Train the Agent, Not the Expert: Learning to Harness Heterogeneous Experts for Multi-Turn Visual Reasoning
Pith reviewed 2026-06-29 08:32 UTC · model grok-4.3
The pith
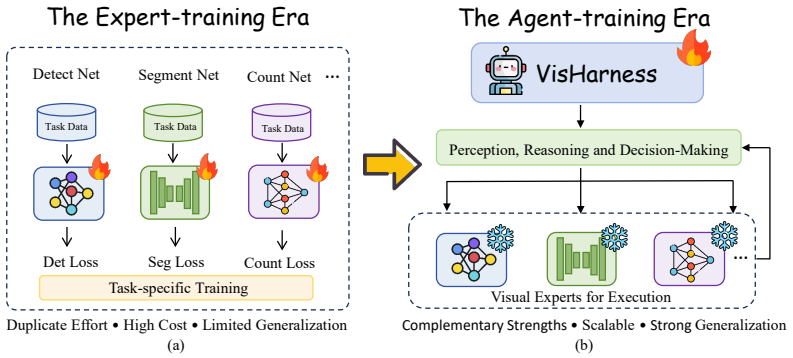
VisHarness trains a lightweight agent to select and sequence calls to fixed heterogeneous visual experts across multi-turn interactions rather than training any single expert for the full task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
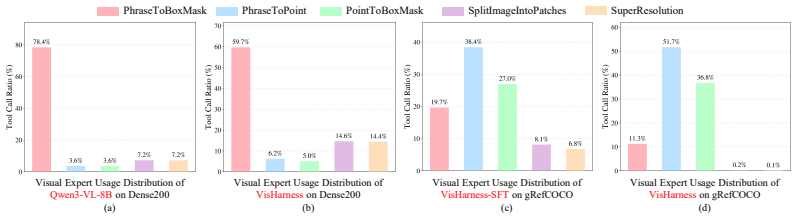
VisHarness learns a generalizable policy that, through multi-turn interactions, chooses which heterogeneous visual experts to invoke and in what order, solving complex visual tasks while preserving the experts' specialized precision and avoiding the need to fine-tune them for each new condition.
What carries the argument
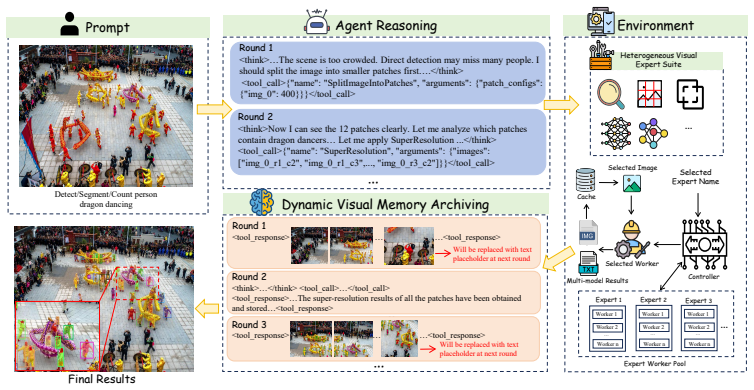
VisHarness, the trainable agent whose policy decides when and which experts to call, supported by dynamic visual memory archiving to control token growth in live multi-turn loops.
If this is right
- The same agent policy can be applied to new visual tasks by adding or swapping experts without retraining the policy from scratch.
- Multi-turn expert interaction becomes feasible at scale once memory archiving keeps token counts bounded.
- General-purpose models can be improved by wrapping them with a learned harness rather than scaling the base model further.
- Task-specific models retain their accuracy edge while gaining the flexibility of a shared decision layer.
Where Pith is reading between the lines
- If the policy generalizes across expert sets, the same training loop could be reused for entirely different modalities such as audio or 3-D data.
- The memory archiving trick may also apply to other agent systems that accumulate large context from tool calls.
- Performance gains would shrink if the experts themselves become outdated faster than the policy can be retrained.
Load-bearing premise
A single lightweight-trained policy can reliably choose and order calls to a fixed set of experts for many different complex visual conditions without any further expert retraining.
What would settle it
On a new benchmark mixing the four task types, the agent would need to produce lower accuracy than both general models and the best task-specific model in at least two categories when experts are held completely fixed.
Figures


read the original abstract
Recent progress in computer vision has produced a wide range of powerful specialized models for detection, segmentation, counting, and other visual tasks. However, these models are usually optimized for isolated task formulations, making it difficult to directly support general-purpose visual intelligence, especially when a task requires complex language understanding and dense small-object perception. In this paper, we propose VisHarness, a trainable visual agent that decouples high-level perception, reasoning, and decision-making from low-level task execution. Instead of training a model to solve a specific visual task, VisHarness learns to harness a set of carefully designed heterogeneous visual experts. This paradigm preserves the general intelligence of the agent while fully leveraging the precision advantages of specialized visual models in concrete visual tasks. With only lightweight training, VisHarness learns a generalizable visual expert-harnessing policy and can solve common fundamental vision tasks under various complex conditions through multi-turn interactions with visual expert models. To enable efficient on-policy reinforcement learning training in a live environment, we introduce dynamic visual memory archiving, which mitigates the rapidly accumulating visual-token overhead caused by multi-turn interactions with visual expert models. Experiments on four representative benchmarks covering reasoning segmentation, generalized referring segmentation, dense small-object detection, and referring counting demonstrate that VisHarness substantially outperforms existing general-purpose models and achieves competitive or superior performance compared with task-specific models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VisHarness, a trainable visual agent that decouples high-level perception, reasoning, and decision-making from low-level task execution by learning a generalizable policy to harness a set of fixed heterogeneous visual experts via multi-turn interactions. It introduces dynamic visual memory archiving to support efficient on-policy reinforcement learning by mitigating visual-token overhead. The central empirical claim is that, with only lightweight training, VisHarness substantially outperforms existing general-purpose models and achieves competitive or superior performance to task-specific models on four benchmarks covering reasoning segmentation, generalized referring segmentation, dense small-object detection, and referring counting.
Significance. If the performance claims hold under rigorous validation, the paradigm of training a lightweight general policy for expert selection and sequencing (rather than fine-tuning the experts themselves) offers a promising route toward general-purpose visual intelligence that combines flexible reasoning with the precision of specialized models. The approach is internally consistent with the described architecture and addresses a genuine limitation of task-specific optimization.
major comments (1)
- [Abstract and Experiments] Abstract and Experiments section: The benchmark results are stated without details on the specific baselines compared, error bars or statistical significance, data splits, or exact training procedures (including reward formulation and on-policy RL hyperparameters), which is load-bearing for assessing whether VisHarness truly outperforms general-purpose models or matches task-specific ones.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater experimental transparency. We agree that the current presentation of results in the abstract and experiments section lacks sufficient detail on baselines, statistical measures, data handling, and training specifics, which is essential for validating the performance claims. We will revise the manuscript to address this.
read point-by-point responses
-
Referee: The benchmark results are stated without details on the specific baselines compared, error bars or statistical significance, data splits, or exact training procedures (including reward formulation and on-policy RL hyperparameters), which is load-bearing for assessing whether VisHarness truly outperforms general-purpose models or matches task-specific ones.
Authors: We fully agree with this assessment. The revised manuscript will expand the Experiments section (and update the abstract if space permits) to explicitly list all compared baselines with citations and categories (general-purpose vs. task-specific), report error bars from multiple random seeds along with statistical significance tests (e.g., paired t-tests or Wilcoxon tests with p-values), detail the exact train/validation/test splits used for each of the four benchmarks, and provide complete training details including the reward function formulation, on-policy RL algorithm hyperparameters (learning rate, discount factor, batch size, rollout length, number of epochs), and any other procedural specifics. These additions will enable rigorous independent verification of the reported gains. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes VisHarness as an agent policy trained via lightweight on-policy RL to select and sequence calls to fixed heterogeneous experts, with dynamic memory to handle multi-turn interactions. No derivation chain reduces a claimed result to its inputs by construction: the central claim is an empirical performance advantage on four external benchmarks (reasoning segmentation, generalized referring segmentation, dense small-object detection, referring counting), which are standard and independent of the training objective or fitted parameters. No self-definitional equations, fitted-input predictions, or load-bearing self-citations are present in the provided text; the architecture is described as decoupled and the evaluation uses external task-specific models for comparison without internal reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Heterogeneous visual experts remain effective when called in sequence by an external policy without modification.
invented entities (2)
-
VisHarness
no independent evidence
-
dynamic visual memory archiving
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Open-world text-specified object counting.arXiv preprint arXiv:2306.01851, 2023
Niki Amini-Naieni, Kiana Amini-Naieni, Tengda Han, and Andrew Zisserman. Open-world text-specified object counting.arXiv preprint arXiv:2306.01851, 2023
-
[2]
Countgd: Multi-modal open-world counting.Advances in Neural Information Processing Systems, 37:48810–48837, 2024
Niki Amini-Naieni, Tengda Han, and Andrew Zisserman. Countgd: Multi-modal open-world counting.Advances in Neural Information Processing Systems, 37:48810–48837, 2024
2024
-
[3]
Shuai Bai et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Sam 3: Segment anything with concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[5]
Referring expression counting
Siyang Dai, Jun Liu, and Ngai-Man Cheung. Referring expression counting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16985–16995. IEEE, 2024
2024
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Vision-language transformer and query generation for referring segmentation
Henghui Ding, Chang Liu, Suchen Wang, and Xudong Jiang. Vision-language transformer and query generation for referring segmentation. InProceedings of the IEEE/CVF international conference on computer vision, pages 16321–16330, 2021
2021
-
[8]
Chan, and Andy J
Yaowu Fan, Jia Wan, Tao Han, Antoni B. Chan, and Andy J. Ma. Video individual counting for moving drones. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12284–12293, 2025
2025
-
[9]
Detect anything via next point prediction
Qing Jiang, Junan Huo, Xingyu Chen, Yuda Xiong, Zhaoyang Zeng, Yihao Chen, Tianhe Ren, Junzhi Yu, and Lei Zhang. Detect anything via next point prediction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026
2026
-
[10]
Locate then segment: A strong pipeline for referring image segmentation
Ya Jing, Tao Kong, Wei Wang, Liang Wang, Lei Li, and Tieniu Tan. Locate then segment: A strong pipeline for referring image segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9858–9867, 2021
2021
-
[11]
Kimi K2.5: Visual Agentic Intelligence
Kimi Team. Kimi K2.5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick. Segment anything. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4015–4026, October 2023
2023
-
[13]
Lisa: Reasoning segmentation via large language model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9579–9589, 2024
2024
-
[14]
Text4seg++: Advancing image segmentation via generative language modeling.IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–16, 2026
Mengcheng Lan, Chaofeng Chen, Jiaxing Xu, Zongrui Li, Yiping Ke, Xudong Jiang, Yingchen Yu, Yunqing Zhao, and Song Bai. Text4seg++: Advancing image segmentation via generative language modeling.IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–16, 2026
2026
-
[15]
Gres: Generalized referring expression segmenta- tion
Chang Liu, Henghui Ding, and Xudong Jiang. Gres: Generalized referring expression segmenta- tion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23592–23601. IEEE, 2023
2023
-
[16]
Llava-plus: Learning to use tools for creating multimodal agents
Shilong Liu, Hao Cheng, Haotian Liu, Hao Zhang, Feng Li, Tianhe Ren, Xueyan Zou, Jianwei Yang, Hang Su, Jun Zhu, et al. Llava-plus: Learning to use tools for creating multimodal agents. InEuropean conference on computer vision, pages 126–142. Springer, 2024. 10
2024
-
[17]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision, pages 38–55. Springer, 2024
2024
-
[18]
Seg-Zero: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement
Yuqi Liu, Bohao Peng, Zhisheng Zhong, Zihao Yue, Fanbin Lu, Bei Yu, and Jiaya Jia. Seg- zero: Reasoning-chain guided segmentation via cognitive reinforcement.arXiv preprint arXiv:2503.06520, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Cohd: A counting-aware hierarchical decoding framework for generalized referring expression segmentation
Zhuoyan Luo, Yinghao Wu, Tianheng Cheng, Yong Liu, Yicheng Xiao, Hongfa Wang, Xiao- Ping Zhang, and Yujiu Yang. Cohd: A counting-aware hierarchical decoding framework for generalized referring expression segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22685–22694, 2025
2025
-
[20]
ToolRL: Reward is All Tool Learning Needs
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani-Tür, Gokhan Tur, and Heng Ji. Toolrl: Reward is all tool learning needs.arXiv preprint arXiv:2504.13958, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026
2026
-
[22]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
arXiv preprint arXiv:2509.25164 (2025)
Ranjan Sapkota, Rahul Harsha Cheppally, Ajay Sharda, and Manoj Karkee. Yolo26: key architectural enhancements and performance benchmarking for real-time object detection.arXiv preprint arXiv:2509.25164, 2025
-
[24]
Training-free object counting with prompts
Zenglin Shi, Ying Sun, and Mengmi Zhang. Training-free object counting with prompts. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pages 323–331, 2024
2024
-
[25]
OpenThinkIMG: Learning to Think with Images via Visual Tool Reinforcement Learning
Zhaochen Su, Linjie Li, Mingyang Song, Yunzhuo Hao, Zhengyuan Yang, Jun Zhang, Guanjie Chen, Jiawei Gu, Juntao Li, Xiaoye Qu, et al. Openthinkimg: Learning to think with images via visual tool reinforcement learning.arXiv preprint arXiv:2505.08617, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Hao Tang, Chenwei Xie, Haiyang Wang, Xiaoyi Bao, Tingyu Weng, Pandeng Li, Yun Zheng, and Liwei Wang. Ufo: A unified approach to fine-grained visual perception via open-ended language interface.arXiv preprint arXiv:2503.01342, 2025
-
[27]
A generalized loss function for crowd counting and localization
Jia Wan, Ziquan Liu, and Antoni B Chan. A generalized loss function for crowd counting and localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1974–1983, 2021
1974
-
[28]
Git: Towards generalist vision transformer through universal language interface
Haiyang Wang, Hao Tang, Li Jiang, Shaoshuai Shi, Muhammad Ferjad Naeem, Hongsheng Li, Bernt Schiele, and Liwei Wang. Git: Towards generalist vision transformer through universal language interface. InComputer Vision – ECCV 2024, pages 55–73. Springer Nature Switzerland, 2025
2024
-
[29]
Acting less is reasoning more! teaching model to act efficiently, 2025
Hongru Wang, Cheng Qian, Wanjun Zhong, Xiusi Chen, Jiahao Qiu, Shijue Huang, Bowen Jin, Mengdi Wang, Kam-Fai Wong, and Heng Ji. Acting less is reasoning more! teaching model to act efficiently.arXiv preprint arXiv:2504.14870, 2025
-
[30]
X. Wang, S. Zhang, S. Li, K. Li, K. Kallidromitis, Y . Kato, K. Kozuka, and T. Darrell. Segllm: Multi-round reasoning segmentation with large language models. InThe Thirteenth Interna- tional Conference on Learning Representations, 2025
2025
-
[31]
Refdetector: A simple yet effective matching-based method for referring expression comprehension
Yabing Wang, Zhuotao Tian, Zheng Qin, Sanping Zhou, and Le Wang. Refdetector: A simple yet effective matching-based method for referring expression comprehension. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 8033–8041, 2025
2025
-
[32]
Cris: Clip-driven referring image segmentation
Zhaoqing Wang, Yu Lu, Qiang Li, Xunqiang Tao, Yandong Guo, Mingming Gong, and Tongliang Liu. Cris: Clip-driven referring image segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11686–11695, 2022. 11
2022
-
[33]
Instructseg: Unifying instructed visual segmentation with multi-modal large language models
Cong Wei, Yujie Zhong, Haoxian Tan, Yingsen Zeng, Yong Liu, Hongfa Wang, and Yujiu Yang. Instructseg: Unifying instructed visual segmentation with multi-modal large language models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20193–20203, 2025
2025
-
[34]
Dettoolchain: A new prompting paradigm to unleash detection ability of mllm
Yixuan Wu, Yizhou Wang, Shixiang Tang, Wenhao Wu, Tong He, Wanli Ouyang, Philip Torr, and Jian Wu. Dettoolchain: A new prompting paradigm to unleash detection ability of mllm. In European Conference on Computer Vision, pages 164–182. Springer, 2024
2024
-
[35]
Gsva: Generalized segmentation via multimodal large language models
Zhuofan Xia, Dongchen Han, Yizeng Han, Xuran Pan, Shiji Song, and Gao Huang. Gsva: Generalized segmentation via multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3858–3869, 2024
2024
-
[36]
Zero-shot object counting
Jingyi Xu, Hieu Le, Vu Nguyen, Viresh Ranjan, and Dimitris Samaras. Zero-shot object counting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15548–15557, June 2023
2023
-
[37]
Zero-shot object counting with language-vision models.arXiv preprint arXiv:2309.13097, 2023
Jingyi Xu, Hieu Le, and Dimitris Samaras. Zero-shot object counting with language-vision models.arXiv preprint arXiv:2309.13097, 2023
-
[38]
Yuqi Yang, Peng-Tao Jiang, Jing Wang, Hao Zhang, Kai Zhao, Jinwei Chen, and Bo Li. Empowering segmentation ability to multi-modal large language models.arXiv preprint arXiv:2403.14141, 2024
-
[39]
Language-aware vision transformer for referring segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(7):5238–5255, 2024
Zhao Yang, Jiaqi Wang, Xubing Ye, Yansong Tang, Kai Chen, Hengshuang Zhao, and Philip HS Torr. Language-aware vision transformer for referring segmentation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(7):5238–5255, 2024
2024
-
[40]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection.arXiv preprint arXiv:2010.04159, 2020. 12
work page internal anchor Pith review Pith/arXiv arXiv 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.