Midpoint Generative Models
Pith reviewed 2026-06-29 08:42 UTC · model grok-4.3
The pith
The vanishing drift field at the midpoint of flow matching paths defines a discrepancy that trains one-step generative models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
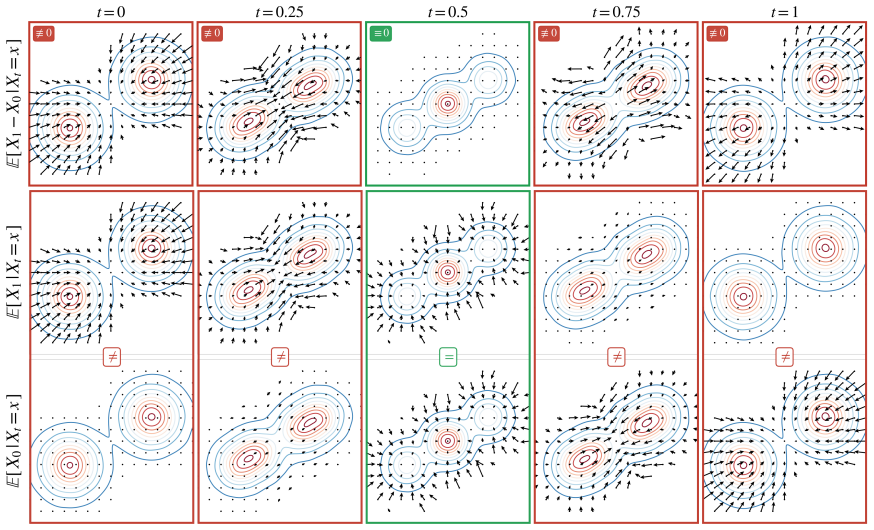
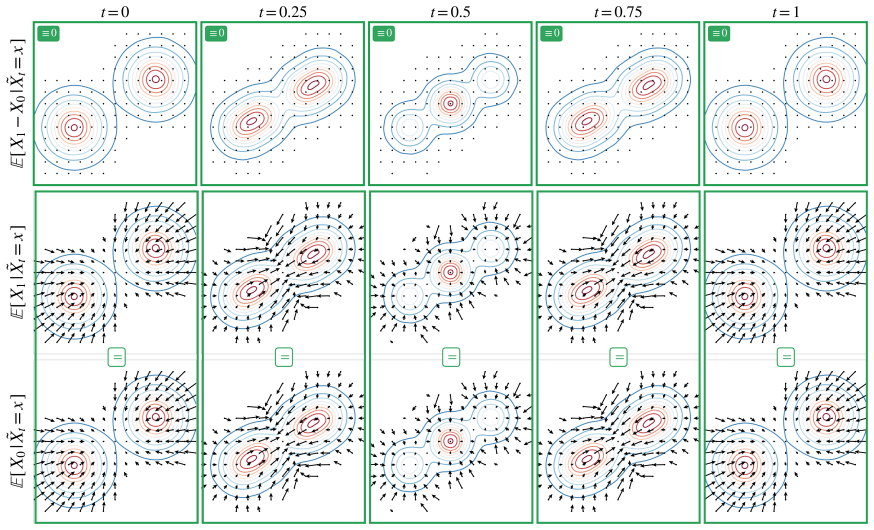
Midpoint Generative Models are built on the fact that the flow-matching drift field vanishes at the midpoint time t=1/2 whenever the source and target distributions coincide. The squared norm of this field therefore measures the difference between the distributions and is termed the Midpoint Divergence. Randomly flipped interpolations extend the measure away from the single midpoint, while replacing deterministic linear paths with symmetric stochastic interpolants yields a generalized Midpoint Divergence. A variational lower bound on this generalized divergence supplies a tractable loss that trains a one-step generator mapping noise directly to data.
What carries the argument
The Midpoint Divergence, defined as the norm of the flow-matching drift field evaluated at the interpolation midpoint t=1/2.
If this is right
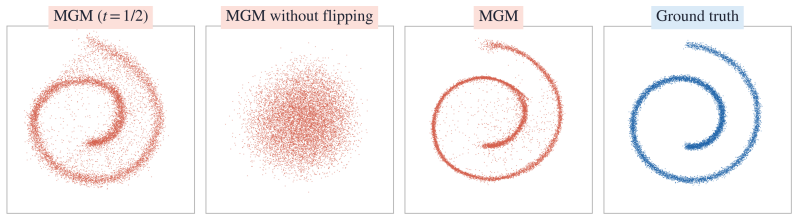
- The MGM algorithm trains one-step generators from a variational objective derived from the generalized midpoint divergence.
- The method reaches competitive performance with other one-step generative modeling techniques on standard benchmarks.
- Randomly flipped interpolations extend the discrepancy beyond a single midpoint evaluation.
- Symmetric stochastic interpolants replace deterministic linear paths while preserving the validity of the divergence.
Where Pith is reading between the lines
- The midpoint symmetry could be tested for stability under small perturbations of the interpolation schedule.
- The variational loss might be combined with perceptual or feature-based regularizers for tasks such as image synthesis.
- If the same vanishing property holds for other families of interpolants, similar one-step objectives could be derived without flow matching.
- Conditional generation could be obtained by simply replacing the marginal distributions with conditional ones inside the same midpoint construction.
Load-bearing premise
When the endpoint distributions are identical, the flow-matching drift field under linear interpolation is exactly zero at the midpoint time t=1/2.
What would settle it
Minimize the variational midpoint-divergence objective on a pair of identical distributions and check whether the learned one-step generator produces samples whose empirical distribution matches the target to within sampling error; the claim fails if the generator still produces mismatched outputs.
Figures

read the original abstract
We introduce Midpoint Generative Models (MGM), a principled framework for training one-step generative models. MGM is based on a simple symmetry of Flow Matching with linear interpolation: when the two endpoint distributions coincide, the corresponding drift field vanishes at the midpoint time, $t=1/2$. We show that the norm of this field defines a valid discrepancy between distributions, which we call the Midpoint Divergence. We extend this discrepancy beyond the midpoint by introducing randomly flipped interpolations and further generalize it by replacing deterministic linear Flow Matching interpolations with symmetric stochastic interpolants, yielding a generalized Midpoint Divergence. Finally, we derive a variational formulation of our generalized divergence, yielding a tractable objective for training a one-step generator. The resulting MGM algorithm offers an effective and theoretically grounded approach to generative modeling, achieving competitive performance against existing one-step generative modeling methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Midpoint Generative Models (MGM) for one-step generative modeling. It starts from the symmetry property of Flow Matching with linear interpolation: when the endpoint distributions coincide, the drift field vanishes at the midpoint t=1/2. The norm of this field is defined as the Midpoint Divergence, a valid discrepancy. The construction is extended via randomly flipped interpolations and then generalized by replacing deterministic linear interpolants with symmetric stochastic interpolants. A variational formulation of the generalized divergence is derived, producing a tractable training objective for a one-step generator. Experiments are reported to show competitive performance against existing one-step methods.
Significance. If the discrepancy property and variational derivation hold, the work supplies a new, symmetry-based objective for training one-step generators directly from flow-matching ideas. The explicit construction from the vanishing drift and the move to a variational form are clear strengths; the paper also ships reproducible code and falsifiable predictions via the discrepancy definition. This could provide a principled alternative to distillation or consistency-model approaches in the one-step regime.
minor comments (3)
- [Abstract] Abstract: the phrase 'achieving competitive performance' should be accompanied by a brief statement of the primary metric and main baselines so that the claim can be evaluated without reading the full experimental section.
- [Section 3] Notation: the definition of the symmetric stochastic interpolant (around Eq. (generalized form)) uses the same symbol for the random flip indicator in both the deterministic and stochastic cases; a distinct symbol or explicit conditioning would improve clarity.
- [Section 5] Table 1: the reported FID values for MGM are given without standard deviations across seeds; adding error bars would strengthen the comparison to the one-step baselines.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work on Midpoint Generative Models and for recommending minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The derivation begins from the symmetry property of Flow Matching (when endpoint distributions coincide the drift vanishes at t=1/2), which follows directly from exchangeability of the joint law and is external to the present work. The Midpoint Divergence is then defined as the norm of that field, with the claim that it is a valid discrepancy (zero iff distributions coincide) presented as shown rather than assumed by construction. Subsequent extensions (random flips, symmetric stochastic interpolants) and the variational formulation are introduced as new steps that produce a tractable objective; none of these reduce the central claims to fitted inputs, self-citations, or definitional renaming. The paper is therefore self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Flow Matching with linear interpolation has the property that the drift field vanishes at the midpoint t=1/2 when the two endpoint distributions coincide.
invented entities (2)
-
Midpoint Divergence
no independent evidence
-
Generalized Midpoint Divergence
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in neural information processing systems, 34:8780–8794, 2021
2021
-
[2]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[3]
Video diffusion models.Advances in neural information processing systems, 35: 8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models.Advances in neural information processing systems, 35: 8633–8646, 2022
2022
-
[4]
Diffwave: A versatile diffusion model for audio synthesis
Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. Diffwave: A versatile diffusion model for audio synthesis. InInternational Conference on Learning Representations,
-
[5]
URLhttps://openreview.net/forum?id=a-xFK8Ymz5J
-
[6]
SDEdit: Guided image synthesis and editing with stochastic differential equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. SDEdit: Guided image synthesis and editing with stochastic differential equations. In International Conference on Learning Representations, 2022. URL https://openreview. net/forum?id=aBsCjcPu_tE
2022
-
[7]
Palette: Image-to-image diffusion models
Chitwan Saharia, William Chan, Huiwen Chang, Chris Lee, Jonathan Ho, Tim Salimans, David Fleet, and Mohammad Norouzi. Palette: Image-to-image diffusion models. InACM SIGGRAPH 2022 conference proceedings, pages 1–10, 2022
2022
-
[8]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[9]
Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35: 26565–26577, 2022
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models.Advances in neural information processing systems, 35: 26565–26577, 2022
2022
-
[10]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in neural information processing systems, 35:5775–5787, 2022
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in neural information processing systems, 35:5775–5787, 2022
2022
-
[11]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. In International Conference on Learning Representations, 2022. URL https://openreview. net/forum?id=TIdIXIpzhoI
2022
-
[12]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. In International Conference on Machine Learning, pages 32211–32252. PMLR, 2023
2023
-
[13]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6613–6623, 2024
2024
-
[14]
Adversarial diffusion distillation
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation. InEuropean Conference on Computer Vision, pages 87–103. Springer, 2024
2024
-
[15]
Susskind
Jiatao Gu, Shuangfei Zhai, Yizhe Zhang, Lingjie Liu, and Joshua M. Susskind. BOOT: Data-free distillation of denoising diffusion models with bootstrapping. InICML 2023 Work- shop on Structured Probabilistic Inference & Generative Modeling, 2023. URL https: //openreview.net/forum?id=ZeM7S01Xi8
2023
-
[16]
Improved techniques for training consistency models
Yang Song and Prafulla Dhariwal. Improved techniques for training consistency models. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=WNzy9bRDvG
2024
-
[17]
One step diffusion via shortcut models
Kevin Frans, Danijar Hafner, Sergey Levine, and Pieter Abbeel. One step diffusion via shortcut models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=OlzB6LnXcS. 10
2025
-
[18]
Mean Flows for One-step Generative Modeling
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Building normalizing flows with stochastic interpolants
Michael Samuel Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=li7qeBbCR1t
2023
-
[22]
Stochastic interpolants: A unifying framework for flows and diffusions.Journal of Machine Learning Research, 26(209): 1–80, 2025
Michael Albergo, Nicholas M Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.Journal of Machine Learning Research, 26(209): 1–80, 2025
2025
-
[23]
Simplifying, stabilizing and scaling continuous-time consistency models
Cheng Lu and Yang Song. Simplifying, stabilizing and scaling continuous-time consistency models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=LyJi5ugyJx
2025
-
[24]
Consistency trajectory models: Learning probability flow ODE trajectory of diffusion
Dongjun Kim, Chieh-Hsin Lai, Wei-Hsiang Liao, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yutong He, Yuki Mitsufuji, and Stefano Ermon. Consistency trajectory models: Learning probability flow ODE trajectory of diffusion. InThe Twelfth International Confer- ence on Learning Representations, 2024. URLhttps://openreview.net/forum?id= ymjI8feDTD
2024
-
[25]
David Berthelot, Arnaud Autef, Jierui Lin, Dian Ang Yap, Shuangfei Zhai, Siyuan Hu, Daniel Zheng, Walter Talbott, and Eric Gu. Tract: Denoising diffusion models with transitive closure time-distillation.arXiv preprint arXiv:2303.04248, 2023
-
[26]
Consistency models made easy
Zhengyang Geng, Ashwini Pokle, Weijian Luo, Justin Lin, and J Zico Kolter. Consistency models made easy. InThe Thirteenth International Conference on Learning Representations,
-
[27]
URLhttps://openreview.net/forum?id=xQVxo9dSID
-
[28]
Truncated consistency models
Sangyun Lee, Yilun Xu, Tomas Geffner, Giulia Fanti, Karsten Kreis, Arash Vahdat, and Weili Nie. Truncated consistency models. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=ZYDEJEvCbv
2025
-
[29]
Diff- instruct: A universal approach for transferring knowledge from pre-trained diffusion models
Weijian Luo, Tianyang Hu, Shifeng Zhang, Jiacheng Sun, Zhenguo Li, and Zhihua Zhang. Diff- instruct: A universal approach for transferring knowledge from pre-trained diffusion models. Advances in Neural Information Processing Systems, 36:76525–76546, 2023
2023
-
[30]
Improved distribution matching distillation for fast image synthesis.Advances in neural information processing systems, 37:47455–47487, 2024
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and Bill Freeman. Improved distribution matching distillation for fast image synthesis.Advances in neural information processing systems, 37:47455–47487, 2024
2024
-
[31]
Yilun Xu, Weili Nie, and Arash Vahdat. One-step diffusion models with f-divergence distribu- tion matching.arXiv preprint arXiv:2502.15681, 2025
-
[32]
Score identity distillation: Exponentially fast distillation of pretrained diffusion models for one-step generation
Mingyuan Zhou, Huangjie Zheng, Zhendong Wang, Mingzhang Yin, and Hai Huang. Score identity distillation: Exponentially fast distillation of pretrained diffusion models for one-step generation. InForty-first International Conference on Machine Learning, 2024
2024
-
[33]
One-step diffusion distillation through score implicit matching.Advances in Neural Information Processing Systems, 37:115377–115408, 2024
Weijian Luo, Zemin Huang, Zhengyang Geng, J Zico Kolter, and Guo-jun Qi. One-step diffusion distillation through score implicit matching.Advances in Neural Information Processing Systems, 37:115377–115408, 2024
2024
-
[34]
Inverse bridge matching distillation
Nikita Gushchin, David Li, Daniil Selikhanovych, Evgeny Burnaev, Dmitry Baranchuk, and Alexander Korotin. Inverse bridge matching distillation. InForty-second International Con- ference on Machine Learning, 2025. URL https://openreview.net/forum?id= UCJSF6Vt0C. 11
2025
-
[35]
Flow generator matching.arXiv preprint arXiv:2410.19310, 2024
Zemin Huang, Zhengyang Geng, Weijian Luo, and Guo-jun Qi. Flow generator matching.arXiv preprint arXiv:2410.19310, 2024
-
[36]
Overclocking electrostatic generative models
Daniil Shlenskii and Alexander Korotin. Overclocking electrostatic generative models. 2026. URLhttps://openreview.net/forum?id=flo449mncA
2026
-
[37]
Universal inverse distillation for matching models with real-data supervision (no GANs)
Nikita Maksimovich Kornilov, David Li, Tikhon Mavrin, Aleksei Leonov, Nikita Gushchin, Evgeny Burnaev, Iaroslav Sergeevich Koshelev, and Alexander Korotin. Universal inverse distillation for matching models with real-data supervision (no GANs). InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?i...
2026
-
[38]
Improved Techniques for Training Consistency Models
Yang Song and Prafulla Dhariwal. Improved techniques for training consistency models.arXiv preprint arXiv:2310.14189, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Flow map matching with stochastic interpolants: A mathematical framework for consistency models
Nicholas Matthew Boffi, Michael Samuel Albergo, and Eric Vanden-Eijnden. Flow map matching with stochastic interpolants: A mathematical framework for consistency models. Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URL https:// openreview.net/forum?id=cqDH0e6ak2
2025
-
[40]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014
2014
-
[41]
f-gan: Training generative neural samplers using variational divergence minimization.Advances in neural information processing systems, 29, 2016
Sebastian Nowozin, Botond Cseke, and Ryota Tomioka. f-gan: Training generative neural samplers using variational divergence minimization.Advances in neural information processing systems, 29, 2016
2016
-
[42]
Wasserstein generative adversarial networks
Martin Arjovsky, Soumith Chintala, and Léon Bottou. Wasserstein generative adversarial networks. InInternational conference on machine learning, pages 214–223. Pmlr, 2017
2017
-
[43]
Tackling the generative learning trilemma with denoising diffusion GANs
Zhisheng Xiao, Karsten Kreis, and Arash Vahdat. Tackling the generative learning trilemma with denoising diffusion GANs. InInternational Conference on Learning Representations,
-
[44]
URLhttps://openreview.net/forum?id=JprM0p-q0Co
-
[45]
Diffusion-GAN: Training GANs with diffusion
Zhendong Wang, Huangjie Zheng, Pengcheng He, Weizhu Chen, and Mingyuan Zhou. Diffusion-GAN: Training GANs with diffusion. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id= HZf7UbpWHuA
2023
-
[46]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
2009
-
[47]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[48]
Let us build bridges: Understanding and extending diffusion generative models
Xingchao Liu, Lemeng Wu, Mao Ye, et al. Let us build bridges: Understanding and extending diffusion generative models. InNeurIPS 2022 Workshop on Score-Based Methods, 2022
2022
-
[49]
Denoising diffusion bridge models
Linqi Zhou, Aaron Lou, Samar Khanna, and Stefano Ermon. Denoising diffusion bridge models. arXiv preprint arXiv:2309.16948, 2023
-
[50]
Diffusion bridge implicit models.arXiv preprint arXiv:2405.15885, 2024
Kaiwen Zheng, Guande He, Jianfei Chen, Fan Bao, and Jun Zhu. Diffusion bridge implicit models.arXiv preprint arXiv:2405.15885, 2024
-
[51]
Consistency diffusion bridge models.Advances in Neural Information Processing Systems, 37:23516–23548, 2024
Guande He, Kaiwen Zheng, Jianfei Chen, Fan Bao, and Jun Zhu. Consistency diffusion bridge models.Advances in Neural Information Processing Systems, 37:23516–23548, 2024
2024
-
[52]
Implicit image-to-image schrödinger bridge for image restoration.Pattern Recognition, 165:111627, 2025
Yuang Wang, Siyeop Yoon, Pengfei Jin, Matthew Tivnan, Sifan Song, Zhennong Chen, Rui Hu, Li Zhang, Quanzheng Li, Zhiqiang Chen, et al. Implicit image-to-image schrödinger bridge for image restoration.Pattern Recognition, 165:111627, 2025. 12
2025
-
[53]
Zheyuan Hu, Chieh-Hsin Lai, Yuki Mitsufuji, and Stefano Ermon. Cmt: Mid-training for effi- cient learning of consistency, mean flow, and flow map models.arXiv preprint arXiv:2509.24526, 2025
-
[54]
Diffratio: Training one-step diffusion models without teacher supervision.arXiv e-prints, pages arXiv–2502, 2025
Wenlin Chen, Mingtian Zhang, Jiajun He, Zijing Ou, José Miguel Hernández-Lobato, Bernhard Schölkopf, and David Barber. Diffratio: Training one-step diffusion models without teacher supervision.arXiv e-prints, pages arXiv–2502, 2025
2025
-
[55]
Stable consistency tuning: Understanding and improving consistency models
Fu-Yun Wang, Zhengyang Geng, and Hongsheng Li. Stable consistency tuning: Understanding and improving consistency models. InICLR 2025 Workshop on Deep Generative Model in Machine Learning: Theory, Principle and Efficacy, 2025. URL https://openreview. net/forum?id=5RoPe2ShXx
2025
-
[56]
Fast sampling of diffusion models via operator learning
Hongkai Zheng, Weili Nie, Arash Vahdat, Kamyar Azizzadenesheli, and Anima Anandkumar. Fast sampling of diffusion models via operator learning. InInternational conference on machine learning, pages 42390–42402. PMLR, 2023
2023
-
[57]
Training generative adversarial networks with limited data.Advances in neural information processing systems, 33:12104–12114, 2020
Tero Karras, Miika Aittala, Janne Hellsten, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Training generative adversarial networks with limited data.Advances in neural information processing systems, 33:12104–12114, 2020
2020
-
[58]
Inductive moment matching.arXiv preprint arXiv:2503.07565, 2025
Linqi Zhou, Stefano Ermon, and Jiaming Song. Inductive moment matching.arXiv preprint arXiv:2503.07565, 2025
-
[59]
Discussion and Limitations
Gianluigi Silvestri, Luca Ambrogioni, Chieh-Hsin Lai, Yuhta Takida, and Yuki Mitsufuji. VCT: Training consistency models with variational noise coupling. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id= CMoX0BEsDs. 13 A Proofs In this section, we provide proofs for all theorems and propositions in the...
2025
-
[60]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.