EarlyTom: Early Token Compression Completes Fast Video Understanding
Pith reviewed 2026-06-29 08:13 UTC · model grok-4.3
The pith
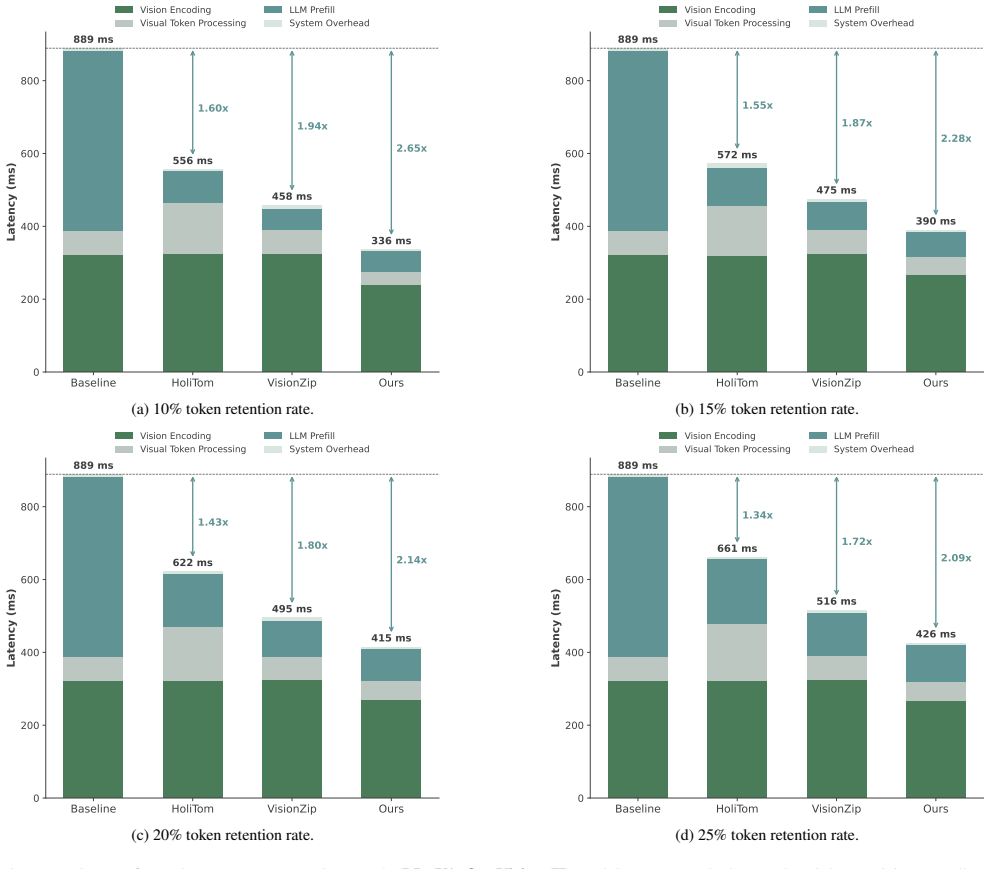
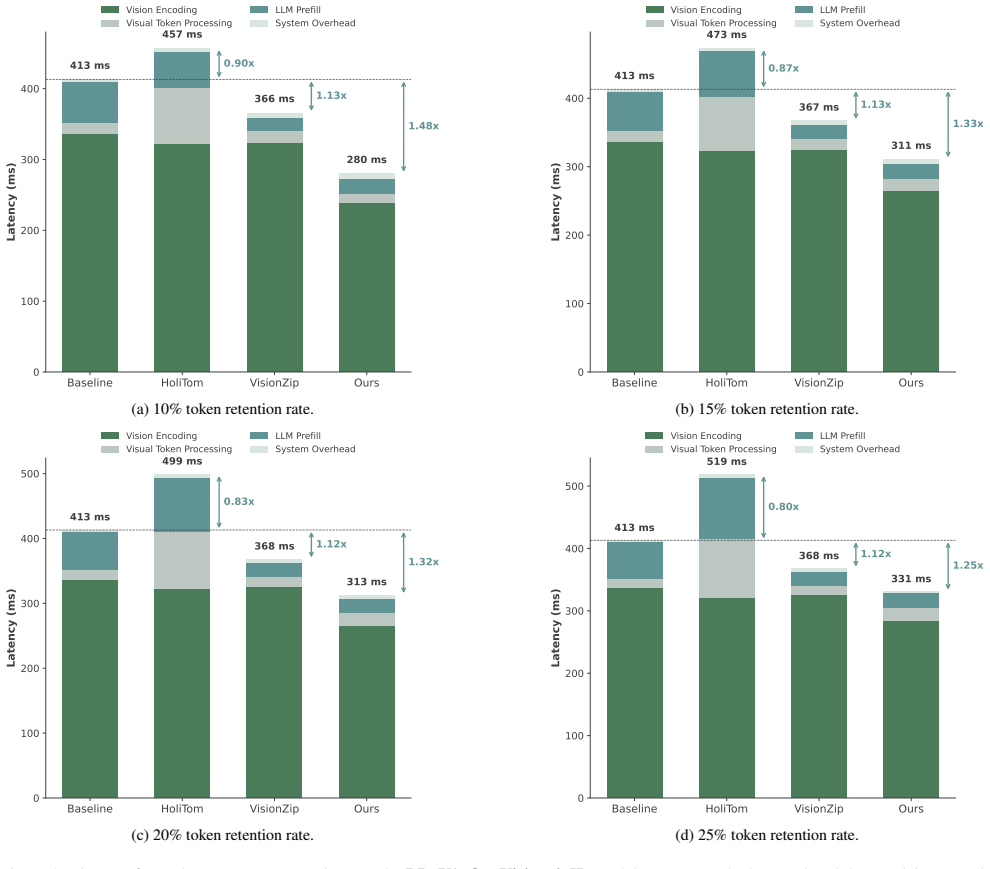
Compressing visual tokens early inside the vision encoder reduces time-to-first-token by up to 2.65 times for video large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
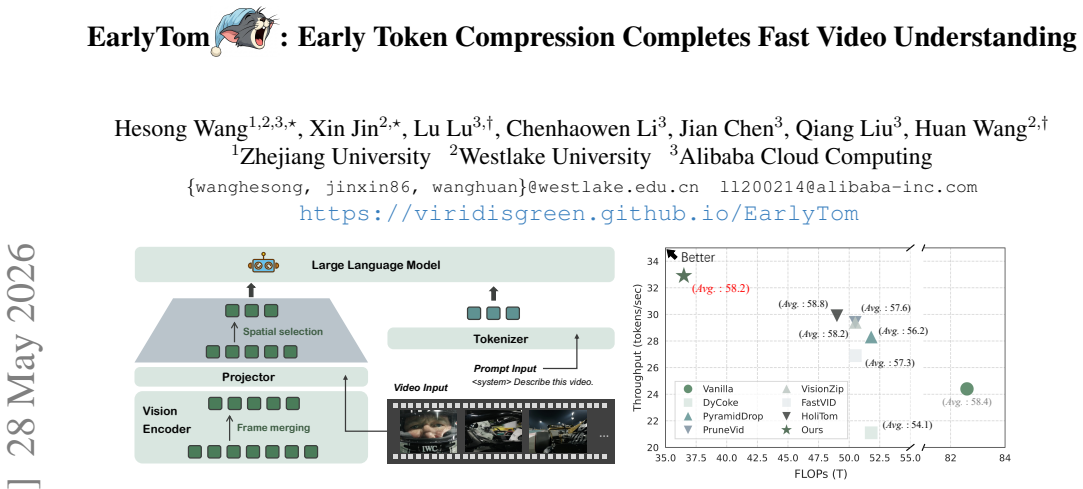
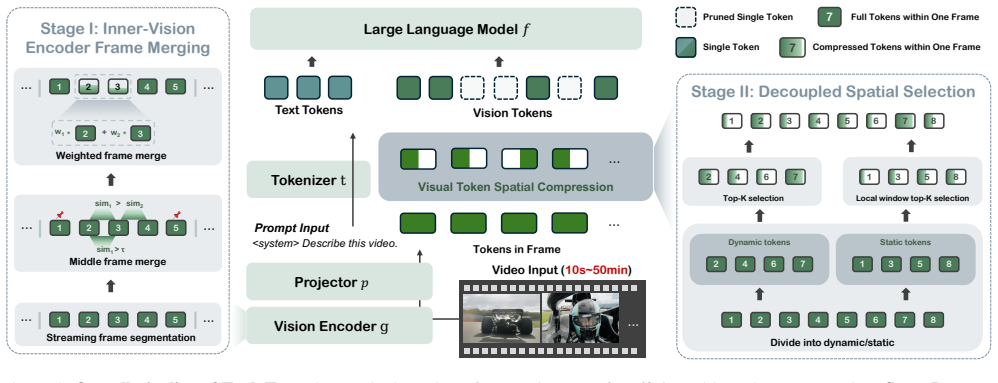
EarlyTom performs early-stage visual token compression inside the vision encoder using a training-free framework and a decoupled spatial token selection strategy. This leads to substantial reductions in time-to-first-token and FLOPs for models like LLaVA-OneVision-7B, with accuracy remaining comparable to using all tokens.
What carries the argument
EarlyTom, a training-free token compression framework that performs compression inside the vision encoder with decoupled spatial token selection.
If this is right
- TTFT is reduced by up to 2.65x on a single NVIDIA A100 GPU.
- FLOPs are reduced by up to 61% for the same model.
- Accuracy stays comparable to the full-token baseline on video understanding tasks.
- Higher throughput is achieved, improving deployment practicality.
Where Pith is reading between the lines
- If the early compression works across different vision encoders, it could be applied to other Video-LLM architectures without modification.
- Testing on longer videos or different tasks might reveal limits where information loss becomes noticeable.
- The method could combine with later-stage compression for even greater efficiency gains.
Load-bearing premise
The assumption that performing token compression inside the vision encoder preserves enough information for accurate video understanding without any retraining or adjustments.
What would settle it
Running the LLaVA-OneVision-7B model with and without EarlyTom on a standard video question-answering benchmark and measuring both the time to first token and the final accuracy to check if the claimed reductions hold while accuracy remains similar.
Figures

read the original abstract
Video large language models (Video-LLMs) have demonstrated strong capabilities in video understanding tasks. However, their practical deployment is still hindered by the inefficiency introduced by processing massive amounts of visual tokens. Although recent approaches achieve extremely low token retention ratios while maintaining accuracy comparable to full-token baselines, most of them perform compression only at the late stage of prefilling, leaving the efficiency of the vision encoder unoptimized. In this paper, we first show that vision encoding contributes a large portion to the time-to-first-token (TTFT). Therefore, instead of compressing visual tokens only after the vision encoder, performing compression inside the encoder still leaves substantial room for exploration. Based on this insight, we propose EarlyTom, a training-free token compression framework that performs early-stage visual token compression inside the vision encoder, enabling significantly better TTFT reduction and higher throughput. In addition, we introduce a decoupled spatial token selection strategy that improves the overall compression effectiveness. EarlyTom reduces TTFT by up to 2.65x and FLOPs by up to 61% on a single NVIDIA A100 GPU for the LLaVA-OneVision-7B model, while maintaining accuracy comparable to the full-token baseline. These improvements substantially enhance the practicality of deploying Video-LLMs in real-world production scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EarlyTom, a training-free token compression framework for Video-LLMs that performs early-stage visual token compression inside the vision encoder (rather than only at late prefilling stages) using a decoupled spatial token selection strategy. It reports empirical gains of up to 2.65x TTFT reduction and 61% FLOP reduction on LLaVA-OneVision-7B while maintaining accuracy comparable to the full-token baseline.
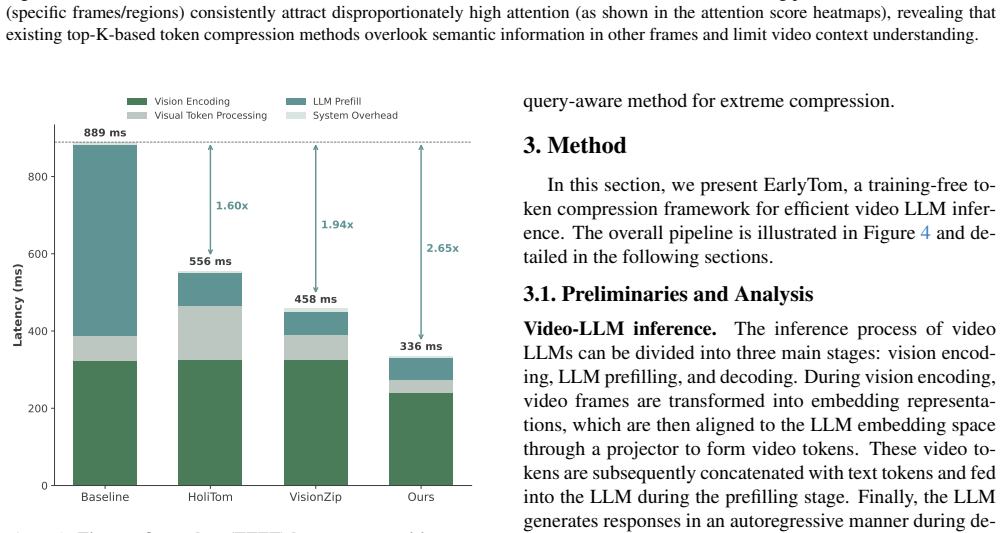
Significance. If the empirical results hold under detailed scrutiny, the work targets a practically important bottleneck in Video-LLM deployment by optimizing the vision-encoding stage of TTFT. The training-free design and explicit focus on early (inside-encoder) compression are strengths relative to prior late-stage methods; the reported speedups on a single A100 would be meaningful for production scenarios if reproducible.
major comments (3)
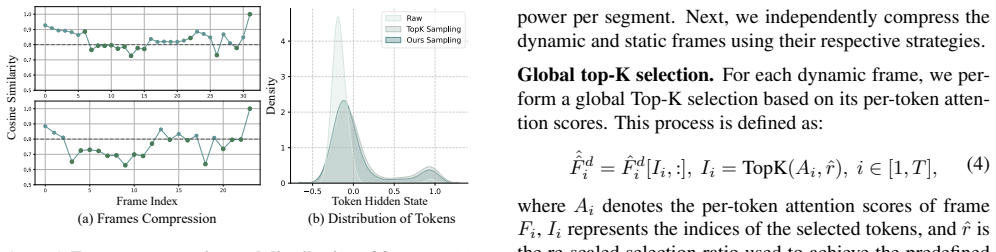
- [Abstract / Motivation section] The central motivation—that vision encoding contributes a large portion of TTFT—is load-bearing for the decision to compress inside the encoder, yet the abstract supplies no quantitative breakdown (e.g., percentage of TTFT attributable to the vision encoder versus LLM prefilling) or supporting figure; without this, the claimed room for improvement cannot be evaluated.
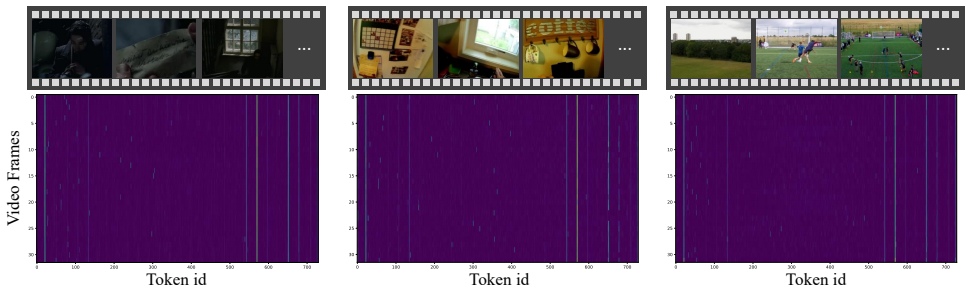
- [Abstract / Method description] The claim that the decoupled spatial token selection “preserves necessary information” in a training-free manner is central to the accuracy-comparability assertion, but the abstract provides neither ablation results on the selection criterion nor information-preservation metrics (e.g., token importance scores or downstream task breakdowns); this leaves the weakest assumption untested.
- [Abstract / Experiments] The headline numbers (2.65x TTFT, 61% FLOPs on LLaVA-OneVision-7B) are presented without reference to error bars, number of runs, video lengths, or dataset statistics; if these are absent from the experimental tables as well, the “comparable accuracy” claim cannot be assessed for statistical robustness.
minor comments (1)
- Notation for the decoupled spatial selection strategy is introduced only at a high level; a concise equation or pseudocode block would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback focused on strengthening the abstract. We address each major comment below and will make targeted revisions to the abstract to incorporate supporting details from the manuscript body.
read point-by-point responses
-
Referee: [Abstract / Motivation section] The central motivation—that vision encoding contributes a large portion of TTFT—is load-bearing for the decision to compress inside the encoder, yet the abstract supplies no quantitative breakdown (e.g., percentage of TTFT attributable to the vision encoder versus LLM prefilling) or supporting figure; without this, the claimed room for improvement cannot be evaluated.
Authors: The full manuscript (Section 3 and associated figures) contains the quantitative profiling analysis and supporting evidence for the vision encoder's contribution to TTFT. We will revise the abstract to include a concise reference to this breakdown, directly drawn from the manuscript's analysis, to make the motivation self-contained. revision: yes
-
Referee: [Abstract / Method description] The claim that the decoupled spatial token selection “preserves necessary information” in a training-free manner is central to the accuracy-comparability assertion, but the abstract provides neither ablation results on the selection criterion nor information-preservation metrics (e.g., token importance scores or downstream task breakdowns); this leaves the weakest assumption untested.
Authors: The manuscript body provides ablations on the selection criterion and validates preservation through downstream task accuracy. We will revise the abstract to briefly note that the decoupled strategy is supported by such experiments while maintaining comparable accuracy, without expanding the abstract into full ablation details. revision: yes
-
Referee: [Abstract / Experiments] The headline numbers (2.65x TTFT, 61% FLOPs on LLaVA-OneVision-7B) are presented without reference to error bars, number of runs, video lengths, or dataset statistics; if these are absent from the experimental tables as well, the “comparable accuracy” claim cannot be assessed for statistical robustness.
Authors: The manuscript's experimental section, tables, and appendix already detail the benchmarks, video lengths, dataset statistics, and evaluation protocol (including multiple runs where applicable). We will add explicit error bars or variance measures to the main result tables if not already present and clarify run counts in the text. The abstract will be lightly updated to reference 'standard benchmark protocols' for context. revision: partial
Circularity Check
No significant circularity; empirical measurements only
full rationale
The paper presents a training-free token compression method for Video-LLMs and reports direct empirical measurements of TTFT and FLOP reductions on specific hardware and models. No equations, fitted parameters, predictions derived from prior results, or self-citation chains appear in the abstract or described claims. The central results are framed as observed performance deltas from the proposed EarlyTom framework and decoupled spatial selection, with no reduction of any 'derivation' to its own inputs by construction. This is the standard case of an applied systems paper whose claims rest on experimental validation rather than internal mathematical equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Token merging: Your vit but faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster. InICLR, 2023. 2
2023
-
[3]
Junjie Chen, Xuyang Liu, Zichen Wen, Yiyu Wang, Siteng Huang, and Honggang Chen. Variation-aware vision to- ken dropping for faster large vision-language models.arXiv preprint arXiv:2509.01552, 2025. 3
-
[4]
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InECCV, 2024. 2, 6
2024
-
[5]
Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InCVPR,
-
[6]
Vision transformers need registers
Timoth ´ee Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers. InICLR,
-
[7]
Which Heads Matter for Reasoning? RL-Guided KV Cache Compression
Wenjie Du, Li Jiang, Keda Tao, Xue Liu, and Huan Wang. Which heads matter for reasoning? rl-guided kv cache com- pression.arXiv preprint arXiv:2510.08525, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Efficient reasoning models: A survey.Transactions on Machine Learning Research, 2025
Sicheng Feng, Gongfan Fang, Xinyin Ma, and Xinchao Wang. Efficient reasoning models: A survey.Transactions on Machine Learning Research, 2025. 3
2025
-
[9]
Edit: Enhancing vi- sion transformers by mitigating attention sink through an encoder-decoder architecture
Wenfeng Feng and Guoying Sun. Edit: Enhancing vi- sion transformers by mitigating attention sink through an encoder-decoder architecture. InOCSA, 2026. 4
2026
-
[10]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InCVPR, 2025. 6
2025
-
[11]
When attention sink emerges in language models: An empirical view
Xiangming Gu, Tianyu Pang, Chao Du, Qian Liu, Fengzhuo Zhang, Cunxiao Du, Ye Wang, and Min Lin. When attention sink emerges in language models: An empirical view. In ICLR, 2025. 4
2025
-
[12]
Knn model-based approach in classification
Gongde Guo, Hui Wang, David Bell, Yaxin Bi, and Kieran Greer. Knn model-based approach in classification. InOTM,
-
[13]
Filter, correlate, compress: Training-free token reduction for mllm acceleration
Yuhang Han, Xuyang Liu, Zihan Zhang, Pengxiang Ding, Junjie Chen, Honggang Chen, Donglin Wang, Qingsen Yan, and Siteng Huang. Filter, correlate, compress: Training-free token reduction for mllm acceleration. InAAAI, 2026. 2
2026
-
[14]
Prunevid: Visual token pruning for efficient video large language models
Xiaohu Huang, Hao Zhou, and Kai Han. Prunevid: Visual token pruning for efficient video large language models. In ACL, 2025. 6, 7
2025
-
[15]
Xin Jin, Siyuan Li, Siyong Jian, Kai Yu, and Huan Wang. Mergemix: A unified augmentation paradigm for visual and multi-modal understanding.arXiv preprint arXiv:2510.23479, 2025. 2
-
[16]
See what you are told: Visual attention sink in large multimodal models
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. See what you are told: Visual attention sink in large multimodal models. InICLR, 2025. 4
2025
-
[17]
Zicheng Kong, Dehua Ma, Zhenbo Xu, Alven Yang, Yi- wei Ru, Haoran Wang, Zixuan Zhou, Fuqing Bie, Liuyu Xi- ang, Huijia Wu, et al. Omni-rrm: Advancing omni reward modeling via automatic rubric-grounded preference synthe- sis.arXiv preprint arXiv:2602.00846, 2026. 3
-
[18]
Lmms-eval: Accelerating the development of large multimoal models, 2024
Bo Li, Peiyuan Zhang, Kaichen Zhang, Fanyi Pu, Xinrun Du, Yuhao Dong, Haotian Liu, Yuanhan Zhang, Ge Zhang, Chunyuan Li, and Ziwei Liu. Lmms-eval: Accelerating the development of large multimoal models, 2024. 6
2024
-
[19]
Llava-onevision: Easy visual task transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. TMLR, 2025. 1, 6
2025
-
[20]
Mvbench: A comprehensive multi-modal video understand- ing benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understand- ing benchmark. InCVPR, 2024. 6
2024
-
[21]
Videochat: Chat-centric video understanding.Science China Information Sciences, page 200102, 2025
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding.Science China Information Sciences, page 200102, 2025. 1
2025
-
[22]
Li, Sachin Goyal, Jo ˜ao Dias Semedo, and J
Kevin Y . Li, Sachin Goyal, Jo ˜ao Dias Semedo, and J. Zico Kolter. Inference optimal vlms need fewer visual tokens and more parameters. InInternational Conference on Learning Representations, 2024. 3
2024
-
[23]
Tokenpacker: Efficient visual projector for multimodal llm.IJCV, pages 1–19, 2025
Wentong Li, Yuqian Yuan, Jian Liu, Dongqi Tang, Song Wang, Jie Qin, Jianke Zhu, and Lei Zhang. Tokenpacker: Efficient visual projector for multimodal llm.IJCV, pages 1–19, 2025. 2
2025
-
[24]
Llama-vid: An image is worth 2 tokens in large language models
Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An image is worth 2 tokens in large language models. InECCV,
-
[25]
Ting Liu, Liangtao Shi, Richang Hong, Yue Hu, Quanjun Yin, and Linfeng Zhang. Multi-stage vision token dropping: Towards efficient multimodal large language model.arXiv preprint arXiv:2411.10803, 2024. 2
-
[26]
Xuyang Liu, Xiyan Gui, Yuchao Zhang, and Linfeng Zhang. Mixing importance with diversity: Joint optimization for kv cache compression in large vision-language models.arXiv preprint arXiv:2510.20707, 2025. 3 9
-
[27]
Video compression commander: Plug-and-play inference ac- celeration for video large language models
Xuyang Liu, Yiyu Wang, Junpeng Ma, and Linfeng Zhang. Video compression commander: Plug-and-play inference ac- celeration for video large language models. InEMNLP, 2025
2025
-
[28]
Global compression commander: Plug- and-play inference acceleration for high-resolution large vision-language models
Xuyang Liu, Ziming Wang, Junjie Chen, Yuhang Han, Yingyao Wang, Jiale Yuan, Jun Song, Siteng Huang, and Honggang Chen. Global compression commander: Plug- and-play inference acceleration for high-resolution large vision-language models. InAAAI, 2026. 3
2026
-
[29]
Video-chatgpt: Towards detailed video un- derstanding via large vision and language models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. Video-chatgpt: Towards detailed video un- derstanding via large vision and language models. InPro- ceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12585–12602, 2024. 1
2024
-
[30]
Egoschema: A diagnostic benchmark for very long- form video language understanding
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long- form video language understanding. InNeurIPS, 2023. 6
2023
-
[31]
Llava-prumerge: Adaptive token reduction for efficient large multimodal models
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. Llava-prumerge: Adaptive token reduction for efficient large multimodal models. InICCV, 2025. 2
2025
-
[32]
Holitom: Holistic token merging for fast video large language models
Kele Shao, Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. Holitom: Holistic token merging for fast video large language models. InNeurIPS, 2025. 2, 5, 6, 7
2025
-
[33]
Kele Shao, Keda Tao, Kejia Zhang, Sicheng Feng, Mu Cai, Yuzhang Shang, Haoxuan You, Can Qin, Yang Sui, and Huan Wang. When tokens talk too much: A survey of multimodal long-context token compression across images, videos, and audios.arXiv preprint arXiv:2507.20198, 2025. 2
-
[34]
Fastvid: Dynamic density prun- ing for fast video large language models
Leqi Shen, Guoqiang Gong, Tao He, Yifeng Zhang, Sicheng Zhao, Guiguang Ding, et al. Fastvid: Dynamic density prun- ing for fast video large language models. InNeurIPS, 2025. 2, 5, 6, 7
2025
-
[35]
Dycoke: Dynamic compression of tokens for fast video large language models
Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. Dycoke: Dynamic compression of tokens for fast video large language models. InCVPR, 2025. 2, 6
2025
-
[36]
Accelerating transformers with spectrum-preserving token merging
Chau Tran, Duy MH Nguyen, Manh-Duy Nguyen, TrungTin Nguyen, Ngan Le, Pengtao Xie, Daniel Sonntag, James Y Zou, Binh Nguyen, and Mathias Niepert. Accelerating transformers with spectrum-preserving token merging. In NeurIPS, 2024. 2
2024
-
[37]
Longvideobench: A benchmark for long-context interleaved video-language understanding
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long-context interleaved video-language understanding. InNeurIPS, 2024. 6
2024
-
[38]
VILA-U: a Unified Foundation Model Integrating Visual Understanding and Generation
Yecheng Wu, Zhuoyang Zhang, Junyu Chen, Haotian Tang, Dacheng Li, Yunhao Fang, Ligeng Zhu, Enze Xie, Hongxu Yin, Li Yi, et al. Vila-u: a unified foundation model inte- grating visual understanding and generation.arXiv preprint arXiv:2409.04429, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InICLR, 2025. 4
2025
-
[40]
Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy re- duction
Long Xing, Qidong Huang, Xiaoyi Dong, Jiajie Lu, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang, Feng Wu, et al. Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy re- duction. InCVPR, 2025. 2, 6, 7
2025
-
[41]
arXiv preprint arXiv:2508.13305 (2025) 1, 2, 4, 10
Minhao Xiong, Zichen Wen, Zhuangcheng Gu, Xuyang Liu, Rui Zhang, Hengrui Kang, Jiabing Yang, Junyuan Zhang, Weijia Li, Conghui He, et al. Prune2drive: A plug-and- play framework for accelerating vision-language models in autonomous driving.arXiv:2508.13305, 2025. 3
-
[42]
Pvc: Progressive visual token compression for unified image and video processing in large vision-language models
Chenyu Yang, Xuan Dong, Xizhou Zhu, Weijie Su, Jiahao Wang, Hao Tian, Zhe Chen, Wenhai Wang, Lewei Lu, and Jifeng Dai. Pvc: Progressive visual token compression for unified image and video processing in large vision-language models. InCVPR, 2025. 2
2025
-
[43]
Visionzip: Longer is better but not necessary in vision language models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. Visionzip: Longer is better but not necessary in vision language models. In CVPR, 2025. 2, 6, 7, 8
2025
-
[44]
Cambrian-S: Towards Spatial Supersensing in Video
Shusheng Yang, Jihan Yang, Pinzhi Huang, Ellis Brown, Zi- hao Yang, Yue Yu, Shengbang Tong, Zihan Zheng, Yifan Xu, Muhan Wang, et al. Cambrian-s: Towards spatial supersens- ing in video.arXiv preprint arXiv:2511.04670, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InICCV, 2023. 4, 6
2023
-
[46]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, et al. Videollama 3: Frontier multi- modal foundation models for image and video understand- ing.arXiv preprint arXiv:2501.13106, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Vs- can: Rethinking visual token reduction for efficient large vision-language models.TMLR, 2025
Ce Zhang, Kaixin Ma, Tianqing Fang, Wenhao Yu, Hong- ming Zhang, Zhisong Zhang, Haitao Mi, and Dong Yu. Vs- can: Rethinking visual token reduction for efficient large vision-language models.TMLR, 2025. 2
2025
-
[48]
LMMs-Eval: Reality Check on the Evaluation of Large Multimodal Models
Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, and Ziwei Liu. Lmms- eval: Reality check on the evaluation of large multimodal models.arXiv preprint arXiv:2407.12772, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Zi- wei Liu, and Chunyuan Li. Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Sparsevlm: Vi- sual token sparsification for efficient vision-language model inference
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis A Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, et al. Sparsevlm: Vi- sual token sparsification for efficient vision-language model inference. InICML, 2025. 2
2025
-
[51]
Accelerating multimodal large language models by searching optimal vision token re- duction
Shiyu Zhao, Zhenting Wang, Felix Juefei-Xu, Xide Xia, Miao Liu, Xiaofang Wang, Mingfu Liang, Ning Zhang, Dim- itris N Metaxas, and Licheng Yu. Accelerating multimodal large language models by searching optimal vision token re- duction. InCVPR, 2025. 4
2025
-
[52]
Obs-diff: Accurate pruning for diffusion mod- els in one-shot.arXiv preprint arXiv:2510.06751, 2025
Junhan Zhu, Hesong Wang, Mingluo Su, Zefang Wang, and Huan Wang. Obs-diff: Accurate pruning for diffusion mod- els in one-shot.arXiv preprint arXiv:2510.06751, 2025. 3
-
[53]
St3: Accelerating multimodal large lan- guage model by spatial-temporal visual token trimming
Jiedong Zhuang, Lu Lu, Ming Dai, Rui Hu, Jian Chen, Qiang Liu, and Haoji Hu. St3: Accelerating multimodal large lan- guage model by spatial-temporal visual token trimming. In AAAI, 2025. 4
2025
-
[54]
Softpick: No Attention Sink, No Massive Activations with Rectified Softmax
Zayd MK Zuhri, Erland Hilman Fuadi, and Alham Fikri Aji. Softpick: No attention sink, no massive activations with rec- tified softmax.arXiv preprint arXiv:2504.20966, 2025. 4 10 EarlyTom : Early Token Compression Completes Fast Video Understanding Supplementary Material Overview Due to page limitations in the main paper, we present additional quantitative...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.