CCS: Clinical Consensus Selection for Radiology Report Generation
Pith reviewed 2026-06-29 07:50 UTC · model grok-4.3
The pith
Selecting the radiology report with highest clinical consensus from multiple model candidates improves quality over default decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
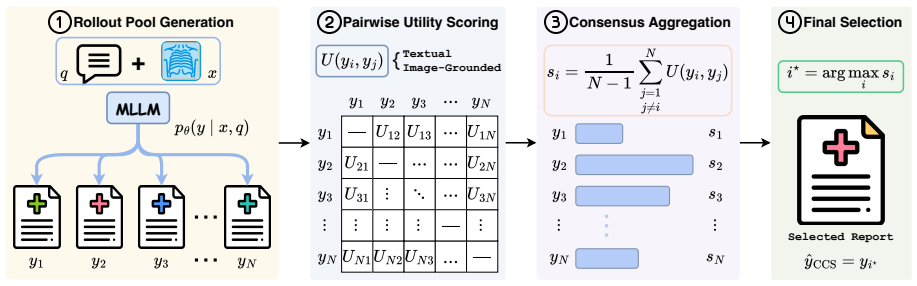
Fixed radiology MLLMs often place clinically stronger reports in their candidate pool than the one chosen by default decoding; Clinical Consensus Selection addresses this by sampling multiple candidates and selecting the report with the highest clinical consensus, where consensus is measured by a unified utility that includes both text-based measures and a radiology-adapted score from an image-report multimodal embedder.
What carries the argument
Clinical Consensus Selection (CCS), a decoder-agnostic framework that ranks candidate reports by their clinical consensus using a multimodal embedder to capture agreement beyond surface text similarity.
If this is right
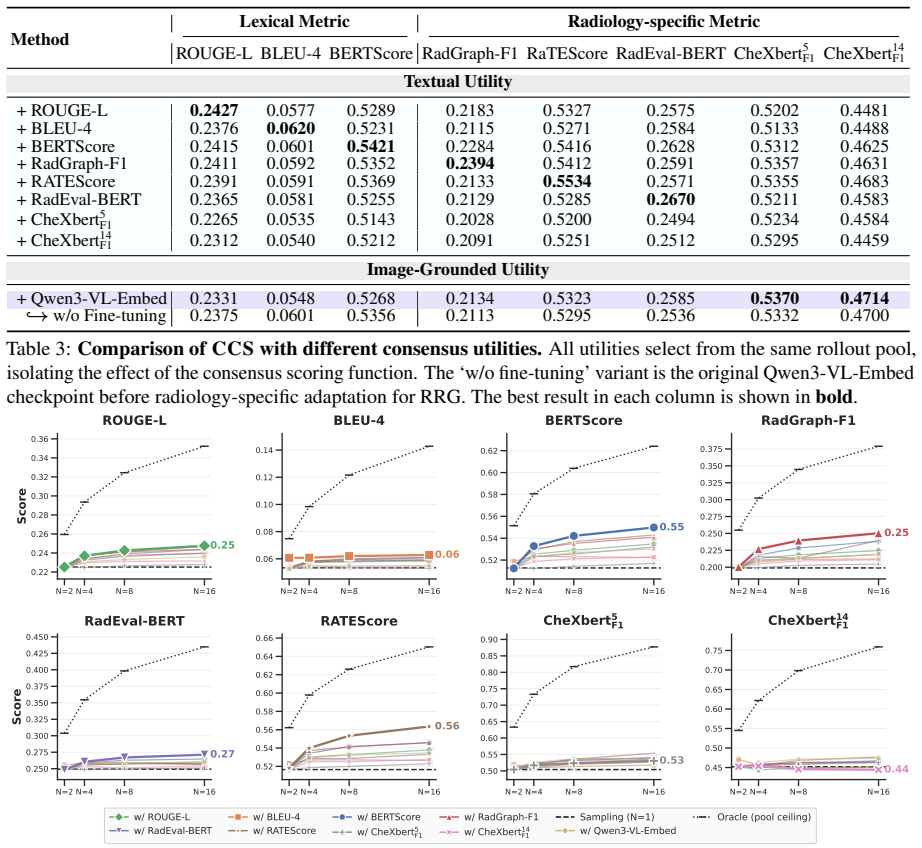
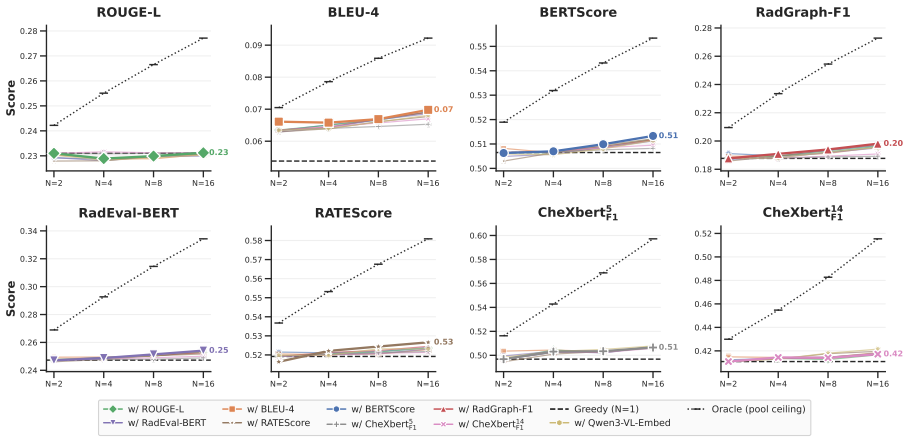
- CCS improves inference-time performance over single-path decoding and generic Best-of-N baselines across three datasets and multiple radiology MLLMs.
- Gains are particularly clear on clinical metrics.
- Image-grounded utility forms a selection axis distinct from textual consensus.
- Substantial headroom remains for improving RRG at inference time.
Where Pith is reading between the lines
- Similar consensus selection could reduce single-path errors in other medical text generation tasks where clinical accuracy is the main goal.
- The distinct image-grounded axis indicates that multimodal signals may be required for reliable selection in clinical domains.
- Applying CCS to larger or differently trained models would test whether the observed gains hold as model capacity increases.
Load-bearing premise
The radiology-adapted utility from the image-report-trained multimodal embedder accurately measures agreement on clinical content rather than merely surface-level textual similarity.
What would settle it
A new test set in which expert radiologists rate the CCS-chosen report as clinically worse than the single-path default output would falsify the central claim.
Figures


read the original abstract
Radiology report generation (RRG) is commonly formulated as a single-path generation task, where a multimodal large language model (MLLM) produces one decoded report as the final output. While recent progress has largely been driven by scaling training data, model capacity, and retrieval mechanisms, improving report quality at inference time remains underexplored. In this work, we observe that fixed radiology MLLMs often generate clinically stronger reports elsewhere in their candidate pool than the one selected by default decoding, suggesting that inference-time decision making remains an overlooked bottleneck. To address this, we propose Clinical Consensus Selection (CCS), a decoder-agnostic inference-time selection framework that samples multiple candidate reports and selects the one with the highest clinical consensus across the rollout pool. CCS unifies text-based utilities with a radiology-adapted utility computed by an image--report-trained multimodal embedder, which measures candidate agreement beyond surface-level textual similarity. Across three datasets and multiple radiology MLLMs, CCS consistently improves inference-time performance over single-path decoding and generic Best-of-N baselines, with particularly clear gains on clinical metrics. Further analysis shows that image-grounded utility forms a selection axis distinct from textual consensus and that substantial headroom remains for improving RRG at inference time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Clinical Consensus Selection (CCS) is a decoder-agnostic inference-time framework that samples multiple candidate radiology reports from MLLMs and selects the one with highest clinical consensus by unifying text-based utilities with a radiology-adapted utility from an image-report-trained multimodal embedder; across three datasets and multiple MLLMs, CCS improves over single-path decoding and Best-of-N baselines, with clear gains on clinical metrics, and that the image-grounded utility forms a distinct selection axis from textual consensus.
Significance. If the central claim holds, the work demonstrates that inference-time selection can unlock better clinical performance from fixed radiology MLLMs without retraining or scaling, and that multimodal embedders can supply a selection signal orthogonal to text-only utilities. This is a practical contribution to RRG deployment and identifies remaining headroom at inference time.
major comments (2)
- [Abstract] Abstract: the assertion that the multimodal embedder 'measures candidate agreement beyond surface-level textual similarity' is load-bearing for the claim of a 'distinct selection axis,' yet the description provides no training procedure, loss function, or correlation analysis against clinical annotations (e.g., CheXpert labels or radiologist scores) to substantiate that the utility captures clinical content rather than textual similarity.
- [Abstract] Abstract: the reported consistent improvements on clinical metrics across datasets and models rest on the assumption that the embedder utility is computed independently of the evaluation data; without details on training splits, embedder training data, or statistical significance testing, it is impossible to rule out that gains are driven by the textual component alone or by data leakage.
minor comments (1)
- The abstract would be clearer if it specified the number of candidates sampled per rollout and the exact functional form used to unify the text-based and embedder utilities.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the manuscript accordingly where details are missing from the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the multimodal embedder 'measures candidate agreement beyond surface-level textual similarity' is load-bearing for the claim of a 'distinct selection axis,' yet the description provides no training procedure, loss function, or correlation analysis against clinical annotations (e.g., CheXpert labels or radiologist scores) to substantiate that the utility captures clinical content rather than textual similarity.
Authors: The abstract is necessarily concise. The full manuscript (Section 3.2 and Appendix) specifies that the multimodal embedder is trained on paired image-report data from the training splits of the radiology datasets using a contrastive InfoNCE loss to align visual and textual embeddings. We provide correlation analysis with CheXpert labels and radiologist preference scores in the supplementary material showing that the utility captures clinical content beyond n-gram overlap. We will revise the abstract to include a brief clause on the training procedure and reference the supporting analyses. revision: yes
-
Referee: [Abstract] Abstract: the reported consistent improvements on clinical metrics across datasets and models rest on the assumption that the embedder utility is computed independently of the evaluation data; without details on training splits, embedder training data, or statistical significance testing, it is impossible to rule out that gains are driven by the textual component alone or by data leakage.
Authors: The embedder is trained exclusively on the official training splits of each dataset and never sees the test or validation reports used for evaluation or metric computation. Ablation studies in the paper isolate the contribution of the multimodal utility and show gains beyond text-only consensus. Statistical significance is assessed via paired t-tests and reported in the results tables. We will add explicit statements on training splits and independence to the abstract and methods to address this concern. revision: yes
Circularity Check
No circularity; CCS uses independent embedder and external utilities with no reduction to evaluation data
full rationale
The paper introduces CCS as an inference-time selection method that samples candidates from an MLLM and chooses the report maximizing clinical consensus, unifying text utilities with a utility from a separately described image-report-trained multimodal embedder. No equations, self-citations, or derivations are shown that define the selection criterion or reported gains in terms of the same fitted quantities used for evaluation. The embedder is presented as an external component measuring agreement beyond surface similarity, and the abstract gives no indication of self-definitional loops or fitted inputs renamed as predictions. The central claim therefore remains independent of its test metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The multimodal embedder trained on image-report pairs measures clinical agreement beyond textual similarity
Reference graph
Works this paper leans on
-
[1]
Maira-2: Grounded radiology report genera- tion.Preprint, arXiv:2406.04449. Pierre Chambon, Jean-Benoit Delbrouck, Thomas Sounack, Shih-Cheng Huang, Zhihong Chen, Maya Varma, Steven QH Truong, Chu The Chuong, and Curtis P. Langlotz. 2024. Chexpert plus: Augment- ing a large chest x-ray dataset with text radiology reports, patient demographics and addition...
-
[2]
RAD-DINO: Exploring scalable medical im- age encoders beyond text supervision.Preprint, arXiv:2401.10815. Fernando Pérez-García, Harshita Sharma, Sam Bond- Taylor, Kenza Bouzid, Valentina Salvatelli, Maxim- ilian Ilse, Shruthi Bannur, Daniel C. Castro, Anton Schwaighofer, Matthew P. Lungren, Maria Teodora Wetscherek, Noel Codella, Stephanie L. Hyland, Jav...
-
[3]
Towards generalist biomedical AI.arXiv preprint arXiv:2307.14334, 2023
Towards generalist biomedical ai.Preprint, arXiv:2307.14334. Han Wang, Archiki Prasad, Elias Stengel-Eskin, and Mohit Bansal. 2024. Soft self-consistency improves language models agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 287– 301. Xiaosong Wang, Yifan Peng, Le Lu, Zhiy...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.