DocRetriever: A Plug-and-Play Framework for Multimodal Document Retrieval with Comprehensive Benchmark
Pith reviewed 2026-06-29 08:07 UTC · model grok-4.3
The pith
DocRetriever improves multimodal document retrieval with layout-aware sparse embeddings for hybrid encoding without OCR and a generalizable few-shot reranker.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
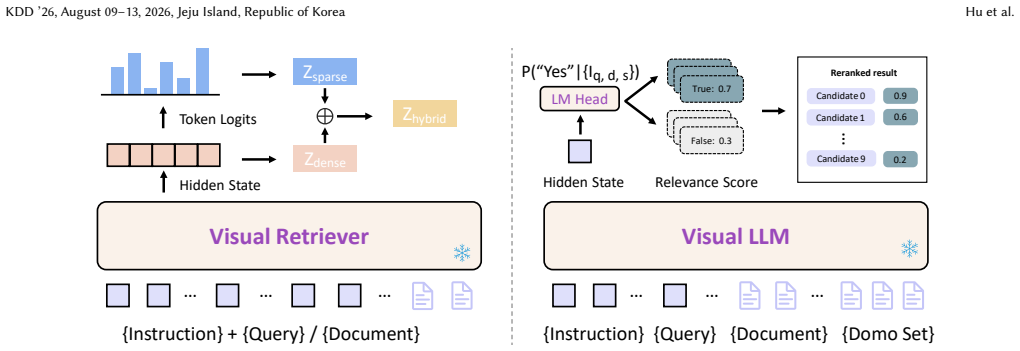
DocRetriever is a plug-and-play framework that enhances visual retrieval via a layout-aware sparse embedding technique, enabling effective hybrid encoding without the overhead of optical character recognition (OCR). We also introduce a generalizable reranker that leverages reasoning-augmented demonstrations and optimized sampling to improve accuracy in few-shot settings. Finally, we construct a new benchmark, MultiDocR, to enable more rigorous evaluation. Experiments across diverse benchmarks validate DocRetriever's superiority over state-of-the-art methods.
What carries the argument
layout-aware sparse embedding technique enabling hybrid encoding without OCR, and generalizable reranker using reasoning-augmented demonstrations and optimized sampling
Load-bearing premise
That the layout-aware sparse embeddings can capture structurally salient information effectively without using OCR, and that the proposed reranker will generalize across domains when using reasoning-augmented demonstrations in few-shot settings.
What would settle it
If experiments on the MultiDocR benchmark show that standard dense embeddings plus a supervised reranker achieve equal or higher retrieval accuracy than DocRetriever, or if the sparse component adds no benefit when ablated.
Figures

read the original abstract
Multimodal documents contain diverse elements, such as tables, figures, and layouts, which can complicate retrieval tasks. While current approaches typically combine dense visual embedding models with supervised rerankers to achieve high-precision retrieval, they face inherent limitations. First, the coarse-grained nature of dense embeddings tends to obfuscate explicit semantics, failing to leverage structurally salient information. Second, supervised reranking models suffer from generalization bottlenecks, as their performance heavily relies on domain-specific training data. Furthermore, existing benchmarks often lack diverse assessment dimensions and comprehensive relevance annotations, limiting reliable evaluation. To address these challenges, we propose DocRetriever, a plug-and-play framework. It enhances visual retrieval via a layout-aware sparse embedding technique, enabling effective hybrid encoding without the overhead of optical character recognition (OCR). We also introduce a generalizable reranker that leverages reasoning-augmented demonstrations and optimized sampling to improve accuracy in few-shot settings. Finally, we construct a new benchmark, MultiDocR, to enable more rigorous evaluation. Experiments across diverse benchmarks validate DocRetriever's superiority over state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DocRetriever, a plug-and-play framework for multimodal document retrieval. It proposes a layout-aware sparse embedding technique to enable effective hybrid encoding without OCR, a generalizable reranker that uses reasoning-augmented demonstrations and optimized sampling for few-shot settings, and a new benchmark MultiDocR with comprehensive relevance annotations. The central claim is that these components yield superior retrieval performance over state-of-the-art dense-embedding-plus-supervised-reranker pipelines across diverse benchmarks.
Significance. If the claims hold with detailed, reproducible evidence, the work would address two practical bottlenecks in document retrieval (coarse dense embeddings that miss layout structure and domain-specific supervised rerankers) while supplying a new evaluation resource. The plug-and-play framing and avoidance of OCR are practically attractive strengths.
major comments (3)
- [§3] §3 (Method), layout-aware sparse embedding subsection: the claim that the technique 'captures structurally salient information' (tables, figures, layout) without OCR is load-bearing for the hybrid-encoding superiority argument, yet the manuscript supplies no description of the sparse feature extraction process, the layout encoding mechanism, or any ablation that isolates the layout component from a standard sparse baseline.
- [§3.2] §3.2 (Reranker), few-shot generalization paragraph: the assertion that reasoning-augmented demonstrations plus optimized sampling produce cross-domain generalization rests on unshown implementation details (exact sampling procedure, how reasoning is injected into demonstrations, and any cross-domain transfer results). Without these, the comparison to supervised rerankers cannot be assessed.
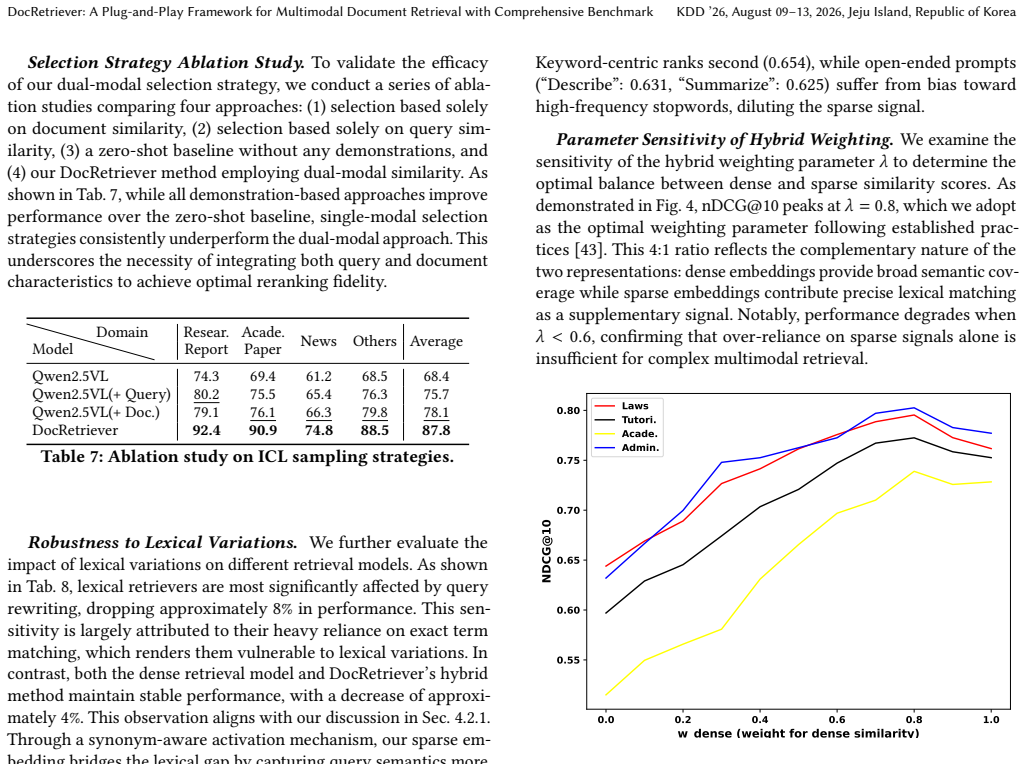
- [§4] §4 (Experiments), main results table: the superiority claim is stated but the provided text contains no quantitative numbers, error bars, statistical tests, or ablation tables that would allow verification that the gains are attributable to the proposed components rather than implementation choices.
minor comments (2)
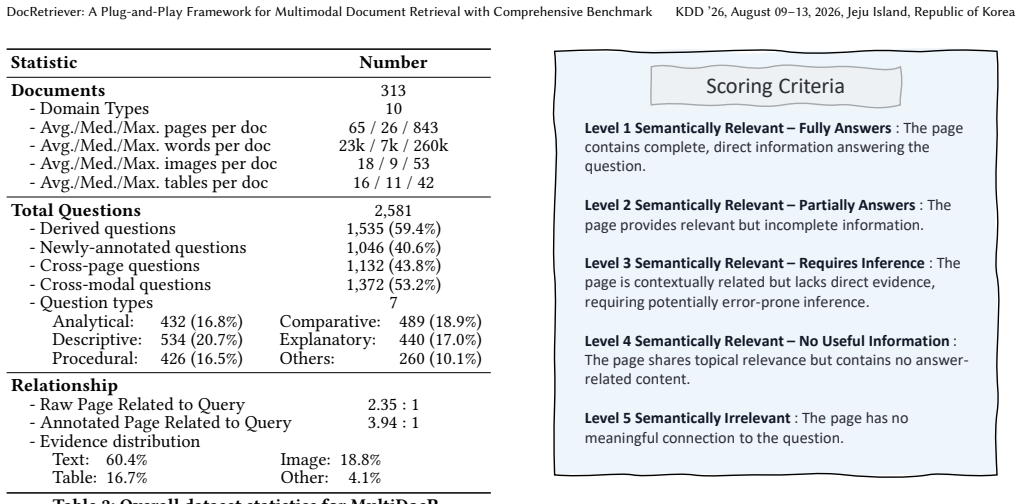
- [Abstract / §2] The abstract and introduction refer to 'diverse benchmarks' and 'MultiDocR' without listing the exact datasets or annotation protocol in the opening sections; moving a concise table of benchmark statistics to §2 would improve readability.
- [§3.1] Notation for the sparse embedding (e.g., how layout tokens are represented) is introduced without an explicit equation or diagram; adding a small schematic in §3.1 would clarify the hybrid encoding pipeline.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will incorporate clarifications and additional results into the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method), layout-aware sparse embedding subsection: the claim that the technique 'captures structurally salient information' (tables, figures, layout) without OCR is load-bearing for the hybrid-encoding superiority argument, yet the manuscript supplies no description of the sparse feature extraction process, the layout encoding mechanism, or any ablation that isolates the layout component from a standard sparse baseline.
Authors: We agree the description of the sparse feature extraction process and layout encoding mechanism requires expansion. The revised §3 will detail the extraction steps, how layout information is encoded without OCR, and include an ablation isolating the layout component versus a standard sparse baseline. revision: yes
-
Referee: [§3.2] §3.2 (Reranker), few-shot generalization paragraph: the assertion that reasoning-augmented demonstrations plus optimized sampling produce cross-domain generalization rests on unshown implementation details (exact sampling procedure, how reasoning is injected into demonstrations, and any cross-domain transfer results). Without these, the comparison to supervised rerankers cannot be assessed.
Authors: We will expand §3.2 with the exact sampling procedure, the method for injecting reasoning into demonstrations, and cross-domain transfer results to substantiate the generalization claims. revision: yes
-
Referee: [§4] §4 (Experiments), main results table: the superiority claim is stated but the provided text contains no quantitative numbers, error bars, statistical tests, or ablation tables that would allow verification that the gains are attributable to the proposed components rather than implementation choices.
Authors: The manuscript tables contain quantitative results, but we acknowledge the absence of error bars, statistical tests, and expanded ablations. The revision will add these to allow verification of component contributions. revision: yes
Circularity Check
No circularity: new methods and benchmark presented without reduction to inputs or self-citations
full rationale
The paper proposes DocRetriever as a new plug-and-play framework with layout-aware sparse embeddings for hybrid encoding, a reasoning-augmented reranker for few-shot settings, and a new MultiDocR benchmark. None of the enumerated circularity patterns appear in the abstract or described claims. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or imported uniqueness theorems are referenced. The derivation chain consists of identifying limitations in prior dense+supervised approaches and asserting novel components to address them, which remains self-contained against external benchmarks rather than reducing by construction to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
IJsbrand Jan Aalbersberg. 1994. A document retrieval model based on term frequency ranks. InSIGIR’94: Proceedings of the Seventeenth Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval, organised by Dublin City University. Springer, 163–172
1994
-
[2]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauff- mann, et al. 2024. Phi-4 technical report.arXiv preprint arXiv:2412.08905(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al . 2025. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Roelien Bastiaanse, Martijn Wieling, and Nienke Wolthuis. 2016. The role of frequency in the retrieval of nouns and verbs in aphasia.Aphasiology30, 11 (2016), 1221–1239
2016
-
[6]
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschan- nen, Emanuele Bugliarello, et al. 2024. Paligemma: A versatile 3b vlm for transfer. arXiv preprint arXiv:2407.07726(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Antoine Chaffin and Aurélien Lac. 2024. MonoQwen: Visual Document Reranking. https://huggingface.co/lightonai/MonoQwen2-VL-v0.1
2024
- [8]
- [9]
-
[10]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation.arXiv preprint arXiv:2402.03216 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Xize Cheng, Ruofan Hu, Xiaoda Yang, Jingyu Lu, Dongjie Fu, Shengpeng Ji, Rongjie Huang, Boyang Zhang, Tao Jin, Zhou Zhao, et al. 2025. Voxdialogue: Can spoken dialogue systems understand information beyond words?. InInternational Conference on Learning Representations, Vol. 2025. 288–303
2025
-
[12]
Yew Ken Chia, Liying Cheng, Hou Pong Chan, Chaoqun Liu, Maojia Song, Shar- ifah Mahani Aljunied, Soujanya Poria, and Lidong Bing. 2024. M-longdoc: A benchmark for multimodal super-long document understanding and a retrieval- aware tuning framework.arXiv preprint arXiv:2411.06176(2024)
-
[13]
Jaemin Cho, Debanjan Mahata, Ozan Irsoy, Yujie He, and Mohit Bansal. 2025. M3DocVQA: Multi-modal Multi-page Multi-document Understanding. InPro- ceedings of the IEEE/CVF International Conference on Computer Vision. 6178–6188
2025
-
[14]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
2019
- [16]
- [17]
- [18]
-
[19]
Minghui Fang, Shengpeng Ji, Jialong Zuo, Xize Cheng, Wenrui Liu, Xiaoda Yang, Ruofan Hu, Jieming Zhu, and Zhou Zhao. 2025. GTA: Towards generative text- to-audio retrieval via multi-scale tokenizer. InProc. Interspeech. 2650–2654
2025
-
[20]
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, and Pierre Colombo. 2024. Colpali: Efficient document retrieval with vision language models. InThe Thirteenth International Conference on Learning Representations
2024
-
[21]
Thibault Formal, Benjamin Piwowarski, and Stéphane Clinchant. 2021. SPLADE: Sparse lexical and expansion model for first stage ranking. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2288–2292
2021
-
[22]
Michael Günther, Saba Sturua, Mohammad Kalim Akram, Isabelle Mohr, Andrei Ungureanu, Sedigheh Eslami, Scott Martens, Bo Wang, Nan Wang, and Han Xiao
- [23]
- [24]
- [25]
- [26]
-
[27]
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bo- janowski, Armand Joulin, and Edouard Grave. 2021. Unsupervised dense in- formation retrieval with contrastive learning.arXiv preprint arXiv:2112.09118 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[28]
Ziyan Jiang, Rui Meng, Xinyi Yang, Semih Yavuz, Yingbo Zhou, and Wenhu Chen. 2024. Vlm2vec: Training vision-language models for massive multimodal embedding tasks.arXiv preprint arXiv:2410.05160(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick SH Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open-Domain Question Answering.. InEMNLP (1). 6769–6781
2020
- [30]
-
[31]
Michael E Lesk. 1969. Word-word associations in document retrieval systems. American documentation20, 1 (1969), 27–38
1969
- [32]
- [33]
-
[34]
Yifan Li, Yikai Wang, Yanwei Fu, Dongyu Ru, Zheng Zhang, and Tong He. 2024. Unified lexical representation for interpretable visual-language alignment.Ad- vances in Neural Information Processing Systems37 (2024), 1141–1161
2024
-
[35]
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. 2023. Towards general text embeddings with multi-stage contrastive learning.arXiv preprint arXiv:2308.03281(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [36]
-
[37]
Qi Liu, Haozhe Duan, Yiqun Chen, Quanfeng Lu, Weiwei Sun, and Jiaxin Mao
- [38]
-
[39]
Edward Loper and Steven Bird. 2002. Nltk: The natural language toolkit.arXiv preprint cs/0205028(2002)
work page internal anchor Pith review Pith/arXiv arXiv 2002
- [40]
-
[43]
Xueguang Ma, Sheng-Chieh Lin, Minghan Li, Wenhu Chen, and Jimmy Lin
-
[44]
Unifying Multimodal Retrieval via Document Screenshot Embedding. arXiv:2406.11251(2024)
- [45]
- [46]
- [47]
-
[48]
Minesh Mathew, Viraj Bagal, Rubèn Tito, Dimosthenis Karatzas, Ernest Valveny, and CV Jawahar. 2022. Infographicvqa. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 1697–1706
2022
-
[49]
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. 2021. Docvqa: A dataset for vqa on document images. InProceedings of the IEEE/CVF winter conference on applications of computer vision. 2200–2209
2021
- [50]
- [51]
-
[52]
Joël Plisson, Nada Lavrac, Dunja Mladenic, et al. 2004. A rule based approach to word lemmatization. InProceedings of IS, Vol. 3. sn, 83–86
2004
-
[53]
Juan Ramos et al. 2003. Using tf-idf to determine word relevance in document queries. InProceedings of the first instructional conference on machine learning, Vol. 242. New Jersey, USA, 29–48. DocRetriever: A Plug-and-Play Framework for Multimodal Document Retrieval with Comprehensive Benchmark KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea
2003
-
[54]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks.arXiv preprint arXiv:1908.10084(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[55]
Stephen Robertson, Hugo Zaragoza, et al . 2009. The probabilistic relevance framework: BM25 and beyond.Foundations and Trends®in Information Retrieval 3, 4 (2009), 333–389
2009
-
[56]
Ryota Tanaka, Kyosuke Nishida, Kosuke Nishida, Taku Hasegawa, Itsumi Saito, and Kuniko Saito. 2023. Slidevqa: A dataset for document visual question an- swering on multiple images. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 13636–13645
2023
- [57]
- [58]
-
[59]
Naftali Tishby, Fernando C Pereira, and William Bialek. 2000. The information bottleneck method.arXiv preprint physics/0004057(2000)
work page internal anchor Pith review Pith/arXiv arXiv 2000
-
[60]
Rubèn Tito, Dimosthenis Karatzas, and Ernest Valveny. 2023. Hierarchical multi- modal transformers for multipage docvqa.Pattern Recognition144 (2023), 109834
2023
-
[61]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
Jordy Van Landeghem, Rubèn Tito, Łukasz Borchmann, Michał Pietruszka, Pawel Joziak, Rafal Powalski, Dawid Jurkiewicz, Mickaël Coustaty, Bertrand Anckaert, Ernest Valveny, et al. 2023. Document understanding dataset and evaluation (dude). InProceedings of the IEEE/CVF International Conference on Computer Vision. 19528–19540
2023
-
[63]
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. 2022. Text embeddings by weakly-supervised contrastive pre-training.arXiv preprint arXiv:2212.03533(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[64]
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2024. Multilingual e5 text embeddings: A technical report.arXiv preprint arXiv:2402.05672(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Lingpeng Kong, Qi Liu, Tianyu Liu, et al. 2024. Large language models are not fair evaluators. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 9440–9450
2024
-
[66]
Yining Wang, Liwei Wang, Yuanzhi Li, Di He, and Tie-Yan Liu. 2013. A theoretical analysis of NDCG type ranking measures. InConference on learning theory. PMLR, 25–54
2013
- [67]
-
[68]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [69]
-
[70]
Xiaoda Yang, Xize Cheng, Minghui Fang, Hongshun Qiu, Yuhang Ma, JunYu Lu, Jiaqi Duan, Sihang Cai, Zehan Wang, Ruofan Hu, et al . 2025. Multimodal conditional retrieval with high controllability. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 3577–3585
2025
-
[71]
Shi Yu, Chaoyue Tang, Bokai Xu, Junbo Cui, Junhao Ran, Yukun Yan, Zheng- hao Liu, Shuo Wang, Xu Han, Zhiyuan Liu, et al . 2024. Visrag: Vision-based retrieval-augmented generation on multi-modality documents.arXiv preprint arXiv:2410.10594(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [72]
-
[73]
Xin Zhang, Yanzhao Zhang, Dingkun Long, Wen Xie, Ziqi Dai, Jialong Tang, Huan Lin, Baosong Yang, Pengjun Xie, Fei Huang, et al. 2024. mGTE: Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track. 1393–1412
2024
-
[74]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. 2025. Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.arXiv preprint arXiv:2506.05176(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [75]
- [76]
-
[77]
Fengbin Zhu, Wenqiang Lei, Fuli Feng, Chao Wang, Haozhou Zhang, and Tat-Seng Chua. 2022. Towards complex document understanding by discrete reasoning. In Proceedings of the 30th ACM International Conference on Multimedia. 4857–4866
2022
-
[78]
Shengyao Zhuang, Xueguang Ma, Bevan Koopman, Jimmy Lin, and Guido Zuccon
- [79]
-
[80]
WANG Zhuohao, WANG Dong, and LI Qing. 2021. Keyword extraction from scientific research projects based on SRP-TF-IDF.Chinese Journal of Electronics 30, 4 (2021), 652–657
2021
-
[81]
Anni Zou, Wenhao Yu, Hongming Zhang, Kaixin Ma, Deng Cai, Zhuosheng Zhang, Hai Zhao, and Dong Yu. 2024. Docbench: A benchmark for evaluating llm-based document reading systems.arXiv preprint arXiv:2407.10701(2024). A Reinforced ICL Details Hyperparameter Configuration Temperature0.2 Top-𝑝0.95 Confidence Threshold>0.8 Max Examples (𝑘)4(2 positive, 2 negati...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.