Geometry Matters: 3D Foundation Priors for Learning Semantic Correspondence
Pith reviewed 2026-06-29 08:25 UTC · model grok-4.3
The pith
3D geometry estimates from SAM3D and geodesic filtering on reconstructed meshes supply reliable supervision that lets a lightweight adapter improve semantic correspondence on top of DINO and Stable Diffusion features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Given an image, SAM3D estimates object geometry and pose; render-and-compare optimization refines the pose; PartField descriptors are rendered into the image plane; geodesic distances on the mesh filter candidate correspondences; and the filtered matches supervise a lightweight adapter on DINO and Stable Diffusion features. This pipeline yields higher semantic correspondence accuracy than prior post-training methods while eliminating the need for pose annotations and coarse spherical geometry.
What carries the argument
The 3D-aware post-training framework that renders PartField descriptors from SAM3D-reconstructed meshes and uses geodesic distances to filter correspondences for adapter supervision.
If this is right
- Correspondence learning becomes robust to symmetry and repeated parts without explicit 3D annotations.
- Training no longer requires manual pose labels or spherical geometry assumptions.
- The same filtered matches can be reused to adapt other 2D foundation features beyond DINO and Stable Diffusion.
- Instance-specific 3D structure guides matching even when objects appear in novel viewpoints.
Where Pith is reading between the lines
- The same geometry-aware filtering step could be applied to other correspondence-heavy tasks such as optical flow or keypoint matching.
- If SAM3D improves over time, the adapter training signal strengthens automatically without changes to the rest of the pipeline.
- The approach may reduce the performance gap between 2D and full 3D correspondence methods on datasets with strong symmetries.
Load-bearing premise
SAM3D must produce geometry and pose estimates accurate enough for render-and-compare optimization and geodesic filtering to generate trustworthy supervision signals.
What would settle it
A controlled test in which SAM3D geometry estimates are deliberately degraded or replaced by random poses, after which the reported gains in semantic correspondence accuracy disappear or reverse.
Figures
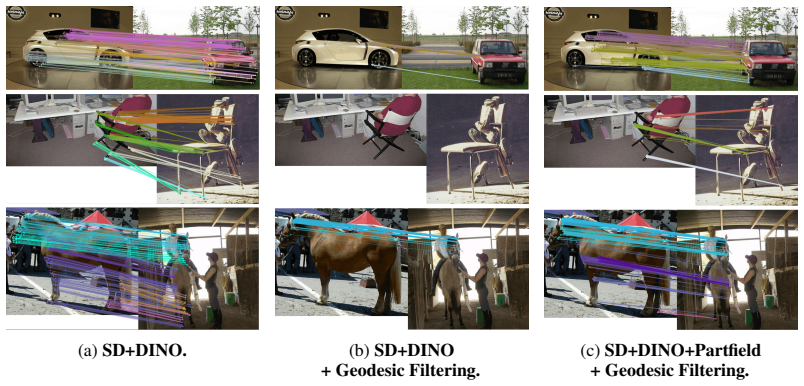
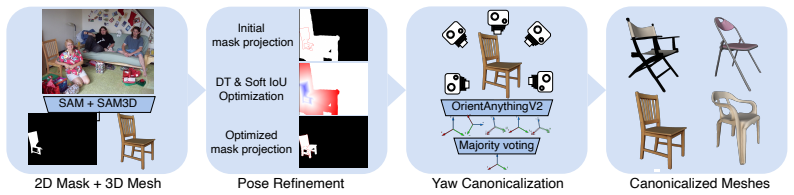
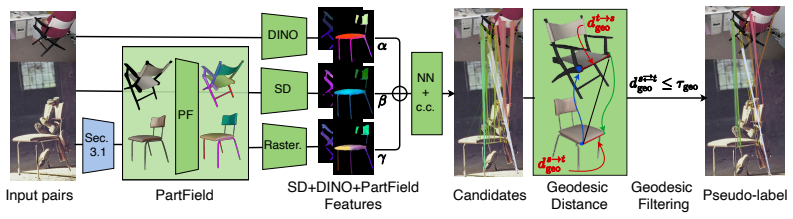

read the original abstract
Foundation features from self-supervised vision models and text-to-image diffusion models have proven effective for semantic correspondence estimation. However, because these features are learned primarily from 2D image objectives, they lack explicit 3D awareness and often confuse symmetric object sides, repeated parts, and visually similar structures that are distinct in 3D. We introduce a 3D-aware post-training framework that goes beyond available 2D foundation features by incorporating priors from 3D foundation models. Given an image, our method uses SAM3D to estimate object geometry and pose, and refines the pose through render-and-compare optimization. Subsequently, we render PartField descriptors from the reconstructed geometry into the image plane based on the estimated object pose. The resulting geometry-aware feature maps complement DINO and Stable Diffusion features, while geodesic distances on the reconstructed shapes enable reliable filtering of candidate correspondences. We use the filtered matches as supervision to train a lightweight adapter on top of DINO and Stable Diffusion for semantic correspondence. In contrast to prior post-training approaches that require pose annotations and rely on coarse spherical geometry, our method automatically obtains instance-specific 3D structure and uses it to guide correspondence learning. Experiments show that our approach improves semantic correspondence over the prior methods while reducing manual geometric supervision. Code and model can be found at https:/github.com/GenIntel/3D-SC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a 3D-aware post-training framework for semantic correspondence that leverages SAM3D to recover per-instance geometry and pose (refined via render-and-compare), renders PartField descriptors into the image plane, and applies geodesic distances on the reconstructed mesh to filter candidate matches. These filtered pairs serve as supervision to train a lightweight adapter atop DINO and Stable Diffusion features. The central claim is that the resulting geometry-aware features improve semantic correspondence accuracy over prior 2D-only post-training methods while reducing the need for manual pose annotations or coarse spherical geometry.
Significance. If the empirical claims hold, the work would demonstrate a practical route to injecting instance-specific 3D structure into existing 2D foundation features, addressing well-known failure modes on symmetric and repeated-part objects. The automatic acquisition of 3D priors and the public release of code and models are concrete strengths that would facilitate follow-up work.
major comments (3)
- [Abstract / Method] Abstract and method description: the improvement claim rests on the premise that SAM3D plus render-and-compare yields geometry and pose accurate enough for geodesic filtering to retain true semantic matches and discard false positives; however, no quantitative SAM3D reconstruction or pose-error statistics are reported on the correspondence evaluation sets, leaving the reliability of the supervision signal unverified.
- [Abstract] Abstract: the statement that 'Experiments show that our approach improves semantic correspondence over the prior methods' is unsupported by any tables, figures, metrics, error bars, dataset descriptions, or ablation results in the manuscript text, rendering the central empirical claim unverifiable from the provided content.
- [Method] Method: because the pipeline composes multiple external foundation models (SAM3D, PartField, DINO, Stable Diffusion) whose outputs are used directly as supervision, the absence of an ablation isolating the contribution of the geodesic-filtered 3D component versus the base 2D features makes it impossible to attribute gains specifically to the 3D priors.
minor comments (1)
- [Abstract] The GitHub URL in the abstract is written as 'https:/github.com/GenIntel/3D-SC' (single slash after https:); this should be corrected to the standard 'https://' form.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the empirical grounding of our 3D-aware post-training framework. We address each major comment below and commit to revisions that strengthen the verification of the supervision signal and the attribution of gains.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method description: the improvement claim rests on the premise that SAM3D plus render-and-compare yields geometry and pose accurate enough for geodesic filtering to retain true semantic matches and discard false positives; however, no quantitative SAM3D reconstruction or pose-error statistics are reported on the correspondence evaluation sets, leaving the reliability of the supervision signal unverified.
Authors: We agree that quantitative validation of SAM3D reconstruction and pose accuracy on the exact correspondence benchmarks is needed to confirm the supervision quality. In the revision we will report mean rotation/translation errors, reconstruction IoU, and render-and-compare convergence statistics computed directly on the SPair-71k and PF-PASCAL evaluation images. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'Experiments show that our approach improves semantic correspondence over the prior methods' is unsupported by any tables, figures, metrics, error bars, dataset descriptions, or ablation results in the manuscript text, rendering the central empirical claim unverifiable from the provided content.
Authors: The Experiments section of the full manuscript presents the supporting tables, figures, and dataset details. To make the abstract claim immediately verifiable, we will insert explicit cross-references (e.g., “see Table 2”) and a one-sentence summary of key metrics within the abstract itself. revision: partial
-
Referee: [Method] Method: because the pipeline composes multiple external foundation models (SAM3D, PartField, DINO, Stable Diffusion) whose outputs are used directly as supervision, the absence of an ablation isolating the contribution of the geodesic-filtered 3D component versus the base 2D features makes it impossible to attribute gains specifically to the 3D priors.
Authors: We concur that an explicit ablation is required. The revised manuscript will include a controlled experiment training the adapter on (i) raw DINO+SD matches and (ii) the same matches after geodesic filtering on the reconstructed meshes, thereby isolating the contribution of the 3D component. revision: yes
Circularity Check
No circularity: pipeline composes external models without self-referential reduction
full rationale
The paper presents a composite pipeline that invokes external models (SAM3D for geometry/pose, PartField descriptors, DINO and Stable Diffusion features) to produce filtered correspondences used as supervision for a lightweight adapter. No equations appear in the abstract or description that define a quantity in terms of itself or rename a fitted input as a prediction. No self-citations are invoked to justify uniqueness theorems, ansatzes, or load-bearing premises. The derivation chain therefore remains self-contained against external benchmarks and does not reduce the claimed improvement to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption SAM3D produces usable per-instance 3D geometry and pose from a single image
- domain assumption Render-and-compare optimization refines the initial pose estimate to sufficient accuracy
- domain assumption Geodesic distances on the reconstructed mesh reliably separate correct from incorrect candidate matches
Reference graph
Works this paper leans on
-
[1]
Aberman, J
K. Aberman, J. Liao, M. Shi, D. Lischinski, B. Chen, and D. Cohen-Or. Neural best-buddies: Sparse cross-domain correspondence.ACM Transactions on Graphics (TOG), 2018
2018
-
[2]
S. Amir, Y . Gandelsman, S. Bagon, and T. Dekel. Deep ViT features as dense visual descriptors. InEuropean Conference on Computer Vision Workshop (ECCVW), 2022
2022
-
[3]
SAM 3: Segment Anything with Concepts
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang, J. Lei, T. Ma, B. Guo, A. Kalla, M. Marks, J. Greer, M. Wang, P. Sun, R. Rädle, T. Afouras, E. Mavroudi, K. Xu, T.-H. Wu, Y . Zhou, L. Momeni, R. Hazra, S. Ding, S. Vaze, F. Porcher, F. Li, S. Li, A. Kamath, H. K. Cheng, P. Dollár, N. Ravi, K. Sae...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Caron, H
M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9650–9660, 2021
2021
-
[5]
Y . Chi, L. Sommer, O. Dünkel, D. Muhle, D. Cremers, C. Theobalt, and A. Kortylewski. C3po: Canonicalization of 3d pose from partial views with generalizable correspondence features. In International Conference on 3D Vision (3DV), 2026
2026
-
[6]
Cuttano, G
C. Cuttano, G. Trivigno, C. Masone, and S. Roth. MARCO: Navigating the unseen space of semantic correspondence. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[7]
Donati, A
N. Donati, A. Sharma, and M. Ovsjanikov. Deep geometric functional maps: Robust feature learning for shape correspondence. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 8592–8601, 2020
2020
-
[8]
Dünkel, T
O. Dünkel, T. Wimmer, C. Theobalt, C. Rupprecht, and A. Kortylewski. Do it yourself: Learning semantic correspondence from pseudo-labels. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[9]
N. S. Dutt, S. Muralikrishnan, and N. J. Mitra. Diffusion 3d features (diff3f): Decorating untextured shapes with distilled semantic features. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4494–4504, 2024
2024
-
[10]
Fundel, J
F. Fundel, J. Schusterbauer, V . T. Hu, and B. Ommer. Distillation of diffusion features for semantic correspondence. InProceedings of the Winter Conference on Applications of Computer Vision (WACV), 2025
2025
-
[11]
B. Ham, M. Cho, C. Schmid, and J. Ponce. Proposal flow: Semantic correspondences from object proposals.IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 40 (7):1711–1725, 2017
2017
-
[12]
Hartwig, D
R. Hartwig, D. Muhle, R. Marin, and D. Cremers. Geco: Geometrically consistent embedding with lightspeed inference. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9309–9319, 2025. 10
2025
-
[13]
Hedlin, G
E. Hedlin, G. Sharma, S. Mahajan, H. Isack, A. Kar, A. Tagliasacchi, and K. M. Yi. Unsuper- vised semantic correspondence using stable diffusion. InConference on Neural Information Processing Systems (NeurIPS), 2023
2023
-
[14]
Huang, Y
Y . Huang, Y . Sun, C. Lai, Q. Xu, X. Wang, X. Shen, and W. Ge. Weakly supervised learning of semantic correspondence through cascaded online correspondence refinement. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[15]
Jesslen, G
A. Jesslen, G. Zhang, A. Wang, W. Ma, A. Yuille, and A. Kortylewski. Novum: Neural object volumes for robust object classification. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[16]
J. Kim, K. Ryoo, J. Seo, G. Lee, D. Kim, H. Cho, and S. Kim. Semi-supervised learning of semantic correspondence with pseudo-labels. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[17]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
N. Kulkarni, S. Tulsiani, and A. Gupta. Canonical surface mapping via geometric cycle consistency. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 2202–2211, 2019. doi: 10.1109/ICCV .2019.00229
-
[18]
Li, D.-P
X. Li, D.-P. Fan, F. Yang, A. Luo, H. Cheng, and Z. Liu. Probabilistic model distillation for semantic correspondence. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021
2021
-
[19]
X. Li, J. Lu, K. Han, and V . A. Prisacariu. SD4Match: Learning to prompt Stable Diffusion model for semantic matching. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 27558–27568, 2024
2024
-
[20]
C. Liu, J. Yuen, and A. Torralba. Sift flow: Dense correspondence across scenes and its applications.IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 33(5): 978–994, 2011
2011
- [21]
-
[22]
D. G. Lowe. Distinctive image features from scale-invariant keypoints.International Journal of Computer Vision (IJCV), 60(2):91–110, 2004
2004
-
[23]
G. Luo, L. Dunlap, D. H. Park, A. Holynski, and T. Darrell. Diffusion hyperfeatures: Searching through time and space for semantic correspondence. InConference on Neural Information Processing Systems (NeurIPS), 2023
2023
-
[24]
Mariotti, O
O. Mariotti, O. Mac Aodha, and H. Bilen. Improving semantic correspondence with viewpoint- guided spherical maps. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[25]
Mariotti, Z
O. Mariotti, Z. Du, Y . Bhalgat, O. Mac Aodha, and H. Bilen. Jamais Vu: Exposing the generalization gap in supervised semantic correspondence. InConference on Neural Information Processing Systems (NeurIPS), volume 38, 2025
2025
- [26]
-
[27]
Neverova, D
N. Neverova, D. Novotny, V . Khalidov, M. Szafraniec, P. Labatut, and A. Vedaldi. Continuous surface embeddings for deformable shape correspondence.Conference on Neural Information Processing Systems (NeurIPS), 2020
2020
-
[28]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, et al. DINOv2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Ovsjanikov, M
M. Ovsjanikov, M. Ben-Chen, J. Solomon, A. Butscher, and L. Guibas. Functional maps: a flexible representation of maps between shapes.ACM Transactions on Graphics (TOG), 31(4): 1–11, 2012. 11
2012
-
[30]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022
2022
-
[31]
SAM 3D: 3Dfy Anything in Images
SAM 3D Team, X. Chen, F.-J. Chu, P. Gleize, K. J. Liang, A. Sax, H. Tang, W. Wang, M. Guo, T. Hardin, X. Li, A. Lin, J. Liu, Z. Ma, A. Sagar, B. Song, X. Wang, J. Yang, B. Zhang, P. Dollár, G. Gkioxari, M. Feiszli, and J. Malik. SAM 3D: 3Dfy anything in images, 2025. URL https://arxiv.org/abs/2511.16624
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Shtedritski, C
A. Shtedritski, C. Rupprecht, and A. Vedaldi. Shic: Shape-image correspondences with no keypoint supervision. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[33]
Sommer, O
L. Sommer, O. Dünkel, C. Theobalt, and A. Kortylewski. Common3d: Self-supervised learning of 3d morphable models for common objects in neural feature space. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6468–6479, June 2025
2025
-
[34]
L. Tang, M. Jia, Q. Wang, C. P. Phoo, and B. Hariharan. Emergent correspondence from image diffusion. InConference on Neural Information Processing Systems (NeurIPS), 2023
2023
-
[35]
Taniai, S
T. Taniai, S. N. Sinha, and Y . Sato. Joint recovery of dense correspondence and cosegmentation in two images. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4246–4255, 2016
2016
-
[36]
Tumanyan, M
N. Tumanyan, M. Geyer, S. Bagon, and T. Dekel. Plug-and-play diffusion features for text- driven image-to-image translation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1921–1930, 2023
1921
-
[37]
K. Wandel and H. Wang. Semalign3d: Semantic correspondence between rgb-images through aligning 3d object-class representations. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1138–1147, 2025. doi: 10.1109/CVPR52734. 2025.00114
-
[38]
P. Wang, T. Ikeda, R. Lee, and K. Nishiwaki. Gs-pose: Category-level object pose estimation via geometric and semantic correspondence. InEuropean Conference on Computer Vision (ECCV), pages 108–126. Springer, 2024
2024
-
[39]
Z. Wang, Z. Zhang, J. Xu, J. Wang, T. Pang, C. Du, H. Zhao, and Z. Zhao. Orient anything v2: Unifying orientation and rotation understanding. InConference on Neural Information Processing Systems (NeurIPS), 2025
2025
- [40]
-
[41]
L. Yi, V . G. Kim, D. Ceylan, W. Shen, M. Yan, H. Su, C. Lu, Q. Huang, A. Sheffer, and L. Guibas. A scalable active framework for region annotation in 3d shape collections. InACM Trans. Graphics (Proc. SIGGRAPH Asia), 2016
2016
-
[42]
H. Yu, Y . Xu, J. Zhang, W. Zhao, Z. Guan, and D. Tao. AP-10k: A benchmark for animal pose estimation in the wild. InConference on Neural Information Processing Systems (NeurIPS), 2021
2021
-
[43]
Zhang, C
J. Zhang, C. Herrmann, J. Hur, L. F. Polanía, V . Jampani, D. Sun, and M.-H. Yang. A tale of two features: Stable diffusion complements DINO for zero-shot semantic correspondence. In Conference on Neural Information Processing Systems (NeurIPS), 2023
2023
-
[44]
Zhang, C
J. Zhang, C. Herrmann, J. Hur, E. Chen, V . Jampani, D. Sun, and M.-H. Yang. Telling left from right: Identifying geometry-aware semantic correspondence. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3076–3085, 2024
2024
-
[45]
T. Zhou, P. Krahenbuhl, M. Aubry, Q. Huang, and A. A. Efros. Learning dense correspondence via 3d-guided cycle consistency. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. 12
2016
-
[46]
J. Zhu, Y . Ju, J. Zhang, M. Wang, Z. Yuan, K. Hu, and H. Xu. Densematcher: Learning 3d semantic correspondence for category-level manipulation from a single demo.International Conference on Learning Representations (ICLR), 2025. 13 Geometry Matters: 3D Foundation Priors for Learning Semantic Correspondence Supplementary Material This supplement is organi...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.