.1003915. URLhttp://dx.plos.org/10.1371/ journal.pcbi.1003915. ISBN: 1553-7358 (Electronic)\r1553-734X (Linking)
-
[32]
Integrative benchmarking to advance neurally mechanistic models of human intelligence.Neuron, 2020
Martin Schrimpf, Jonas Kubilius, Michael J Lee, N Apurva Ratan Murty, Robert Ajemian, and James J DiCarlo. Integrative benchmarking to advance neurally mechanistic models of human intelligence.Neuron, 2020. URL https://www.cell.com/neuron/fulltext/S0896-6273(20)3 0605-X
2020
-
[33]
Radoslaw Martin Cichy, Gemma Roig, Alex Andonian, Kshitij Dwivedi, Benjamin Lahner, Alex Lascelles, Yalda Mohsenzadeh, Kandan Ramakrishnan, and Aude Oliva. The algonauts project: A platform for communication between the sciences of biological and artificial intelligence, 2019. URLhttps://arxiv.org/abs/1905.05675
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [34]
- [35]
-
[36]
Chengxu Zhuang, Siming Yan, Aran Nayebi, Martin Schrimpf, Michael C. Frank, James J. DiCarlo, and Daniel L. Yamins. Unsupervised neural network models of the ventral visual stream. Proceedings of the National Academy of Sciences, 118(3), 2021. doi: 10.1073/pnas.2014196118
-
[37]
Vandermeulen, and Simon Kornblith
Lukas Muttenthaler, Jonas Dippel, Lorenz Linhardt, Robert A. Vandermeulen, and Simon Kornblith. Human alignment of neural network representations. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=ReDQ 1OUQR0X
2023
-
[38]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. URL https: //arxiv.org/abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[39]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Allen, Ghislain St-Yves, Yihan Wu, Jesse L
Emily J. Allen, Ghislain St-Yves, Yihan Wu, Jesse L. Breedlove, Jacob S. Prince, Logan T. Dowdle, Matthias Nau, Brad Caron, Franco Pestilli, Ian Charest, J. Benjamin Hutchinson, Thomas Naselaris, and Kendrick Kay. A massive 7t fmri dataset to bridge cognitive neuroscience and artificial intelligence.Nature Neuroscience, 25(1):116–126, December 2021. ISSN ...
-
[41]
Vo, Vasudev Lal, and Alexander Huth
Jerry Tang, Meng Du, Vy A. Vo, Vasudev Lal, and Alexander Huth. Brain encoding models based on multimodal transformers can transfer across language and vision. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/f orum?id=UPefaFqjNQ
2023
-
[42]
Multi-modal brain encoding models for multi-modal stimuli
Subba Reddy Oota, Khushbu Pahwa, mounika marreddy, Maneesh Kumar Singh, Manish Gupta, and Bapi Raju Surampudi. Multi-modal brain encoding models for multi-modal stimuli. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openrevi ew.net/forum?id=0dELcFHig2
2025
-
[43]
A multimodal seq2seq transformer for predicting brain responses to naturalistic stimuli, 2025
Qianyi He and Yuan Chang Leong. A multimodal seq2seq transformer for predicting brain responses to naturalistic stimuli, 2025. URLhttps://arxiv.org/abs/2507.18104
-
[44]
Anna A Ivanova, Martin Schrimpf, Stefano Anzellotti, Noga Zaslavsky, Evelina Fedorenko, and Leyla Isik. Beyond linear regression: mapping models in cognitive neuroscience should align with research goals.Neurons, Behavior, Data analysis, and Theory, 1, August 2022. ISSN 2690-2664. doi: 10.51628/001c.37507. URLhttp://dx.doi.org/10.51628/001c.37507
-
[45]
In silico mapping of visual categorical selectivity across the whole brain
Ethan Hwang, Hossein Adeli, Wenxuan Guo, Andrew Luo, and Nikolaus Kriegeskorte. In silico mapping of visual categorical selectivity across the whole brain. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/f orum?id=B23WUS3W8Z. 14
2025
-
[46]
Modeling the human visual system: Comparative insights from response-optimized and task-optimized vision models, language models, and different readout mechanisms
Shreya Saha, Ishaan Chadha, and Meenakshi Khosla. Modeling the human visual system: Comparative insights from response-optimized and task-optimized vision models, language models, and different readout mechanisms. In8th Annual Conference on Cognitive Computational Neuroscience, 2025. URLhttps://openreview.net/forum?id=QA0P53hQRT
2025
-
[47]
Meenakshi Khosla, Keith Jamison, Amy Kuceyeski, and Mert R. Sabuncu. Characterizing the ventral visual stream with response-optimized neural encoding models. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems, 2022. URLhttps://openreview.net/forum?id=IU3nj1tqwyY
2022
-
[48]
Improving semantic understanding in speech language models via brain-tuning
Omer Moussa, Dietrich Klakow, and Mariya Toneva. Improving semantic understanding in speech language models via brain-tuning. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=KL8Sm4xRn7
2025
-
[49]
Realnet: Achieving more human brain-like vision via human neural representational alignment
Zitong Lu, Yile Wang, and Julie Golomb. Realnet: Achieving more human brain-like vision via human neural representational alignment. InICLR 2024 Workshop on Representational Alignment,
2024
-
[50]
URLhttps://openreview.net/forum?id=BN9WE9pOSD
-
[51]
Joel Dapello, Kohitij Kar, Martin Schrimpf, Robert Baldwin Geary, Michael Ferguson, David Daniel Cox, and James J. DiCarlo. Aligning model and macaque inferior temporal cortex representations improves model-to-human behavioral alignment and adversarial robust- ness. InThe Eleventh International Conference on Learning Representations, 2023. URL https://ope...
2023
-
[52]
Perceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. Perceiver: General perception with iterative attention. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 4651–4664. PMLR, 18–24 Jul 2021. URL ...
2021
-
[53]
Perceiver IO: A general architecture for structured inputs & outputs
Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier J Henaff, Matthew Botvinick, Andrew Zisserman, Oriol Vinyals, and Joao Carreira. Perceiver IO: A general architecture for structured inputs & outputs. InInternational Conference on Learnin...
2022
-
[54]
Alexander Schaefer, Ru Kong, Evan M Gordon, Timothy O Laumann, Xi-Nian Zuo, Avram J Holmes, Simon B Eickhoff, and B T Thomas Yeo. Local-global parcellation of the human cerebral cortex from intrinsic functional connectivity mri.Cerebral Cortex, 28(9):3095–3114, July 2017. ISSN 1460-2199. doi: 10.1093/cercor/bhx179. URLhttp://dx.doi.org/10.1093/cercor/bhx1...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.