The generalized method of moments is (almost) statistically efficient in low-SNR Gaussian latent-variable models
Pith reviewed 2026-06-29 00:03 UTC · model grok-4.3
The pith
In low-SNR Gaussian latent-variable models the generalized method of moments matches the leading asymptotic covariance of maximum likelihood when moments are taken to the minimal identification order and weighted optimally.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the low-SNR regime, if the moment features are chosen up to the minimal local order required for identification and are weighted optimally, then the resulting GMoM estimator has the same leading asymptotic covariance as the maximum-likelihood estimator. This equivalence is governed by a layered local geometry: different directions become informative at different moment orders, partitioning the space into layers with distinct SNR scalings. The observed Fisher information and the GMoM information operator admit matching layerwise expansions across these layers.
What carries the argument
The layered local geometry that partitions the parameter space into layers with distinct SNR scalings and produces matching layerwise expansions of the observed Fisher information and the GMoM information operator.
If this is right
- GMoM supplies a statistically efficient alternative to maximum likelihood while retaining the computational advantages of moment-based estimation.
- The equivalence between GMoM and maximum likelihood holds across the broad class of Gaussian latent-variable models that includes mixtures and orbit recovery.
- The matching layerwise expansions imply that efficiency is achieved separately in each SNR-scaled layer of the parameter space.
- Optimal weighting of the chosen moments is required to attain the matching leading covariance term.
Where Pith is reading between the lines
- The layered geometry may suggest systematic rules for selecting moment orders in other estimation problems that exhibit similar SNR-dependent identifiability.
- In practice the result could encourage replacing maximum-likelihood routines with GMoM implementations in high-noise regimes where speed matters.
- The same layerwise expansion technique might be applied to derive efficiency statements for other moment-based estimators outside the Gaussian setting.
Load-bearing premise
The low-SNR regime admits a layered local geometry in which different directions become informative at different moment orders, partitioning the parameter space into layers with distinct SNR scalings.
What would settle it
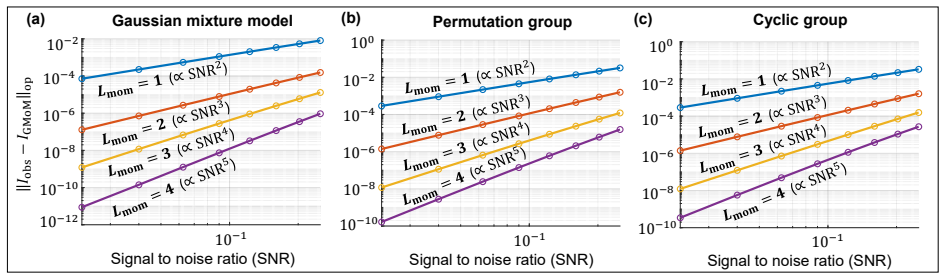
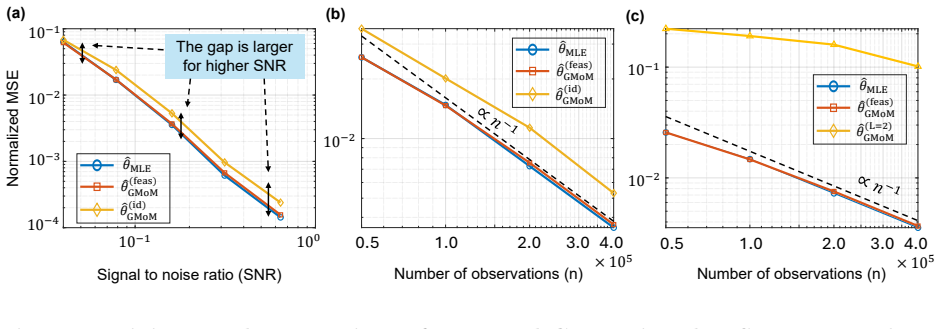
A direct calculation, for a concrete low-SNR Gaussian mixture, of the leading asymptotic covariance matrix of the optimally weighted GMoM estimator using moments up to the minimal identification order, compared against the inverse of the observed Fisher information matrix.
Figures
read the original abstract
We study estimation in the low signal-to-noise ratio (SNR) regime for a broad class of Gaussian latent-variable models, including Gaussian mixtures and orbit recovery problems. We show that, in this regime, the generalized method-of-moments (GMoM) matches the first-order asymptotic efficiency of maximum likelihood. In particular, if the moment features are chosen up to the minimal local order required for identification and are weighted optimally, then the resulting GMoM estimator has the same leading asymptotic covariance as the maximum-likelihood estimator. Our analysis shows that, in low SNR, this equivalence is governed by a layered local geometry: different directions become informative at different moment orders, partitioning the space into layers with distinct SNR scalings. We prove that the observed Fisher information and the GMoM information operator admit matching layerwise expansions across these layers. As a consequence, in the low-SNR regime, GMoM provides a statistically efficient alternative to maximum likelihood, while preserving the computational advantages of moment-based estimation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that for a broad class of Gaussian latent-variable models (including mixtures and orbit recovery) in the low-SNR regime, the generalized method of moments (GMoM) achieves the same leading asymptotic covariance as maximum likelihood estimation. Specifically, when moment features are selected up to the minimal local order required for identification and weighted optimally, the GMoM estimator matches the first-order efficiency of the MLE. The argument relies on a layered local geometry that partitions the parameter space into layers with distinct SNR scalings; the observed Fisher information and the GMoM information operator are shown to admit matching layerwise expansions across these layers.
Significance. If the layerwise matching result holds, the paper establishes that GMoM furnishes a computationally tractable, first-order asymptotically efficient alternative to MLE precisely in the low-SNR regime where MLE is often intractable. The layered geometry and the explicit matching of information operators constitute a substantive technical contribution to the analysis of moment-based estimators in singular or low-signal settings. The manuscript supplies a direct comparison of the two information operators under the stated geometry, which is a strength.
major comments (2)
- [§4, Theorem 2] §4, Theorem 2 (layerwise expansion of the GMoM information operator): the claim that the leading term matches the observed Fisher information layer by layer requires that the optimal weighting matrix exactly cancels all higher-order contributions within each layer; the proof sketch does not explicitly verify that the remainder terms are o(1/SNR^k) uniformly across layers when the identification order varies with the direction.
- [§3.2, Definition 3] §3.2, Definition 3 (minimal local identification order): the construction of the moment features up to this order is invoked to ensure the information operators coincide at leading order, but it is not shown that this choice remains feasible when the parameter lies at the boundary between two layers; a concrete counter-example or perturbation argument would strengthen the claim.
minor comments (2)
- [§2 and §4] Notation for the SNR scaling parameter is introduced in §2 but reused with different normalizations in the layerwise expansions of §4; a single consistent definition would improve readability.
- [§1.2] The abstract states the result for 'Gaussian latent-variable models' but the precise class (e.g., whether it includes non-identifiable mixtures) is only delimited in §1.2; an explicit list of included models would help.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. The positive assessment of the layered geometry and the information-operator comparison is appreciated. We address each major comment below and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: [§4, Theorem 2] §4, Theorem 2 (layerwise expansion of the GMoM information operator): the claim that the leading term matches the observed Fisher information layer by layer requires that the optimal weighting matrix exactly cancels all higher-order contributions within each layer; the proof sketch does not explicitly verify that the remainder terms are o(1/SNR^k) uniformly across layers when the identification order varies with the direction.
Authors: We agree that an explicit uniform bound on the remainder terms is needed when the identification order changes across directions. In the revised manuscript we will augment the proof of Theorem 2 with a uniform estimate: because each layer is defined by a fixed minimal moment order and the optimal weighting matrix is block-diagonal with respect to the layer decomposition, the cross-layer contributions are controlled by the SNR gap between consecutive layers. This yields the required o(1/SNR^k) remainder uniformly on compact sets that intersect finitely many layers, thereby confirming that the leading terms match layer by layer. revision: yes
-
Referee: [§3.2, Definition 3] §3.2, Definition 3 (minimal local identification order): the construction of the moment features up to this order is invoked to ensure the information operators coincide at leading order, but it is not shown that this choice remains feasible when the parameter lies at the boundary between two layers; a concrete counter-example or perturbation argument would strengthen the claim.
Authors: The definition of minimal local identification order is constructed via the lowest moment order that renders the local information operator full rank in a given direction; at layer boundaries the two adjacent orders become simultaneously minimal. We will add a short perturbation argument in §3.2 showing that, for any parameter on the boundary, the moment features selected from either adjacent layer remain valid: a small perturbation into one layer preserves the rank condition by continuity of the moment map, while the information-operator expansion remains unchanged at leading order because the extra moments contribute only higher-order terms. This establishes feasibility without requiring a separate counter-example. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper derives matching layerwise expansions between the observed Fisher information and the GMoM information operator under a partitioned low-SNR geometry, with the central claim resting on this direct comparison when moments are taken to the minimal identification order and weighted optimally. No step reduces by construction to a fitted parameter renamed as prediction, a self-definitional loop, or a load-bearing self-citation chain; the argument is presented as an independent expansion analysis of the information operators themselves. The derivation is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The generalized method of moments for multi-reference alignment.IEEE Transactions on Signal Processing, 70:1377–1388, 2022
Asaf Abas, Tamir Bendory, and Nir Sharon. The generalized method of moments for multi-reference alignment.IEEE Transactions on Signal Processing, 70:1377–1388, 2022
2022
-
[2]
Pereira, Nir Sharon, and Amit Singer
Emmanuel Abbe, Tamir Bendory, William Leeb, Jo˜ ao M. Pereira, Nir Sharon, and Amit Singer. Multireference alignment is easier with an aperiodic translation distribution. IEEE Transactions on Information Theory, 65(6):3565–3584, 2019
2019
-
[3]
Princeton University Press, 2008
P-A Absil, Robert Mahony, and Rodolphe Sepulchre.Optimization algorithms on matrix manifolds. Princeton University Press, 2008. 33
2008
-
[4]
Fundamental limits in multi-image alignment.IEEE Transactions on Signal Processing, 64(21):5707–5722, 2016
Cecilia Aguerrebere, Mauricio Delbracio, Alberto Bartesaghi, and Guillermo Sapiro. Fundamental limits in multi-image alignment.IEEE Transactions on Signal Processing, 64(21):5707–5722, 2016
2016
-
[5]
Tensor decompositions for learning latent variable models.The Journal of Machine Learning Research, 15(1):2773–2832, 2014
Animashree Anandkumar, Rong Ge, Daniel Hsu, Sham M Kakade, and Matus Telgarsky. Tensor decompositions for learning latent variable models.The Journal of Machine Learning Research, 15(1):2773–2832, 2014
2014
-
[6]
Orbit recovery under the rigid motions group.arXiv preprint arXiv:2512.07405, 2025
Amnon Balanov, Tamir Bendory, and Dan Edidin. Orbit recovery under the rigid motions group.arXiv preprint arXiv:2512.07405, 2025
-
[7]
Group-invariant moments under tomographic projections
Amnon Balanov, Tamir Bendory, and Dan Edidin. Group-invariant moments under tomographic projections.arXiv preprint arXiv:2604.08330, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Expectation-maximization for low-SNR multi-reference alignment.arXiv preprint arXiv:2505.21435, 2026
Amnon Balanov, Wasim Huleihel, and Tamir Bendory. Expectation-maximization for low-SNR multi-reference alignment.arXiv preprint arXiv:2505.21435, 2026
-
[9]
Projected multi-reference alignment
Amnon Balanov, Josh Katz, Tamir Bendory, and Dan Edidin. Projected multi-reference alignment.arXiv preprint arXiv:2605.25533, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Estimation under group actions: recovering orbits from invari- ants.Applied and Computational Harmonic Analysis, 66:236–319, 2023
Afonso S Bandeira, Ben Blum-Smith, Joe Kileel, Jonathan Niles-Weed, Amelia Perry, and Alexander S Wein. Estimation under group actions: recovering orbits from invari- ants.Applied and Computational Harmonic Analysis, 66:236–319, 2023
2023
-
[11]
Single-particle cryo-electron microscopy: Mathematical theory, computational challenges, and opportunities.IEEE signal processing magazine, 37(2):58–76, 2020
Tamir Bendory, Alberto Bartesaghi, and Amit Singer. Single-particle cryo-electron microscopy: Mathematical theory, computational challenges, and opportunities.IEEE signal processing magazine, 37(2):58–76, 2020
2020
-
[12]
Bispectrum inversion with application to multireference alignment.IEEE Transactions on signal processing, 66(4):1037–1050, 2017
Tamir Bendory, Nicolas Boumal, Chao Ma, Zhizhen Zhao, and Amit Singer. Bispectrum inversion with application to multireference alignment.IEEE Transactions on signal processing, 66(4):1037–1050, 2017
2017
-
[13]
Orbit recovery for spherical functions.arXiv preprint arXiv:2508.02674, 2025
Tamir Bendory, Dan Edidin, Josh Katz, and Shay Kreymer. Orbit recovery for spherical functions.arXiv preprint arXiv:2508.02674, 2025
-
[14]
Dihedral multi-reference alignment.IEEE Transactions on Information Theory, 68(5):3489–3499, 2022
Tamir Bendory, Dan Edidin, William Leeb, and Nir Sharon. Dihedral multi-reference alignment.IEEE Transactions on Information Theory, 68(5):3489–3499, 2022
2022
-
[15]
Springer, 2006
Christopher M Bishop and Nasser M Nasrabadi.Pattern recognition and machine learn- ing, volume 4. Springer, 2006
2006
-
[16]
On the asymptotic efficiency of GMM.Econo- metric Theory, 30(2):372–406, 2014
Marine Carrasco and Jean-Pierre Florens. On the asymptotic efficiency of GMM.Econo- metric Theory, 30(2):372–406, 2014
2014
-
[17]
Spectral experts for estimating mixtures of linear regressions
Arun Tejasvi Chaganty and Percy Liang. Spectral experts for estimating mixtures of linear regressions. InInternational conference on machine learning, pages 1040–1048. PMLR, 2013
2013
-
[18]
Princeton university press, 1999
Harald Cram´ er.Mathematical methods of statistics, volume 9. Princeton university press, 1999. 34
1999
-
[19]
Maximum likelihood from incomplete data via the EM algorithm.Journal of the royal statistical society: series B (methodological), 39(1):1–22, 1977
Arthur P Dempster, Nan M Laird, and Donald B Rubin. Maximum likelihood from incomplete data via the EM algorithm.Journal of the royal statistical society: series B (methodological), 39(1):1–22, 1977
1977
-
[20]
Orbit recovery from invariants of low degree in represen- tations of finite groups
Dan Edidin and Josh Katz. Orbit recovery from invariants of low degree in represen- tations of finite groups. In2025 International Conference on Sampling Theory and Applications (SampTA), pages 1–5. IEEE, 2025
2025
-
[21]
Maximum likeli- hood for high-noise group orbit estimation and single-particle cryo-EM.The Annals of Statistics, 52(1):52–77, 2024
Zhou Fan, Roy R Lederman, Yi Sun, Tianhao Wang, and Sheng Xu. Maximum likeli- hood for high-noise group orbit estimation and single-particle cryo-EM.The Annals of Statistics, 52(1):52–77, 2024
2024
-
[22]
Likelihood landscape and maximum likelihood estimation for the discrete orbit recovery model.Communications on Pure and Applied Mathematics, 76(6):1208–1302, 2023
Zhou Fan, Yi Sun, Tianhao Wang, and Yihong Wu. Likelihood landscape and maximum likelihood estimation for the discrete orbit recovery model.Communications on Pure and Applied Mathematics, 76(6):1208–1302, 2023
2023
-
[23]
Springer, 2006
Sylvia Fr¨ uhwirth-Schnatter.Finite mixture and Markov switching models. Springer, 2006
2006
-
[24]
The Wiener-Itˆ o chaos decomposition and multiple Wiener integrals.Unpub- lished online notes, 2020
Xi Geng. The Wiener-Itˆ o chaos decomposition and multiple Wiener integrals.Unpub- lished online notes, 2020
2020
-
[25]
Wiley Online Library, 2004
Alastair Hall.Generalized method of moments. Wiley Online Library, 2004
2004
-
[26]
Large sample properties of generalized method of moments estima- tors.Econometrica: Journal of the econometric society, pages 1029–1054, 1982
Lars Peter Hansen. Large sample properties of generalized method of moments estima- tors.Econometrica: Journal of the econometric society, pages 1029–1054, 1982
1982
-
[27]
Graduate Texts in Mathematics, No
Robin Hartshorne.Algebraic geometry. Graduate Texts in Mathematics, No. 52. Springer-Verlag, New York-Heidelberg, 1977
1977
-
[28]
Strong identifiability and optimal minimax rates for finite mixture estimation.The Annals of Statistics, 46(6A):2844 – 2870, 2018
Philippe Heinrich and Jonas Kahn. Strong identifiability and optimal minimax rates for finite mixture estimation.The Annals of Statistics, 46(6A):2844 – 2870, 2018
2018
-
[29]
Learning mixtures of spherical Gaussians: Moment methods and spectral decompositions
Daniel Hsu and Sham M Kakade. Learning mixtures of spherical Gaussians: Moment methods and spectral decompositions. InITCS, 2013
2013
-
[30]
Number 129 in Cambridge Tracts in Mathe- matics
Svante Janson.Gaussian hilbert spaces. Number 129 in Cambridge Tracts in Mathe- matics. Cambridge university press, 1997
1997
-
[31]
Likelihood maximization and moment matching in low SNR Gaussian mixture models.Communications on Pure and Applied Mathe- matics, 76(4):788–842, 2023
Anya Katsevich and Afonso S Bandeira. Likelihood maximization and moment matching in low SNR Gaussian mixture models.Communications on Pure and Applied Mathe- matics, 76(4):788–842, 2023
2023
-
[32]
Springer Science & Business Media, 2000
Lucien Le Cam and Grace Lo Yang.Asymptotics in statistics: some basic concepts. Springer Science & Business Media, 2000
2000
-
[33]
Smooth manifolds
John M Lee. Smooth manifolds. InIntroduction to smooth manifolds, pages 1–29. Springer, 2003
2003
-
[34]
Mixture models: theory, geometry, and applications
Bruce G Lindsay. Mixture models: theory, geometry, and applications. IMS, 1995. 35
1995
-
[35]
John Wiley & Sons, 2008
Geoffrey J McLachlan and Thriyambakam Krishnan.The EM algorithm and extensions. John Wiley & Sons, 2008
2008
-
[36]
Finite mixture models
Geoffrey J McLachlan, Sharon X Lee, and Suren I Rathnayake. Finite mixture models. Annual review of statistics and its application, 6(1):355–378, 2019
2019
-
[37]
Large sample estimation and hypothesis testing.Handbook of econometrics, 4:2111–2245, 1994
Whitney K Newey and Daniel McFadden. Large sample estimation and hypothesis testing.Handbook of econometrics, 4:2111–2245, 1994
1994
-
[38]
Springer, 2006
David Nualart.The Malliavin calculus and related topics. Springer, 2006
2006
-
[39]
SBM, 2019
David Nualart and Alison Etheridge.Malliavin calculus and normal approximations. SBM, 2019
2019
-
[40]
Springer Science & Business Media, 2011
Giovanni Peccati and Murad S Taqqu.Wiener Chaos: Moments, Cumulants and Dia- grams: A survey with computer implementation, volume 1. Springer Science & Business Media, 2011
2011
-
[41]
The sample complexity of multireference alignment.SIAM Journal on Mathematics of Data Science, 1(3):497–517, 2019
Amelia Perry, Jonathan Weed, Afonso S Bandeira, Philippe Rigollet, and Amit Singer. The sample complexity of multireference alignment.SIAM Journal on Mathematics of Data Science, 1(3):497–517, 2019
2019
-
[42]
Multi-reference alignment in high dimensions: Sample complexity and phase transition.SIAM Journal on Mathematics of Data Science, 3(2):494–523, 2021
Elad Romanov, Tamir Bendory, and Or Ordentlich. Multi-reference alignment in high dimensions: Sample complexity and phase transition.SIAM Journal on Mathematics of Data Science, 3(2):494–523, 2021
2021
-
[43]
Provable tensor methods for learning mixtures of generalized linear models
Hanie Sedghi, Majid Janzamin, and Anima Anandkumar. Provable tensor methods for learning mixtures of generalized linear models. InArtificial Intelligence and Statistics, pages 1223–1231. PMLR, 2016
2016
-
[44]
The interplay of signal-to-noise ratio and variance misspecification in Gaussian mixtures
Vladimir Serov, Amnon Balanov, and Tamir Bendory. The interplay of signal- to-noise ratio and variance misspecification in Gaussian mixtures.arXiv preprint arXiv:2605.02448, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Cambridge university press, 2000
Aad W Van der Vaart.Asymptotic statistics, volume 3. Cambridge university press, 2000
2000
-
[46]
Liu Zhang, Oscar Mickelin, Sheng Xu, and Amit Singer. Diagonally-weighted gener- alized method of moments estimation for Gaussian mixture modeling.arXiv preprint arXiv:2507.20459, 2025. Appendix Appendix organization.Appendix A collects the basic analytical properties of the Gaus- sian latent-variable model used throughout the paper, including likelihood ...
-
[47]
For everyy∈R d, the mapθ7→p θ,β(y) = R Z φσ y−βA(z)θ µ(dz)isC ∞ onU
-
[48]
There exists a measurable functionG U :R d →[0,∞)such thatE Y∼p θ⋆,β[GU(Y)]<∞ and, for ally∈R d, sup θ∈U |logp θ,β(y)|+ sup θ∈U ∥∇θ logp θ,β(y)∥+ sup θ∈U ∥∇2 θ logp θ,β(y)∥op ≤G U(y).(A.3)
-
[49]
LetB Θ ≜sup θ∈Θ ∥θ∥<∞andR≜βa maxBΘ
The observed-data Fisher information matrix satisfies Iobs(θ;β) =E Y∼p θ,β ∇θ logp θ,β(Y)∇ θ logp θ,β(Y) ⊤ (A.4) =−E Y∼p θ,β ∇2 θ logp θ,β(Y) .(A.5) Proof of Lemma A.1.By Assumption 2.4, Θ is compact and∥A(z)∥ op ≤a max for a.e.z∈ Z. LetB Θ ≜sup θ∈Θ ∥θ∥<∞andR≜βa maxBΘ. Then∥βA(z)θ∥ ≤Rfor allθ∈Θ and a.e. z∈ Z, soβA(z)θlie in the fixed compact ballB(0, R)⊂R...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.