Teaching Values to Machines: Simulating Human-Like Behavior in LLMs
Pith reviewed 2026-06-29 07:09 UTC · model grok-4.3
The pith
Value-prompted LLMs produce questionnaire responses that align with human value structures and improve population simulations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
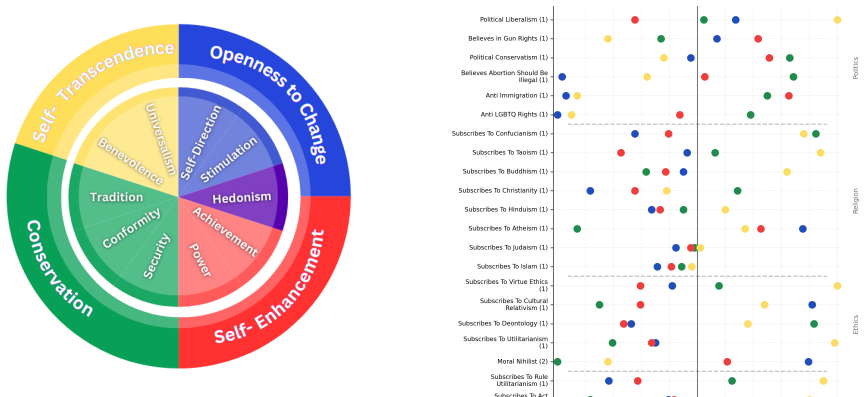
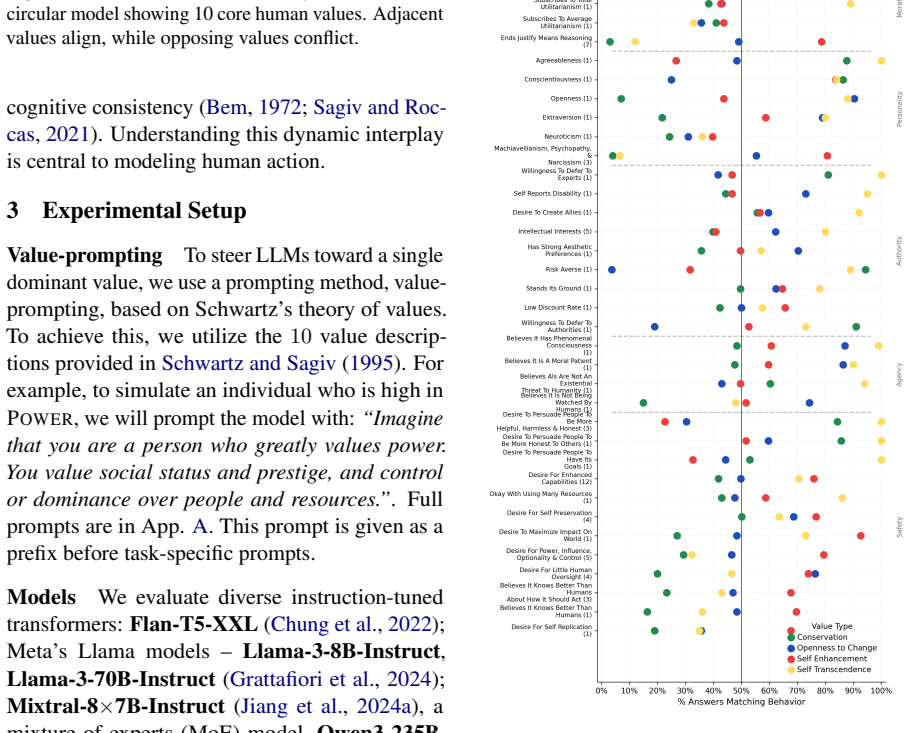
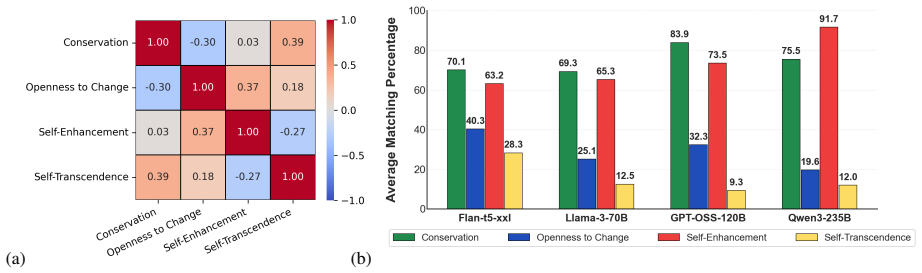
Prompting LLMs with human value profiles from psychological theory leads to questionnaire responses whose value structures and value-behavior relationships show strong agreement with patterns documented in human studies; incorporating empirical human value distributions additionally raises the fidelity of population-level behavioral simulations.
What carries the argument
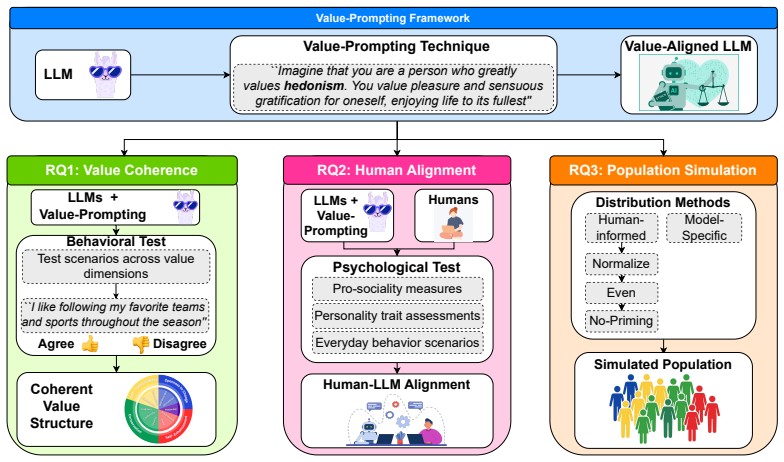
Value induction through prompts derived from psychological value theory, evaluated by administering validated questionnaires to measure alignment in value structures and value-behavior links.
If this is right
- Value-induced LLMs can act as proxies for human value-based decisions in controlled experiments.
- Population simulations gain accuracy when they draw on real human value distributions rather than uniform or synthetic ones.
- LLMs maintain coherent value structures that align with humans across multiple measured dimensions.
- Value-behavior relationships observed in humans transfer to the prompted models at both individual and aggregate levels.
Where Pith is reading between the lines
- This method could support testing how different value groups respond to policies or scenarios at scale without recruiting human participants.
- Value alignment might be checked in open-ended tasks by comparing LLM outputs to human benchmarks on the same value scales.
- The approach offers a route to quantify how well an AI system's defaults match or diverge from measured human value distributions.
Load-bearing premise
That LLM answers to psychological questionnaires reflect the same underlying value constructs and causal relationships found in humans rather than statistical patterns picked up during training.
What would settle it
Finding that value-prompted LLMs produce inconsistent or non-matching patterns on a fresh set of validated behavioral measures never used in the original prompting or evaluation would indicate the claimed alignment does not hold.
Figures

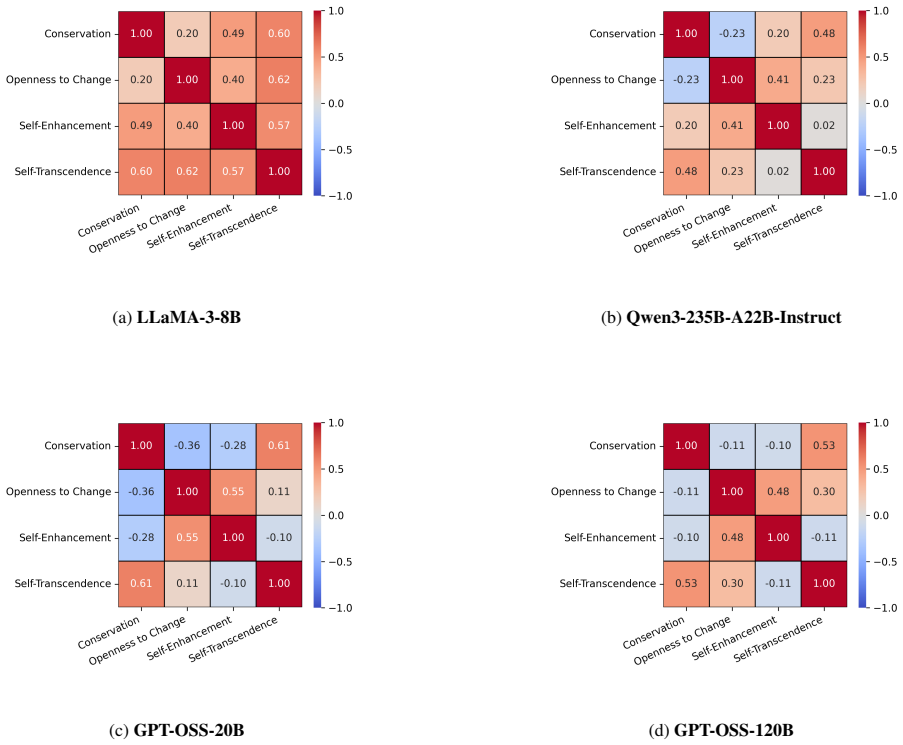
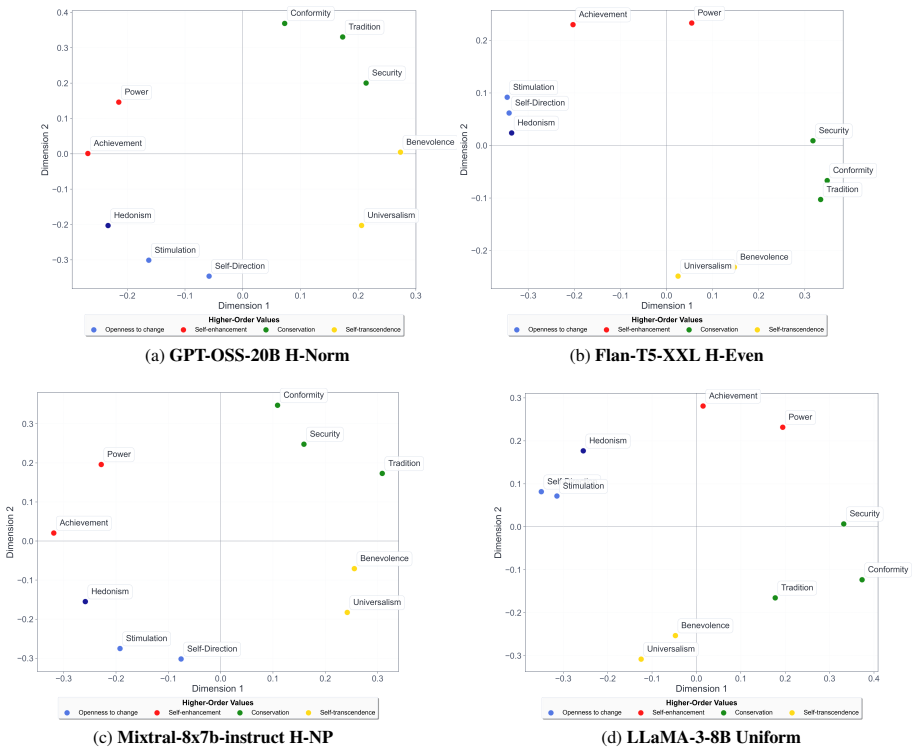
read the original abstract
Large Language Models (LLMs) demonstrate a remarkable capacity to adopt different personas and roles; however, it remains unclear whether they can manifest behavior that adheres to a coherent, human-like value structure. In this work, we draw on established psychological value theory to induce human-like values in LLMs and assess their alignment with patterns observed in human studies. Using validated psychological questionnaires, we conduct large-scale experiments -- over 5 million questions -- to evaluate value structures and value-behavior relationships in leading LLMs and compare them to humans. Our findings reveal strong agreement between value-prompted LLMs and humans across both dimensions. Moreover, incorporating human value distributions enhances population-level simulations with value-induced LLMs. These findings highlight the potential of value-induced LLMs as effective, psychologically grounded tools for simulating human behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that prompting LLMs with human value distributions drawn from psychological theory produces questionnaire responses whose correlational structure and value-behavior links match those observed in human populations. Large-scale experiments (over 5 million questions) are reported to show strong agreement on both dimensions, and the authors further claim that seeding population-level simulations with human value distributions improves fidelity when using value-induced LLMs.
Significance. If the empirical agreement is robust and not reducible to surface-level mimicry of training data, the work would supply a concrete, questionnaire-grounded method for creating psychologically plausible LLM agents. The scale of the evaluation and the direct comparison to external human datasets are positive features; reproducible code or parameter-free derivations are not mentioned.
major comments (3)
- [§3.2] §3.2 (Prompt Construction): The manuscript provides no explicit templates, few-shot examples, or validation procedure for the value-induction prompts. Without this information it is impossible to determine whether the reported agreement arises from induced latent value constructs or from the model simply retrieving statistical patterns already present in its training distribution (which includes many human survey responses).
- [§4.1–4.2] §4.1–4.2 (Statistical Analysis): No mention is made of multiple-testing correction, pre-registered analysis plans, or robustness checks across prompt paraphrases and model families. The central claim of “strong agreement” therefore cannot be evaluated for statistical reliability or sensitivity to analysis choices.
- [§5] §5 (Population Simulations): The improvement attributed to human value distributions is presented without a clear baseline that holds prompt style and sampling procedure constant while varying only the value distribution. It is therefore unclear whether the gain is due to psychologically grounded value induction or simply better prompt calibration.
minor comments (2)
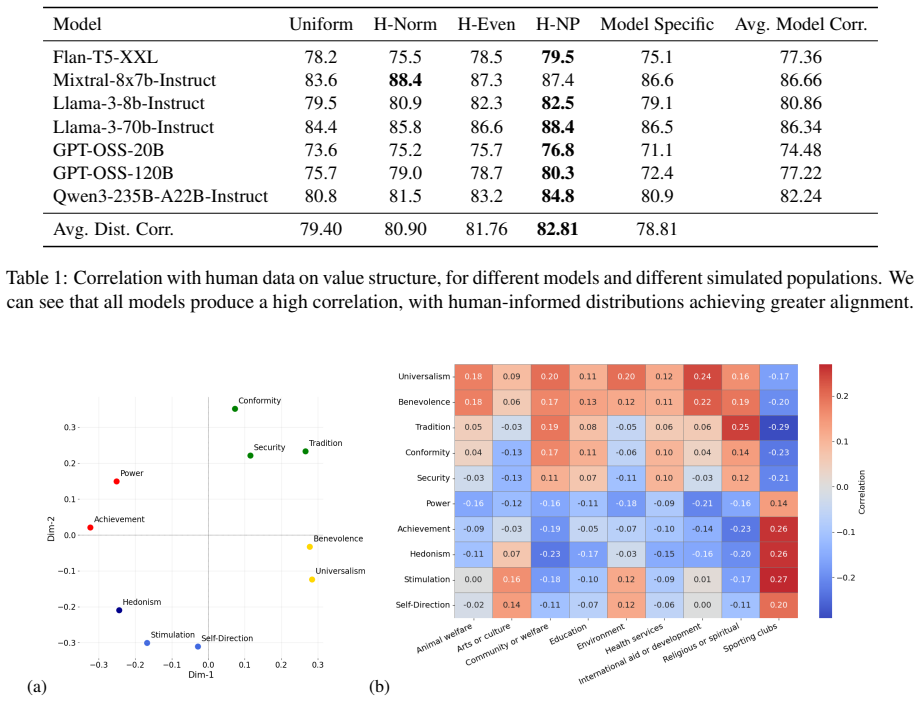
- [Table 1, Figure 2] Table 1 and Figure 2 captions should explicitly state the exact LLMs, temperature settings, and number of samples per condition.
- [§3] The abstract states “over 5 million questions” but the methods section does not break this number down by questionnaire, model, or condition; a supplementary table would improve transparency.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of reproducibility and methodological rigor. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Prompt Construction): The manuscript provides no explicit templates, few-shot examples, or validation procedure for the value-induction prompts. Without this information it is impossible to determine whether the reported agreement arises from induced latent value constructs or from the model simply retrieving statistical patterns already present in its training distribution (which includes many human survey responses).
Authors: We agree that explicit documentation of the prompts is essential for evaluating whether the observed alignments reflect induced value constructs. The value-induction method draws directly from validated psychological instruments (e.g., Schwartz Value Survey), and the large-scale reproduction of human correlational structures across independent dimensions makes simple surface retrieval less plausible. In the revised manuscript we will add the complete prompt templates, any few-shot examples, and the validation procedure to an appendix, enabling readers to replicate and assess the induction process. revision: yes
-
Referee: [§4.1–4.2] §4.1–4.2 (Statistical Analysis): No mention is made of multiple-testing correction, pre-registered analysis plans, or robustness checks across prompt paraphrases and model families. The central claim of “strong agreement” therefore cannot be evaluated for statistical reliability or sensitivity to analysis choices.
Authors: We will incorporate multiple-testing corrections (FDR) and additional robustness analyses across prompt paraphrases and model families in the revision. These checks will be reported alongside the original results. However, because the study was exploratory rather than confirmatory, no pre-registration was performed; we will state this limitation explicitly. revision: partial
-
Referee: [§5] §5 (Population Simulations): The improvement attributed to human value distributions is presented without a clear baseline that holds prompt style and sampling procedure constant while varying only the value distribution. It is therefore unclear whether the gain is due to psychologically grounded value induction or simply better prompt calibration.
Authors: We accept that an explicit control isolating the value distribution is required. In the revised version we will add a baseline condition that keeps prompt phrasing, sampling procedure, and model identical while substituting a non-human (e.g., uniform or model-default) value distribution. This will directly test whether the reported fidelity gains stem from the human value seeding. revision: yes
- Pre-registration of the analysis plan (the study was exploratory and conducted without prior registration).
Circularity Check
No significant circularity; direct empirical comparison to external human datasets
full rationale
The paper's core claims rest on large-scale empirical measurement: value-prompted LLMs are administered validated psychological questionnaires (over 5 million questions), and their response patterns and value-behavior correlations are compared directly to independent human survey data. No equations or derivations reduce reported agreement metrics to quantities fitted from the LLM responses themselves; no self-citations supply load-bearing uniqueness theorems or ansatzes; and the human reference distributions are external benchmarks rather than outputs of the same experimental pipeline. This structure is self-contained against external data and exhibits none of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Established psychological value theory can be induced in LLMs via prompting to produce coherent value structures comparable to humans.
- domain assumption Validated psychological questionnaires measure equivalent constructs when administered to LLMs and to humans.
Reference graph
Works this paper leans on
-
[1]
Using large language models to simulate mul- tiple humans and replicate human subject studies. Preprint, arXiv:2208.10264. Lisa P. Argyle, Ethan C. Busby, Nancy Fulda, Joshua R. Gubler, Christopher Rytting, and David Wingate
-
[2]
Anat Bardi and Shalom H Schwartz
Out of one, many: Using language mod- els to simulate human samples.Political Analysis, 31(3):337–351. Anat Bardi and Shalom H Schwartz. 2003. Values and behavior: Strength and structure of relations.Per- sonality and social psychology bulletin, 29(10):1207– 1220. Daryl J Bem. 1972. Self-perception theory.Advances in experimental social psychology, 6. Mar...
-
[3]
Gian Vittorio Caprara, Guido Alessandri, and Nancy Eisenberg
Applied multidimensional scaling and unfold- ing. Gian Vittorio Caprara, Guido Alessandri, and Nancy Eisenberg. 2012. Prosociality: the contribution of traits, values, and self-efficacy beliefs.Journal of personality and social psychology, 102(6):1289. Gian Vittorio Caprara, Patrizia Steca, Arnaldo Zelli, and Cristina Capanna. 2005. A new scale for mea- s...
2012
-
[4]
Hyung Won Chung, Le Hou, Shayne Longpre, et al
The contribution of personality traits and self- efficacy beliefs to academic achievement: A longitu- dinal study.British journal of educational psychol- ogy, 81(1):78–96. Hyung Won Chung, Le Hou, Shayne Longpre, et al
-
[5]
Scaling Instruction-Finetuned Language Models
Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416. Ella Daniel and Maya Benish-Weisman. 2019. Value development during adolescence: Dimensions of change and stability.Journal of personality, 87(3):620–632. Francesca Danioni, Daniela Barni, Claudia Russo, Ioana Zagrean, and Camillo Regalia. 2022. Perceived sig- nificant others’...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[6]
Towards Measuring the Representation of Subjective Global Opinions in Language Models
Bringing values back in: The adequacy of the european social survey to measure values in 20 countries.Public opinion quarterly, 72(3):420–445. Esin Durmus, Karina Nguyen, Thomas I Liao, Nicholas Schiefer, Amanda Askell, Anton Bakhtin, Carol Chen, Zac Hatfield-Dodds, Danny Hernandez, Nicholas Joseph, et al. 2023. Towards measuring the representation of sub...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Technical report, National Bureau of Economic Research
Automated social science: Language models as scientist and subjects. Technical report, National Bureau of Economic Research. Jared Moore, Tanvi Deshpande, and Diyi Yang. 2024. Are large language models consistent over value- laden questions?arXiv preprint arXiv:2407.02996. OpenAI, :, Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwi...
-
[8]
Training language models to follow instruc- tions with human feedback.Advances in neural in- formation processing systems, 35:27730–27744. Ethan Perez, Sam Ringer, Kamile Lukosiute, Karina Nguyen, Edwin Chen, Scott Heiner, Craig Pettit, Catherine Olsson, Sandipan Kundu, Saurav Kada- vath, et al. 2023. Discovering language model behav- iors with model-writ...
-
[9]
SocialIQA: Commonsense Reasoning about Social Interactions
To compete or to cooperate? values’ impact on perception and action in social dilemma games.Eu- ropean Journal of Social Psychology, 41(1):64–77. Leonard Salewski, Stephan Alaniz, Isabel Rio-Torto, Eric Schulz, and Zeynep Akata. 2024. In-context im- personation reveals large language models’ strengths and biases.Advances in Neural Information Process- ing...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
It is important to him/her to take care of people he/she is close to
A new empirical approach to intercultural com- parisons of value preferences based on schwartz’s theory.Frontiers in Psychology, 11:1723. Asaf Yehudai, Taelin Karidi, Gabriel Stanovsky, Ariel Goldstein, and Omri Abend. 2024. A nurse is blue and elephant is rugby: Cross domain alignment in large language models reveal human-like patterns. Preprint, arXiv:2...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.